
Web Scraping
Web Scraping With Java - Concurrent Scraping, Headless Browser, and Anti Detect Browser
In this article, we will combine Java with concurrent programming to scrape data from the entire site.
Apr 23, 2024Carlos Rivera
We have provided a successful example of using Java to scrape data from a single page on the Scrapeme site in the previous blog in this tutorial.
So, are there any more special methods for data scraping?
Definitely! In this article, you will get another 3 useful tools to finish web scraping with Java:
- Concurrent Scraping Process
- Headless Browser
- Antidetect Browser
1. Concurrent Scraping Process
The concurrent scraping process is faster and more efficient compared to normal web crawling methods. Don't believe me? You will learn from the following explanation and specific code demonstration:
Site Source Code Analysis
Crawling ScrapeMe as an example to analyze:
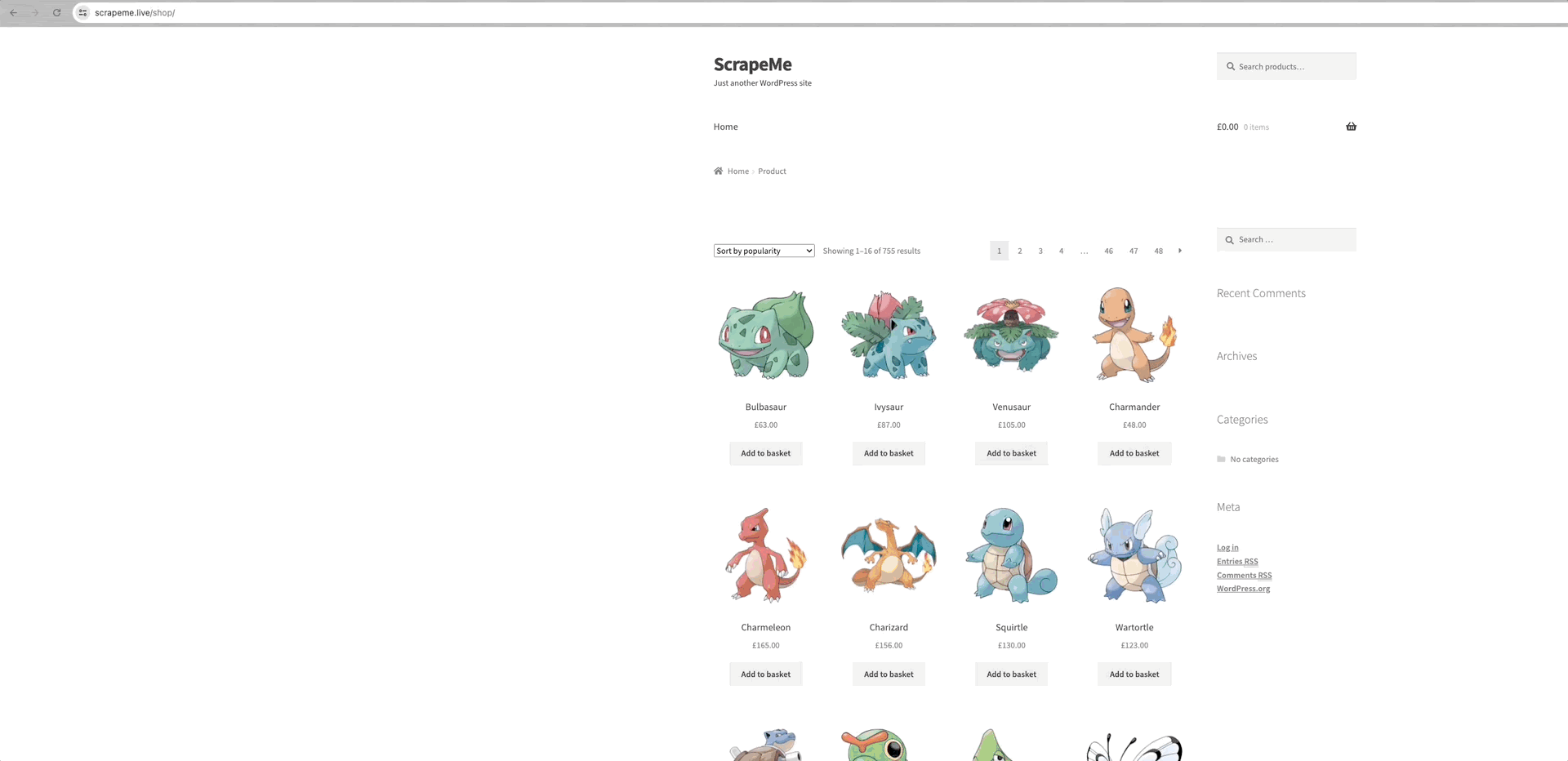