
Web Scraping
Lỗi 403 Forbidden: Nó là gì? Làm thế nào để khắc phục nó?
Lỗi 403 cực kỳ khó chịu! Lỗi 403 bị cấm là gì? Giải quyết thế nào? Hãy tìm câu trả lời từ blog này.
Jul 12, 2024Triệu Lệ Chi
Lỗi 403 chắc hẳn bạn không còn lạ lẫm gì nữa! Lỗi này có thể khiến bạn mất lưu lượng truy cập và thậm chí là cơ hội kinh doanh!
Hả? Bạn gặp lỗi 403 trên trang web của mình? Hãy sửa nó ngay lập tức! Nhưng nguyên nhân của lỗi này là gì? Làm thế nào để khắc phục? Cả hai câu hỏi này đều quan trọng và có thể gây nhầm lẫn.
Bài viết trên blog này sẽ giúp bạn!
Khi đọc blog này, bạn sẽ học được:
- Nguyên nhân gây ra lỗi 403?
- Làm thế nào để khắc phục lỗi 403?
Hãy cuộn xuống ngay bây giờ!
Lỗi 403 là gì?
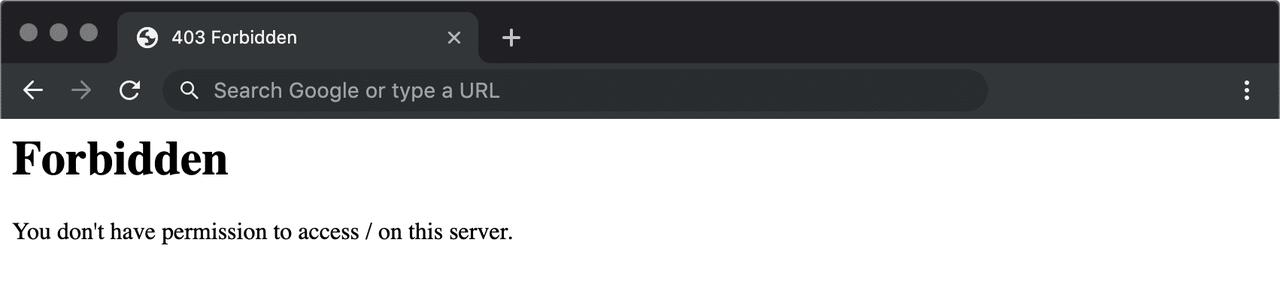
Lỗi 403 có nghĩa là máy chủ có thể hiểu rõ yêu cầu của bạn, nhưng bạn vẫn không thể truy cập trang web. Điều này thường là do quyền không đủ từ phía máy chủ hoặc thông tin xác thực bị thiếu.
Nói cách khác, máy chủ biết chính xác những gì bạn muốn làm, nhưng vì lý do nào đó, bạn không có quyền truy cập.
Nó giống như bạn muốn tham dự một sự kiện riêng tư, nhưng vì lý do nào đó, tên của bạn đã bị xóa khỏi danh sách khách mời.
Nguyên nhân gây ra lỗi 403?
Năm nguyên nhân phổ biến của lỗi 403:
- Quyền của tệp hoặc thư mục không đúng
- Tệp
.htaccesskhông đúng - Vấn đề về địa chỉ IP
- Xung đột plugin
- Thiếu một trang chỉ mục
1. Quyền của tệp hoặc thư mục không đúng
Nếu bạn cố gắng truy cập một tệp, thư mục hoặc thậm chí là một thư mục toàn bộ, và máy chủ không nhận ra các quyền được cung cấp bởi máy khách, quyền truy cập sẽ bị từ chối.
Để tránh lỗi này, hãy kiểm tra và thay đổi quyền của tệp hoặc thư mục.
Bash
# Đối với thư mục, thiết lập quyền là 755
chmod 755 /path/to/directory
# Đối với tệp, thiết lập quyền là 644
chmod 644 /path/to/file2. Tệp .htaccess không đúng
Một tệp .htaccess được cấu hình không đúng hoặc bị hỏng (ví dụ: bị nhiễm phần mềm độc hại) có thể gây ra nhiều vấn đề.
