
Web Scraping
Web Crawler trong Java: Hướng dẫn từng bước 2024
Java web crawler giúp các tác vụ tự động hóa và thu thập dữ liệu web dễ dàng. Làm thế nào để thu thập dữ liệu web bằng Java web crawler? Đây là tất cả mọi thứ bạn sẽ thích!
Aug 16, 2024Triệu Lệ Chi
Efficient way to get useful information from the website? It's obviously a Java web crawler!
Trong bài viết này, bạn sẽ học được:
- Sự khác biệt giữa web crawler và web scraper là gì?
- Làm thế nào để sử dụng Jsoup để phân tích và trích xuất dữ liệu từ các trang web?
- Làm thế nào để tránh bị phát hiện và cải thiện hiệu quả, độ ổn định khi crawling?
Có thể thực hiện Web Scraping bằng Java không?
Có! Là một ngôn ngữ lập trình phổ biến và được sử dụng rộng rãi, Java cung cấp sự hỗ trợ mạnh mẽ giúp việc web scraping trở nên hiệu quả và đáng tin cậy. Java có thể dựa vào nhiều thư viện khác nhau, điều này có nghĩa là bạn có thể lựa chọn từ nhiều thư viện web scraping bằng Java.
Dưới đây là một số lợi ích chính của việc web scraping bằng Java:
- Thư viện và framework phong phú. Java cung cấp các thư viện và framework mạnh mẽ như Jsoup, Selenium và Apache HttpClient, giúp các nhà phát triển dễ dàng thực hiện scraping và phân tích dữ liệu web.
- Hiệu suất tuyệt vời. Quản lý bộ nhớ hiệu quả và hỗ trợ đa luồng của Java giúp nó hoạt động tốt khi xử lý một lượng lớn dữ liệu.
- Khả năng tương thích đa nền tảng. Java có khả năng chạy trên nhiều hệ điều hành khác nhau như Windows, Linux, hoặc macOS, đảm bảo tính nhất quán và khả năng tương thích của các công cụ scraping.
- Khả năng xử lý dữ liệu mạnh mẽ. Khả năng xử lý dữ liệu của Java rất mạnh mẽ, có thể dễ dàng xử lý các cấu trúc dữ liệu phức tạp và các bộ dữ liệu lớn. Cho dù là phân tích văn bản đơn giản hay chuyển đổi dữ liệu phức tạp, Java đều cung cấp các giải pháp hiệu quả.
- Bảo mật. Các tính năng bảo mật của Java, như mô hình sandbox và security manager, cung cấp sự bảo vệ bổ sung cho các crawler trong môi trường mạng, giúp hệ thống của bạn không bị đe dọa.
Với những lợi ích này, Java là lựa chọn lý tưởng để xây dựng các công cụ crawling web mạnh mẽ và hiệu quả. Cho dù là crawling dữ liệu web tĩnh hay xử lý nội dung động, Java đều cung cấp cho các nhà phát triển một giải pháp đáng tin cậy.
Java Web Crawler là gì?
Trong Java, web crawler là một chương trình tự động được sử dụng để thu thập dữ liệu từ Internet. Nó trích xuất thông tin trên các trang web bằng cách mô phỏng quá trình người dùng truy cập các trang web, sau đó lưu trữ hoặc xử lý thông tin đó để sử dụng sau này.
Các chức năng chính của Java crawler bao gồm:
- Gửi yêu cầu HTTP. Thông qua thư viện HTTP client của Java (như HttpURLConnection hoặc Apache HttpClient), crawler có thể gửi yêu cầu tới trang web mục tiêu để lấy nội dung trang web.
- Phân tích nội dung trang web. Sử dụng các thư viện phân tích HTML (như Jsoup) để phân tích nội dung trang web thành cấu trúc DOM có thể thao tác để trích xuất thông tin cần thiết từ đó.
- Xử lý dữ liệu. Thông tin được trích xuất có thể được xử lý, lưu trữ hoặc phân tích thêm. Ví dụ, lưu dữ liệu vào cơ sở dữ liệu, tạo báo cáo hoặc thực hiện phân tích thống kê.