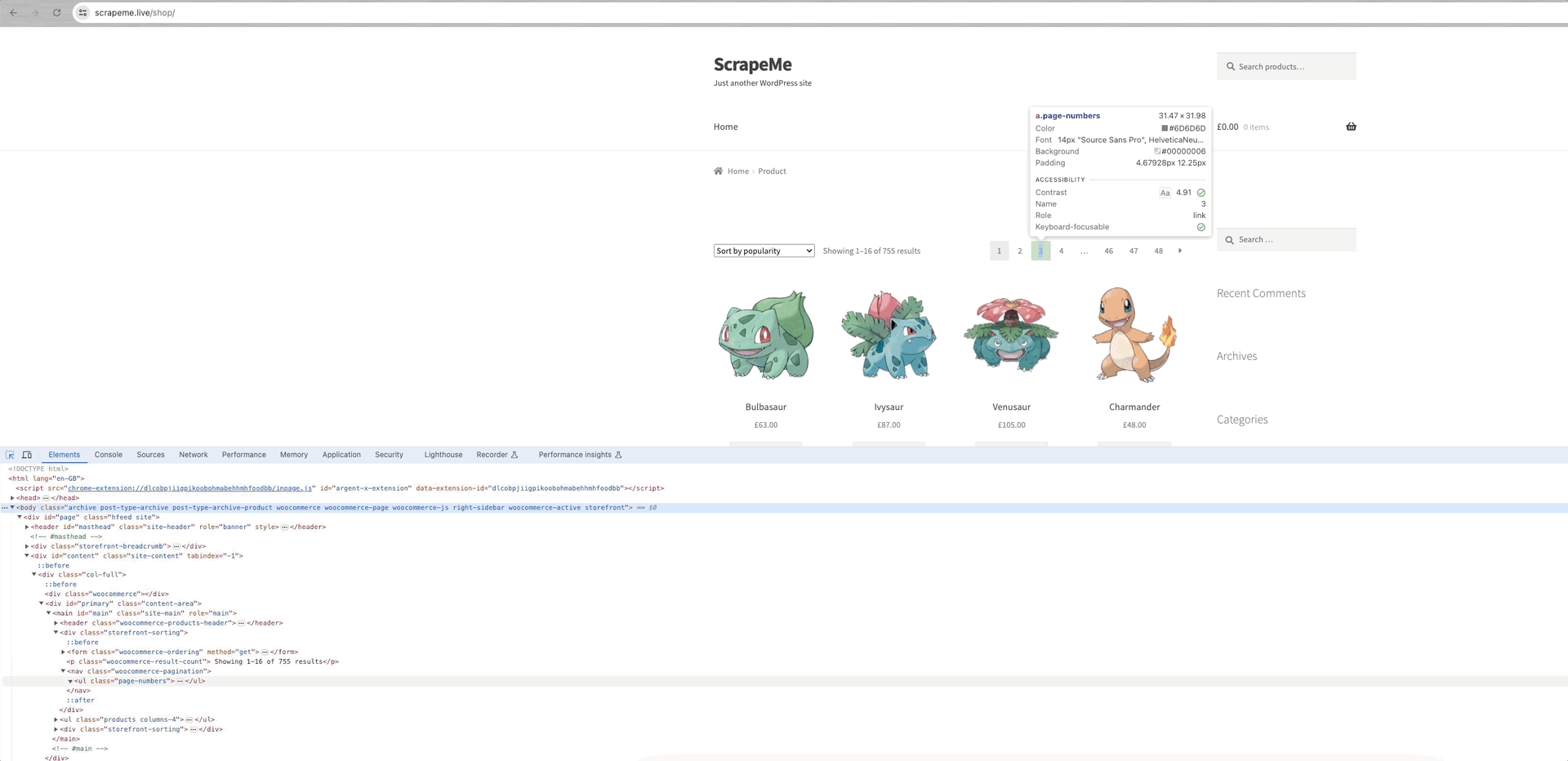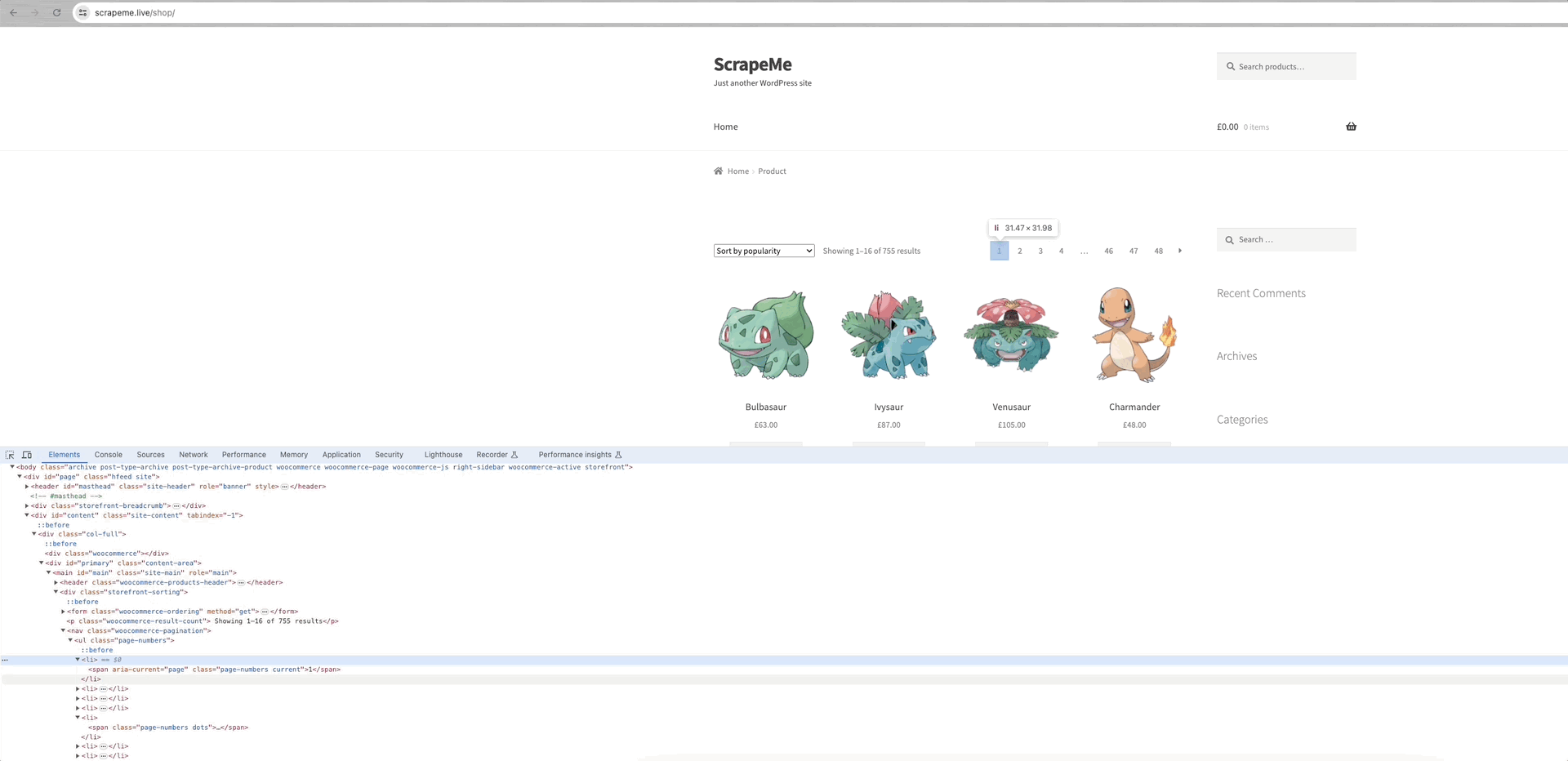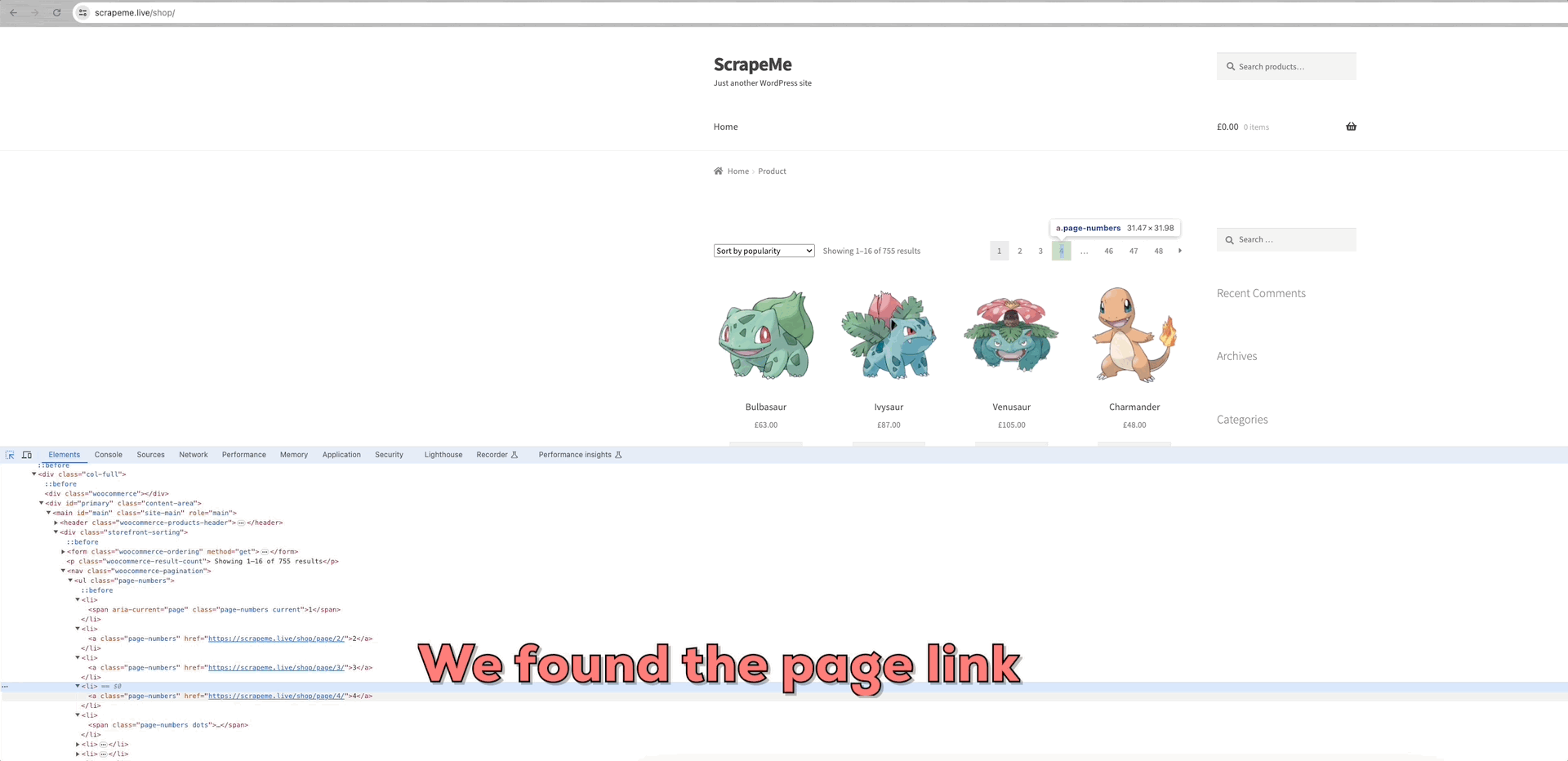
We can see that the links to each page of data are within the a.page-numbers element, and each page's detail is the same. So, we only need to iterate through these pagination links to obtain the links of all other pages.