Làm thế nào để khắc phục? Kiểm tra và sửa tệp .htaccess, hoặc tạo một tệp mới.
Apache
# Ví dụ nội dung cho tệp .htaccess
<Directory "/path/to/directory">
AllowOverride All
Require all granted
</Directory>3. Vấn đề về địa chỉ IP
Dừng lại! Một địa chỉ IP miền không đúng hoặc hết hạn cũng có thể gây ra lỗi 403? Đúng vậy!
Vì vậy, hãy kiểm tra cấu hình DNS của miền để đảm bảo rằng nó đang trỏ đến đúng địa chỉ IP.
4. Vấn đề về plugin của WordPress
Lỗi thường xuất hiện khi người dùng cố gắng truy cập các trang web được cấu hình không đúng bởi plugin của WordPress. Điều này thường liên quan đến các plugin không tương thích hoặc cấu hình không đúng.
Ồ! Điều này cũng có thể là do máy chủ không thể truy cập thư mục wp-content trong thư mục gốc của WordPress.
Đã đến lúc vô hiệu hóa tất cả các plugin và kích hoạt chúng từng cái một để xác định cái nào đang gây ra vấn đề.
PHP
// Thêm mã sau vào wp-config.php để vô hiệu hóa tất cả các plugin
define('WP_ALLOW_REPAIR', true);5. Thiếu một trang chỉ mục
Nguyên nhân cuối cùng là nếu trang chủ của trang web của tôi không được đặt tên là "index.php" hoặc "index.html", tôi cũng sẽ gặp lỗi 403.
Vì vậy, bạn cần đảm bảo rằng tệp trang chủ của trang web được đặt tên đúng cách.
Làm thế nào để tránh bị chặn trang web dễ dàng để có quyền truy cập không giới hạn?
Hãy bắt đầu sử dụng Nstbrowser miễn phí ngay bây giờ!
Bạn có suy nghĩ hoặc câu hỏi nào về việc thu thập dữ liệu web và Browseless không?
Hãy đến xem những gì các nhà phát triển khác đang chia sẻ trên Discord và Telegram!
10 cách lỗi 403
- Error 403 – Forbidden: Lỗi truy cập tổng quát.
- 403 – Forbidden: Truy cập bị từ chối bởi máy chủ, có thể là vấn đề về quyền hoặc cấu hình không đúng.
- 403 Forbidden – nginx: Lỗi truy cập bị từ chối tổng quát.
- Forbidden – You don’t have permission to access /path on this server: Vấn đề về quyền trong thư mục gốc của máy chủ hoặc thiếu tệp chỉ mục.
- 403 – Forbidden Error – You don’t have permission to access this address: Truy cập bị từ chối đến một địa chỉ cụ thể.
- HTTP Error 403 – Forbidden – You do not have permission to access the requested document or program: Truy cập bị vô hiệu hóa đến tài liệu hoặc chương trình yêu cầu.
- 403 Forbidden – Access to the resource on this server is denied: Truy cập bị cấm đến tài nguyên trên máy chủ.
- 403. That’s an error. Your client does not have permission to get URL / from this server: Máy khách không có quyền truy cập vào URL được chỉ định.
- You don’t have permission to view this page: Bạn không có quyền xem trang này.
- It appears you don’t have permission to access this page: Bạn không có quyền truy cập vào trang mục tiêu này.
Làm thế nào để khắc phục lỗi 403?
Làm thế nào để tránh lỗi 403? Đây là năm phương pháp!
Phương pháp 1. Tránh lỗi 403 bằng cách sử dụng Nstbrowser:
Phương pháp hiệu quả nhất là sử dụng trình duyệt antidetec để tránh lỗi 403. Nó được trang bị nhiều biện pháp chống bot!
