
Web Scraping
使用 Java 进行网页抓取 - 并发抓取、无头浏览器和反检测浏览器
本篇我们将结合Java并发编程来爬取整个站点的数据.
Apr 23, 2024Carlos Rivera
在本教程的上一篇博客中,我们提供了一个使用 Java 从 Scrapeme 站点上的单个页面抓取数据的成功示例。
那么,有没有更特殊的数据抓取方法呢?
没错!在本文中,您将获得另外 3 个有用的工具来使用 Java 完成网页抓取:
- 并行扫描程序
- 无头浏览器
- 反检测浏览器
1. 并行扫描程序
与普通的网络爬行方法相比,并发抓取过程更快、更高效。不相信我?通过下面的讲解和具体代码演示您将会了解到:
站点源码分析
以爬取ScrapeMe为例来分析:
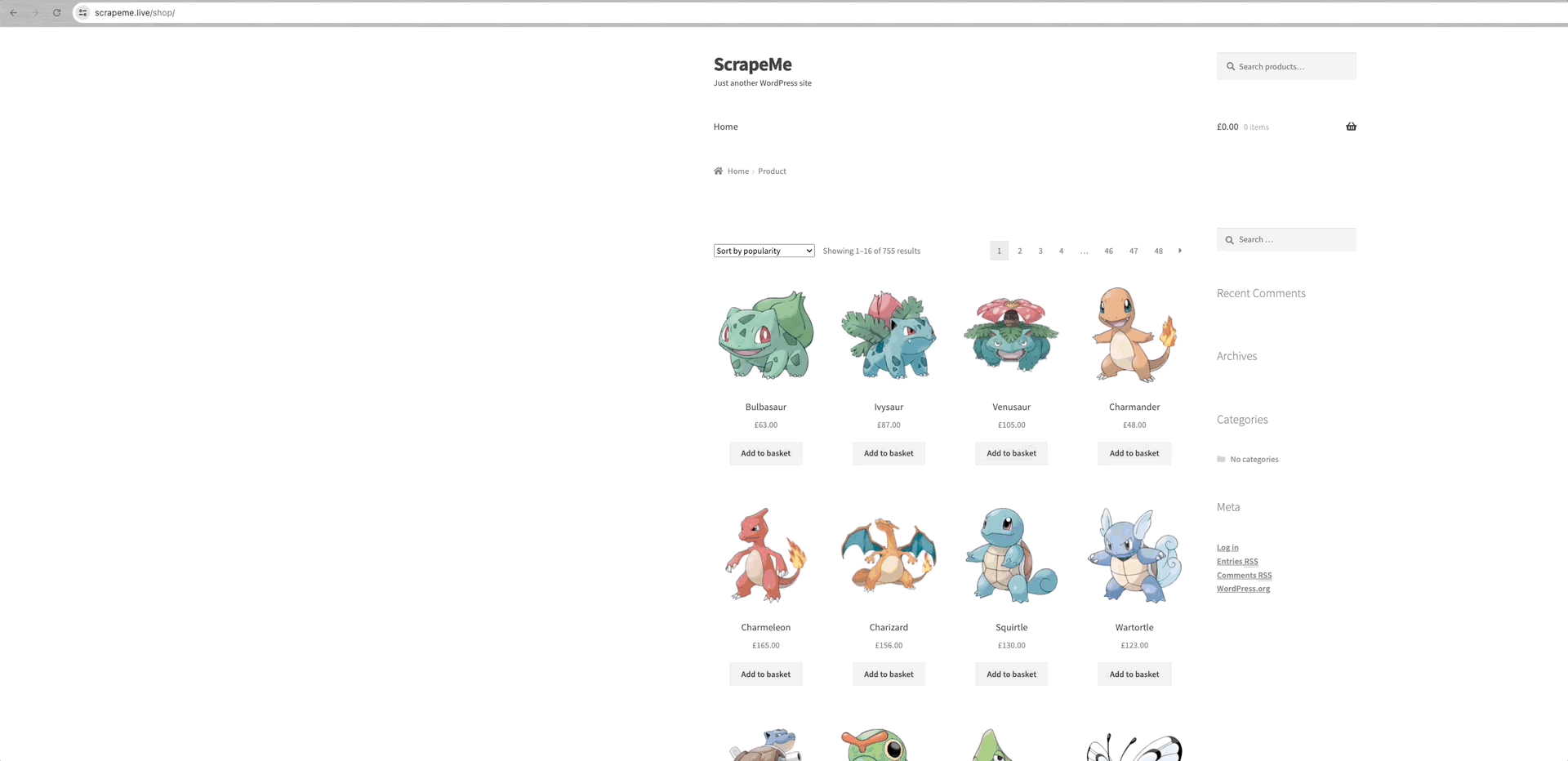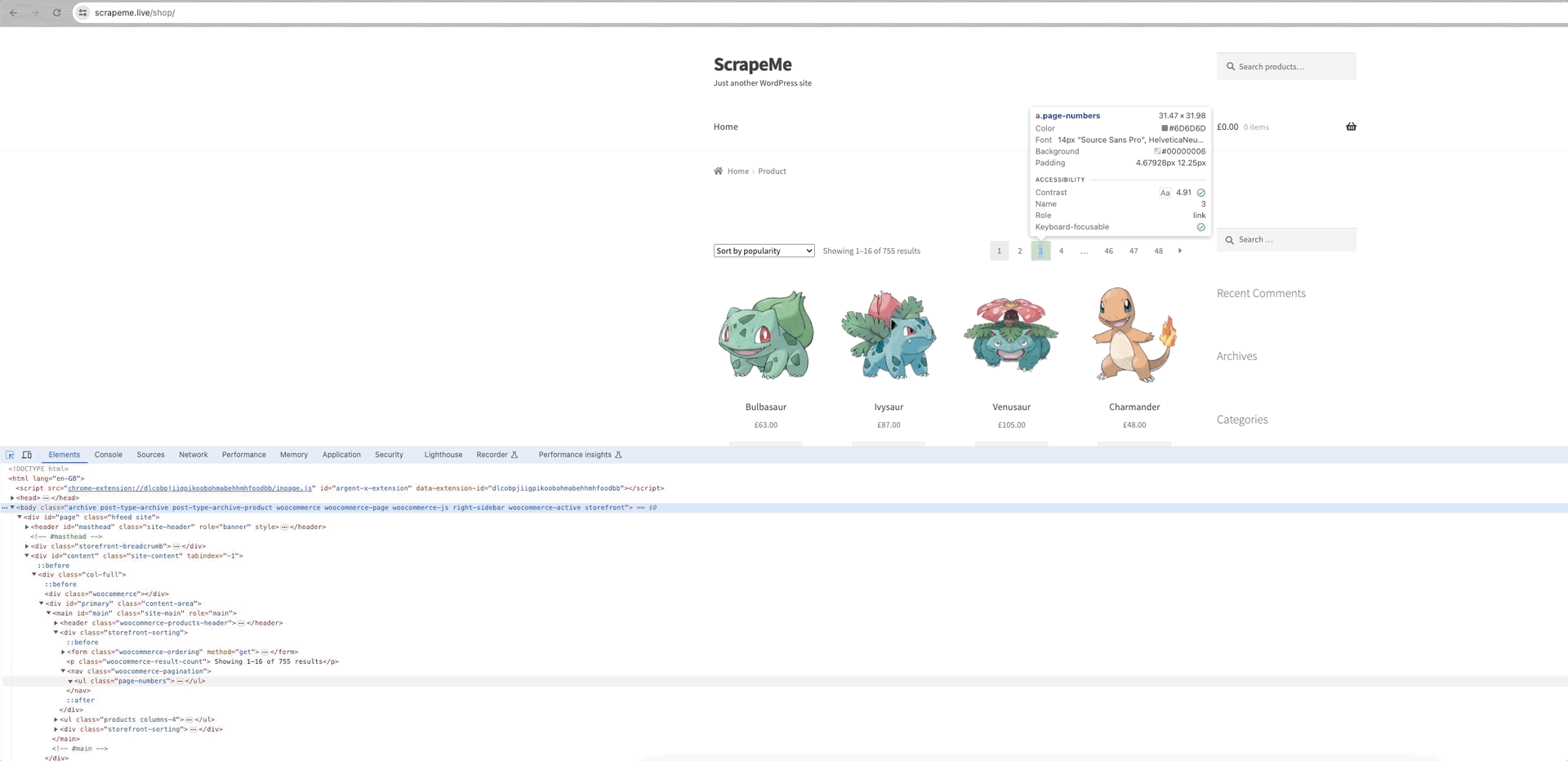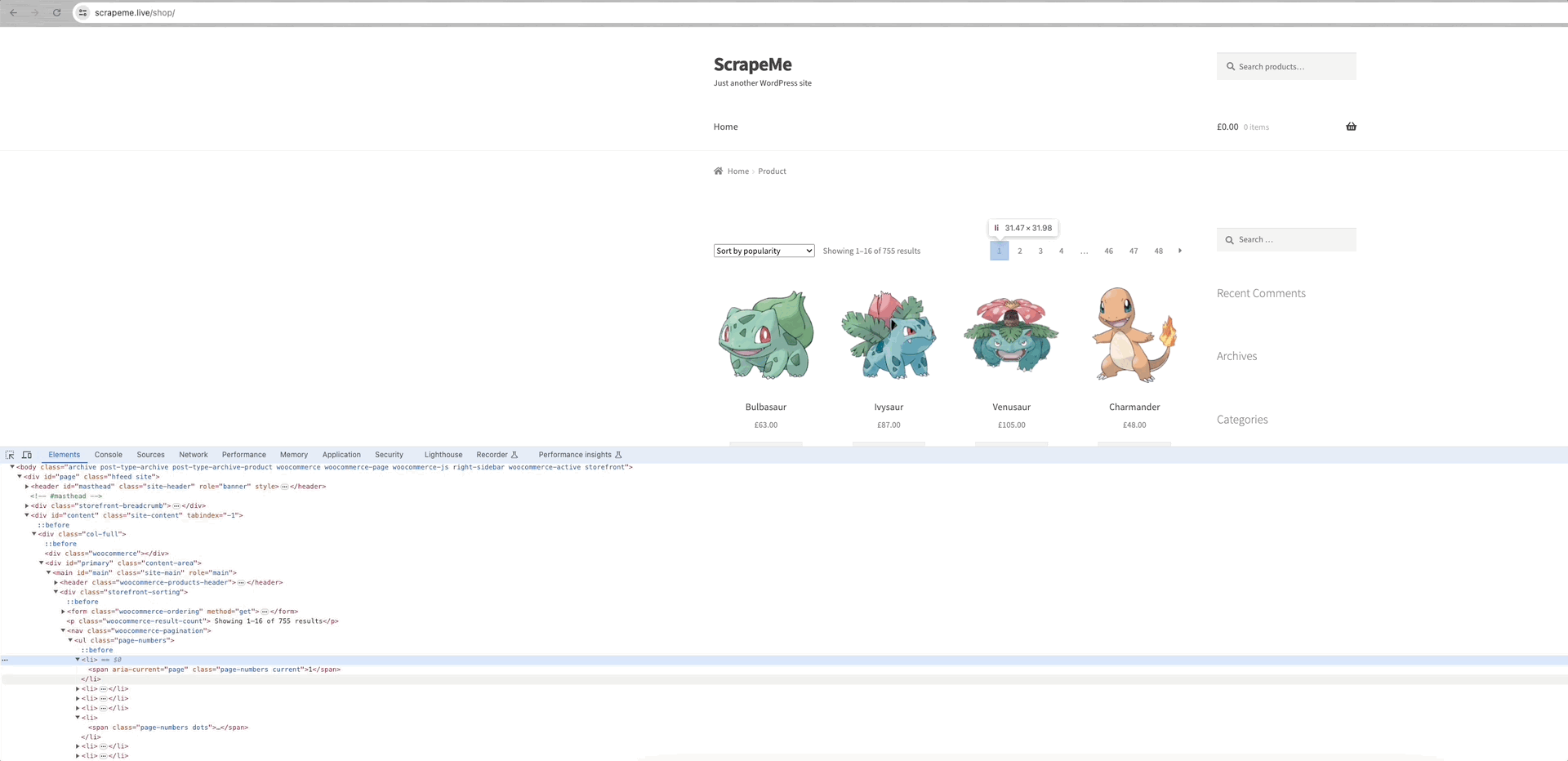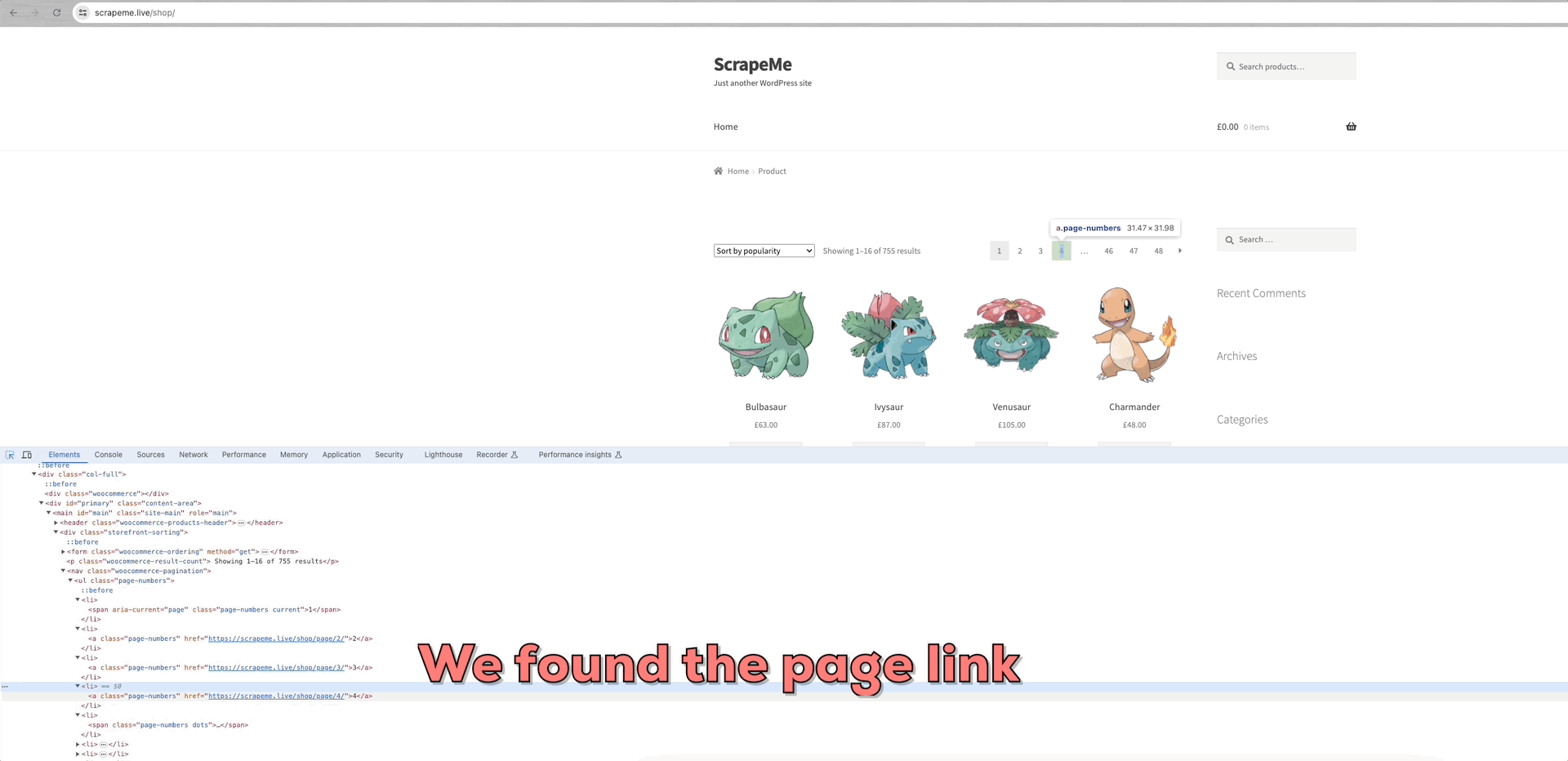
我们可以看到每个数据页面的链接都在a.page-numbers元素内,并且每个页面的详细信息都是相同的。所以,我们只需要迭代这些分页链接就可以获得所有其他页面的链接。
然后,我们可以为每个页面启动一个单独的线程来执行数据抓取,从而获得所有页面数据。如果任务很多,我们可能还需要使用线程池,根据我们的设备配置线程数量。