Then, we can start a separate thread for each page to execute data scraping, thus obtaining all page data. If there are many tasks, we may also need to use a thread pool, configuring the number of threads according to our device.
Coding Demonstration
For the sake of comparison, let's start by operating all the data scraping without using the concurrency method:
Scraper.class
java
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.*;
import java.io.IOException;
import java.util.*;
public class Scraper {
// First page of scrapeme products list
private static final String SCRAPEME_SITE_URL = "https://scrapeme.live/shop";
public static void scrape(List<ScrapeMeProduct> scrapeMeProducts, Set<String> pagesFound, List<String> todoPages) {
// HTML document for scrapeme page
Document doc;
// Remove page from todoPages
String url = todoPages.removeFirst();
try {
doc = Jsoup.connect(url).userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36").header("Accept-Language", "*").get();
// Select product nodes
Elements products = doc.select("li.product");
for (Element product : products) {
ScrapeMeProduct scrapeMeProduct = new ScrapeMeProduct();
scrapeMeProduct.setUrl(product.selectFirst("a").attr("href")); // Parse and set product URL
scrapeMeProduct.setImage(product.selectFirst("img").attr("src")); // Parse and set product image
scrapeMeProduct.setName(product.selectFirst("h2").text()); // Parse and set product name
scrapeMeProduct.setPrice(product.selectFirst("span").text()); // Parse and set product price
scrapeMeProducts.add(scrapeMeProduct);
}
// Add to pages found set
pagesFound.add(url);
Elements paginationElements = doc.select("a.page-numbers");
for (Element pageElement : paginationElements) {
String pageUrl = pageElement.attr("href");
// Add new pages to todoPages
if (!pagesFound.contains(pageUrl) && !todoPages.contains(pageUrl)) {
todoPages.add(pageUrl);
}
// Add to pages found set
pagesFound.add(pageUrl);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static List<ScrapeMeProduct> scrapeAll() {
// Products
List<ScrapeMeProduct> scrapeMeProducts = new ArrayList<>();
// All pages found
Set<String> pagesFound = new HashSet<>();
// Pages list waiting for scrape
List<String> todoPages = new ArrayList<>();
// Add the first page to scrape
todoPages.add(SCRAPEME_SITE_URL);
while (!todoPages.isEmpty()) {
scrape(scrapeMeProducts, pagesFound, todoPages);
}
return scrapeMeProducts;
}
}Main.class
java
import io.xxx.basic.ScrapeMeProduct;
import io.xxx.basic.Scraper;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<ScrapeMeProduct> products = Scraper.scrapeAll();
System.out.println(products.size() + " products scraped");
// Then you can do whatever you want
}
}In the above non-concurrent mode code, we create a list named todoPages to save pending page URLs to be scraped. We loop through it until all pages are scraped. However, during the loop, sequentially executing and waiting for all tasks to finish can take a long time.
How to accelerate our efficiency?
