
Web Scraping
Urllib, Urllib3 và Yêu cầu: Cái nào là tốt nhất cho bạn khi quét web?
Urllib, urllib3 và request là 3 thư viện Python thông dụng và tuyệt vời. Sự khác biệt của 3 cái này là gì? Hãy đọc bài viết này và tìm ra bài viết phù hợp nhất với bạn nhé!
Jul 17, 2024Tạ Quí Lĩnh
Bạn luôn sử dụng Python để web scraping? Vậy bạn cũng phải bối rối về thư viện HTTP client tốt nhất giữa Urllib, Urllib3 và Requests như tôi đúng không?
Đúng vậy, trong lập trình Python, xử lý các yêu cầu HTTP là một yêu cầu phổ biến.
Python cung cấp nhiều thư viện để thực hiện chức năng này, và Urllib, Urllib3 và Requests là 3 thư viện phổ biến nhất.
Điều gì đặc biệt về chúng? Thư viện nào phù hợp với bạn?
Chúng đều có các tính năng và lợi ích độc đáo của riêng họ. Hãy bắt đầu đọc bài viết này và tìm hiểu nhé!
Tổng quan so sánh
| Thư viện | Urllib | Urllib3 | Requests |
|---|---|---|---|
| Yêu cầu cài đặt | Không | Có | Có |
| Tốc độ | Trung bình | Nhanh | Trung bình |
| Xử lý phản hồi | Thường cần các bước giải mã | Không cần bước giải mã thêm | Không cần bước giải mã thêm |
| Connection pooling | Không hỗ trợ | Hỗ trợ | Hỗ trợ |
| Dễ sử dụng | Cú pháp phức tạp hơn | Dễ sử dụng | Dễ sử dụng và thân thiện với người mới bắt đầu |
1. Urllib
Urllib là một phần của thư viện tiêu chuẩn của Python để xử lý URL, và bạn không cần phải cài đặt thêm bất kỳ thư viện nào để sử dụng nó.
Khi bạn sử dụng Urllib để gửi yêu cầu, nó trả về một mảng byte của đối tượng phản hồi. Tuy nhiên, tôi phải nói rằng mảng byte được trả về của nó đòi hỏi một bước giải mã bổ sung, điều này có thể khó khăn đối với người mới bắt đầu.
Điều đặc biệt về Urllib là gì?
Urllib cho phép kiểm soát tinh vi với giao diện cấp thấp, nhưng điều này cũng có nghĩa là người dùng thường cần phải viết thêm mã. Vì vậy, người dùng thường cần phải tự động hóa mã hóa URL, thiết lập tiêu đề yêu cầu và giải mã phản hồi.
Nhưng đừng lo lắng! Urllib cung cấp các chức năng cơ bản của yêu cầu HTTP như yêu cầu GET và POST và nó cũng hỗ trợ phân tích cú pháp, mã hóa và giải mã URL.
Ưu điểm & Nhược điểm
Ưu điểm:
- Không cần cài đặt thêm. Bởi vì nó là một phần của thư viện tiêu chuẩn của Python, bạn không cần phải cài đặt thêm bất kỳ thư viện nào khi sử dụng nó.
- Chức năng toàn diện. Hỗ trợ xử lý yêu cầu URL, phản hồi và phân tích cú pháp.
Nhược điểm:
- Độ phức tạp cao. Các bước gửi yêu cầu và xử lý phản hồi rất phức tạp.
- Mảng byte cần được xử lý thủ công. Phản hồi được trả về cần phải được giải mã thủ công, làm tăng thêm một bước.
Urllib có thể được sử dụng để làm gì?
Urllib thích hợp cho các nhiệm vụ đơn giản như yêu cầu HTTP, đặc biệt là khi bạn không muốn cài đặt các thư viện bên thứ ba.
Nó cũng có thể học và hiểu các nguyên lý cơ bản. Vì vậy, người dùng có thể sử dụng nó để học và hiểu về cài đặt cơ bản của yêu cầu HTTP.
