
Web Scraping
Веб-кроулинг с помощью Java - параллельный кроулинг, безголовый браузер и браузер для защиты от несанкционированного доступа
В этой статье мы объединим программирование на Java для того, чтобы проползти по всему сайту.
May 07, 2024Luke Ulyanov
В предыдущем блоге этого руководства мы привели успешный пример использования Java для получения данных с одной страницы на сайте Scrapeme.
Так есть ли более конкретный способ извлечения данных?
Да, есть! В этой статье вы получите еще 3 полезных инструмента для обобщения веб-страниц с помощью Java:
- Параллельная процедура сканирования
- безголовые браузеры
- антидетекторный браузер
1. одновременный процесс ползания
Процесс одновременного поиска быстрее и эффективнее, чем обычные методы поиска в Интернете. Не верите? Вы узнаете об этом из следующих объяснений и демонстрации кода:
Анализ исходного кода сайта
В качестве примера для анализа можно привести ползание ScrapeMe:
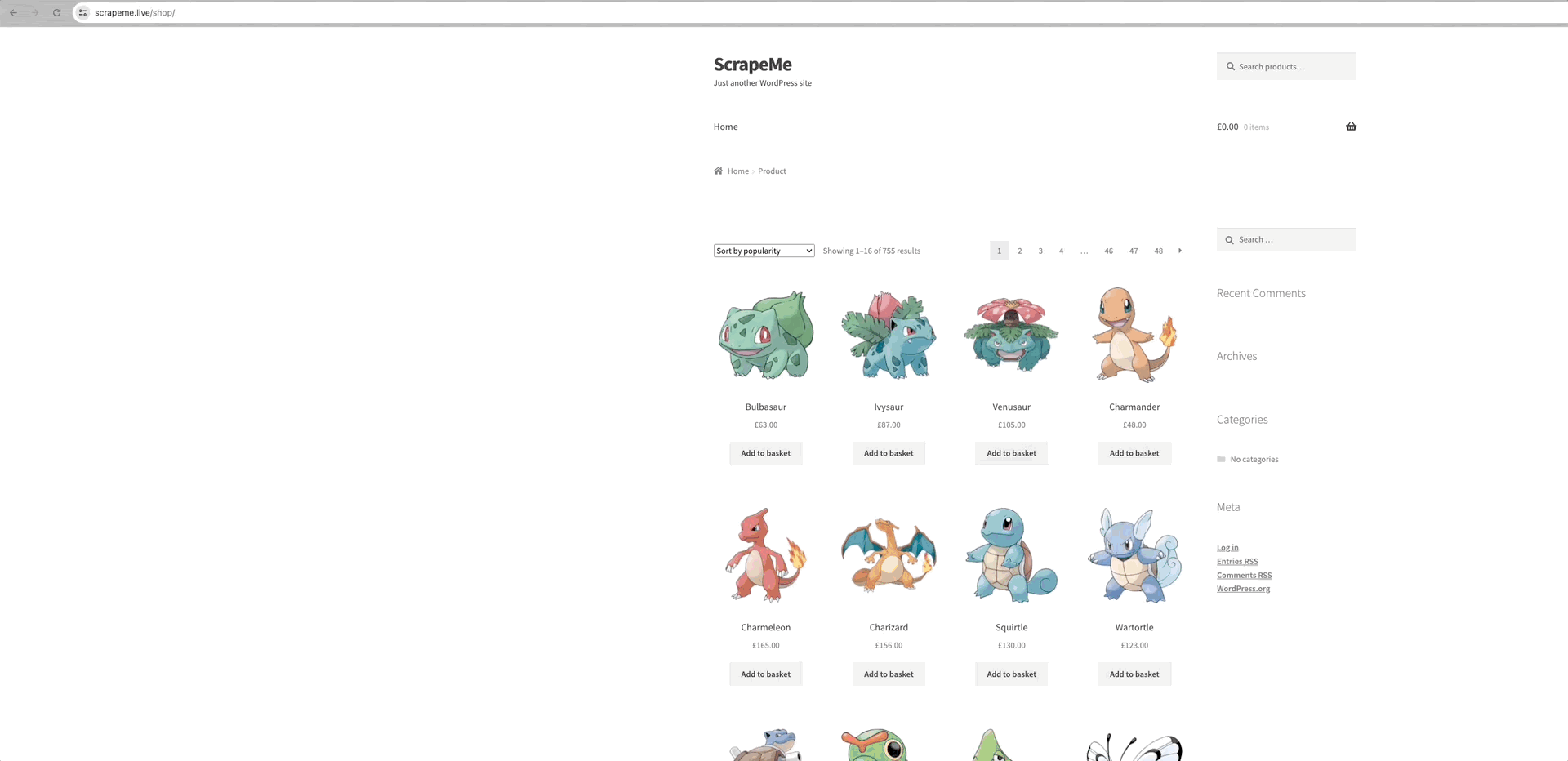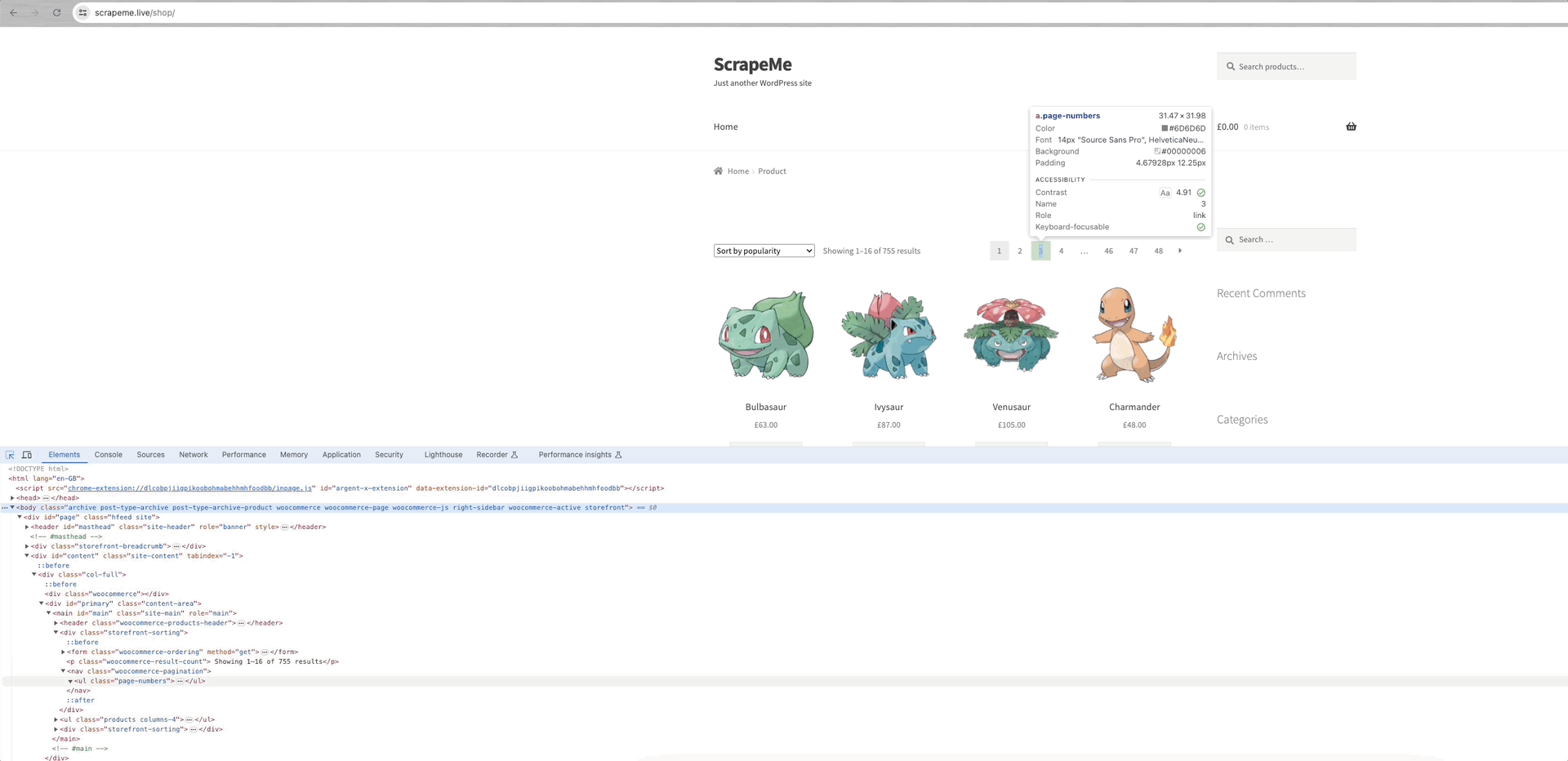