
Web Scraping
Web Scraping với Java - Concurrent Scraping, Headless Browser và Anti-Detection Browser
Trong bài viết này, chúng tôi sẽ kết hợp Java với lập trình đồng thời để thu thập dữ liệu từ toàn bộ trang web.
May 07, 2024Carlos Rivera
Trong blog trước của hướng dẫn này, chúng tôi đã cung cấp một ví dụ thành công về việc thu thập dữ liệu từ một trang duy nhất trên trang web Scrapeme bằng Java.
Vậy, có cách nào đặc biệt hơn để thu thập dữ liệu không?
Chính xác! Trong bài viết này, bạn sẽ nhận được 3 công cụ hữu ích khác để hoàn thành việc thu thập dữ liệu trang web bằng Java:
- Quy trình loại bỏ song song
- Trình duyệt không đầu
- Trình duyệt chống phát hiện
1. Quá trình thu thập đồng thời
Quá trình thu thập dữ liệu đồng thời nhanh hơn và hiệu quả hơn so với các phương pháp thu thập dữ liệu web thông thường. Không tin tôi? Qua những lời giải thích và trình diễn mã cụ thể dưới đây, bạn sẽ biết:
Phân tích nguồn trang web
Lấy ScrapeMe làm ví dụ:
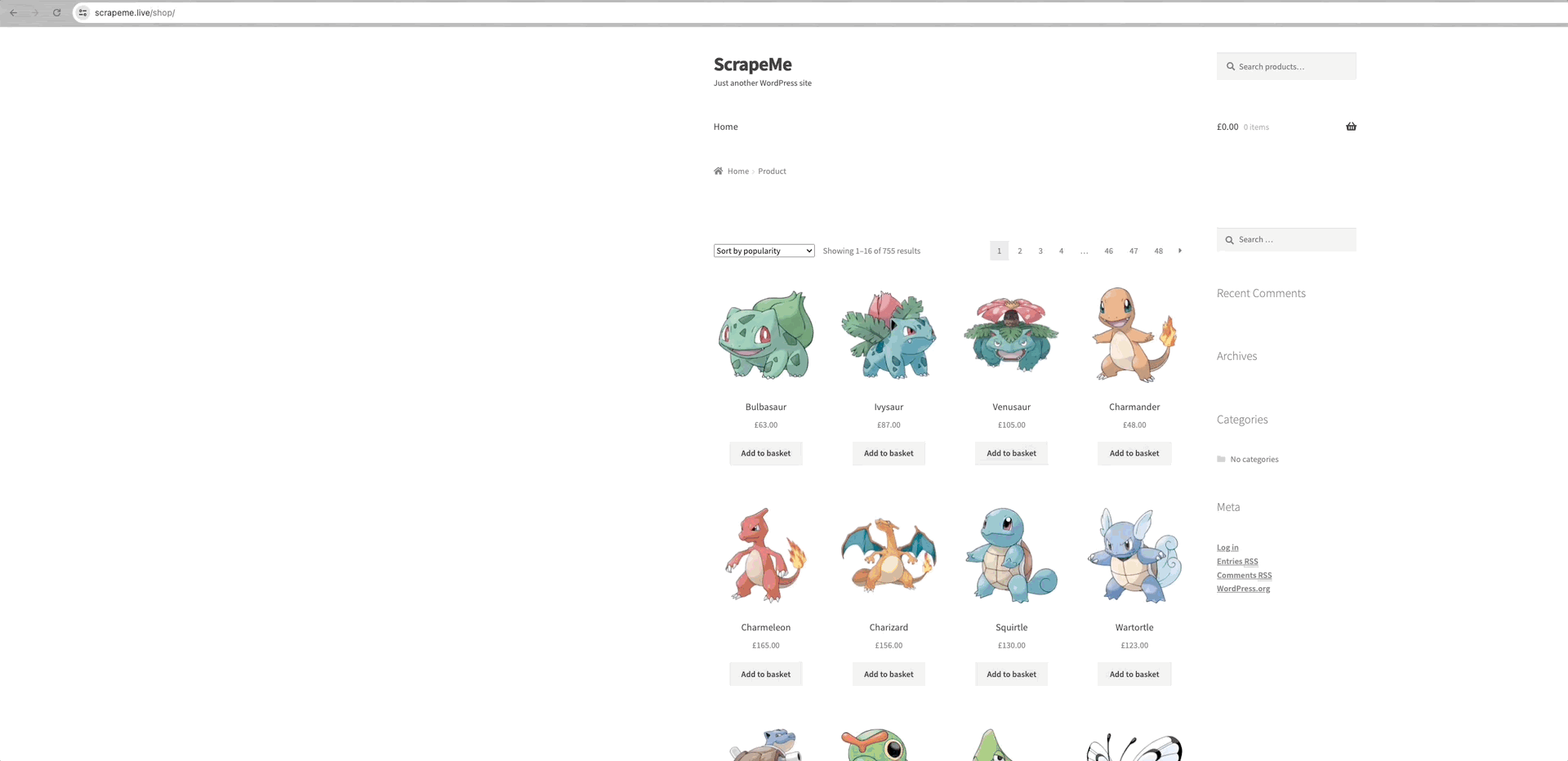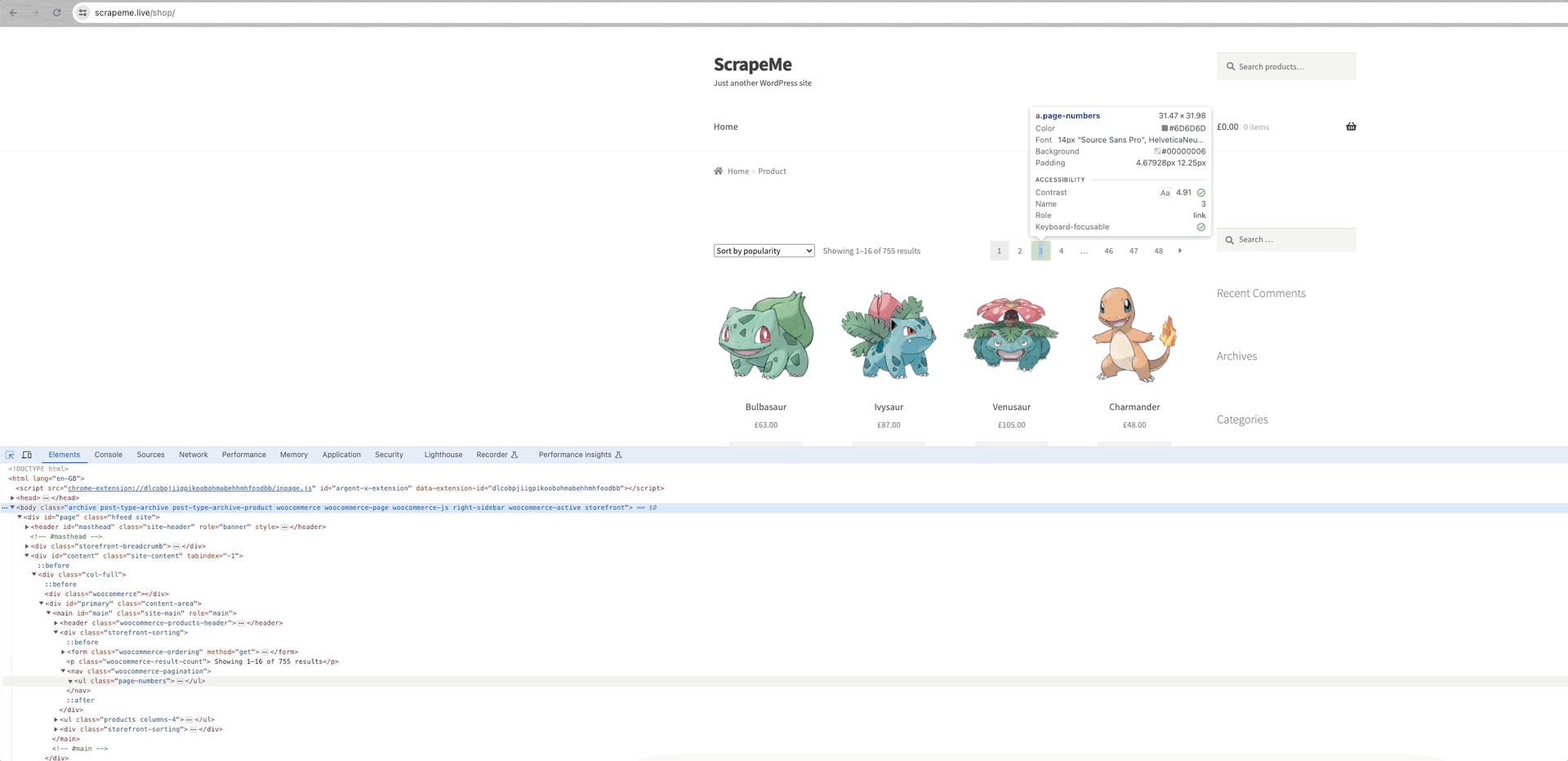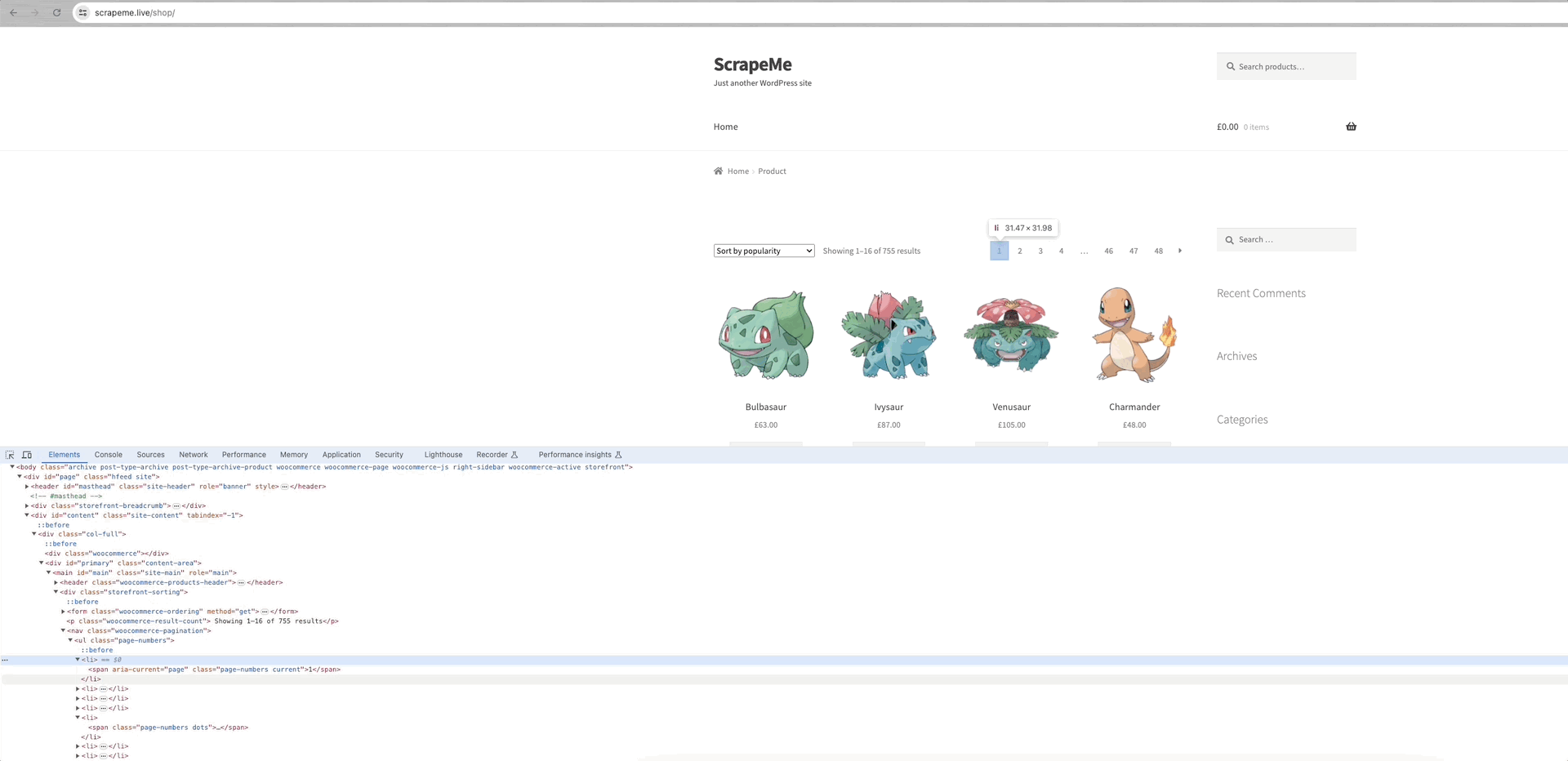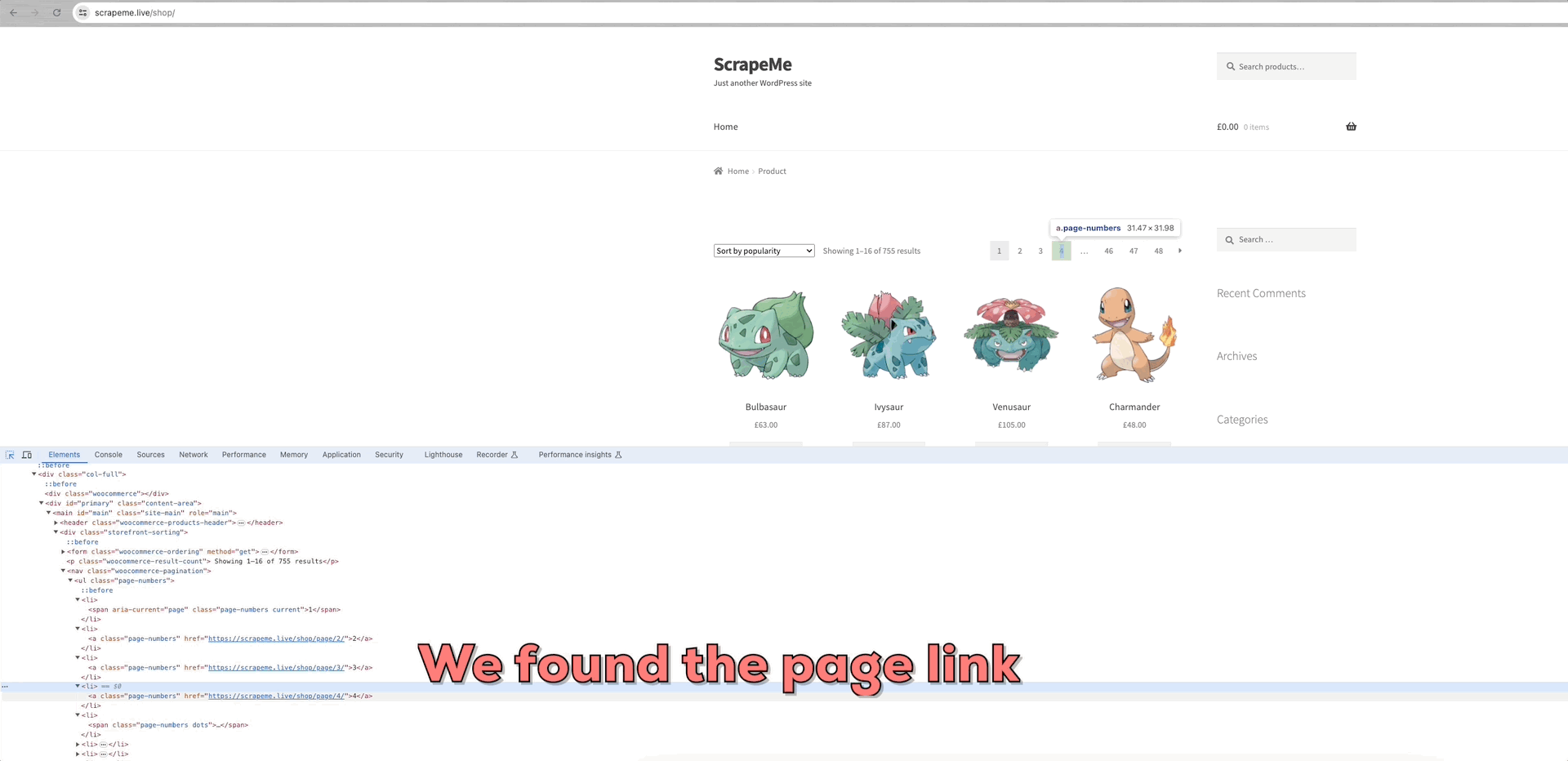
Chúng ta có thể thấy rằng các liên kết đến mỗi trang dữ liệu nằm trong phần tử a.page-numbers và chi tiết của mỗi trang là như nhau. Vì vậy, chúng ta chỉ cần lặp lại các liên kết phân trang này để có được liên kết đến tất cả các trang khác.
Sau đó, chúng ta có thể bắt đầu một luồng riêng biệt cho mỗi trang để thực hiện thu thập dữ liệu, do đó chúng ta có được tất cả dữ liệu trang. Nếu có nhiều tác vụ, chúng ta cũng có thể cần phải sử dụng một nhóm các luồng, cấu hình số lượng các luồng dựa trên thiết bị của chúng ta.
Trình diễn mã hóa
Để so sánh dễ dàng hơn, chúng ta không sử dụng phương thức đồng thời để thao tác tất cả dữ liệu thu thập:
Scraper.class
java
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.*;
import java.io.IOException;
import java.util.*;
public class Scraper {
/**
first page of scrapeme products list
*/
private static final String SCRAPEME_SITE_URL = "https://scrapeme.live/shop";
public static void scrape(List<ScrapeMeProduct> scrapeMeProducts, Set<String> pagesFound, List<String> todoPages) {
// html doc for scrapeme page
Document doc;
// remove page from todoPages
String url = todoPages.removeFirst();
try {
doc = Jsoup.connect(url).userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36").header("Accept-Language", "*").get();
// select product nodes
Elements products = doc.select("li.product");
for (Element product : products) {
ScrapeMeProduct scrapeMeProduct = new ScrapeMeProduct();
scrapeMeProduct.setUrl(product.selectFirst("a").attr("href")); // parse and set product url
scrapeMeProduct.setImage(product.selectFirst("img").attr("src")); // parse and set product image
scrapeMeProduct.setName(product.selectFirst("h2").text()); // parse and set product name
scrapeMeProduct.setPrice(product.selectFirst("span").text()); // parse and set product price
scrapeMeProducts.add(scrapeMeProduct);
}
// add to pages found set
pagesFound.add(url);
Elements paginationElements = doc.select("a.page-numbers");
for (Element pageElement : paginationElements) {
String pageUrl = pageElement.attr("href");
// add new pages to todoPages
if (!pagesFound.contains(pageUrl) && !todoPages.contains(pageUrl)) {
todoPages.add(pageUrl);
}
// add to pages found set
pagesFound.add(pageUrl);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static List<ScrapeMeProduct> scrapeAll() {
// products
List<ScrapeMeProduct> scrapeMeProducts = new ArrayList<>();
// all pages found
Set<String> pagesFound = new HashSet<>();
// pages list waiting for scrape
List<String> todoPages = new ArrayList<>();
// add the first page to scrape
todoPages.add(SCRAPEME_SITE_URL);
while (!todoPages.isEmpty()) {
scrape(scrapeMeProducts, pagesFound, todoPages);
}
return scrapeMeProducts;
}
}Main.class
java
import io.xxx.basic.ScrapeMeProduct;
import io.xxx.basic.Scraper;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<ScrapeMeProduct> products = Scraper.scrapeAll();
System.out.println(products.size() + " products scraped");
// then you can do whatever you want
}
}Trong mã chế độ không đồng thời ở trên, chúng tôi tạo một danh sách được gọi là todoPages để lưu URL của trang được thu thập dữ liệu. Chúng tôi lặp đi lặp lại nó cho đến khi tất cả các trang bị cạo. Tuy nhiên, trong chu kỳ, có thể mất một thời gian dài để thực hiện tuần tự và chờ cho tất cả các nhiệm vụ hoàn thành.
