
Web Scraping
Trình duyệt chống phát hiện tốt nhất để quét web năm 2024
Trình duyệt chống phát hiện giúp bạn ẩn dấu vân tay của trình duyệt khi quét trang web. Nó thực sự đơn giản hóa công việc của bạn. Đọc blog này và tìm thấy nhiều hơn nữa!
Jul 19, 2024Triệu Lệ Chi
Trình Duyệt Chống Phát Hiện Là Gì?
Trình duyệt chống phát hiện có khả năng tạo và vận hành nhiều danh tính số không bị các nền tảng xã hội nhận diện. Điều này đòi hỏi nhiều công việc tùy chỉnh từ các nhà phát triển, vì vậy các công cụ như vậy thường không được cung cấp miễn phí.
Chúng được tạo ra để chống lại việc theo dõi và phân tích để bạn có thể thực hiện các hoạt động của mình một cách riêng tư. Nói cách khác, một trình duyệt chống dấu vân tay tăng cường quyền riêng tư, giữ cho dữ liệu và hoạt động web của bạn ẩn danh, và giúp các công cụ thu thập dữ liệu web của bạn tránh bị chặn.
Thử miễn phí trình duyệt chống phát hiện - Nstbrowser!
Mở khóa 99.9% các trang web với nhiều giải pháp hiệu quả
Đơn giản hóa việc thu thập dữ liệu web và tự động hóa
Bạn có suy nghĩ hoặc câu hỏi nào về việc thu thập dữ liệu web và Browseless không?
Hãy đến xem những gì các nhà phát triển khác đang chia sẻ trên Discord và Telegram!
Trình Duyệt Chống Phát Hiện Giúp Thu Thập Dữ Liệu Như Thế Nào?
Một trình duyệt chống phát hiện giúp giảm thiểu tác động của việc can thiệp web. Nó giảm thiểu hoặc thậm chí ngăn chặn các trang web nhận diện người dùng và theo dõi hoạt động trực tuyến của họ.
Vì các trang web có hệ thống chống thu thập dữ liệu, khi bạn sử dụng một bot thu thập dữ liệu để thu thập dữ liệu trực tiếp, bạn sẽ bị phát hiện và do đó bị chặn bởi trang web. Người dùng con người được ưu tiên hơn bot và một số trang web không khuyến khích các doanh nghiệp khác thu thập dữ liệu của họ.
Do đó, nhiều tổ chức kết hợp công nghệ thu thập dữ liệu web và các trình duyệt chống phát hiện với các biện pháp bảo mật như proxy để hỗ trợ ẩn danh các bot.
Nstbrowser Là Gì?
Nstbrowser là một trình duyệt chống dấu vân tay hoàn toàn miễn phí, tích hợp với bot chống phát hiện, Web Unblocker, và Proxy Thông Minh. Nó hỗ trợ Cloud Container Clusters, Browserless, và giải pháp trình duyệt đám mây cấp doanh nghiệp tương thích với Windows/Mac/Linux.
Cách Thực Hiện Thu Thập Dữ Liệu Web Với Trình Duyệt Chống Phát Hiện?
Tiếp theo, hãy lấy ví dụ về việc thu thập dữ liệu với Nstbrowser. Chỉ với 5 bước đơn giản:
Bước 1: Chuẩn Bị
Trước khi thu thập dữ liệu, bạn phải thực hiện các chuẩn bị sau:
Shell
pip install pyppeteer requests jsonSau khi cài đặt pyppeteer, chúng ta cần tạo một tệp mới: scraping.py, và đưa các thư viện chúng ta vừa cài đặt cũng như một số thư viện hệ thống vào tệp:
Python
import asyncio
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from pyppeteer import launcherChúng ta có thể sử dụng pyppeteer ngay bây giờ không?
Xin vui lòng bình tĩnh!
Chúng ta đã dành vài phút để kết nối với Nstbrowser, nơi cung cấp một API để trả về webSocketDebuggerUrl cho pyppeteer.