Tuy nhiên, do urllib thiếu các tính năng nâng cao như quản lý connection pool, nén mặc định và xử lý JSON, việc sử dụng nó khá phức tạp, đặc biệt là đối với các yêu cầu HTTP phức tạp.
2. Urllib3
Urllib3 cung cấp các trừu tượng cấp cao, bao gồm API yêu cầu, connection pool, nén mặc định, mã hóa và giải mã JSON, và nhiều hơn nữa.
Áp dụng các tính năng này rất đơn giản! Bạn có thể tùy chỉnh yêu cầu HTTP chỉ với vài dòng mã. Urllib3 sử dụng các phần mở rộng C để cải thiện hiệu suất. Do đó, nó là nhanh nhất trong số ba thư viện.
Điều đặc biệt về Urllib3 là gì?
Urllib3 cung cấp một giao diện cao cấp hơn. Nó cũng hỗ trợ các tính năng nâng cao như connection pool, tự động thử lại, cấu hình SSL và tải lên tập tin:
- Connection pool: Quản lý các connection pool để giảm thiểu overhead kết nối TCP lặp lại.
- Cơ chế thử lại: Tự động thử lại yêu cầu để cải thiện độ ổn định.
- Nén mặc định: Hỗ trợ nén và giải nén dữ liệu yêu cầu và phản hồi.
- Hỗ trợ JSON: Mặc dù không phải là tính năng tích hợp, nó có thể được sử dụng cùng với module JSON để xử lý dữ liệu JSON.
- Xác minh SSL: Cung cấp hỗ trợ SSL tốt hơn và tùy chọn cấu hình.
Ưu điểm & Nhược điểm
Ưu điểm:
- Các tính năng nâng cao hơn. Cung cấp các tính năng nâng cao hơn so với urllib, chẳng hạn như connection pool, tải lên file, thử lại yêu cầu, v.v.
- Dễ sử dụng hơn. Cú pháp đơn giản hơn so với urllib, giảm bớt độ phức tạp của mã lập trình.
Nhược điểm:
- Yêu cầu cài đặt. Bạn cần sử dụng pip để cài đặt urllib3 (pip install urllib3).
Urllib3 có thể được sử dụng để làm gì?
Người dùng có thể áp dụng urllib3 cho một số yêu cầu HTTP phức tạp, chẳng hạn như x
ử lý các yêu cầu song song, quản lý connection pool, v.v.
Urllib3 cũng phù hợp với một số yêu cầu cần hiệu suất và độ ổn định cao.
3. Requests
Requests là một thư viện phổ biến để gửi các yêu cầu HTTP. Nó nổi tiếng với thiết kế API đơn giản và các chức năng mạnh mẽ, làm cho việc tương tác với mạng rất dễ dàng.
Các yêu cầu HTTP được gửi thông qua requests sẽ trở nên rất đơn giản và trực quan. Ngoài ra, nó có các chức năng tích hợp như xử lý cookie, phiên, cài đặt proxy và dữ liệu JSON, đảm bảo trải nghiệm thân thiện với người dùng.
Nó cũng có một số tính năng mạnh mẽ:
- API đơn giản: Cung cấp giao diện đơn giản nhất và dễ nhất để sử dụng. Đó là lý do tại sao yêu cầu HTTP rất trực quan.
- Connection pool: Quản lý connection pool được tích hợp sẵn.
- Nén mặc định: Tự động xử lý nén của các yêu cầu và phản hồi.
- Hỗ trợ JSON: Rất tiện lợi để xử lý dữ liệu JSON với
requestsnhờ vào các chức năng mã hóa và giải mã JSON tích hợp. - Các chức năng phong phú: Bao gồm tải lên file, tải xuống dữ liệu theo luồng, duy trì phiên, v.v.
Ưu điểm & Nhược điểm
Ưu điểm:
- Cú pháp ngắn gọn và thân thiện với người dùng nhất.