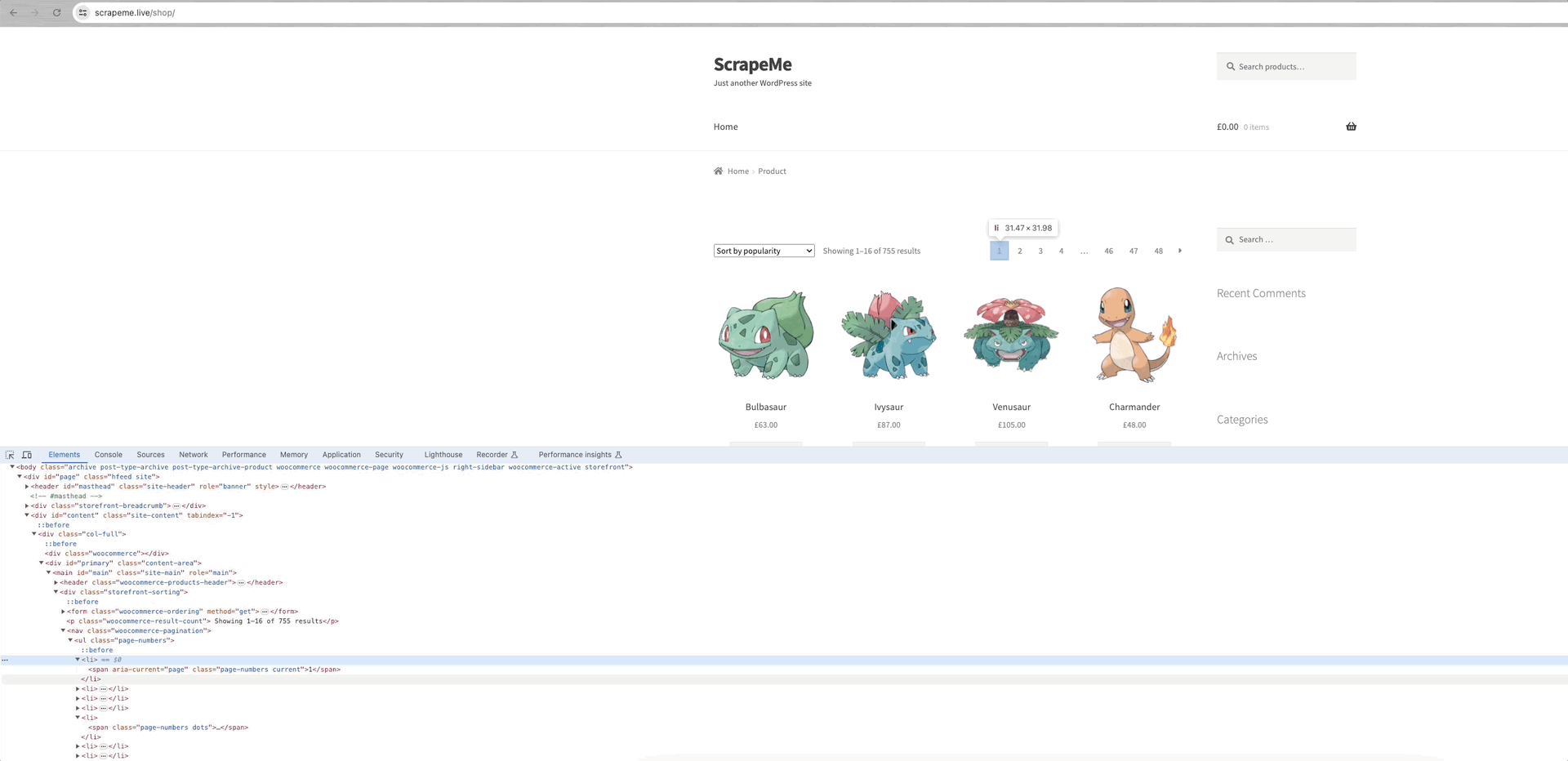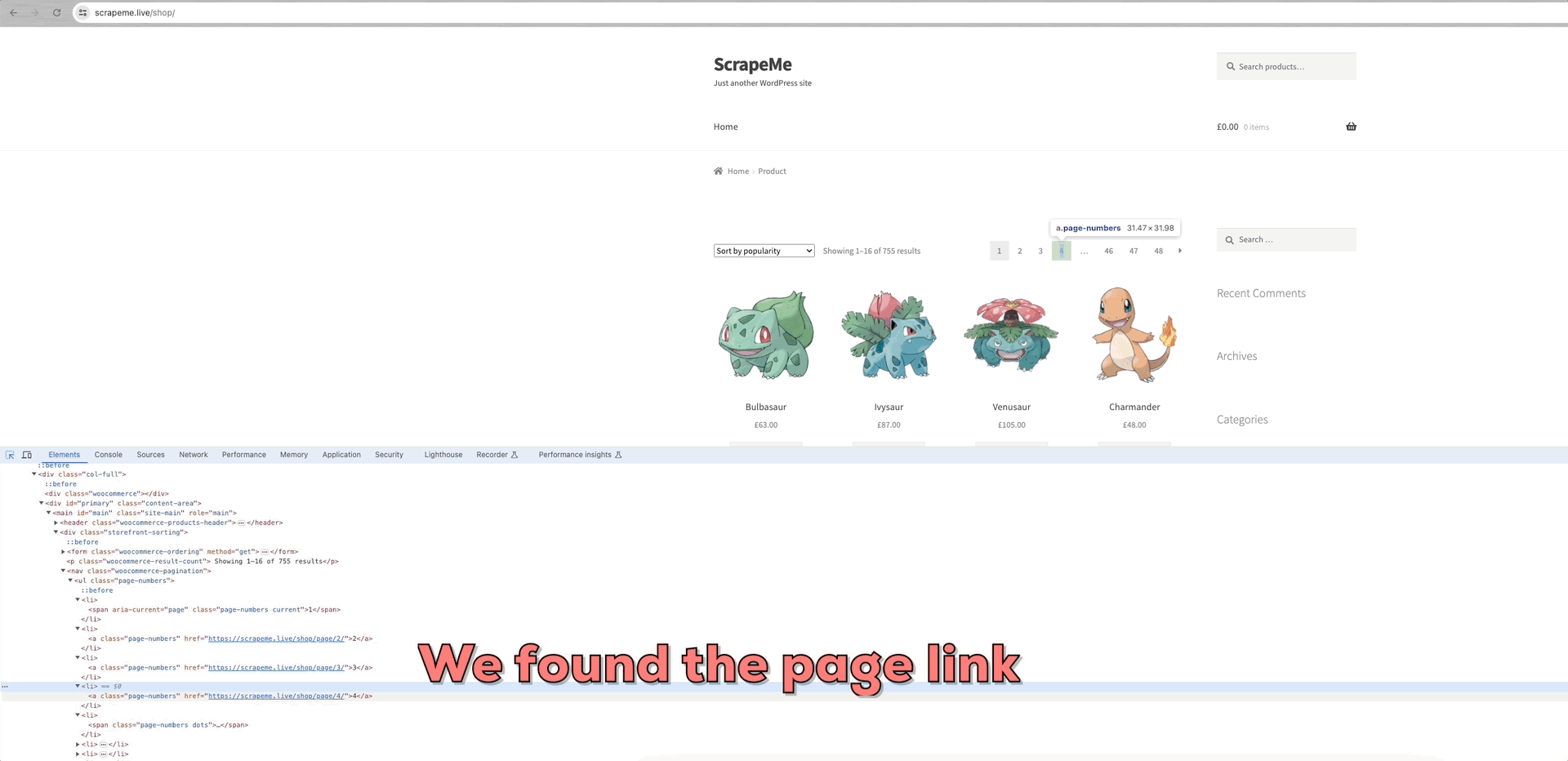
Мы видим, что ссылки на каждую из страниц данных находятся в элементе a.page-numbers, и детали для каждой страницы одинаковы. Таким образом, нам нужно только выполнить итерацию по этим постраничным ссылкам, чтобы получить ссылки на все остальные страницы.
