
Web Scraping
Web Scraping con Java - Crawling concurrente, navegador sin cabeza y navegador anti-intección
En este artículo vamos a combinar la programación concurrente Java para rastrear todos los datos del sitio .
May 07, 2024Carlos Rivera
En el blog anterior de este tutorial, proporcionamos un ejemplo exitoso del uso de Java para rastrear datos de una sola página en el sitio Scrapeme.
Entonces, ¿hay una forma más específica de rastrear datos?
Sí, la hay. En este artículo, obtendrá 3 herramientas más útiles para hacer rastreo web utilizando Java:
- Proceso de raspado concurrente
- Navegador sin cabeza
- Navegador antidetección
1. Proceso de rastreo concurrente
El proceso de rastreo concurrente es más rápido y eficiente que los métodos normales de rastreo web. ¿No me cree? Lo aprenderá a través de la siguiente explicación y demostración de código específico:
Análisis del código fuente del sitio
Tomemos como ejemplo de análisis el rastreo de ScrapeMe:
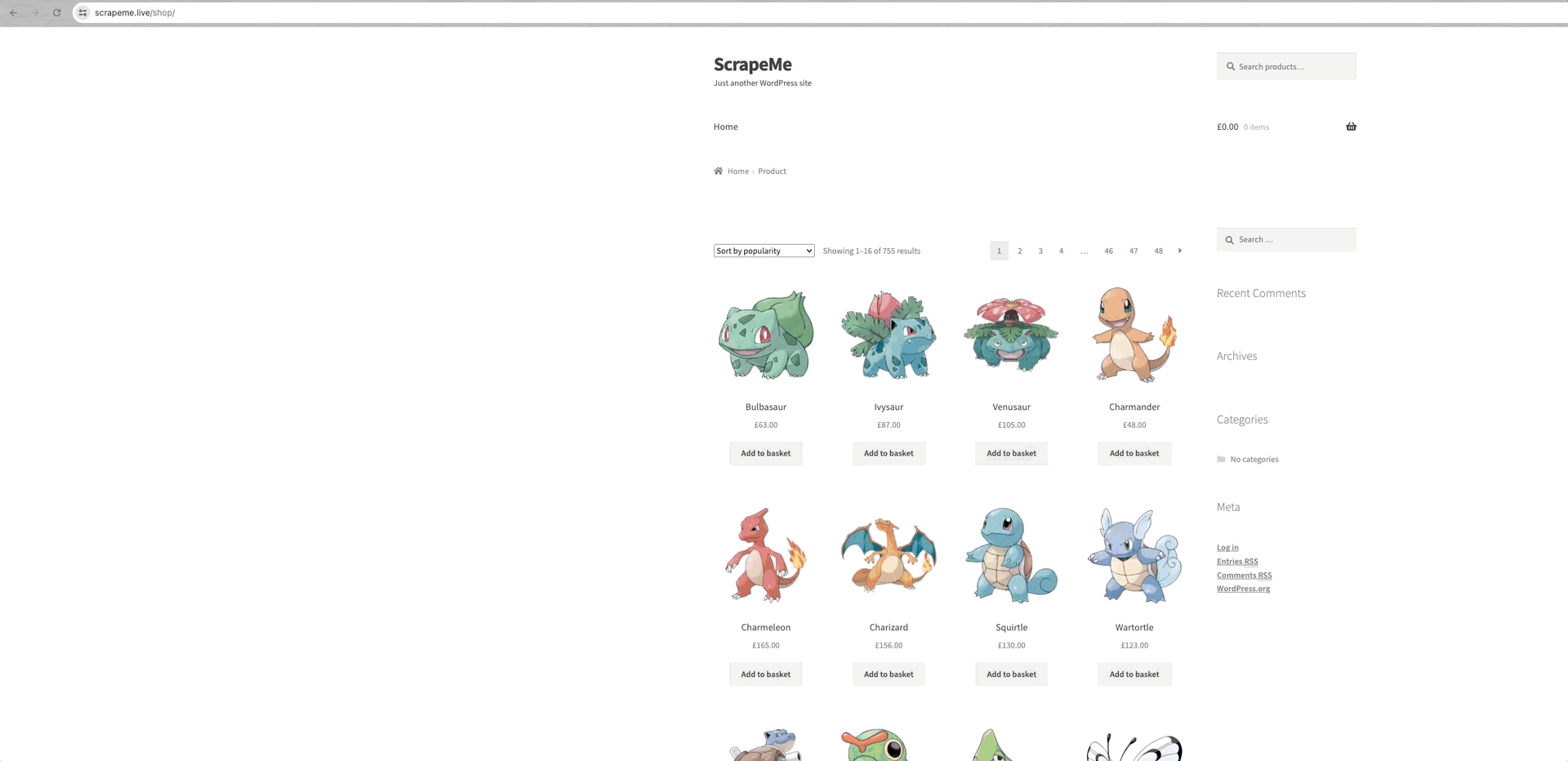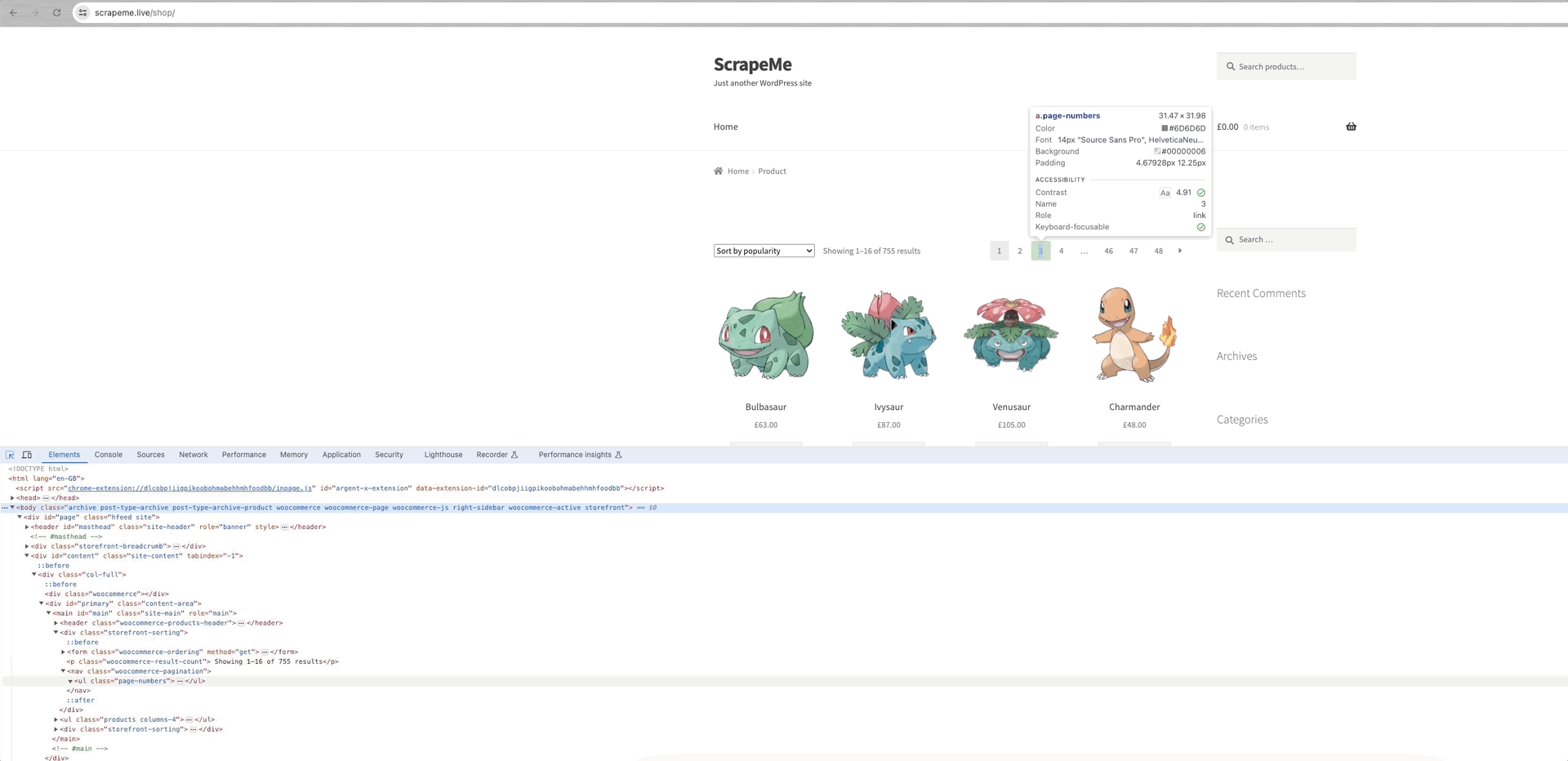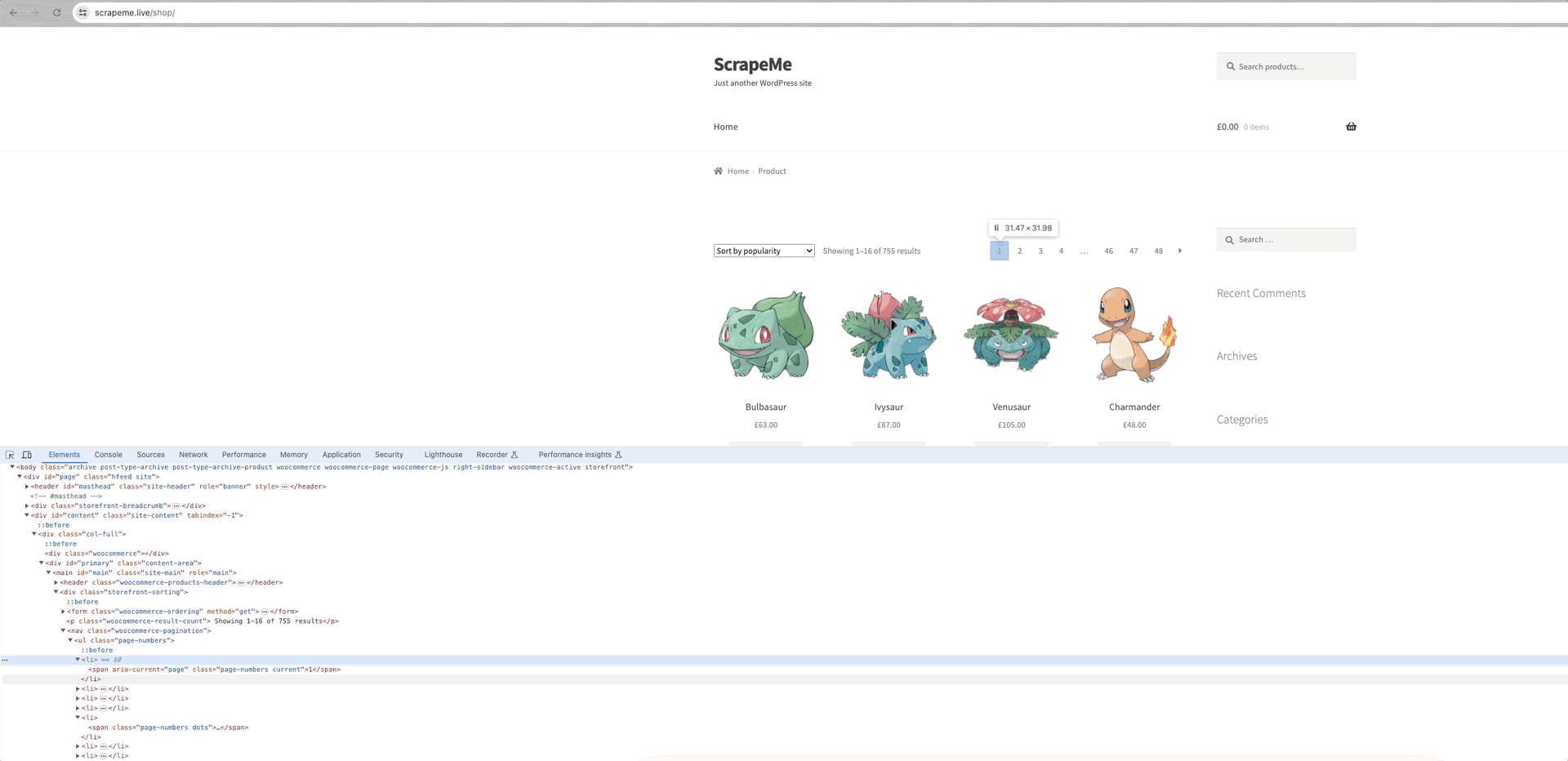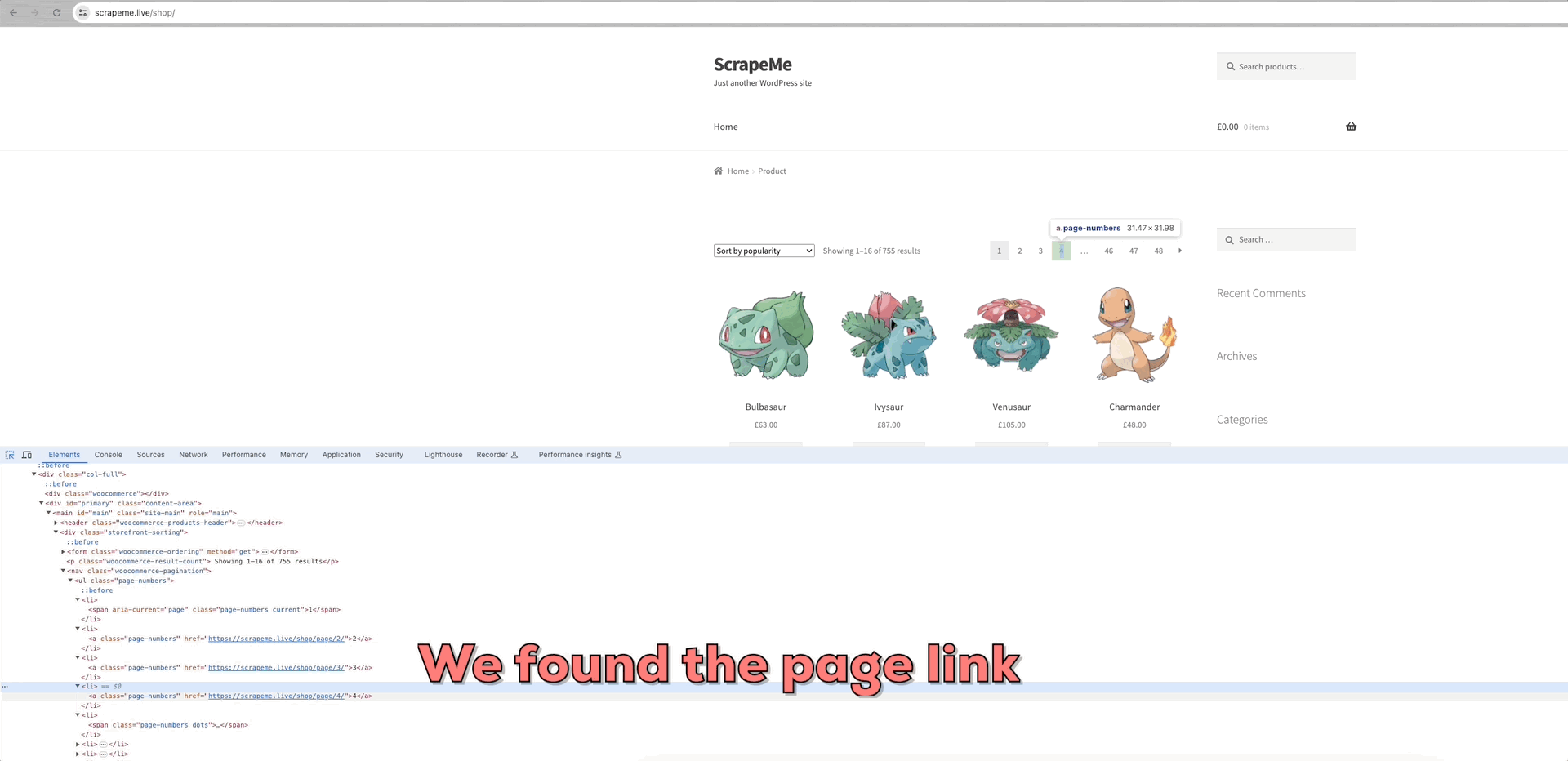
Podemos ver que los enlaces a cada una de las páginas de datos están dentro del elemento a.page-numbers y los detalles son los mismos para cada página. Por lo tanto, sólo tenemos que iterar sobre estos enlaces paginados para obtener los enlaces a todas las demás páginas.
A continuación, podemos iniciar un hilo separado para cada página para realizar el rastreo de datos para obtener todos los datos de la página. Si hay muchas tareas, es posible que necesitemos utilizar un pool de hilos para configurar el número de hilos según nuestro dispositivo.