编码演示
为了便于比较,我们先不使用并发的方式来操作所有的数据抓取:
Scraper.class
java
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.*;
import java.io.IOException;
import java.util.*;
public class Scraper {
/**
first page of scrapeme products list
*/
private static final String SCRAPEME_SITE_URL = "https://scrapeme.live/shop";
public static void scrape(List<ScrapeMeProduct> scrapeMeProducts, Set<String> pagesFound, List<String> todoPages) {
// html doc for scrapeme page
Document doc;
// remove page from todoPages
String url = todoPages.removeFirst();
try {
doc = Jsoup.connect(url).userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36").header("Accept-Language", "*").get();
// select product nodes
Elements products = doc.select("li.product");
for (Element product : products) {
ScrapeMeProduct scrapeMeProduct = new ScrapeMeProduct();
scrapeMeProduct.setUrl(product.selectFirst("a").attr("href")); // parse and set product url
scrapeMeProduct.setImage(product.selectFirst("img").attr("src")); // parse and set product image
scrapeMeProduct.setName(product.selectFirst("h2").text()); // parse and set product name
scrapeMeProduct.setPrice(product.selectFirst("span").text()); // parse and set product price
scrapeMeProducts.add(scrapeMeProduct);
}
// add to pages found set
pagesFound.add(url);
Elements paginationElements = doc.select("a.page-numbers");
for (Element pageElement : paginationElements) {
String pageUrl = pageElement.attr("href");
// add new pages to todoPages
if (!pagesFound.contains(pageUrl) && !todoPages.contains(pageUrl)) {
todoPages.add(pageUrl);
}
// add to pages found set
pagesFound.add(pageUrl);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static List<ScrapeMeProduct> scrapeAll() {
// products
List<ScrapeMeProduct> scrapeMeProducts = new ArrayList<>();
// all pages found
Set<String> pagesFound = new HashSet<>();
// pages list waiting for scrape
List<String> todoPages = new ArrayList<>();
// add the first page to scrape
todoPages.add(SCRAPEME_SITE_URL);
while (!todoPages.isEmpty()) {
scrape(scrapeMeProducts, pagesFound, todoPages);
}
return scrapeMeProducts;
}
}Main.class
java
import io.xxx.basic.ScrapeMeProduct;
import io.xxx.basic.Scraper;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<ScrapeMeProduct> products = Scraper.scrapeAll();
System.out.println(products.size() + " products scraped");
// then you can do whatever you want
}
}在上面的非并发模式代码中,我们创建一个名为todoPages保存待抓取页面 URL 的列表。我们循环遍历它,直到所有页面都被刮掉。然而,在循环期间,顺序执行并等待所有任务完成可能需要很长时间。
如何加快我们的效率?