Python
# get_debugger_url: Nhận URL debugger
def get_debugger_url(url: str):
try:
resp = requests.get(url).json()
if resp['data'] is None:
raise Exception(resp['msg'])
webSocketDebuggerUrl = resp['data']['webSocketDebuggerUrl']
return webSocketDebuggerUrl
except HTTPError:
raise Exception(HTTPError.response)
async def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'your api key'
config = {
'once': True,
'headless': False,
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, như Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # required
'name': 'custom browser',
'platform': 'windows', # support: windows, mac, linux
'kernel': 'chromium', # only support: chromium
'kernelMilestone': '120', # support: 113, 115, 118, 120
'hardwareConcurrency': 4, # support: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # support: 2, 4, 8
'proxy': '', # input format: schema://user:password@host:port eg: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # required
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
browser_ws_endpoint = get_debugger_url(url)
print("browser_ws_endpoint: " + browser_ws_endpoint) # pyppeteer connect Nstbrowser với browser_ws_endpoint
(
asyncio
.get_event_loop()
.run_until_complete(create_and_connect_to_browser())
)Tuyệt vời! Chúng ta đã lấy thành công webSocketDebuggerUrl của Nstbrowser!
Đã đến lúc kết nối pyppeteer với Nstbrowser:
Python
async def exec_pyppeteer(wsEndpoint: str):
browser = await launcher.connect(browserWSEndpoint = wsEndpoint)
page = await browser.newPage()Chạy đoạn mã chúng ta vừa viết trong terminal: python scraping.py, chúng ta đã mở thành công một Nstbrowser và tạo một tab mới trong đó.
Mọi thứ đã sẵn sàng, bây giờ, chúng ta có thể bắt đầu thu thập dữ liệu!
Bước 2: Truy cập trang web mục tiêu
Ví dụ: https://www.yahoo.com/
Python
options = {'timeout': 60000}
await page.goto('https://www.yahoo.com/', options)Bước 3: Thực thi mã
Thực thi mã một lần nữa và sau đó chúng ta sẽ truy cập trang web mục tiêu thông qua Nstbrowser.