Nstbrowser cung cấp giải pháp toàn diện nhất, bao gồm render JavaScript, xoay proxy thông minh và phát hiện bot hiệu quả. Điều này giúp bạn tránh lỗi 403 và không bị chặn.
Tùy chọn 1: Tạo nhiều dấu vân tay của trình duyệt
Nstbrowser cung cấp các dấu vân tay trình duyệt thực tế, điều này có thể giải quyết lỗi 403 chỉ trong ba bước sau khi đăng ký:
Bước 1. Tạo nhiều hồ sơ
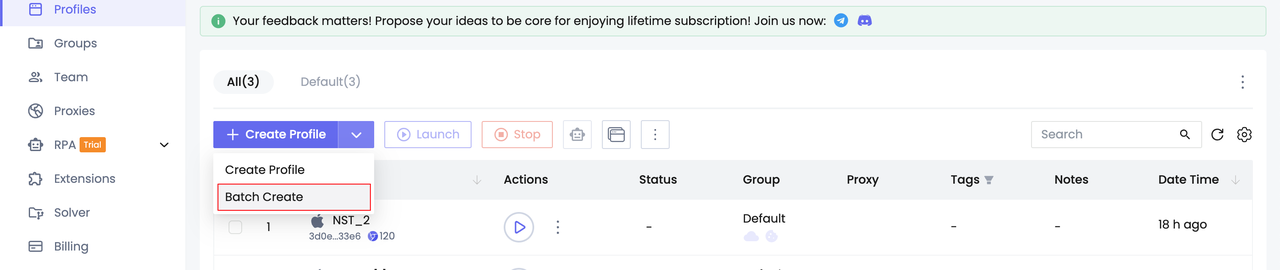
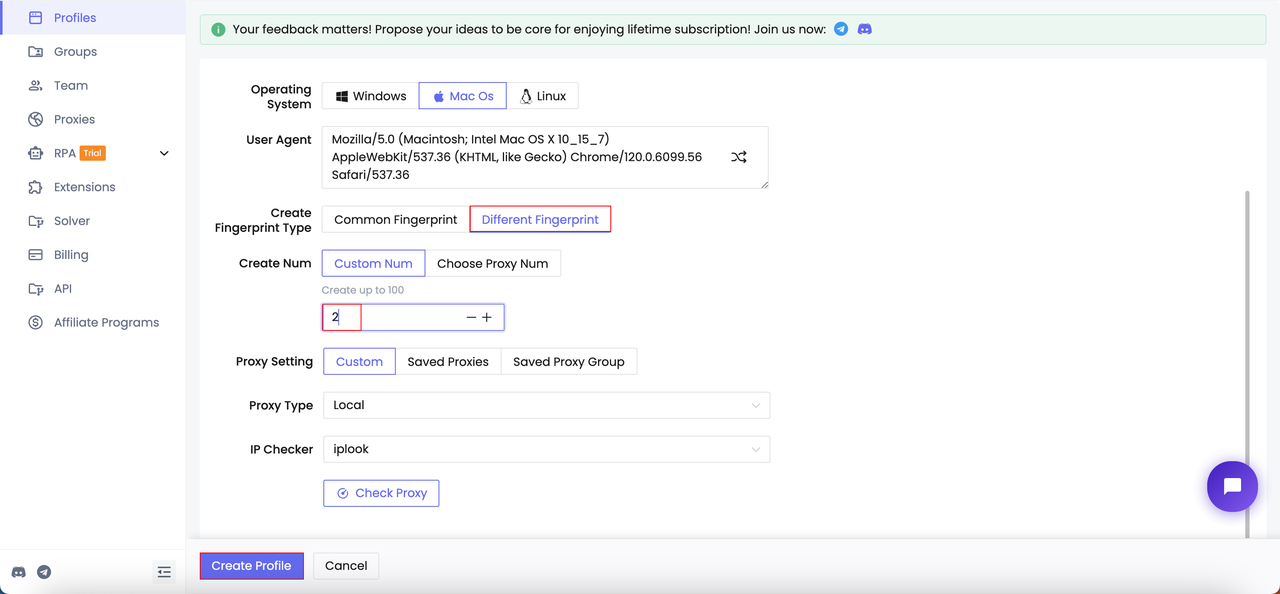
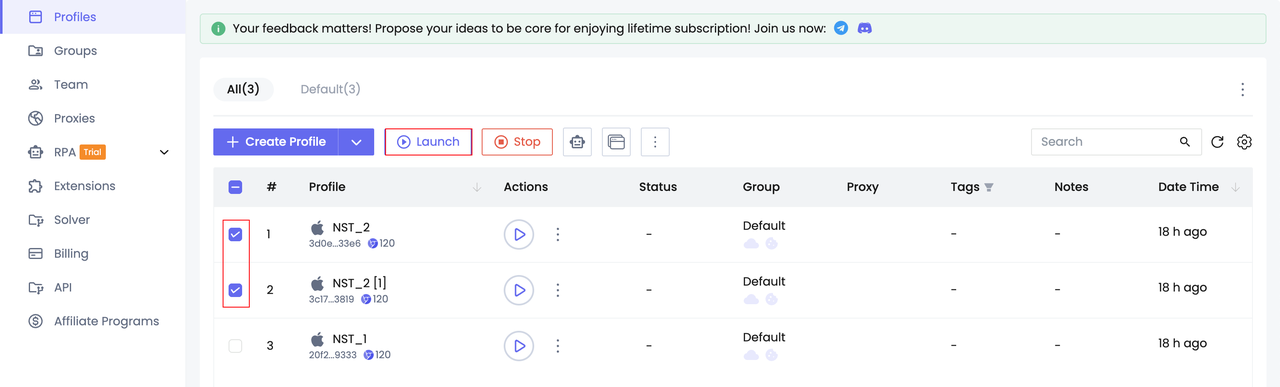
Bước 2. Khởi động hồ sơ
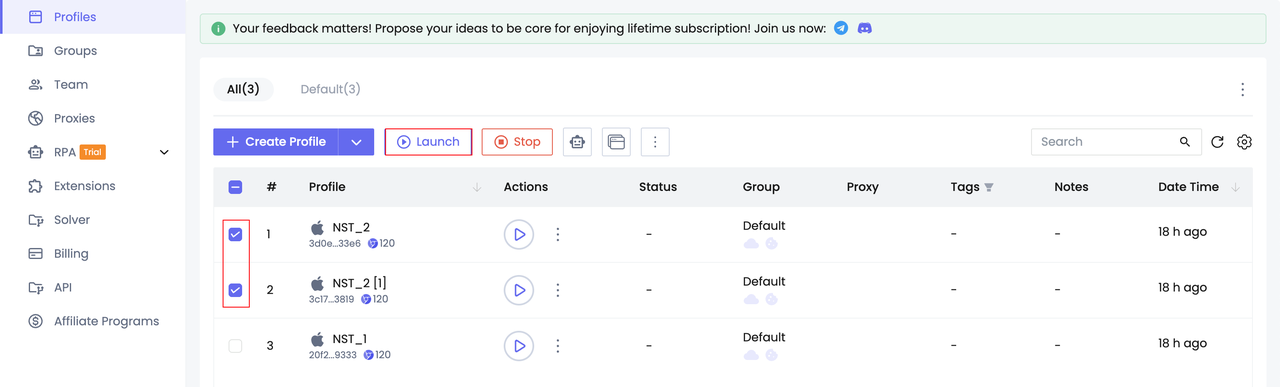
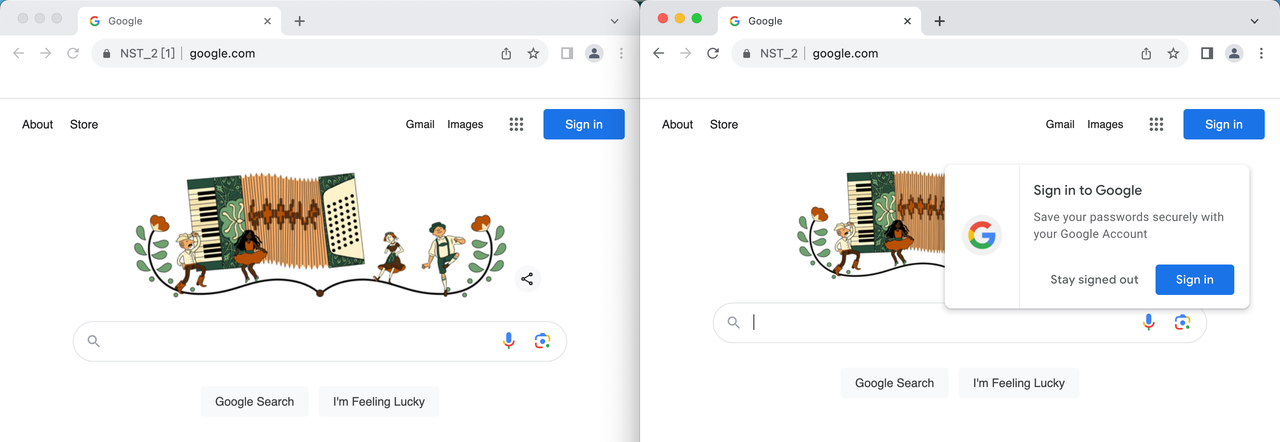
Bước 3. Truy cập trang web mục tiêu