Requestscung cấp giao diện đơn giản và dễ hiểu nhất. Do đó, việc gửi các yêu cầu HTTP sẽ rất dễ dàng. - Sử dụng
urllib3tích hợp. Sử dụngurllib3ở dưới cùng, kết hợp hiệu suất cao và các chức năng nâng cao trong khi che giấu sự phức tạp. - Phổ biến và được cộng đồng hỗ trợ. Do được sử dụng rộng rãi, có rất nhiều tài liệu, hướng dẫn và hỗ trợ từ cộng đồng.
Nhược điểm:
- Yêu cầu cài đặt. Requests cần được cài đặt bằng pip (pip install requests).
- Mặc dù có các tính năng phong phú, hiệu suất của nó tương đối chậm do sự trừu tượng cao của nó.
Requests có thể được sử dụng để làm gì?
Requests thích hợp cho hầu hết các kịch bản yêu cầu HTTP, đặc biệt là cho các web crawler và yêu cầu API. Nhờ vào cú pháp ngắn gọn và tài liệu phong phú, nó cũng đặc biệt thích hợp cho người mới bắt đầu.
So sánh hiệu suất
Theo kết quả thử nghiệm, hiệu suất của ba thư viện này sau 100 lượt lặp là như sau:
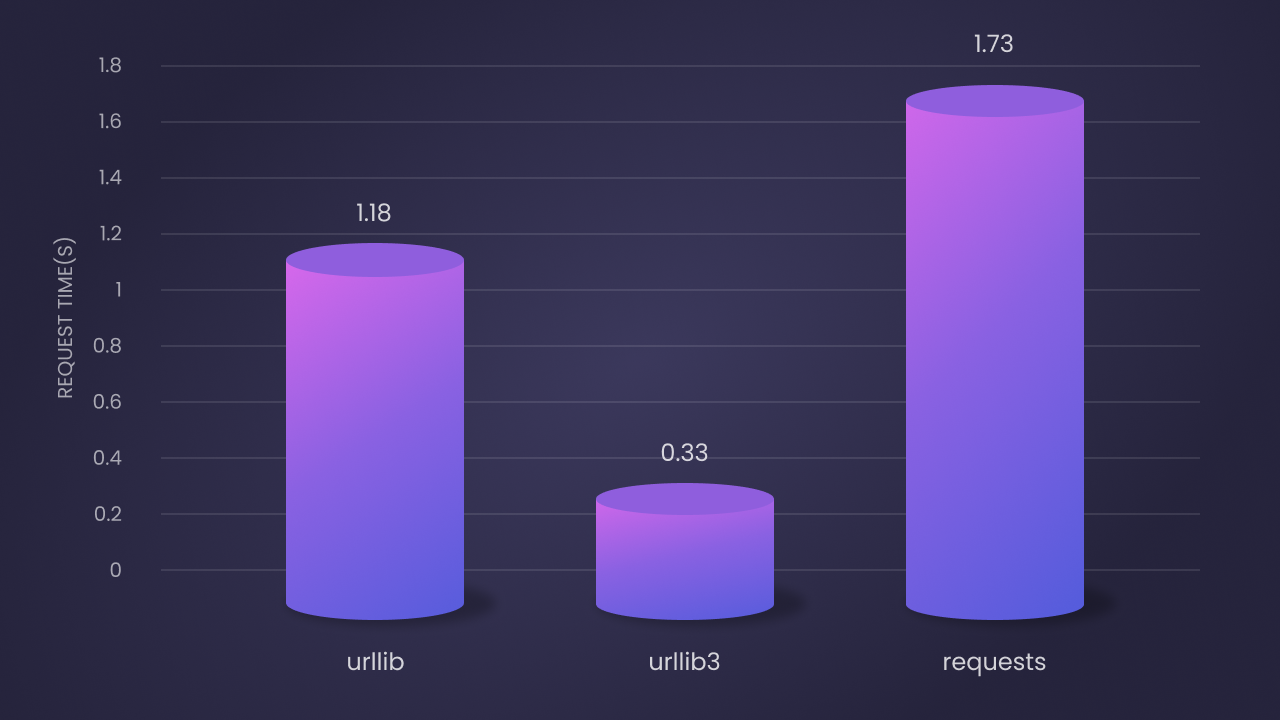
Urlliblà thứ hai về tốc độ: thời gian yêu cầu trung bình là 1.18 giây. Mặc dù nó là một triển khai Python thuần túy, nhưng nó có hiệu suất tốt hơn nhờ vào cài đặt cơ bản.Urllib3là nhanh nhất: thời gian yêu cầu trung bình là 0.33 giây. Điều này là do sự mở rộng C và quản lý connection pool hiệu quả.Requestslà chậm nhất: thời gian yêu cầu trung bình là 1.73 giây. Nhưng cú pháp ngắn gọn và tính năng phong phú của nó bù đắp cho điểm yếu này.