Bây giờ chúng ta cần mở Devtool để xem thông tin cụ thể chúng ta muốn thu thập và chúng ta có thể thấy tất cả đều là các yếu tố với cùng cấu trúc dom.
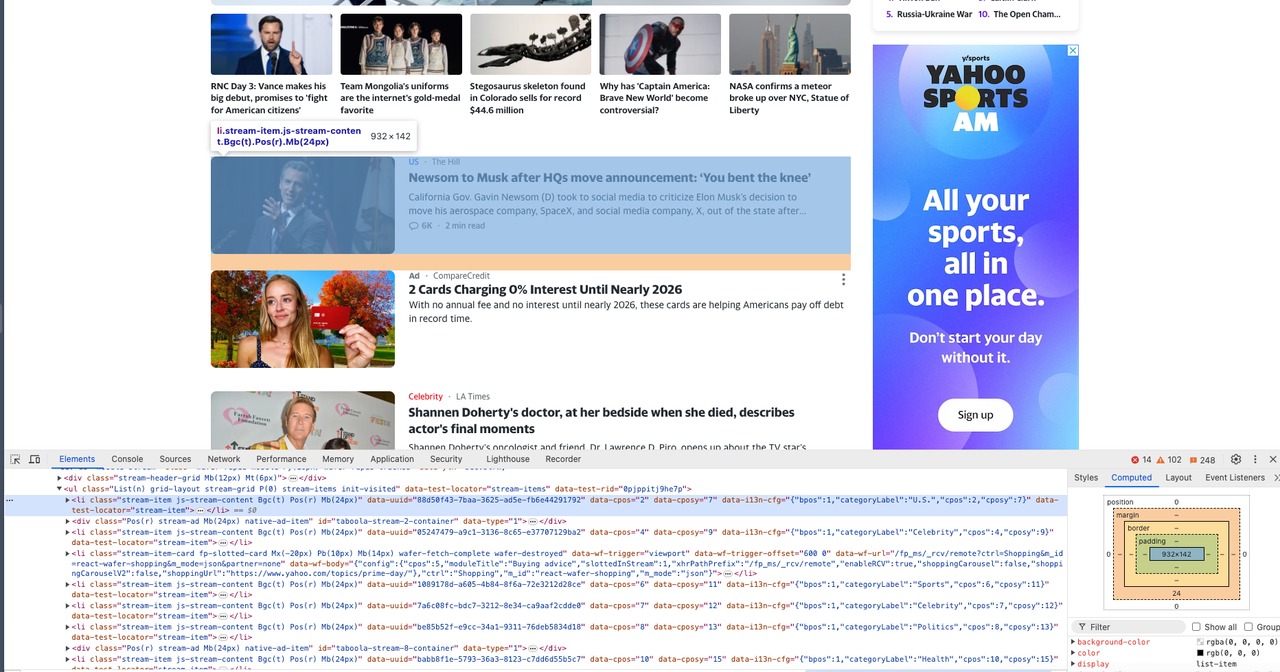
Bước 4: Thu thập trang web
Bây giờ, đến lúc sử dụng Pyppeteer để thu thập các cấu trúc dom này và phân tích nội dung của chúng:
Python
news = await page.JJ('li.stream-item')
for row in news:
title = await row.J('a:not([data-test-locator])')
content = await row.J('p')
comment = await row.J('span[data-test-locator="stream-comment"]')
title_text = await page.evaluate('item => item.textContent', title)
content_text = await page.evaluate('item => item.textContent', content)
comment_text = await page.evaluate('item => item.textContent', comment)
pringt('titile: ', title_text)
pringt('content: ', content_text)
pringt('comment: ', comment_text)Tất nhiên, chỉ xuất dữ liệu tại terminal không phải là mục tiêu cuối cùng của chúng ta, chúng ta cũng cần lưu dữ liệu.
Bước 5: Lưu dữ liệu
Chúng ta sử dụng thư viện json để lưu dữ liệu vào một tệp json cục bộ:
Python
news = await page.JJ('li.stream-item')
news_info = []
for row in news:
title = await row.J('a:not([data-test-locator])')
content = await row.J('p')
comment = await row.J('span[data-test-locator="stream-comment"]')
title_text = await page.evaluate('item => item.textContent', title)
content_text = await page.evaluate('item => item.textContent', content)
comment_text = await page.evaluate('item => item.textContent', comment)
news_item = {
"title": title_text,
"content": content_text,
"comment": comment_text
}
news_info.append(news_item)
# tạo tệp json
json_file = open("news.json", "w")
# chuyển đổi movies_info sang JSON
json.dump(news_info, json_file)
# giải phóng tài nguyên tệp
json_file.close()Chạy mã của chúng ta và sau đó mở thư mục nơi mã được đặt. Bạn sẽ thấy một tệp news.json mới xuất hiện. Mở nó để kiểm tra nội dung!
Nếu bạn thấy nó giống như thế này:
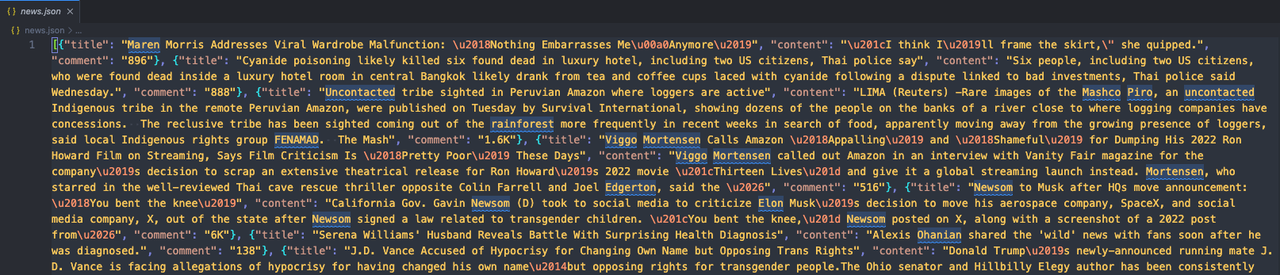
Điều đó có nghĩa là chúng ta đã thu thập thành công trang web mục tiêu bằng Pyppeteer và Nstbrowser!