- Theo dõi liên kết. Crawler có thể theo dõi các liên kết trên một trang web và crawling nhiều trang web khác nhau để thu thập dữ liệu toàn diện hơn.
Sự khác biệt chính giữa Web scraper và Web crawler
Web scraping nhằm mục đích trích xuất dữ liệu trang web, trong khi web crawling nhằm mục đích lập chỉ mục và tìm các trang web.
Web scraping có nghĩa là viết một chương trình có thể bí mật thu thập dữ liệu từ nhiều trang web. Ngược lại, web crawling liên quan đến việc liên tục theo dõi các liên kết dựa trên các siêu liên kết.
Bạn có ý tưởng hay hoặc thắc mắc nào về web scraping và Browserless không?
Hãy xem các nhà phát triển khác đang chia sẻ gì trên Discord và Telegram!
Làm thế nào để thực hiện web scraping bằng Jsoup và Nstbrowser API?
Hãy lấy ví dụ về việc lấy thông tin cơ bản và giá của các loại tiền điện tử trên trang chủ của CoinmarketCap để minh họa cách sử dụng Jsoup và Selenium trong Java web crawler thông qua Nstbrowser API, cụ thể là sử dụng LaunchExistBrowser API.
Trước khi bắt đầu crawling dữ liệu, chúng ta cần:
- Tải xuống và cài đặt Nstbrowser và tạo API key của bạn.
- Tạo một hồ sơ và khởi động hồ sơ để tự động tải xuống phiên bản kernel tương ứng.
- Bước duy nhất còn lại là tải xuống chromedriver của phiên bản kernel tương ứng trước khi sử dụng selenium, có thể tham khảo tại: How to use in Selenium in Nstbrowser.
Phân tích trang
Bắt đầu phân tích trang web và xem trang mà chúng ta muốn crawling trông như thế nào:
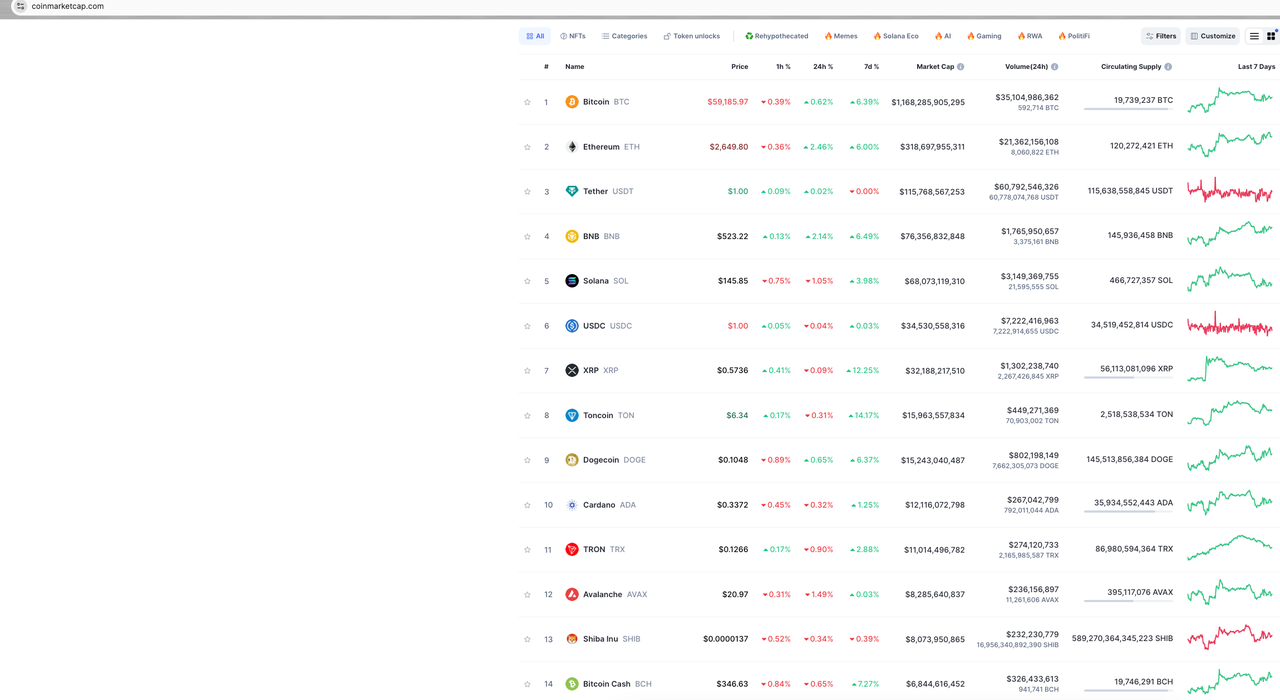
Dữ liệu mục tiêu của chúng ta là dữ liệu trên trang chủ của CoinmarketCap. Ở đây, chúng ta chỉ lấy một số dữ liệu để minh họa, chẳng hạn như xếp hạng tiền điện tử, logo tiền điện tử, tiền điện tử và giá trị tiền tệ.