Lời khuyên lựa chọn
- Nếu bạn muốn dựa vào ít thư viện bên ngoài càng tốt và các yêu cầu dự án đơn giản, bạn có thể chọn Urllib. Nó là một phần của thư viện tiêu chuẩn và không cần phải cài đặt riêng biệt.
- Nếu bạn cần hiệu suất cao và các tính năng nâng cao và không phiền lòng với một số thao tác kỹ thuật, urllib3 là một lựa chọn tốt.
- Nếu bạn theo đuổi mã ngắn gọn và một giao diện dễ sử dụng nhất, đặc biệt là khi xử lý các yêu cầu HTTP phức tạp, requests là lựa chọn lý tưởng. Nó là thư viện dễ sử dụng nhất và được sử dụng rộng rãi cho web crawler và yêu cầu API.
2 Phương pháp hiệu quả để tránh bị chặn khi Scraping
Nhiều trang web đã tích hợp hệ thống chống bot để phát hiện và chặn các kịch bản tự động như web scraper. Vì vậy, việc bypass những rào cản này để truy cập dữ liệu là rất quan trọng!
Một cách để tránh bị phát hiện là sử dụng Nstbrowser để tránh chặn IP. Urllib và urllib3 cũng có khả năng tích hợp để thêm proxy vào các yêu cầu HTTP.
Nstbrowser được thiết kế với tính năng xoay IP và mở khóa web.
Thử Nstbrowser miễn phí để tránh chặn IP!
Bạn có suy nghĩ hoặc câu hỏi nào về việc thu thập dữ liệu web và Browseless không?
Hãy đến xem những gì các nhà phát triển khác đang chia sẻ trên Discord và Telegram!
Phương pháp 1: Sử dụng Nstbrowser để bypass hệ thống chống bot
Trước khi bắt đầu, bạn cần đáp ứng một số điều kiện sau:
- Trở thành người dùng của Nstbrowser.
- Lấy API Key của Nstbrowser.
- Chạy dịch vụ Nstbrowserless trên máy cục bộ.
Dưới đây là các bước cụ thể. Chúng ta sẽ lấy ví dụ về việc scrap nội dung tiêu đề của một trang trên website Amazon.