您将会感到兴奋,因为我们可以使用Java 并发编程来优化网页抓取。它有助于启动多个线程同时执行任务,然后合并结果。
下面是优化后的方法:
Scraper.class
java
// duplicates omitted
public static void concurrentScrape() {
// using synchronized collections
List<ScrapeMeProduct> pokemonProducts = Collections.synchronizedList(new ArrayList<>());
Set<String> pagesDiscovered = Collections.synchronizedSet(new HashSet<>());
List<String> pagesToScrape = Collections.synchronizedList(new ArrayList<>());
pagesToScrape.add(SCRAPEME_SITE_URL);
// new thread pool with CPU cores
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
scrape(pokemonProducts, pagesDiscovered, pagesToScrape);
try {
while (!pagesToScrape.isEmpty()) {
executorService.execute(() -> scrape(pokemonProducts, pagesDiscovered, pagesToScrape));
// sleep for a while for all pending threads to end
TimeUnit.MILLISECONDS.sleep(300);
}
executorService.shutdown();
executorService.awaitTermination(5, TimeUnit.MINUTES);
} catch (Exception e) {
throw new RuntimeException(e);
}
}在这段代码中,我们应用了同步集合Collections.synchronizedList和Collections.synchronizedSet确保多个线程之间的安全访问和修改。
然后,我们使用Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors())来创建一个与CPU核心数相同线程数的线程池,最大化系统资源利用率。
最后,我们使用executorService.awaitTermination方法等待线程池中的所有任务完成。
运行程序
运行结果:

2. Headless浏览器
在网络数据抓取过程中,无头浏览器变得越来越普遍,特别是在处理动态内容或执行 JavaScript 时。
传统爬取工具的挑战
传统的网页抓取工具只能检索静态 HTML 内容,无法执行 JavaScript 代码或模拟用户交互。因此,随着使用 JavaScript 技术动态加载内容或执行交互操作的现代网站的兴起,传统的网络爬虫面临着巨大的挑战。
为了应对这一挑战,引入了无头浏览器
无头浏览器是一种没有图形用户界面的浏览器,可以在后台运行并执行 JavaScript 代码,同时提供与常规浏览器相同的功能和 API。
通过使用无头浏览器,我们可以在浏览器中模拟用户行为,包括页面加载、点击、表单填写等,从而更准确地抓取网页内容。在Java语言中,Selenium WebDriver和Playwright是流行的无头浏览器驱动程序库。
3. 指纹浏览器
反检测浏览器(指纹浏览器)被认为是最有效、最安全的数据抓取工具。
随着网络安全技术的发展,网站对于网络爬虫的防御也越来越严格。传统的爬虫往往很容易被识别和拦截,主要的识别方法之一是:浏览器指纹,一个特殊的“监督者”来区分真实用户和爬虫程序。
因此,就网页抓取而言,理解和处理指纹浏览器变得至关重要。
什么是反检测浏览器?
反检测浏览器是一种可以模拟真实用户浏览器行为,同时具有独特的浏览器指纹特征的浏览器。这些功能包括但不限于用户代理字符串、屏幕分辨率、操作系统信息、插件列表、语言设置等。利用这些信息,网站可以识别访问者的真实身份。指纹浏览器的用户可以自定义指纹特征来隐藏自己的真实身份。
无头浏览器和指纹浏览器的主要区别
与普通无头浏览器相比,反检测浏览器更注重模拟真实用户的浏览行为,生成与真实用户相似的浏览器指纹特征。目的是绕过网站反抓取机制,尽可能隐藏抓取者的身份,从而提高抓取的成功率。目前主流的反检测浏览器都支持headless模式。
在接下来的内容中,我们将根据实际的爬虫需求,使用Selenium WebDriver来重构我们之前的爬虫业务,例如自定义指纹、绕过反爬虫机制、自动验证Cloudflare等。
使用Nstbrowser指纹浏览器重构
添加selenium-java依赖
bash
// gradle => build.gradle => dependencies
implementation "org.seleniumhq.selenium:selenium-java:4.14.1"下载及配置Nstbrowser
下载 Nstbrowser 指纹浏览器并注册一个账户,即可免费使用!