Tiếp theo, chúng ta sẽ phân tích từng phần dữ liệu cần thiết.
Bước 1. Mở bảng điều khiển trình duyệt và bắt đầu xem các phần tử trang:
Phân tích tổng thể
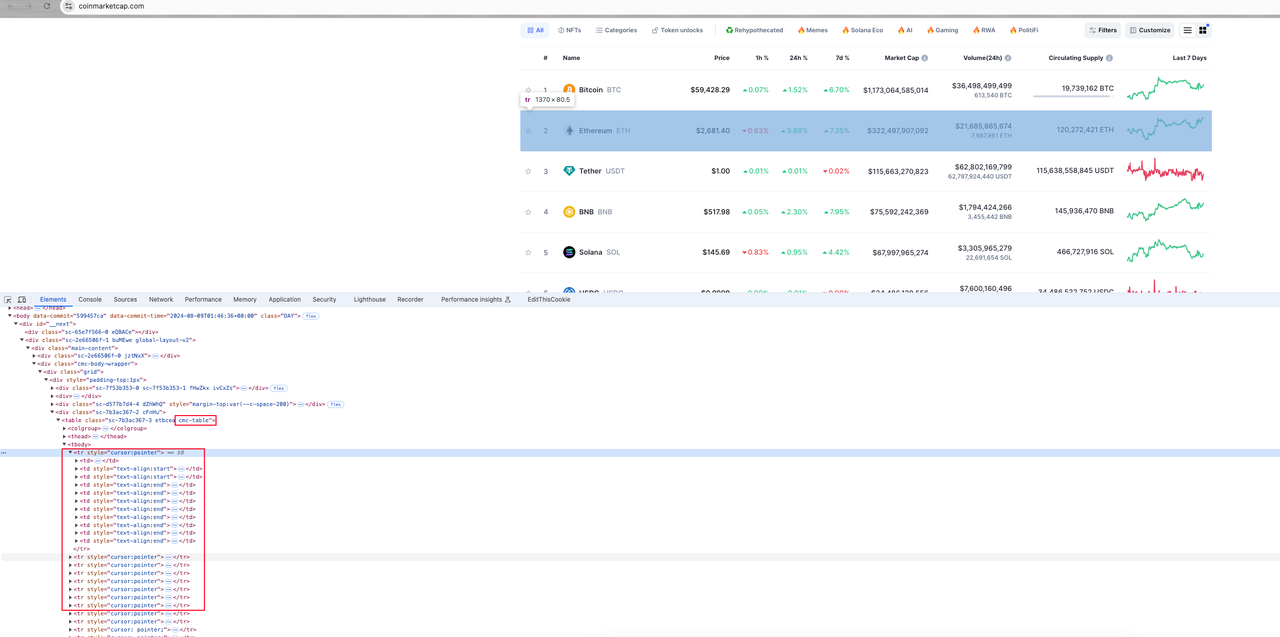
Tất cả thông tin về tiền tệ trên trang đều nằm trong một phần tử table có tên lớp là cmc-table. Phần tử trang tương ứng với thông tin tiền tệ là hàng bảng tr dưới phần tử bảng. Mỗi hàng bảng chứa một số phần tử cột bảng td. Mục tiêu của chúng ta là phân tích dữ liệu mục tiêu từ các phần tử td này.