Tùy chọn 2: Lấy proxy động
Bạn cũng có thể sử dụng Nstbrowser để thiết lập proxy trong các hồ sơ của bạn, đạt được các proxy động hàng loạt để tránh trình duyệt của bạn nhận được cảnh báo lỗi 403. Bạn chỉ cần làm theo các bước sau:
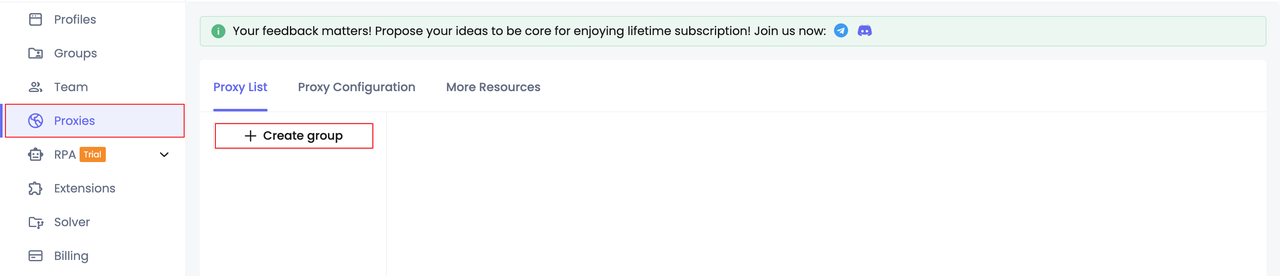
Bước 1. Thiết lập nhóm proxy
- Tạo nhóm proxy
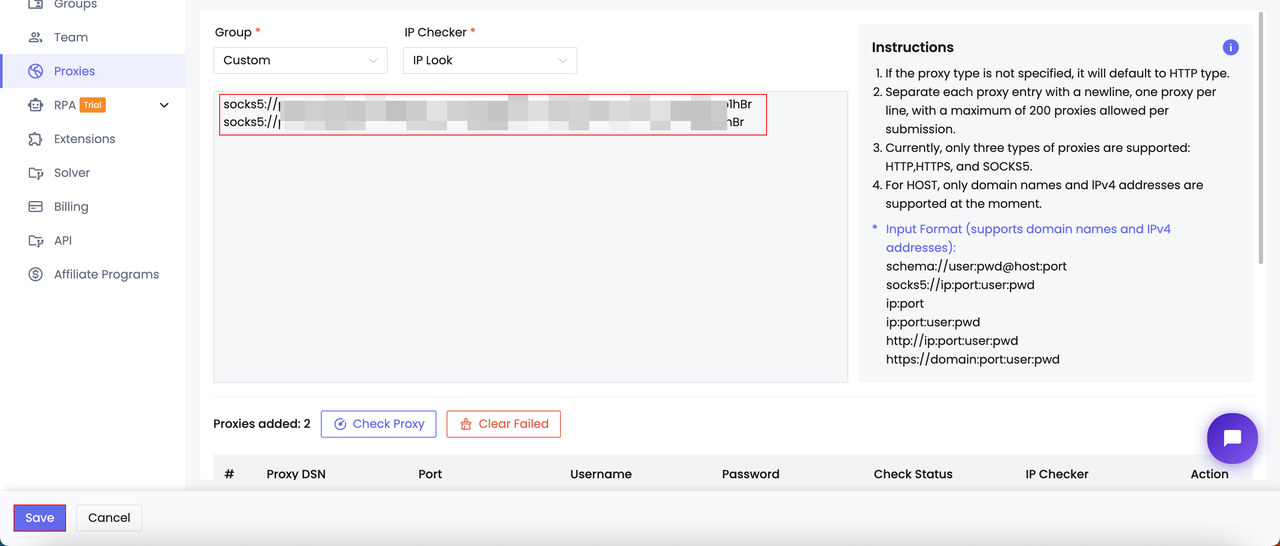
- Thêm proxy

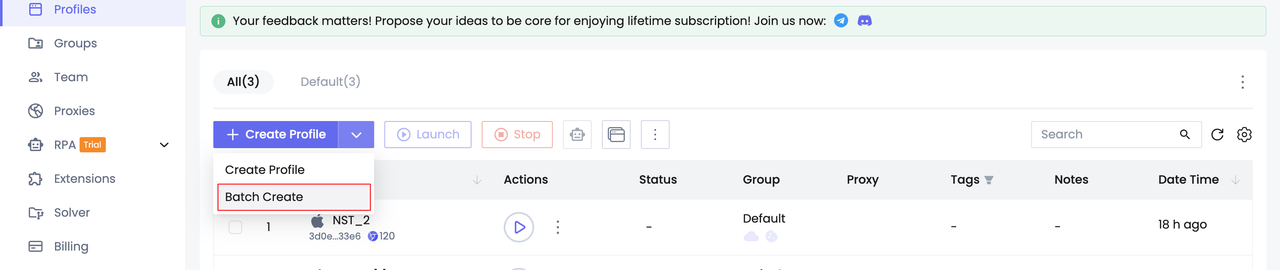
- Tạo hồ sơ
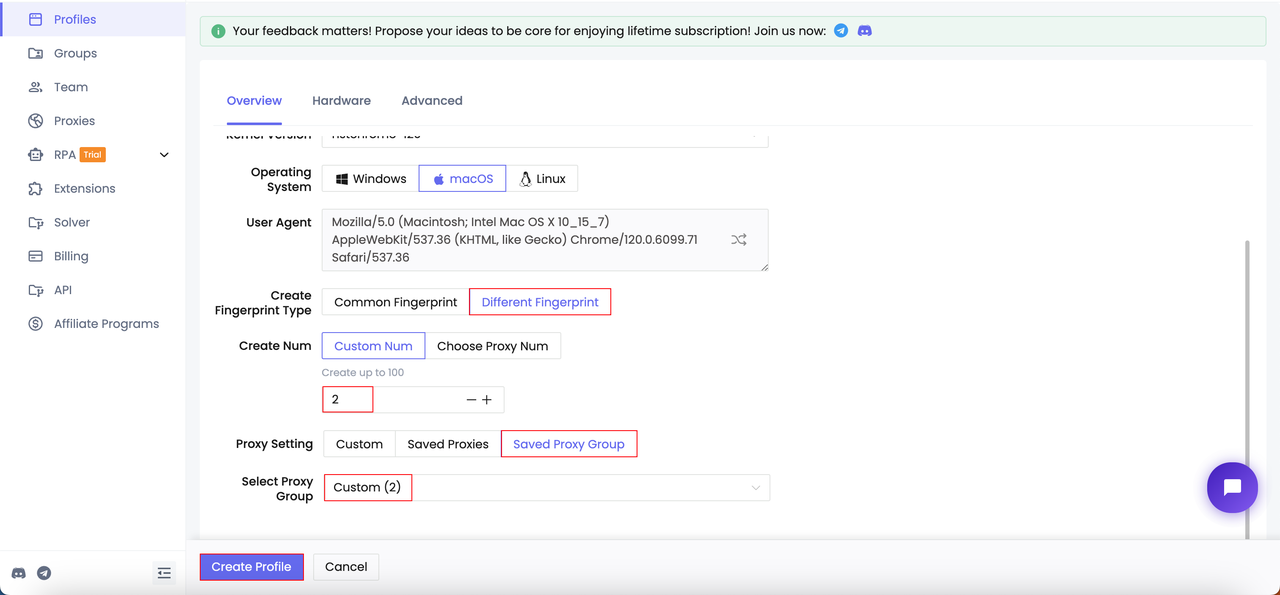
Bước 2. Khởi động hồ sơ
Bước 3. Truy cập trang web mục tiêu
Phương pháp 2. Thiết lập tiêu đề yêu cầu phù hợp