Затем мы можем запустить отдельный поток для каждой страницы, чтобы выполнить перебор данных и получить все данные о странице. Если задач много, нам может понадобиться пул потоков, чтобы настроить количество потоков в соответствии с нашим устройством.
Демонстрация кодирования
Для сравнения давайте сначала выполним все операции захвата данных без использования параллелизма:
Scraper.class
java
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.*;
import java.io.IOException;
import java.util.*;
public class Scraper {
/**
first page of scrapeme products list
*/
private static final String SCRAPEME_SITE_URL = "https://scrapeme.live/shop";
public static void scrape(List<ScrapeMeProduct> scrapeMeProducts, Set<String> pagesFound, List<String> todoPages) {
// html doc for scrapeme page
Document doc;
// remove page from todoPages
String url = todoPages.removeFirst();
try {
doc = Jsoup.connect(url).userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36").header("Accept-Language", "*").get();
// select product nodes
Elements products = doc.select("li.product");
for (Element product : products) {
ScrapeMeProduct scrapeMeProduct = new ScrapeMeProduct();
scrapeMeProduct.setUrl(product.selectFirst("a").attr("href")); // parse and set product url
scrapeMeProduct.setImage(product.selectFirst("img").attr("src")); // parse and set product image
scrapeMeProduct.setName(product.selectFirst("h2").text()); // parse and set product name
scrapeMeProduct.setPrice(product.selectFirst("span").text()); // parse and set product price
scrapeMeProducts.add(scrapeMeProduct);
}
// add to pages found set
pagesFound.add(url);
Elements paginationElements = doc.select("a.page-numbers");
for (Element pageElement : paginationElements) {
String pageUrl = pageElement.attr("href");
// add new pages to todoPages
if (!pagesFound.contains(pageUrl) && !todoPages.contains(pageUrl)) {
todoPages.add(pageUrl);
}
// add to pages found set
pagesFound.add(pageUrl);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static List<ScrapeMeProduct> scrapeAll() {
// products
List<ScrapeMeProduct> scrapeMeProducts = new ArrayList<>();
// all pages found
Set<String> pagesFound = new HashSet<>();
// pages list waiting for scrape
List<String> todoPages = new ArrayList<>();
// add the first page to scrape
todoPages.add(SCRAPEME_SITE_URL);
while (!todoPages.isEmpty()) {
scrape(scrapeMeProducts, pagesFound, todoPages);
}
return scrapeMeProducts;
}
}Main.class
java
import io.xxx.basic.ScrapeMeProduct;
import io.xxx.basic.Scraper;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<ScrapeMeProduct> products = Scraper.scrapeAll();
System.out.println(products.size() + " products scraped");
// then you can do whatever you want
}
}В приведенном выше коде неконкурентного режима мы создаем список todoPages, в котором хранятся URL-адреса страниц, подлежащих отбору. Мы проходим по нему до тех пор, пока все страницы не будут соскоблены. Однако во время цикла последовательное выполнение и ожидание завершения всех задач может занять много времени.
Как мы можем ускорить нашу работу?
Вы будете рады узнать, что для оптимизации работы с веб-страницами мы можем использовать параллельное программирование Java. Оно позволяет запустить несколько потоков для одновременного выполнения задач и затем объединить результаты.
Вот оптимизированный метод:
Scraper.class
java
// duplicates omitted
public static void concurrentScrape() {
// using synchronized collections
List<ScrapeMeProduct> pokemonProducts = Collections.synchronizedList(new ArrayList<>());
Set<String> pagesDiscovered = Collections.synchronizedSet(new HashSet<>());
List<String> pagesToScrape = Collections.synchronizedList(new ArrayList<>());
pagesToScrape.add(SCRAPEME_SITE_URL);
// new thread pool with CPU cores
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
scrape(pokemonProducts, pagesDiscovered, pagesToScrape);
try {
while (!pagesToScrape.isEmpty()) {
executorService.execute(() -> scrape(pokemonProducts, pagesDiscovered, pagesToScrape));
// sleep for a while for all pending threads to end
TimeUnit.MILLISECONDS.sleep(300);
}
executorService.shutdown();
executorService.awaitTermination(5, TimeUnit.MINUTES);
} catch (Exception e) {
throw new RuntimeException(e);
}
}В этом коде мы применили синхронизированные коллекции Collections.synchronizedList и Collections.synchronizedSet для обеспечения безопасного доступа и модификации между несколькими потоками.