Bước 2. Chúng ta sẽ tìm kiếm và phân tích từng dữ liệu mục tiêu:
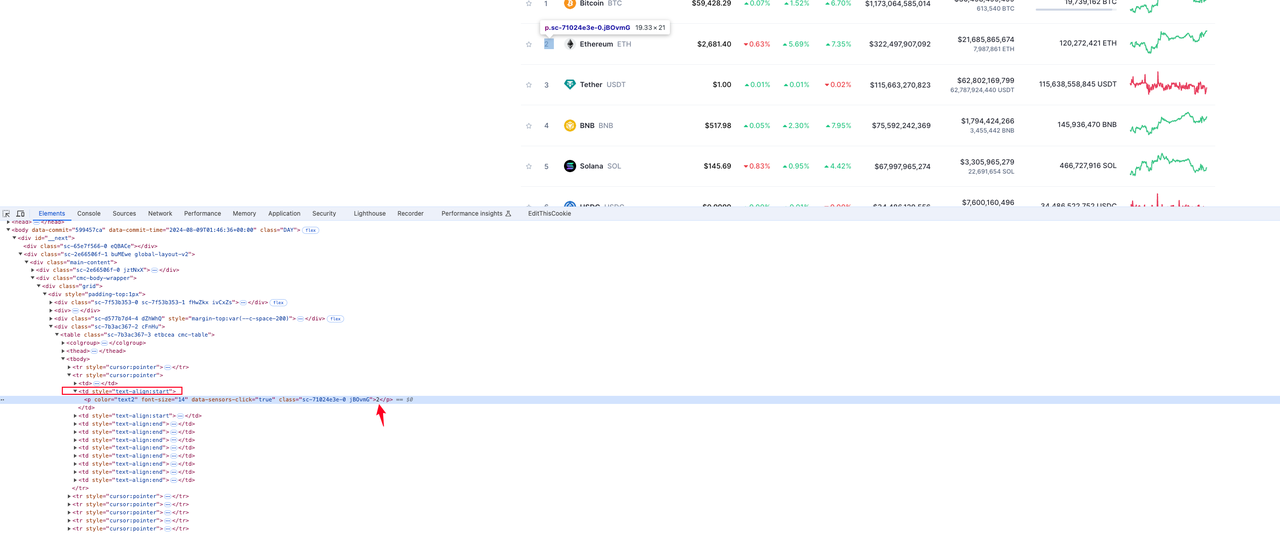
Xếp hạng tiền tệ
Từ hình dưới đây, chúng ta có thể thấy phần tử nơi xếp hạng tiền tệ nằm trong giá trị thẻ p dưới thẻ td thứ hai trong tr:
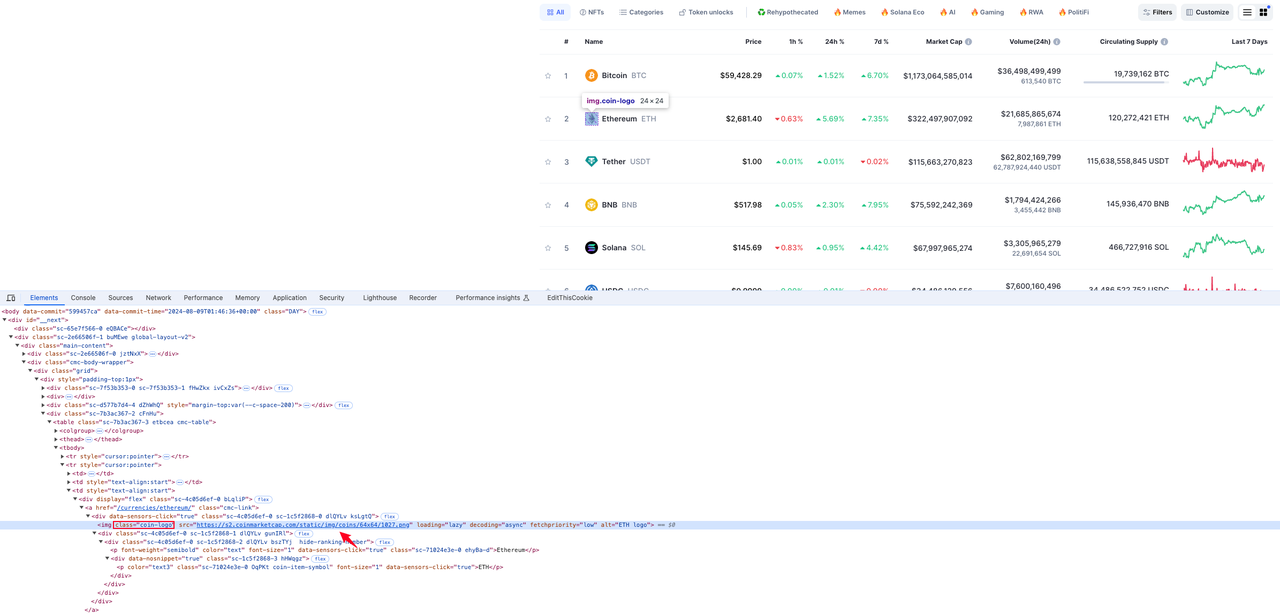
Logo tiền tệ