You will be excited that we can optimize web scraping using Java concurrent programming. It helps start multiple threads to execute tasks simultaneously and then merge the results.
Below is the optimized method:
Scraper.class
java
// Duplicates omitted
public static void concurrentScrape() {
// Using synchronized collections
List<ScrapeMeProduct> pokemonProducts = Collections.synchronizedList(new ArrayList<>());
Set<String> pagesDiscovered = Collections.synchronizedSet(new HashSet<>());
List<String> pagesToScrape = Collections.synchronizedList(new ArrayList<>());
pagesToScrape.add(SCRAPEME_SITE_URL);
// New thread pool with CPU cores
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
scrape(pokemonProducts, pagesDiscovered, pagesToScrape);
try {
while (!pagesToScrape.isEmpty()) {
executorService.execute(() -> scrape(pokemonProducts, pagesDiscovered, pagesToScrape));
// Sleep for a while for all pending threads to end
TimeUnit.MILLISECONDS.sleep(300);
}
executorService.shutdown();
executorService.awaitTermination(5, TimeUnit.MINUTES);
} catch (Exception e) {
throw new RuntimeException(e);
}
}In this code, we applied a synchronized collection Collections.synchronizedList and Collections.synchronizedSet to ensure safe access and modification between multiple threads.
Then, we created a thread pool with the same number of threads as CPU cores using Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors()), maximizing system resource utilization.
Finally, we used executorService.awaitTermination method to wait for all tasks in the thread pool to finish.
Running the Program
Results of data scraping:

2. Headless Browser
In the process of web data scraping, headless browsers are becoming increasingly common, especially when dealing with dynamic content or executing JavaScript.
The challenge of traditional scraping tools
The traditional web scraping tools can only retrieve static HTML content and they are unable to execute JavaScript code or simulate user interactions. As a result, with the rise of modern websites using JavaScript technology to dynamically load content or perform interactive operations, traditional web scrapers are facing overwhelming challenges.
To address this challenge, headless browsers have been introduced
A headless browser is a browser without a graphical user interface that can run in the background and execute JavaScript code while providing the same functionality and APIs as regular browsers.
By using a headless browser, we can simulate user behaviors in the browser, including page loading, clicking, form filling, etc., to more accurately scrape web content. In the Java language, Selenium WebDriver and Playwright are popular headless browser driver libraries.
3. Antidetect Browser
Antidetect browser (fingerprint browser) has been regarded as the most effective and safe tool for operating data scraping.
With the development of web security technology, websites are becoming stricter in defending against web scrapers. Traditional scrapers are often easily identified and intercepted, with one of the main identification methods: the browser fingerprint, a special "supervisor" to distinguish between real users and scraper programs.
So, in terms of web scraping, understanding and dealing with fingerprint browsers has become crucial.
What is an antidetect browser?
An antidetect browser is a browser that can simulate real user browser behavior while having unique browser fingerprint features. These features include but are not limited to, user agent strings, screen resolutions, operating system information, plugin lists, language settings, etc. With this information, websites can identify the true identity of visitors. Users of fingerprint browsers customize fingerprint features to hide their real identities.
The main difference between a headless browser and a fingerprint browser
Compared to ordinary headless browsers, antidetect browsers focus more on simulating real user browsing behavior and generating browser fingerprint features similar to real users. The purpose is to bypass website anti-scraping mechanisms and hide the identity of the scraper as much as possible, thereby improving the success rate of scraping. Currently, mainstream antidetect browsers support headless mode.
In the next contents, we will use Selenium WebDriver to refactor our previous scraping business based on actual scraper needs, such as custom fingerprints, bypassing anti-scraping mechanisms, and automatically verifying Cloudflare.
Refactoring with Nstbrowser
Add selenium-java dependency.
bash
// Gradle => build.gradle => dependencies
implementation "org.seleniumhq.selenium:selenium-java:4.14.1"Nstbrowser Can Solve your Problems
Downloading the Nstbrowser fingerprint browser and registering an account, you can enjoy it for free!