Làm thế nào để tăng tốc hiệu quả của chúng tôi?
Bạn sẽ rất hào hứng vì chúng tôi có thể sử dụng lập trình đồng thời Java để tối ưu hóa việc thu thập dữ liệu trang web. Nó giúp bắt đầu nhiều luồng để thực hiện các tác vụ cùng một lúc và sau đó kết hợp kết quả.
Đây là những gì bạn sẽ làm sau khi tối ưu hóa:
Scraper.class
lava
// duplicates omitted
public static void concurrentScrape() {
// using synchronized collections
List<ScrapeMeProduct> pokemonProducts = Collections.synchronizedList(new ArrayList<>());
Set<String> pagesDiscovered = Collections.synchronizedSet(new HashSet<>());
List<String> pagesToScrape = Collections.synchronizedList(new ArrayList<>());
pagesToScrape.add(SCRAPEME_SITE_URL);
// new thread pool with CPU cores
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
scrape(pokemonProducts, pagesDiscovered, pagesToScrape);
try {
while (!pagesToScrape.isEmpty()) {
executorService.execute(() -> scrape(pokemonProducts, pagesDiscovered, pagesToScrape));
// sleep for a while for all pending threads to end
TimeUnit.MILLISECONDS.sleep(300);
}
executorService.shutdown();
executorService.awaitTermination(5, TimeUnit.MINUTES);
} catch (Exception e) {
throw new RuntimeException(e);
}
}Trong đoạn mã này, chúng tôi đã áp dụng bộ sưu tập đồng bộ Collections.synchronizedList và Collections.synchronizedSet để đảm bảo truy cập và sửa đổi an toàn giữa nhiều luồng.
Sau đó, chúng tôi sử dụng Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors()) để tạo ra một nhóm các luồng có cùng số lượng luồng như lõi CPU, tối đa hóa việc sử dụng tài nguyên hệ thống.
Cuối cùng, chúng ta sử dụng phương thức executorService.awaitTermination để chờ cho tất cả các tác vụ trong thread pool hoàn thành.
Chạy chương trình
Kết quả chạy:

2. Trình duyệt Headless
Các trình duyệt headless ngày càng trở nên phổ biến trong quá trình thu thập dữ liệu web, đặc biệt là khi xử lý nội dung động hoặc thực thi JavaScript.
Thách thức của các công cụ leo truyền thống
Công cụ thu thập dữ liệu trang web truyền thống chỉ có thể truy xuất nội dung HTML tĩnh và không thể thực thi mã JavaScript hoặc mô phỏng tương tác người dùng. Do đó, với sự gia tăng của các trang web hiện đại sử dụng công nghệ JavaScript để tải nội dung động hoặc thực hiện các hành động tương tác, các trình thu thập thông tin web truyền thống phải đối mặt với những thách thức lớn.
Để đối phó với thách thức này, Headless Browser đã được giới thiệu
Headless Browser là một trình duyệt không có giao diện người dùng đồ họa có thể chạy và thực thi mã JavaScript trong nền trong khi cung cấp các tính năng và API tương tự như các trình duyệt thông thường.