Nếu chúng ta cần scrap nội dung tiêu đề h3 của trang web sau:
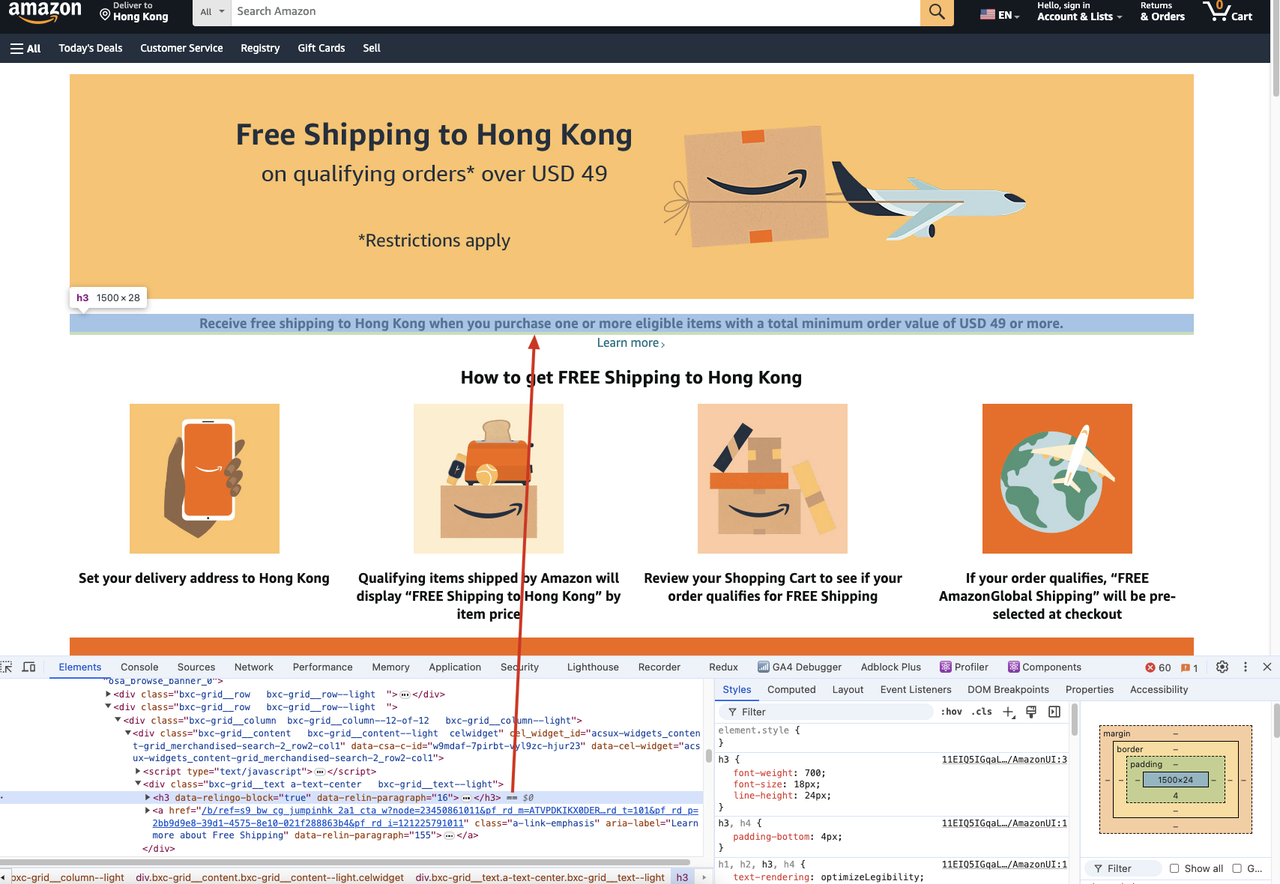
Chúng ta sẽ chạy đoạn mã sau đây:
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # thiết lập chế độ headless
"autoClose": True,
"args": {"--disable-gpu": "", "--no-sandbox": ""}, # các đối số của trình duyệt nên là một từ điển
"fingerprint": {
"name": 'amazon_scraper',
"platform": 'mac', # hỗ trợ: windows, mac, linux
"kernel": 'chromium', # chỉ hỗ trợ: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8,
"deviceMemory": 8,
},
}
query = {'config': json.dumps(config)}
profileUrl = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
print("URL Hồ sơ: ", profileUrl)
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profileUrl)
try:
page = await browser.new_page()
await page.goto("https://www.amazon.com/b/?_encoding=UTF8&node=121225791011&pd_rd_w=Uoi8X&content-id=amzn1.sym.dde8a7c4-f315-46af-87af-ab98d7f18222&pf_rd_p=dde8a7c4-f315-46af-87af-ab98d7f18222&pf_rd_r=CM6698M8C3J02BBVTVM3&pd_rd_wg=olMbe&pd_rd_r=ff5d2eaf-26db-4aa4-a4dd-e74ea389f355&ref_=pd_hp_d_atf_unk&discounts-widget=%2522%257B%255C%2522state%255C%2522%253A%257B%255C%2522refinementFilters%255C%2522%253A%257B%257D%257D%252C%255C%2522version%255C%2522%253A1%257D%2522")
await page.wait_for_selector('h3')
title = await page.inner_text('h3')
print(title)
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())Trong mã trên, chúng ta chủ yếu đã thực hiện các bước sau:
- Tạo dịch vụ Nstbrowser và thiết lập chế độ headless và một số tham số khởi động cơ bản trong cấu hình khởi động.