Phần tử nơi biểu tượng logo tiền tệ nằm trong giá trị thuộc tính src của thẻ img có tên lớp coin-logo trong phần tử hàng tr:
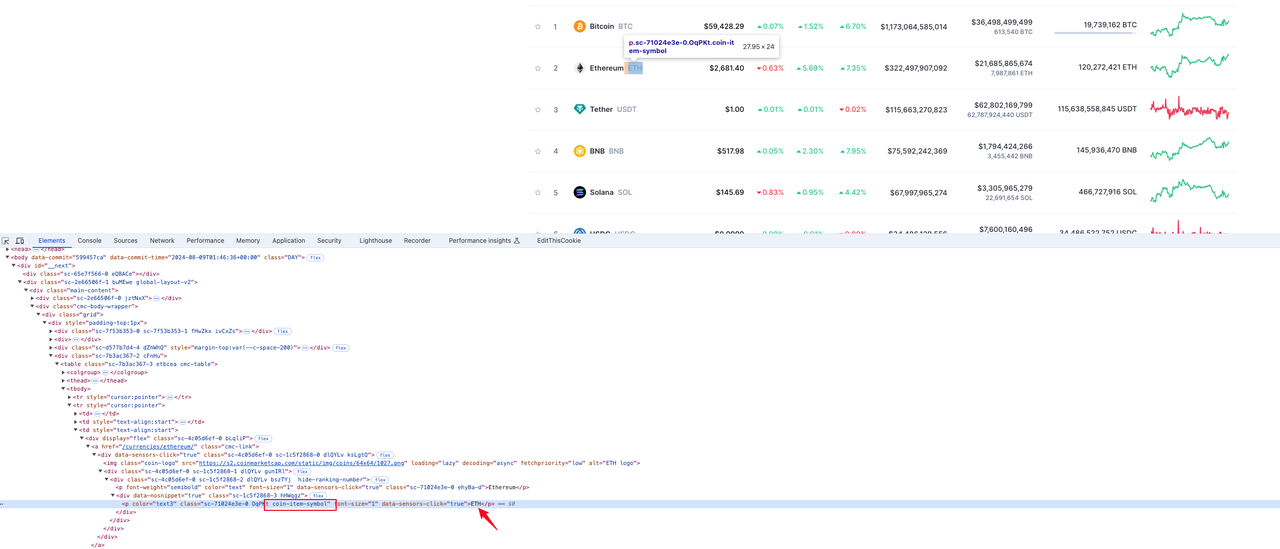
Ký hiệu tiền tệ
Phần tử nơi thông tin tiền tệ nằm trong giá trị thẻ p có tên lớp coin-item-symbol trong phần tử hàng tr:
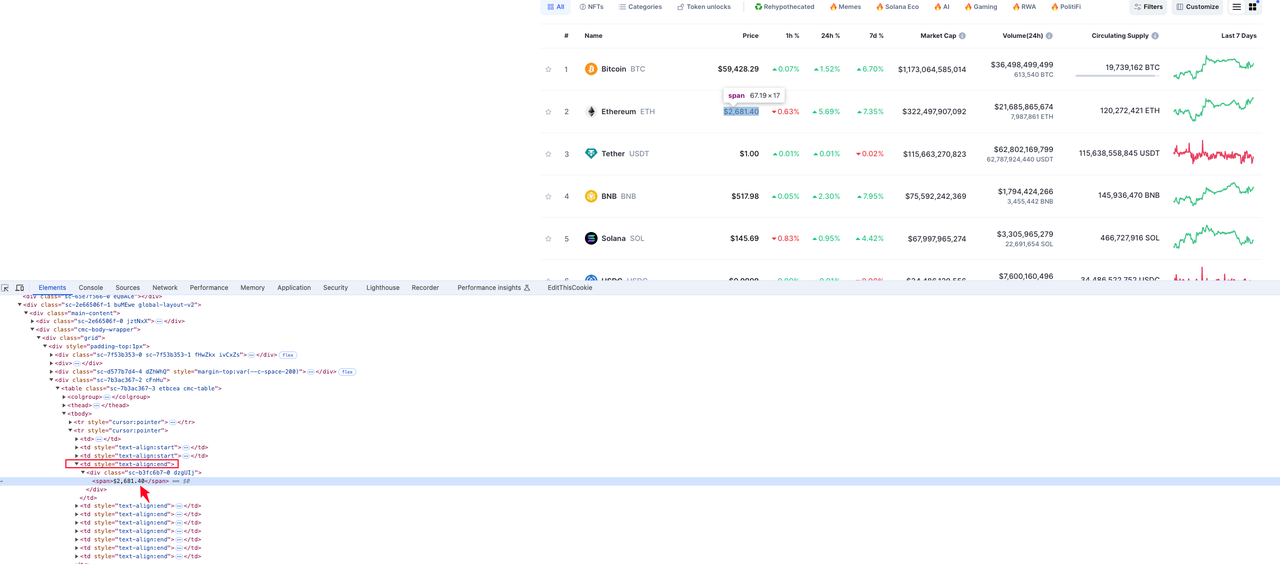
Giá tiền tệ
Phần tử nơi thông tin tiền tệ nằm trong giá trị phần tử div span dưới phần tử td thứ tư trong phần tử hàng tr:
Sau khi phân tích, chúng ta đã thu thập được các phần tử nơi dữ liệu mục tiêu nằm. Bạn có thể tự nghiên cứu thêm về phân tích phần tử dữ liệu khác.