Затем мы используем Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors()) для создания пула потоков с тем же количеством потоков, что и количество ядер процессора, чтобы максимально использовать системные ресурсы.
Наконец, мы используем метод executionService.awaitTermination, чтобы дождаться завершения всех задач в пуле.
Выполните программу
Запустите результаты:

2. Безголовые браузеры
Безголовые браузеры становятся все более распространенными при поиске веб-данных, особенно при работе с динамическим контентом или выполнении JavaScript.
Проблемы традиционных инструментов для краулинга
Традиционные веб-краулеры могут получать только статический HTML-контент и не могут выполнять код JavaScript или имитировать взаимодействие с пользователем. Поэтому с ростом числа современных веб-сайтов, использующих технологию JavaScript для динамической загрузки контента или выполнения интерактивных действий, традиционные веб-краулеры сталкиваются с серьезной проблемой.
Для решения этой проблемы были созданы безголовые браузеры
Безголовый браузер - это браузер без графического интерфейса пользователя, который запускает и выполняет код JavaScript в фоновом режиме, предоставляя при этом те же функции и API, что и обычный браузер.
Используя безголовый браузер, мы можем имитировать поведение пользователя в браузере, включая загрузку страницы, клики, заполнение форм и т. д., чтобы более точно передавать веб-контент. В языке Java популярными библиотеками драйверов безголовых браузеров являются Selenium WebDriver и Playwright.
3. Браузер отпечатков пальцев
Браузеры с защитой от обнаружения (браузеры отпечатков пальцев) считаются наиболее эффективными и безопасными инструментами для сбора данных.
С развитием технологий веб-безопасности веб-сайты становятся все более и более строгими в защите от краулеров. Традиционные краулеры часто легко идентифицируются и перехватываются, и одним из основных методов идентификации является "отпечаток пальца" браузера - специальный "сторожевой пес", который отличает реальных пользователей от краулеров.
Поэтому понимание и решение проблемы браузеров с отпечатками пальцев стало критически важным в контексте веб-краулинга.
Что такое антиобнаруживающий браузер?
Браузер, предотвращающий обнаружение, - это браузер, который имитирует поведение браузера реального пользователя и обладает уникальными функциями "отпечатков пальцев" браузера. К ним относятся, в частности, строки агента пользователя, разрешение экрана, информация об операционной системе, списки подключаемых модулей, языковые настройки и многое другое. Используя эту информацию, веб-сайты могут идентифицировать истинную личность посетителей. Пользователи браузеров с отпечатками пальцев могут настраивать свои функции, чтобы скрыть истинную личность.
Основные различия между безголовыми браузерами и браузерами с отпечатками пальцев
По сравнению с обычными безголовыми браузерами, антиобнаруживающие браузеры больше внимания уделяют имитации поведения реальных пользователей и генерированию отпечатков пальцев, похожих на отпечатки пальцев реальных пользователей. Цель состоит в том, чтобы обойти механизм защиты сайта от краулинга и максимально скрыть личность краулера, чтобы повысить успешность краулинга. В настоящее время основные браузеры для защиты от обнаружения поддерживают режим headless.
В следующем разделе мы используем Selenium WebDriver для реконструкции нашей предыдущей работы в соответствии с реальными требованиями, такими как пользовательские отпечатки пальцев, обход механизмов защиты от краулинга, автоматическая проверка Cloudflare и так далее.
Рефакторинг браузера отпечатков пальцев с помощью Nstbrowser
Добавление зависимости selenium-java
bash
// gradle => build.gradle => dependencies
implementation "org.seleniumhq.selenium:selenium-java:4.14.1"Загрузка и настройка Nstbrowser
Функциональность на стороне клиента уже доступна, но нам нужна функциональность, связанная с автоматизацией. Вы можете обратиться к документации по API.
- Шаг 1. Прежде чем начать, необходимо создать отпечаток пальца и загрузить соответствующее ядро локально.
- Шаг 2. Загрузите Chromedriver, соответствующий версии отпечатка пальца.
- Шаг 3. Используйте API LaunchNewBrowser для создания экземпляра браузера отпечатков пальцев.