Tại Sao Trình Duyệt Chống Phát Hiện Tốt Nhất Cho Việc Thu Thập Dữ Liệu Web?
Một trình duyệt chống phát hiện rất hiệu quả cho việc thu thập dữ liệu web nhờ khả năng mô phỏng hành vi duyệt web của con người và tránh bị phát hiện bởi các trang web. Hãy để tôi chỉ cho bạn 6 tính năng chính:
1. Tránh Bị Chặn IP
Các trang web thường theo dõi và giới hạn số lượng yêu cầu từ một địa chỉ IP duy nhất. Trình duyệt chống phát hiện có thể tích hợp với các dịch vụ proxy, cho phép người thu thập dữ liệu tự động thay đổi địa chỉ IP và tránh kích hoạt các giới hạn hoặc lệnh cấm.
2. Vượt Qua Dấu Vân Tay Trình Duyệt
Các trang web sử dụng dấu vân tay trình duyệt để phát hiện và chặn lưu lượng tự động. Trình duyệt chống phát hiện có thể thay đổi các đặc điểm của trình duyệt, chẳng hạn như user-agent, độ phân giải màn hình và các plugin đã cài đặt, tạo ra các dấu vân tay độc đáo làm cho các yêu cầu tự động trông như đến từ người dùng thực.
3. Tương Tác Giống Như Con Người
Trình duyệt chống phát hiện có thể mô phỏng các tương tác của con người như di chuyển chuột, nhấp chuột và nhập bàn phím. Hành vi này có thể giúp tránh các cơ chế phát hiện theo dõi các mẫu không phải của con người, làm cho quá trình thu thập dữ liệu trở nên tự nhiên hơn và ít có khả năng bị cấm.
4. Thay Đổi User Agent
Bất kỳ trình duyệt chống dấu vân tay nào cũng cho phép thay đổi các chuỗi user-agent, điều này giúp ngụy trang hoạt động thu thập dữ liệu. Vì vậy, các yêu cầu sẽ được nhận diện từ các trình duyệt và thiết bị khác nhau. Sự đa dạng trong các user-agent này làm cho các trang web khó nhận diện và chặn các bot thu thập dữ liệu.
5. Thực Thi JavaScript
Nhiều trang web hiện đại dựa nhiều vào JavaScript để hiển thị nội dung động. Trình duyệt chống phát hiện có thể thực thi JavaScript, đảm bảo rằng công cụ thu thập dữ liệu có thể truy cập và tương tác với nội dung không có sẵn trong mã nguồn HTML ban đầu.
6. Giải Quyết Captcha
Trình duyệt chống phát hiện thường hỗ trợ tích hợp với các dịch vụ giải quyết captcha. Tính năng này rất quan trọng để vượt qua các thử thách captcha mà các trang web áp dụng để ngăn chặn việc thu thập dữ liệu tự động.
Lời Kết
Với bất kỳ cá nhân nào chờ đợi cơ hội để đánh cắp dữ liệu của bạn và bất kỳ công ty nào chuẩn bị thu thập thông tin của bạn để phát triển công việc kinh doanh của họ, quyền riêng tư là rất quan trọng.
Trình duyệt chống phát hiện là một cách tuyệt vời để bảo vệ dữ liệu của bạn mà không bị các bot phát hiện. Chúng cũng có thể giúp bạn nâng cao nhiệm vụ thu thập dữ liệu web của mình.
Đã đến lúc sử dụng Nstbrowser để giúp bạn bảo vệ quyền riêng tư và thực hiện thu thập dữ liệu web nhanh chóng và hiệu quả!
Bạn cũng có thể thích:
Quản lý nhiều tài khoản với một trình duyệt chống phát hiện
Hơn