Mã hóa
Không cần nói nhiều nữa, hãy bắt đầu với đoạn mã ngay thôi:
Phụ thuộc (build.gradle)
Java
dependencies {
implementation 'com.squareup.okhttp3:okhttp:4.12.0'
implementation 'com.google.code.gson:gson:2.10.1'
implementation 'org.jsoup:jsoup:1.17.2'
implementation "org.seleniumhq.selenium:selenium-java:4.14.1"
}CmcRank.java
Java
public class CMCRank {
// thứ hạng coin
private Integer rank;
// ký hiệu coin
private String coinSymbol;
// logo coin
private String coinLogo;
// giá coin
private String price;
// getter và setter đã bị bỏ qua
}CmcScraper.java
Java
import com.google.gson.Gson;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
import org.openqa.selenium.*;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class CmcScraper {
// http client
private static final OkHttpClient client = new OkHttpClient();
// gson
private static final Gson gson = new Gson();
// apiKey của bạn
private static final String API_KEY = "your apikey";
// profileId của bạn
private static final String PROFILE_ID = "your profileId";
// url website cmc
private static final String BASE_URL = "https://coinmarketcap.com";
// url cơ bản của API nstbrowser
private final String baseUrl;
// đường dẫn tệp webdriver
private final String webdriverPath;
public CmcScraper(String baseUrl, String webdriverPath) {
this.baseUrl = baseUrl;
this.webdriverPath = webdriverPath;
}
public void scrape() {
String url = String.format("%s/devtool/launch/%s", this.baseUrl, PROFILE_ID);
Request request = new Request.Builder()
.url(url)
.get()
.addHeader("Content-Type", "application/json")
.addHeader("x-api-key", API_KEY)
.build();
try (Response response = client.newCall(request).execute()) {
if (!response.isSuccessful()) {
throw new IOException("Unexpected code " + response);
}
Map<String, Object> responseBody = gson.fromJson(response.body().string(), Map.class);
Map<String, Object> data = (Map<String, Object>) responseBody.get("data");
Double port = (Double) data.get("port"); // lấy port trình duyệt
if (port != null) {
this.execSelenium("localhost:" + port.intValue());
} else {
throw new IOException("Port không được tìm thấy trong phản hồi");
}
} catch (IOException e) {
throw new RuntimeException("Thất bại trong việc scrape", e);
}
}
public void execSelenium(String debuggerAddress) {
System.setProperty("webdriver.chrome.driver", this.webdriverPath);
ChromeOptions options = new ChromeOptions();
options.setExperimentalOption("debuggerAddress", debuggerAddress);
try {
WebDriver driver = new ChromeDriver(options);
driver.get(BASE_URL);
WebElement cmcTable = driver.findElement(By.cssSelector("table.cmc-table"));