The client's functionalities can be experienced, but what we need is automation-related features. You can refer to the API documentation.
- Step 1. Before starting, you need to create a fingerprint and download the corresponding kernel locally.
- Step 2. Download the Chromedriver corresponding to the fingerprint version.
- Step 3. Use the LaunchNewBrowser API to create a fingerprint browser instance.
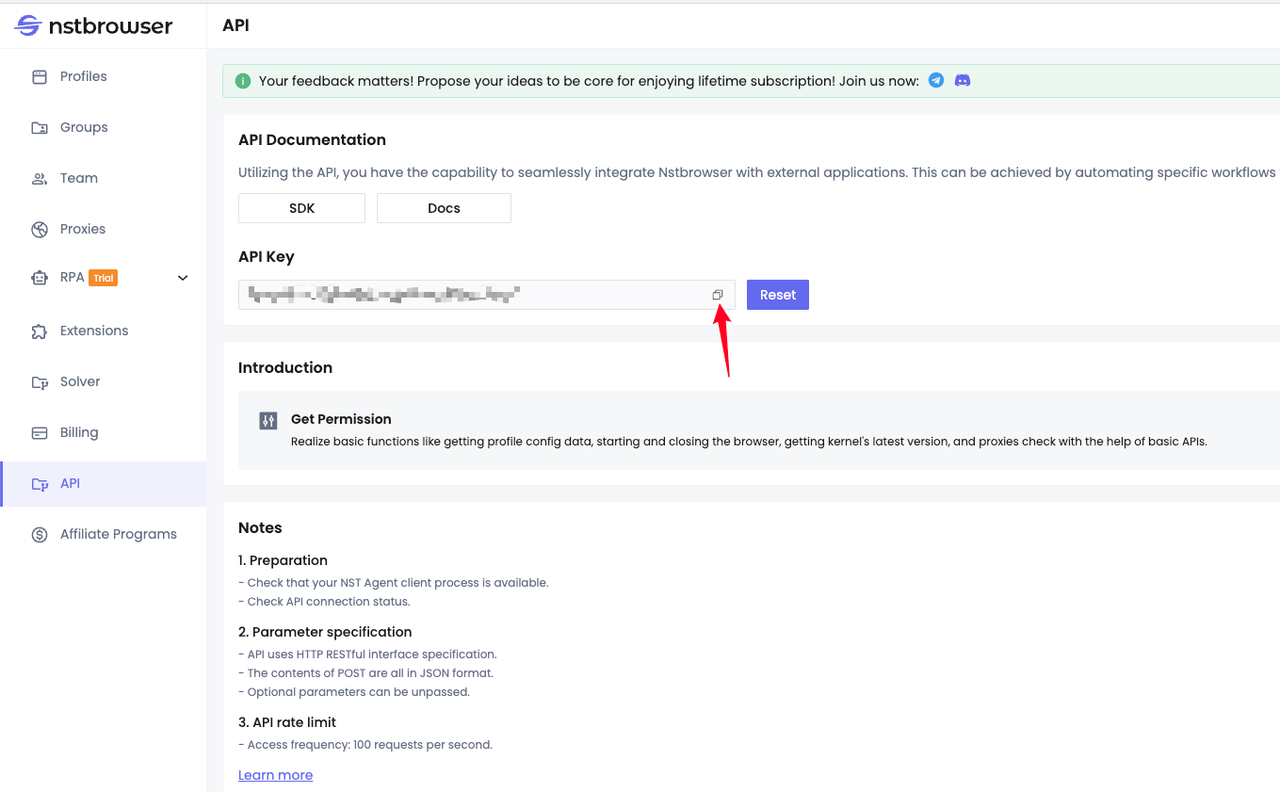
According to the interface documentation, we need to generate and copy our API Key in advance:
Code Demonstration
Scraper.class
java
import io.xxx.basic.ScrapeMeProduct;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.*;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class NstbrowserScraper {
// Scrapeme site URL
private static final String SCRAPEME_SITE_URL = "https://scrapeme.live/shop";
// Nstbrowser LaunchNewBrowser API URL
private static final String NSTBROWSER_LAUNCH_BROWSER_API = "http://127.0.0.1:8848/api/agent/devtool/launch";
/**
* Launches a new browser instance using the Nstbrowser LaunchNewBrowser API.