Bằng cách sử dụng trình duyệt Headless, chúng tôi có thể mô phỏng hành vi của người dùng trong trình duyệt của chúng tôi, bao gồm tải trang, nhấp chuột, điền biểu mẫu, v.v., để thu thập dữ liệu chính xác hơn về nội dung trang web. Trong ngôn ngữ Java, Selenium WebDriver và Playwright là các thư viện trình điều khiển trình duyệt không đầu phổ biến.
3. Trình duyệt vân tay
Anti-Detection Browser (trình duyệt vân tay) được coi là công cụ thu thập dữ liệu hiệu quả và an toàn nhất.
Cùng với sự phát triển của công nghệ an ninh mạng, các trang web cũng ngày càng nghiêm ngặt trong việc phòng thủ chống lại các loài bò sát mạng. Các trình thu thập thông tin truyền thống có xu hướng dễ dàng nhận ra và bị chặn, và một trong những phương pháp nhận dạng chính là: dấu vân tay trình duyệt, một "người giám sát" đặc biệt để phân biệt người dùng thực và chương trình thu thập thông tin.
Do đó, nó trở nên quan trọng để hiểu và xử lý trình duyệt vân tay khi nói đến thu thập dữ liệu trang web.
Anti-Detection Browser là gì?
Anti-Detection Browser là một trình duyệt có thể mô phỏng hành vi trình duyệt của người dùng thực trong khi có dấu vân tay trình duyệt độc đáo. Các tính năng này bao gồm nhưng không giới hạn ở chuỗi tác nhân người dùng, độ phân giải màn hình, thông tin hệ điều hành, danh sách plugin, cài đặt ngôn ngữ và hơn thế nữa. Sử dụng thông tin này, trang web có thể xác định danh tính thực sự của khách truy cập. Người dùng trình duyệt vân tay có thể tùy chỉnh dấu vân tay để ẩn danh tính thực của họ.
Sự khác biệt chính giữa Headless Browser và Fingerprint Browser
So với các trình duyệt không đầu thông thường, trình duyệt Anti-Detection tập trung nhiều hơn vào việc mô phỏng hành vi duyệt web của người dùng thực, tạo ra các dấu vân tay trình duyệt tương tự như người dùng thực. Mục đích là để vượt qua cơ chế chống thu thập dữ liệu của trang web và che giấu danh tính của người thu thập dữ liệu càng nhiều càng tốt, do đó tăng tỷ lệ thành công của việc thu thập dữ liệu. Các trình duyệt Anti-Detection hiện nay đều hỗ trợ chế độ headless.
Trong phần tiếp theo, chúng tôi sẽ sử dụng Selenium WebDriver để tái cấu trúc hoạt động thu thập dữ liệu trước đây của chúng tôi dựa trên nhu cầu thu thập dữ liệu thực tế, chẳng hạn như tùy chỉnh dấu vân tay, bỏ qua cơ chế chống thu thập dữ liệu, tự động xác thực Cloudflare, v.v.
3. Trình duyệt vân tay Nstbrowser
Tải xuống Nstbrowser Fingerprint Browser và đăng ký tài khoản để thưởng thức miễn phí!
Có thể trải nghiệm các chức năng của khách hàng, nhưng những gì chúng ta cần là các chức năng liên quan đến tự động hóa. Bạn có thể tham khảo tài liệu API.
- Bước 1. Trước khi bắt đầu, bạn cần tạo dấu vân tay và tải xuống hạt nhân tương ứng cục bộ.
- Bước 2. Tải xuống Chromedriver tương ứng với phiên bản vân tay.
- Bước 3. Sử dụng API LaunchNewBrowser để tạo một phiên bản trình duyệt vân tay.
Dựa trên tài liệu giao diện, chúng ta cần tạo và sao chép khóa API của mình trước thời hạn:
Mã Demo
Scraper.class
java
import io.xxx.basic.ScrapeMeProduct;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.*;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class NstbrowserScraper {
// Scrapeme site URL
private static final String SCRAPEME_SITE_URL = "https://scrapeme.live/shop";
// Nstbrowser LaunchNewBrowser API URL
private static final String NSTBROWSER_LAUNCH_BROWSER_API = "http://127.0.0.1:8848/api/agent/devtool/launch";
/**
* Launches a new browser instance using the Nstbrowser LaunchNewBrowser API.