Một nguyên nhân khác là tiêu đề User-Agent không được thiết lập hoặc không hợp lệ. Điều này có thể khiến trang web mục tiêu trả về lỗi 403 để ngăn truy cập từ các bot tự động.
Trong trường hợp này, bạn cần thiết lập một tiêu đề User-Agent phù hợp để mô phỏng hành vi của người dùng thật.
- Dùng thư viện Requests trong Python
Python
import requests
url = 'http://example.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
print(response.status_code)
print(response.text)- Dùng Puppeteer
JavaScript
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36');
await page.goto('http://example.com');
const content = await page.content();
console.log(content);
await browser.close();
})();Phương pháp 3. Thiết lập đầy đủ các tiêu đề yêu cầu
Khi bạn thực hiện yêu cầu sử dụng Selenium và Python Requests, các tiêu đề mặc định có thể không chứa đủ thông tin thông thường của các yêu cầu từ người dùng.
Điều này có thể làm cho yêu cầu của bạn trông rất đáng ngờ. Do đó, rất có thể bạn sẽ gặp lỗi 403.
Do đó, khi sử dụng các công cụ tự động hóa, bước quan trọng nhất là thiết lập đầy đủ các tiêu đề yêu cầu để mô phỏng các yêu cầu từ người dùng thật.
- User-Agent: Xác định loại ứng dụng khách, hệ điều hành, nhà cung cấp phần mềm hoặc phiên bản phần mềm.
- Referer: Chỉ định URL từ đó yêu cầu được thực hiện.
- Accept: Chỉ định các loại nội dung mà ứng dụng khách có thể xử lý.
- Accept-Language: Ngôn ngữ tự nhiên ưu tiên của ứng dụng khách.
- Accept-Encoding: Các loại mã hóa nội dung mà ứng dụng khách có thể xử lý.
- Connection: Kiểm soát cách quản lý các kết nối (ví dụ: giữ kết nối sống).
- Cache-Control: Cơ chế lưu trữ được sử dụng cho các yêu cầu và phản hồi.
- Host: Tên miền và số cổng của máy chủ.
- Upgrade-Insecure-Requests: Chỉ định rằng ứng dụng khách muốn máy chủ nâng cấp lên HTTPS.
Phương pháp 4. Tránh bị chặn IP
Trong một khoảng thời gian nhất định, thực hiện nhiều yêu cầu từ cùng một địa chỉ IP rất có thể sẽ dẫn đến việc chặn IP.