Demostración de codificación
A modo de comparación, vamos a realizar primero todas las capturas de datos sin utilizar concurrencia:
Scraper.class
java
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.*;
import java.io.IOException;
import java.util.*;
public class Scraper {
/**
first page of scrapeme products list
*/
private static final String SCRAPEME_SITE_URL = "https://scrapeme.live/shop";
public static void scrape(List<ScrapeMeProduct> scrapeMeProducts, Set<String> pagesFound, List<String> todoPages) {
// html doc for scrapeme page
Document doc;
// remove page from todoPages
String url = todoPages.removeFirst();
try {
doc = Jsoup.connect(url).userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36").header("Accept-Language", "*").get();
// select product nodes
Elements products = doc.select("li.product");
for (Element product : products) {
ScrapeMeProduct scrapeMeProduct = new ScrapeMeProduct();
scrapeMeProduct.setUrl(product.selectFirst("a").attr("href")); // parse and set product url
scrapeMeProduct.setImage(product.selectFirst("img").attr("src")); // parse and set product image
scrapeMeProduct.setName(product.selectFirst("h2").text()); // parse and set product name
scrapeMeProduct.setPrice(product.selectFirst("span").text()); // parse and set product price
scrapeMeProducts.add(scrapeMeProduct);
}
// add to pages found set
pagesFound.add(url);
Elements paginationElements = doc.select("a.page-numbers");
for (Element pageElement : paginationElements) {
String pageUrl = pageElement.attr("href");
// add new pages to todoPages
if (!pagesFound.contains(pageUrl) && !todoPages.contains(pageUrl)) {
todoPages.add(pageUrl);
}
// add to pages found set
pagesFound.add(pageUrl);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static List<ScrapeMeProduct> scrapeAll() {
// products
List<ScrapeMeProduct> scrapeMeProducts = new ArrayList<>();
// all pages found
Set<String> pagesFound = new HashSet<>();
// pages list waiting for scrape
List<String> todoPages = new ArrayList<>();
// add the first page to scrape
todoPages.add(SCRAPEME_SITE_URL);
while (!todoPages.isEmpty()) {
scrape(scrapeMeProducts, pagesFound, todoPages);
}
return scrapeMeProducts;
}
}Main.class
java
import io.xxx.basic.ScrapeMeProduct;
import io.xxx.basic.Scraper;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<ScrapeMeProduct> products = Scraper.scrapeAll();
System.out.println(products.size() + " products scraped");
// then you can do whatever you want
}
}En el código de modo no concurrente anterior, creamos una lista llamada todoPages que contiene las URL de las páginas que se van a raspar. Hacemos un bucle a través de ella hasta que todas las páginas han sido raspadas. Sin embargo, durante el bucle, puede llevar mucho tiempo ejecutar secuencialmente y esperar a que se completen todas las tareas.
¿Cómo podemos acelerar nuestra eficiencia?
Le encantará saber que podemos utilizar la programación concurrente de Java para optimizar el raspado web. Ayuda a iniciar múltiples hilos para ejecutar tareas simultáneamente y luego fusionar los resultados.
Este es el método optimizado:
Scraper.class
java
// duplicates omitted
public static void concurrentScrape() {
// using synchronized collections
List<ScrapeMeProduct> pokemonProducts = Collections.synchronizedList(new ArrayList<>());
Set<String> pagesDiscovered = Collections.synchronizedSet(new HashSet<>());
List<String> pagesToScrape = Collections.synchronizedList(new ArrayList<>());
pagesToScrape.add(SCRAPEME_SITE_URL);
// new thread pool with CPU cores
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
scrape(pokemonProducts, pagesDiscovered, pagesToScrape);
try {
while (!pagesToScrape.isEmpty()) {
executorService.execute(() -> scrape(pokemonProducts, pagesDiscovered, pagesToScrape));
// sleep for a while for all pending threads to end
TimeUnit.MILLISECONDS.sleep(300);
}
executorService.shutdown();
executorService.awaitTermination(5, TimeUnit.MINUTES);
} catch (Exception e) {
throw new RuntimeException(e);
}
}En este código, hemos aplicado las colecciones sincronizadas Collections.synchronizedList y Collections.synchronizedSet para garantizar el acceso seguro y la modificación entre múltiples hilos.