- Sử dụng Playwright để kết nối với Nstbrowser.
- Đi tới trang tương ứng cần scrap để lấy nội dung của nó.
Sau khi thực thi mã trên, cuối cùng bạn sẽ thấy kết quả đầu ra như sau:

Phương pháp 2: Sử dụng tiêu đề yêu cầu tùy chỉnh để mô phỏng một trình duyệt thực
Bước 1. Chúng ta nên sử dụng Playwright và Nstbrowser để truy cập vào một trang web có thể lấy thông tin tiêu đề yêu cầu hiện tại.
- Minh họa mã:
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # thiết lập chế độ headless
"autoClose": True,
"args": {"--disable-gpu": "", "--no-sandbox": ""}, # các đối số của trình duyệt nên là một từ điển
"fingerprint": {
"name": 'amazon_scraper',
"platform": 'mac', # hỗ trợ: windows, mac, linux
"kernel": 'chromium', # chỉ hỗ trợ: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8,
"deviceMemory": 8,
},
}
query = {'config': json.dumps(config)}
profileUrl = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
print("URL Hồ sơ: ", profileUrl)
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profileUrl)
try:
page = await browser.new_page()
await page.goto("https://httpbin.org/headers")
await page.wait_for_selector('pre')
content = await page.inner_text('pre')
print(content)
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
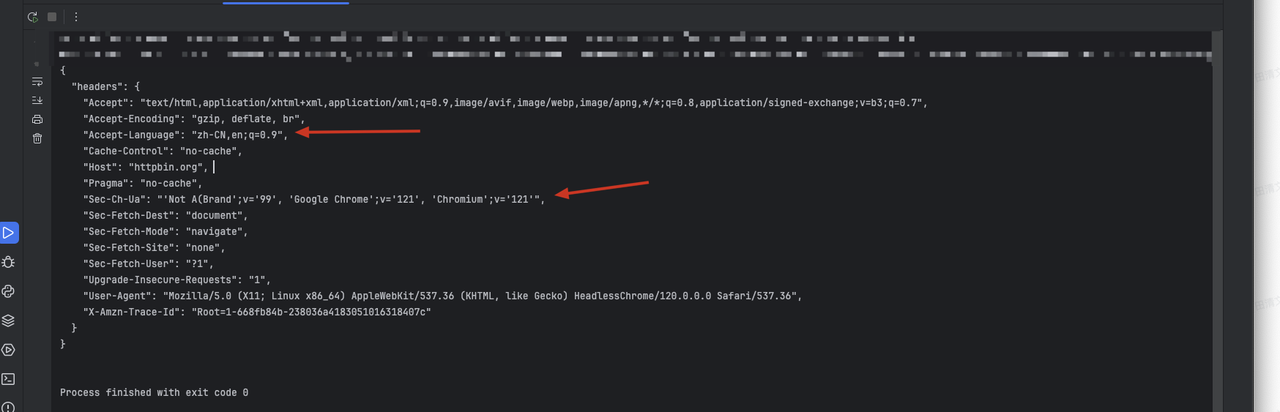
asyncio.run(main())Thông qua mã trên, chúng ta sẽ thấy kết quả đầu ra như sau:
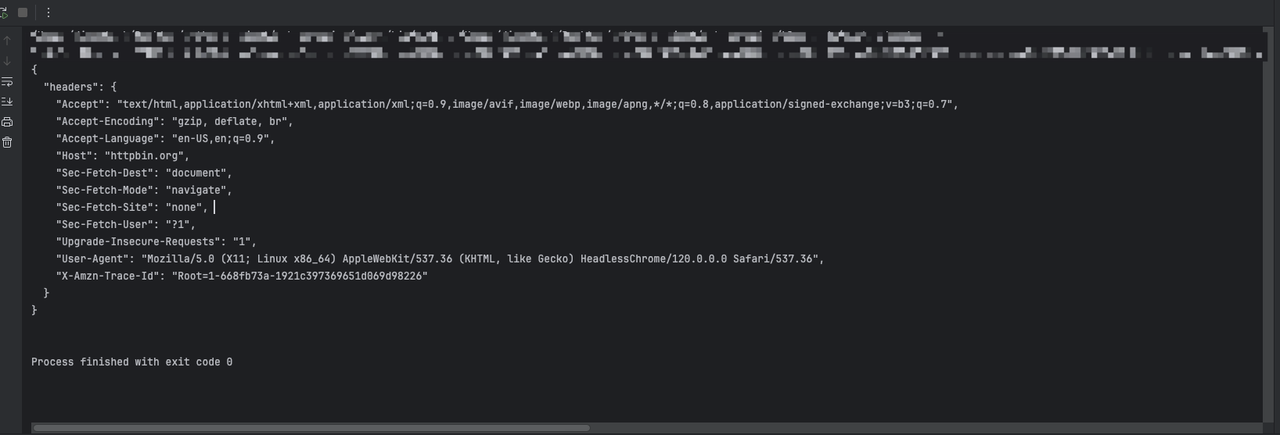
Bước 2. Chúng ta cần sử dụng Playwright để thêm thông tin tiêu đề yêu cầu bổ sung bằng cách thiết lập chặn yêu cầu khi tạo trang:
Python
{
'sec-ch-ua': '\'Not A(Brand\';v=\'99\', \'Google Chrome\';v=\'121\', \'Chromium\';v=\'121\'',
'accept-Language': 'zh-CN,en;q=0.9'
}- Minh họa mã:
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
extra_headers = {