Согласно документации по интерфейсу, нам необходимо заранее сгенерировать и скопировать наш API-ключ:
Код Демо
Scraper.class
java
import io.xxx.basic.ScrapeMeProduct;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.*;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class NstbrowserScraper {
// scrapeme site url
private static final String SCRAPEME_SITE_URL = "https://scrapeme.live/shop";
// Nstbrowser LaunchNewBrowser api url
private static final String NSTBROWSER_LAUNCH_BROWSER_API = "http://127.0.0.1:8848/api/agent/devtool/launch";
/**
* Launches a new browser instance using the Nstbrowser LaunchNewBrowser API.
*/
public static void launchBrowser(String port) throws Exception {
String config = buildLaunchNewBrowserQueryConfig(port);
String launchUrl = NSTBROWSER_LAUNCH_BROWSER_API + "?config=" + config;
URL url = new URL(launchUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
// set request headers
conn.setRequestProperty("User-Agent", "Mozilla/5.0");
conn.setRequestProperty("Accept-Language", "en-US,en;q=0.5");
conn.setRequestProperty("x-api-key", "your Nstbrowser api key");
conn.setDoOutput(true);
try (BufferedReader in = new BufferedReader(new InputStreamReader(conn.getInputStream()))) {
String inputLine;
StringBuilder response = new StringBuilder();
while ((inputLine = in.readLine()) != null) {
response.append(inputLine);
}
// deal with response ...
}
}
/**
* Builds the JSON configuration for launching a new browser instance.
*
*/
private static String buildLaunchNewBrowserQueryConfig(String port) {
String jsonParam = """
{
"once": true,
"headless": false,
"autoClose": false,
"remoteDebuggingPort": %port,
"fingerprint": {
"name": "test",
"kernel": "chromium",
"platform": "mac",
"kernelMilestone": "120",
"hardwareConcurrency": 10,
"deviceMemory": 8
}
}
""";
jsonParam = jsonParam.replace("%port", port);
return URLEncoder.encode(jsonParam, StandardCharsets.UTF_8);
}
/**
* Scrapes product data from the Scrapeme website using Nstbrowser headless browser.
*
*/
public static List<ScrapeMeProduct> scrape(String port) {
ChromeOptions options = new ChromeOptions();
// enable headless mode
options.addArguments("--headless");
// set driver path
System.setProperty("webdriver.chrome.driver", "your chrome webdriver path");
System.setProperty("webdriver.http.factory", "jdk-http-client");
// create options
// debuggerAddress
options.setExperimentalOption("debuggerAddress", "127.0.0.1:" + port);
options.addArguments("--remote-allow-origins=*");
WebDriver driver = new ChromeDriver(options);
driver.get(SCRAPEME_SITE_URL);
// products data
List<ScrapeMeProduct> pokemonProducts = new ArrayList<>();
List<WebElement> products = driver.findElements(By.cssSelector("li.product"));
for (WebElement product : products) {
ScrapeMeProduct pokemonProduct = new ScrapeMeProduct();
pokemonProduct.setUrl(product.findElement(By.tagName("a")).getAttribute("href")); // parse and set product url
pokemonProduct.setImage(product.findElement(By.tagName(("img"))).getAttribute("src")); // parse and set product image
pokemonProduct.setName(product.findElement(By.tagName(("h2"))).getText()); // parse and set product name
pokemonProduct.setPrice(product.findElement(By.tagName(("span"))).getText()); // parse and set product price
pokemonProducts.add(pokemonProduct);
}
// quit browser
driver.quit();
return pokemonProducts;
}
public static void main(String[] args) {
// browser remote debug port
String port = "9222";
try {
launchBrowser(port);
} catch (Exception e) {
throw new RuntimeException(e);
}
List<ScrapeMeProduct> products = scrape(port);
products.forEach(System.out::println);
}
}Резюме
В этом блоге кратко описано использование Java-программ для краулинга сайтов в Concurrent Programming и Anti-Detection Browser.
Показывая, как использовать Nstbrowser Anti-Detection Browser для сбора данных, и предоставляя подробные примеры кода, он, несомненно, даст вам более глубокое понимание информации и операций Java, Headless Browser и Fingerprint Browser!
Больше