*/
public static void launchBrowser(String port) throws Exception {
String config = buildLaunchNewBrowserQueryConfig(port);
String launchUrl = NSTBROWSER_LAUNCH_BROWSER_API + "?config=" + config;
URL url = new URL(launchUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
// Set request headers
conn.setRequestProperty("User-Agent", "Mozilla/5.0");
conn.setRequestProperty("Accept-Language", "en-US,en;q=0.5");
conn.setRequestProperty("x-api-key", "your Nstbrowser API key");
conn.setDoOutput(true);
try (BufferedReader in = new BufferedReader(new InputStreamReader(conn.getInputStream()))) {
String inputLine;
StringBuilder response = new StringBuilder();
while ((inputLine = in.readLine()) != null) {
response.append(inputLine);
}
// Deal with response ...
}
}
/**
* Builds the JSON configuration for launching a new browser instance.
*/
private static String buildLaunchNewBrowserQueryConfig(String port) {
String jsonParam = """
{
"once": true,
"headless": false,
"autoClose": false,
"remoteDebuggingPort": %port,
"fingerprint": {
"name": "test",
"kernel": "chromium",
"platform": "mac",
"kernelMilestone": "120",
"hardwareConcurrency": 10,
"deviceMemory": 8
}
}
""";
jsonParam = jsonParam.replace("%port", port);
return URLEncoder.encode(jsonParam, StandardCharsets.UTF_8);
}
/**
* Scrapes product data from the Scrapeme website using Nstbrowser headless browser.
*/
public static List<ScrapeMeProduct> scrape(String port) {
ChromeOptions options = new ChromeOptions();
// Enable headless mode
options.addArguments("--headless");
// Set driver path
System.setProperty("webdriver.chrome.driver", "your chrome webdriver path");
System.setProperty("webdriver.http.factory", "jdk-http-client");
// Create options
// DebuggerAddress
options.setExperimentalOption("debuggerAddress", "127.0.0.1:" + port);
options.addArguments("--remote-allow-origins=*");
WebDriver driver = new ChromeDriver(options);
driver.get(SCRAPEME_SITE_URL);
// Products data
List<ScrapeMeProduct> pokemonProducts = new ArrayList<>();
List<WebElement> products = driver.findElements(By.cssSelector("li.product"));
for (WebElement product : products) {
ScrapeMeProduct pokemonProduct = new ScrapeMeProduct();
pokemonProduct.setUrl(product.findElement(By.tagName("a")).getAttribute("href")); // Parse and set product URL
pokemonProduct.setImage(product.findElement(By.tagName(("img"))).getAttribute("src")); // Parse and set product image
pokemonProduct.setName(product.findElement(By.tagName(("h2"))).getText()); // Parse and set product name
pokemonProduct.setPrice(product.findElement(By.tagName(("span"))).getText()); // Parse and set product price
pokemonProducts.add(pokemonProduct);
}
// Quit browser
driver.quit();
return pokemonProducts;
}
public static void main(String[] args) {
// Browser remote debug port
String port = "9222";
try {
launchBrowser(port);
} catch (Exception e) {
throw new RuntimeException(e);
}
List<ScrapeMeProduct> products = scrape(port);
products.forEach(System.out::println);
}
}Điểm mấu chốt
Blog này cung cấp một cái nhìn ngắn gọn về cách thu thập dữ liệu trang web bằng cách sử dụng chương trình Java trong trình duyệt lập trình đồng thời và chống phát hiện.
Bằng cách chỉ cho bạn cách sử dụng trình duyệt chống phát hiện Nstbrowser để thu thập dữ liệu và cung cấp các ví dụ mã chi tiết, nó chắc chắn sẽ cung cấp cho bạn cái nhìn sâu sắc hơn về thông tin và hành động liên quan đến Java, trình duyệt không đầu và trình duyệt vân tay!
Hơn