客户端的功能是可以体验的,但我们需要的是自动化相关的功能。可以参考API文档。
- 步骤 1. 开始之前,您需要创建指纹并在本地下载相应的内核。
- 步骤 2. 下载指纹版本对应的Chromedriver。
- 步骤 3. 使用LaunchNewBrowser 创建指纹浏览器实例。
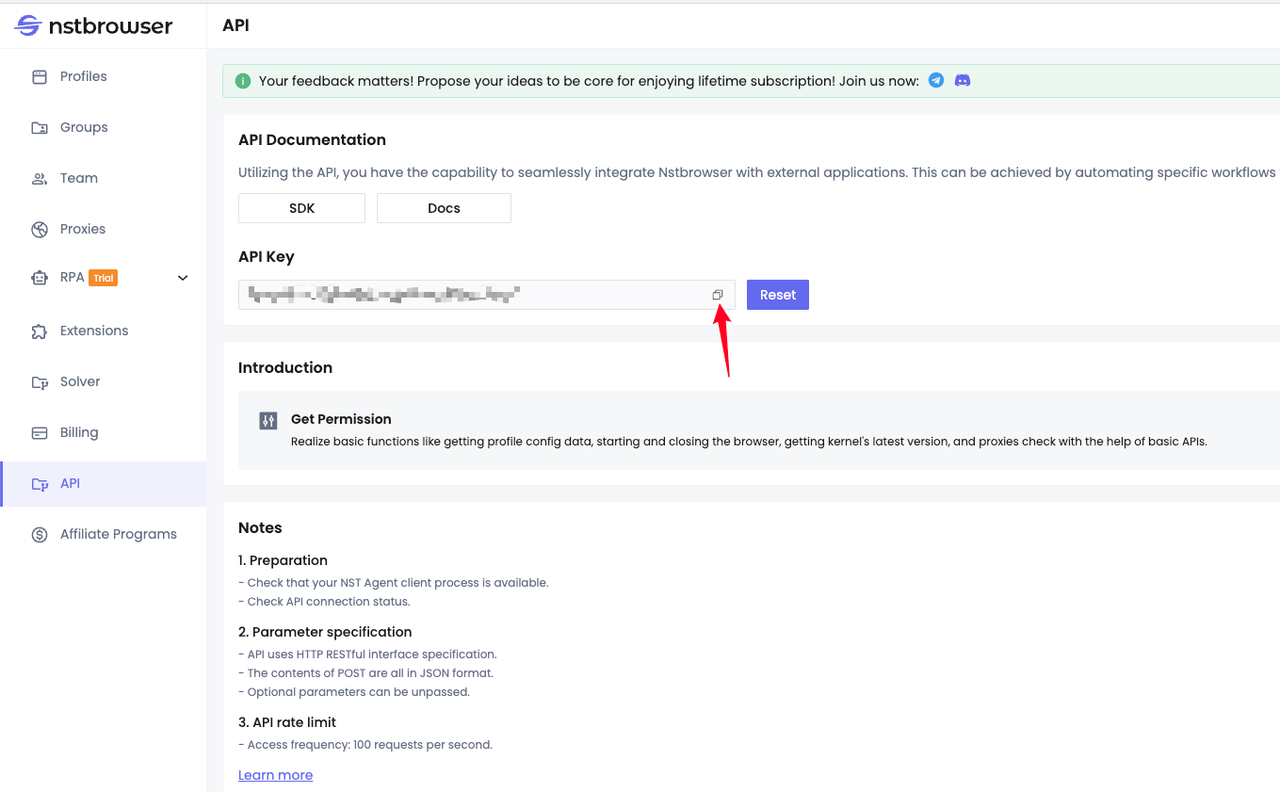
根据接口文档,我们需要提前生成并复制我们的API Key:
代码演示
Scraper.class
java
import io.xxx.basic.ScrapeMeProduct;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.*;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class NstbrowserScraper {
// scrapeme site url
private static final String SCRAPEME_SITE_URL = "https://scrapeme.live/shop";
// Nstbrowser LaunchNewBrowser api url
private static final String NSTBROWSER_LAUNCH_BROWSER_API = "http://127.0.0.1:8848/api/agent/devtool/launch";
/**
* Launches a new browser instance using the Nstbrowser LaunchNewBrowser API.