if (cmcTable != null) {
List<WebElement> tableRows = cmcTable.findElements(By.cssSelector("tbody tr"));
List<CMCRank> cmcRanks = new ArrayList<>(tableRows.size());
for (WebElement row : tableRows) {
CMCRank cmcRank = extractCMCRank(row);
if (cmcRank != null) {
System.out.println(gson.toJson(cmcRank));
cmcRanks.add(cmcRank);
}
}
// TODO
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
private CMCRank extractCMCRank(WebElement row) {
try {
CMCRank cmcRank = new CMCRank();
List<WebElement> tds = row.findElements(By.tagName("td"));
if (tds.size() > 1) {
WebElement rankElem = tds.get(1).findElement(By.tagName("p"));
// tìm thứ hạng coin
if (rankElem != null && !rankElem.getText().isEmpty()) {
cmcRank.setRank(Integer.valueOf(rankElem.getText()));
}
// tìm logo coin
WebElement logoElem = row.findElement(By.cssSelector("img.coin-logo"));
if (logoElem != null) {
cmcRank.setCoinLogo(logoElem.getAttribute("src"));
}
// tìm ký hiệu coin
WebElement symbolElem = row.findElement(By.cssSelector("p.coin-item-symbol"));
if (symbolElem != null && !symbolElem.getText().isEmpty()) {
cmcRank.setCoinSymbol(symbolElem.getText());
}
// tìm giá coin
WebElement priceElem = tds.get(3).findElement(By.cssSelector("div span"));
if (priceElem != null) {
cmcRank.setPrice(priceElem.getText());
}
}
return cmcRank;
} catch (NoSuchElementException e) {
System.err.println("Thất bại trong việc lấy thông tin coin: " + e.getMessage());
return null;
}
}
}Main.java
Java
public class Main {
public static void main(String[] args) {
String baseUrl = "http://localhost:8848";
String webdriverPath = "đường dẫn tệp chromedriver của bạn";
CmcScraper scraper = new CmcScraper(baseUrl, webdriverPath);
scraper.scrape();
}
}Chạy chương trình
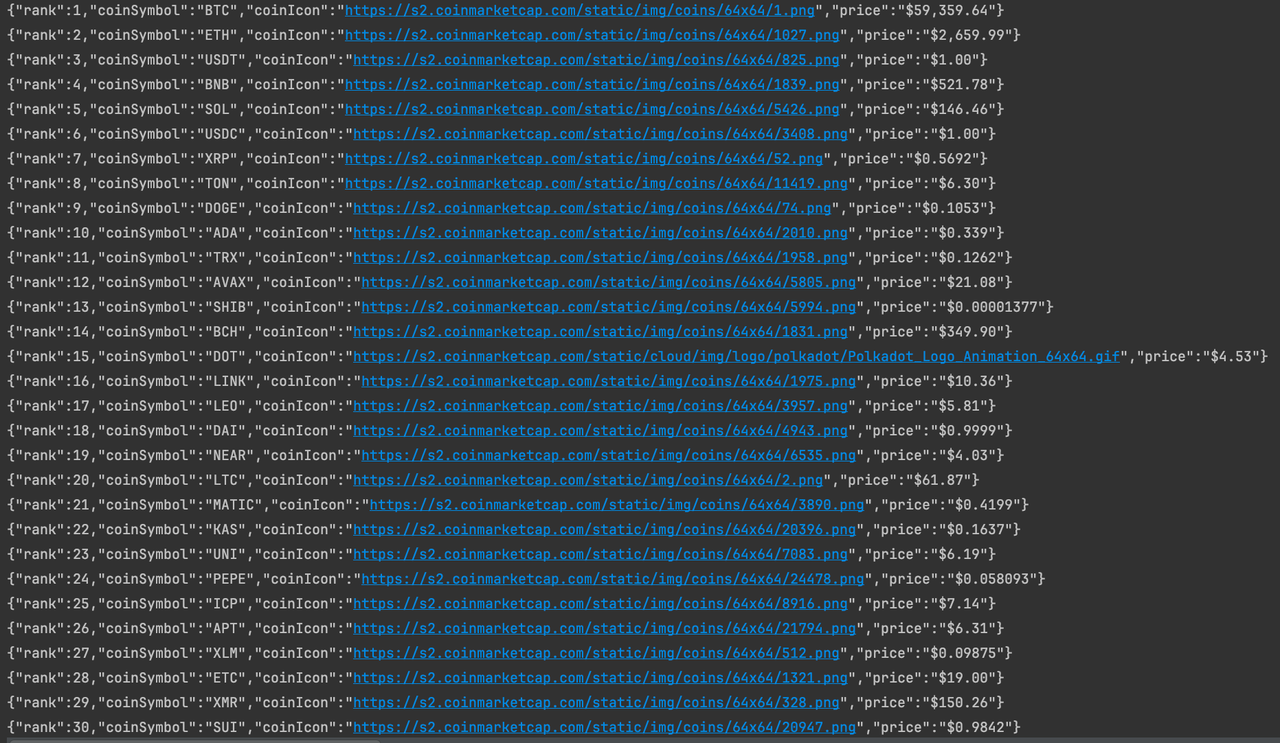
Cho đến bây giờ, chúng ta đã thành công trong việc crawl dữ liệu thông tin tiền điện tử trên trang chủ của CoinmarketCap. Nếu bạn quan tâm, bạn có thể phân tích trang kỹ hơn để crawl thêm dữ liệu.
Kết luận
Tại sao Java là một ngôn ngữ lập trình tuyệt vời cho việc crawl dữ liệu web? Làm thế nào để crawl toàn bộ một website bằng Java? Sự khác biệt giữa web crawler và web scraping là gì? Không vấn đề gì, bạn đã học tất cả những gì bạn cần biết để thực hiện việc crawl dữ liệu chuyên nghiệp với Java trong blog này.
Tuy nhiên, điều quan trọng nhất khi thực hiện web crawling là: trình crawler của bạn phải có khả năng vượt qua các hệ thống chống bot. Đây là lý do tại sao bạn cần một trình duyệt chống phát hiện có thể vượt qua việc chặn website.
Nstbrowser cung cấp mọi thứ tuyệt vời cho việc web scraping.
Hơn