Hầu hết các trang web sử dụng giới hạn tốc độ để kiểm soát lưu lượng và sử dụng tài nguyên. Do đó, vượt quá các giới hạn đặt ra bởi trang web sẽ dẫn đến việc bị chặn.
Trong trường hợp này, bạn có thể ngăn chặn việc bị chặn IP bằng cách thiết lập các khoảng thời gian hoặc trì hoãn giữa các yêu cầu liên tiếp và triển khai giới hạn tốc độ (giới hạn số lượng yêu cầu có thể được gửi trong một khoảng thời gian cụ thể).
Thay đổi địa chỉ IP tự động để tránh bị chặn IP và dễ dàng vượt qua lỗi 403.
Hãy bắt đầu sử dụng Nstbrowser miễn phí ngay bây giờ!
- JavaScript
Trong Node.js, bạn có thể sử dụng hàm setTimeout() để giới thiệu một khoảng trì hoãn:
JavaScript
const axios = require('axios');
const url = 'http://example.com';
const headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
};
// Định nghĩa phạm vi thời gian trì hoãn ngẫu nhiên
const minDelay = 1000; // Thời gian trì hoãn tối thiểu (mili giây)
const maxDelay = 5000; // Thời gian trì hoãn tối đa (mili giây)
// Thực hiện yêu cầu
axios.get(url, { headers })
.then(response => {
console.log(response.data);
})
.catch(error => {
console.error(error);
})
.finally(() => {
// Chờ một thời gian ngẫu nhiên trước khi thực hiện yêu cầu tiếp theo
const delay = Math.random() * (maxDelay - minDelay) + minDelay;
setTimeout(() => {
// Thực hiện yêu cầu tiếp theo hoặc các hành động khác
}, delay);
});- Python
Trong Python, sử dụng hàm time.sleep() để giới thiệu một khoảng trì hoãn ngẫu nhiên:
Python
import requests
import time
import random
url = 'http://example.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# Định nghĩa phạm vi thời gian trì hoãn ngẫu nhiên
min_delay = 1 # Thời gian trì hoãn tối thiểu (giây)
max_delay = 5 # Thời gian trì hoãn tối đa (giây)
# Thực hiện yêu cầu
response = requests.get(url, headers=headers)
# Xử lý phản hồi
print(response.status_code)
print(response.text)
# Chờ một thời gian ngẫu nhiên trước khi thực hiện yêu cầu tiếp theo
delay = random.uniform(min_delay, max_delay)
time.sleep(delay)Phương pháp 5. Sử dụng Nstbrowserless
Nstbrowserless là một trình duyệt không giao diện có thể dễ dàng vượt qua lỗi HTTP 403. Chìa khóa là thiết lập đúng các tiêu đề yêu cầu và mô phỏng hành vi con người để tránh bị máy chủ phát hiện là bot.
- Thiết lập các tiêu đề yêu cầu: Đảm bảo thiết lập các trường User-Agent, Referer, v.v., để mô phỏng truy cập của người dùng thật.
- Mô phỏng hành vi con người: Giới thiệu các khoảng thời gian ngẫu nhiên, di chuyển chuột, nhấp chuột, v.v., để mô phỏng chế độ hoạt động của con người khi thực hiện các tác vụ scraping web hoặc tự động hóa.
- Xử lý render JavaScript: Nstbrowserless có thể xử lý render JavaScript để đảm bảo nội dung trang được tải đầy đủ.
- Tránh yêu cầu quá thường xuyên: Thiết lập tần suất yêu cầu phù hợp để tránh gửi yêu cầu quá thường xuyên đến cùng một trang web.
Kết luận
Lỗi 403 có nghĩa là: tôi biết bạn là ai, nhưng bạn không có quyền truy cập vào đây.
Có 5 cách hiệu quả để giải quyết vấn đề này, nhưng cách hiệu quả nhất là sử dụng Nstbrowser.
Dễ dàng tránh bị phát hiện thông qua xoay IP mạnh mẽ và các tính năng mở khóa trang web, đảm bảo bạn không gặp lỗi 403.
Hơn