*/
public static void launchBrowser(String port) throws Exception {
String config = buildLaunchNewBrowserQueryConfig(port);
String launchUrl = NSTBROWSER_LAUNCH_BROWSER_API + "?config=" + config;
URL url = new URL(launchUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
// set request headers
conn.setRequestProperty("User-Agent", "Mozilla/5.0");
conn.setRequestProperty("Accept-Language", "en-US,en;q=0.5");
conn.setRequestProperty("x-api-key", "your Nstbrowser api key");
conn.setDoOutput(true);
try (BufferedReader in = new BufferedReader(new InputStreamReader(conn.getInputStream()))) {
String inputLine;
StringBuilder response = new StringBuilder();
while ((inputLine = in.readLine()) != null) {
response.append(inputLine);
}
// deal with response ...
}
}
/**
* Builds the JSON configuration for launching a new browser instance.
*
*/
private static String buildLaunchNewBrowserQueryConfig(String port) {
String jsonParam = """
{
"once": true,
"headless": false,
"autoClose": false,
"remoteDebuggingPort": %port,
"fingerprint": {
"name": "test",
"kernel": "chromium",
"platform": "mac",
"kernelMilestone": "120",
"hardwareConcurrency": 10,
"deviceMemory": 8
}
}
""";
jsonParam = jsonParam.replace("%port", port);
return URLEncoder.encode(jsonParam, StandardCharsets.UTF_8);
}
/**
* Scrapes product data from the Scrapeme website using Nstbrowser headless browser.
*
*/
public static List<ScrapeMeProduct> scrape(String port) {
ChromeOptions options = new ChromeOptions();
// enable headless mode
options.addArguments("--headless");
// set driver path
System.setProperty("webdriver.chrome.driver", "your chrome webdriver path");
System.setProperty("webdriver.http.factory", "jdk-http-client");
// create options
// debuggerAddress
options.setExperimentalOption("debuggerAddress", "127.0.0.1:" + port);
options.addArguments("--remote-allow-origins=*");
WebDriver driver = new ChromeDriver(options);
driver.get(SCRAPEME_SITE_URL);
// products data
List<ScrapeMeProduct> pokemonProducts = new ArrayList<>();
List<WebElement> products = driver.findElements(By.cssSelector("li.product"));
for (WebElement product : products) {
ScrapeMeProduct pokemonProduct = new ScrapeMeProduct();
pokemonProduct.setUrl(product.findElement(By.tagName("a")).getAttribute("href")); // parse and set product url
pokemonProduct.setImage(product.findElement(By.tagName(("img"))).getAttribute("src")); // parse and set product image
pokemonProduct.setName(product.findElement(By.tagName(("h2"))).getText()); // parse and set product name
pokemonProduct.setPrice(product.findElement(By.tagName(("span"))).getText()); // parse and set product price
pokemonProducts.add(pokemonProduct);
}
// quit browser
driver.quit();
return pokemonProducts;
}
public static void main(String[] args) {
// browser remote debug port
String port = "9222";
try {
launchBrowser(port);
} catch (Exception e) {
throw new RuntimeException(e);
}
List<ScrapeMeProduct> products = scrape(port);
products.forEach(System.out::println);
}
}总结
本篇博客简单介绍了如何在并发编程和反检测浏览器中使用Java程序进行网站爬行。
通过展示如何使用Nstbrowser反检测浏览器进行数据抓取并提供详细的代码示例,一定能让您更深入地了解Java、Headless Browser、Fingerprint Browser的相关信息和操作!
更多