*/
public static void launchBrowser(String port) throws Exception {
String config = buildLaunchNewBrowserQueryConfig(port);
String launchUrl = NSTBROWSER_LAUNCH_BROWSER_API + "?config=" + config;
URL url = new URL(launchUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
// Set request headers
conn.setRequestProperty("User-Agent", "Mozilla/5.0");
conn.setRequestProperty("Accept-Language", "en-US,en;q=0.5");
conn.setRequestProperty("x-api-key", "your Nstbrowser API key");
conn.setDoOutput(true);
try (BufferedReader in = new BufferedReader(new InputStreamReader(conn.getInputStream()))) {
String inputLine;
StringBuilder response = new StringBuilder();
while ((inputLine = in.readLine()) != null) {
response.append(inputLine);
}
// Deal with response ...
}
}
/**
* Builds the JSON configuration for launching a new browser instance.
*/
private static String buildLaunchNewBrowserQueryConfig(String port) {
String jsonParam = """
{
"once": true,
"headless": false,
"autoClose": false,
"remoteDebuggingPort": %port,
"fingerprint": {
"name": "test",
"kernel": "chromium",
"platform": "mac",
"kernelMilestone": "120",
"hardwareConcurrency": 10,
"deviceMemory": 8
}
}
""";
jsonParam = jsonParam.replace("%port", port);
return URLEncoder.encode(jsonParam, StandardCharsets.UTF_8);
}
/**
* Scrapes product data from the Scrapeme website using Nstbrowser headless browser.
*/
public static List<ScrapeMeProduct> scrape(String port) {
ChromeOptions options = new ChromeOptions();
// Enable headless mode
options.addArguments("--headless");
// Set driver path
System.setProperty("webdriver.chrome.driver", "your chrome webdriver path");
System.setProperty("webdriver.http.factory", "jdk-http-client");
// Create options
// DebuggerAddress
options.setExperimentalOption("debuggerAddress", "127.0.0.1:" + port);
options.addArguments("--remote-allow-origins=*");
WebDriver driver = new ChromeDriver(options);
driver.get(SCRAPEME_SITE_URL);
// Products data
List<ScrapeMeProduct> pokemonProducts = new ArrayList<>();
List<WebElement> products = driver.findElements(By.cssSelector("li.product"));
for (WebElement product : products) {
ScrapeMeProduct pokemonProduct = new ScrapeMeProduct();
pokemonProduct.setUrl(product.findElement(By.tagName("a")).getAttribute("href")); // Parse and set product URL
pokemonProduct.setImage(product.findElement(By.tagName(("img"))).getAttribute("src")); // Parse and set product image
pokemonProduct.setName(product.findElement(By.tagName(("h2"))).getText()); // Parse and set product name
pokemonProduct.setPrice(product.findElement(By.tagName(("span"))).getText()); // Parse and set product price
pokemonProducts.add(pokemonProduct);
}
// Quit browser
driver.quit();
return pokemonProducts;
}
public static void main(String[] args) {
// Browser remote debug port
String port = "9222";
try {
launchBrowser(port);
} catch (Exception e) {
throw new RuntimeException(e);
}
List<ScrapeMeProduct> products = scrape(port);
products.forEach(System.out::println);
}
}The Bottom Lines
This blog briefly describes how to use Java programs for website crawling in concurrent programming and antidetect browsers.
By showing how to use the Nstbrowser anti-detect browser for data scraping and providing detailed code examples, it will surely give you a more in-depth understanding of Java, Headless Browser, and Fingerprint Browser-related information and operations!
More