'sec-ch-ua': '\'Not A(Brand\';v=\'99\', \'Google Chrome\';v=\'121\', \'Chromium\';v=\'121\'',
'accept-Language': 'en-US,en;q=0.9'
}
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # thiết lập chế độ headless
"autoClose": True,
"args": ["--disable-gpu", "--no-sandbox"], # các đối số của trình duyệt nên là một danh sách
"fingerprint": {
"name": 'amazon_scraper',
"platform": 'mac', # hỗ trợ: windows, mac, linux
"kernel": 'chromium', # chỉ hỗ trợ: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8,
"deviceMemory": 8,
},
}
query = {'config': json.dumps(config)}
profileUrl = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
print("URL Hồ sơ: ", profileUrl)
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profileUrl)
try:
context = await browser.new_context()
page = await context.new_page()
# Thêm chặn yêu cầu để thiết lập các tiêu đề bổ sung
await page.route('**/*', lambda route, request: route.continue_(headers={**request.headers, **extra_headers}))
response = await page.goto("https://httpbin.org/headers")
print(await response.text())
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())Thông qua đoạn mã trên, chúng ta sẽ nhận được thông tin kết quả như sau, trong đó thông tin tiêu đề tùy chỉnh mà chúng ta thiết lập sẽ được thêm vào:
- Tiêu đề
sec-ch-ua. - Nội dung đã thay đổi của tiêu đề gốc
accept-Language.
Lời nhắc cuối cùng
Nói chung:
Requestsđã trở thành sự lựa chọn hàng đầu đối với hầu hết các nhà phát triển nhờ vào tính dễ sử dụng và các chức năng phong phú.Urllib3xuất sắc khi hiệu suất và các tính năng nâng cao được yêu cầu.- Là một phần của thư viện chuẩn,
urllibphù hợp với các dự án có yêu cầu phụ thuộc cao.
Tùy thuộc vào nhu cầu và tình huống cụ thể của bạn, việc chọn công cụ phù hợp nhất sẽ giúp bạn xử lý các yêu cầu HTTP một cách hiệu quả hơn.
Hơn