A continuación, utilizamos Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors()) para crear un pool de hilos con el mismo número de hilos que el número de núcleos de CPU para maximizar la utilización de los recursos del sistema.
Por último, utilizamos el método executionService.awaitTermination para esperar a que se completen todas las tareas del pool.
Ejecutar el programa
Comprueba los resultados:

2. Navegadores sin cabeza
Los navegadores sin cabeza son cada vez más habituales durante el rastreo de datos web, especialmente cuando se trabaja con contenidos dinámicos o se ejecuta JavaScript.
Desafíos de las herramientas de rastreo tradicionales
Los rastreadores web tradicionales sólo pueden recuperar contenido HTML estático y no pueden ejecutar código JavaScript ni simular interacciones del usuario. Por tanto, con el auge de los sitios web modernos que utilizan tecnología JavaScript para cargar contenidos dinámicamente o realizar acciones interactivas, los rastreadores web tradicionales se enfrentan a un enorme desafío.
Para hacer frente a este reto, se introdujeron los navegadores sin cabeza (headless browsers)
Un navegador headless es un navegador sin interfaz gráfica de usuario que ejecuta código JavaScript en segundo plano y ofrece las mismas funciones y API que un navegador normal.
Al utilizar un navegador sin cabeza, podemos simular los comportamientos del usuario en el navegador, incluida la carga de páginas, los clics, la cumplimentación de formularios, etc., con el fin de capturar el contenido web con mayor precisión. En el lenguaje Java, Selenium WebDriver y Playwright son librerías populares de controladores de navegadores sin cabeza.
3. Navegador de huellas dactilares
Los navegadores antidetección (navegadores de huellas dactilares) se consideran las herramientas de rastreo de datos más eficaces y seguras.
Con el desarrollo de la tecnología de seguridad web, los sitios web son cada vez más estrictos en sus defensas contra los rastreadores web. Los rastreadores tradicionales suelen ser fáciles de identificar e interceptar, y uno de los principales métodos de identificación es: la huella digital del navegador, un "perro guardián" especial que distingue entre usuarios reales y rastreadores.
Entender y tratar con navegadores con huellas dactilares se ha convertido, por tanto, en algo crucial en el contexto del rastreo web.
¿Qué es un navegador antidetección?
Un navegador antidetección es un navegador que imita el comportamiento del navegador de un usuario real y tiene características únicas de huella digital del navegador. Estas características incluyen, entre otras, cadenas de agente de usuario, resolución de pantalla, información sobre el sistema operativo, listas de complementos, configuración de idioma, etcétera. Con esta información, los sitios web pueden identificar la verdadera identidad de los visitantes. Los usuarios de navegadores con huella digital pueden personalizar sus características para ocultar su verdadera identidad.
Principales diferencias entre los navegadores sin huella digital y los navegadores con huella digital
En comparación con los navegadores sin cabeza normales, los navegadores antidetección se centran más en simular el comportamiento de navegación de los usuarios reales y generar características de huellas dactilares del navegador similares a las de los usuarios reales. El objetivo es eludir el mecanismo anti rastreo del sitio web y ocultar la identidad del rastreador en la medida de lo posible, con el fin de mejorar la tasa de éxito del rastreo. Actualmente, los principales navegadores antidetección admiten el modo headless.
En la siguiente sección, utilizaremos Selenium WebDriver para reconstruir nuestra actividad de rastreo anterior de acuerdo con los requisitos de rastreo reales, como las huellas dactilares personalizadas, eludir los mecanismos anti rastreo, verificar automáticamente Cloudflare, etc.
Refactorización de la huella digital del navegador con Nstbrowser
Añadir dependencia selenium-java
bash
// gradle => build.gradle => dependencies
implementation "org.seleniumhq.selenium:selenium-java:4.14.1"Descarga y configuración de Nstbrowser
Descargando el navegador de huellas dactilares Nstbrowser y registrando una cuenta, ¡podrás disfrutarlo gratis!
La funcionalidad del lado del cliente está disponible para experimentar, pero necesitamos funcionalidad relacionada con la automatización. Puedes consultar la documentación de la API.
- Paso 1. Antes de empezar, necesitas crear la huella digital y descargar el kernel correspondiente localmente.
- Paso 2. Descarga el Chromedriver correspondiente a la versión del fingerprint.
- Paso 3. Utiliza la API LaunchNewBrowser para crear la instancia del navegador de huellas dactilares.
De acuerdo con la documentación de la interfaz, necesitamos generar y copiar nuestra API Key por adelantado:
Código Demo
Scraper.class
java
import io.xxx.basic.ScrapeMeProduct;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.*;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class NstbrowserScraper {
// scrapeme site url
private static final String SCRAPEME_SITE_URL = "https://scrapeme.live/shop";
// Nstbrowser LaunchNewBrowser api url
private static final String NSTBROWSER_LAUNCH_BROWSER_API = "http://127.0.0.1:8848/api/agent/devtool/launch";
/**
* Launches a new browser instance using the Nstbrowser LaunchNewBrowser API.
*/
public static void launchBrowser(String port) throws Exception {
String config = buildLaunchNewBrowserQueryConfig(port);
String launchUrl = NSTBROWSER_LAUNCH_BROWSER_API + "?config=" + config;
URL url = new URL(launchUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
// set request headers
conn.setRequestProperty("User-Agent", "Mozilla/5.0");
conn.setRequestProperty("Accept-Language", "en-US,en;q=0.5");
conn.setRequestProperty("x-api-key", "your Nstbrowser api key");
conn.setDoOutput(true);
try (BufferedReader in = new BufferedReader(new InputStreamReader(conn.getInputStream()))) {
String inputLine;
StringBuilder response = new StringBuilder();
while ((inputLine = in.readLine()) != null) {
response.append(inputLine);
}
// deal with response ...
}
}
/**
* Builds the JSON configuration for launching a new browser instance.
*
*/
private static String buildLaunchNewBrowserQueryConfig(String port) {
String jsonParam = """
{
"once": true,
"headless": false,
"autoClose": false,
"remoteDebuggingPort": %port,
"fingerprint": {
"name": "test",
"kernel": "chromium",
"platform": "mac",
"kernelMilestone": "120",
"hardwareConcurrency": 10,
"deviceMemory": 8
}
}
""";
jsonParam = jsonParam.replace("%port", port);
return URLEncoder.encode(jsonParam, StandardCharsets.UTF_8);
}
/**
* Scrapes product data from the Scrapeme website using Nstbrowser headless browser.
*
*/
public static List<ScrapeMeProduct> scrape(String port) {
ChromeOptions options = new ChromeOptions();
// enable headless mode
options.addArguments("--headless");
// set driver path
System.setProperty("webdriver.chrome.driver", "your chrome webdriver path");
System.setProperty("webdriver.http.factory", "jdk-http-client");
// create options
// debuggerAddress
options.setExperimentalOption("debuggerAddress", "127.0.0.1:" + port);
options.addArguments("--remote-allow-origins=*");
WebDriver driver = new ChromeDriver(options);
driver.get(SCRAPEME_SITE_URL);
// products data
List<ScrapeMeProduct> pokemonProducts = new ArrayList<>();
List<WebElement> products = driver.findElements(By.cssSelector("li.product"));
for (WebElement product : products) {
ScrapeMeProduct pokemonProduct = new ScrapeMeProduct();
pokemonProduct.setUrl(product.findElement(By.tagName("a")).getAttribute("href")); // parse and set product url
pokemonProduct.setImage(product.findElement(By.tagName(("img"))).getAttribute("src")); // parse and set product image
pokemonProduct.setName(product.findElement(By.tagName(("h2"))).getText()); // parse and set product name
pokemonProduct.setPrice(product.findElement(By.tagName(("span"))).getText()); // parse and set product price
pokemonProducts.add(pokemonProduct);
}
// quit browser
driver.quit();
return pokemonProducts;
}
public static void main(String[] args) {
// browser remote debug port
String port = "9222";
try {
launchBrowser(port);
} catch (Exception e) {
throw new RuntimeException(e);
}
List<ScrapeMeProduct> products = scrape(port);
products.forEach(System.out::println);
}
}Resumen
Este blog describe brevemente cómo utilizar programas Java para el rastreo de sitios web en Programación Concurrente y Anti-Detection Browser.
Al mostrar cómo utilizar Nstbrowser Anti-Detection Browser para el rastreo de datos y proporcionar ejemplos de código detallados, ¡seguramente le dará una comprensión más profunda de la información y las operaciones de Java, Headless Browser y Fingerprint Browser!
Más





