
Web Scraping
Cách thực hiện Web Scraping trong Golang sử dụng Colly?
Golang là một trong những công cụ mạnh mẽ nhất để thu thập dữ liệu trên web. Và Colly giúp rất nhiều khi sử dụng Go. Đọc blog này và tìm thông tin chi tiết nhất về Colly và học cách thu thập dữ liệu từ trang web với Colly.
Sep 30, 2024Tạ Quí Lĩnh
Colly là gì?
Go là một ngôn ngữ đa năng với các gói và framework có thể làm gần như mọi thứ.
Hôm nay, chúng ta sẽ sử dụng một framework có tên Colly, một framework thu thập dữ liệu web hiệu quả và mạnh mẽ được viết bằng Go để thu thập dữ liệu trên web. Nó cung cấp một API đơn giản và dễ sử dụng cho phép các nhà phát triển nhanh chóng xây dựng các trình thu thập dữ liệu để truy cập các trang web và trích xuất thông tin cần thiết.
Colly là gì?
Colly cung cấp một bộ công cụ tiện lợi và mạnh mẽ để trích xuất dữ liệu từ các trang web, tự động hóa các tương tác mạng và xây dựng các công cụ thu thập dữ liệu web.
Trong bài viết này, bạn sẽ có được một số kinh nghiệm thực tế khi sử dụng Colly và tìm hiểu cách thu thập dữ liệu từ web bằng Golang: Colly.
Colly hoạt động như thế nào?
Phần cốt lõi của Colly là Collector. Nó chịu trách nhiệm thực hiện các yêu cầu HTTP và cho phép bạn xác định cách xử lý các yêu cầu và phản hồi. Bằng cách gọi c := colly.NewCollector(), bạn có thể tạo một thể hiện Collector mới, sau đó có thể được sử dụng để khởi tạo các yêu cầu mạng và xử lý dữ liệu.
Các chức năng cốt lõi:
1. Các phương thức Visit và Request:
Visit: Đây là phương thức yêu cầu được sử dụng phổ biến nhất, trực tiếp truy cập trang web đích.Request: Cho phép bạn đính kèm một số thông tin bổ sung (như tiêu đề tùy chỉnh hoặc tham số) khi gửi yêu cầu, được sử dụng cho các kịch bản yêu cầu phức tạp hơn.
2. Cơ chế gọi lại: Colly dựa vào các hàm gọi lại để thực thi ở các giai đoạn khác nhau của vòng đời yêu cầu. Collector cung cấp nhiều phương thức đăng ký gọi lại, chủ yếu bao gồm sáu phương thức sau:
OnRequest: Được kích hoạt trước khi gửi yêu cầu HTTP, bạn có thể thêm tiêu đề tùy chỉnh, in thông tin yêu cầu, v.v.OnError: Được kích hoạt khi lỗi xảy ra trong quá trình yêu cầu, được sử dụng để bắt và xử lý các lỗi yêu cầu.OnResponse: Được kích hoạt sau khi nhận được phản hồi của máy chủ, có thể được sử dụng để xử lý dữ liệu phản hồi.OnHTML: Được kích hoạt khi nội dung HTML được nhận và khớp với bộ chọn CSS được chỉ định, được sử dụng để trích xuất dữ liệu từ các trang HTML.OnXML: Được kích hoạt khi nội dung phản hồi là XML hoặc HTML và có thể được sử dụng để xử lý nội dung có định dạng XML.OnScraped: Được kích hoạt sau khi tất cả dữ liệu được yêu cầu được xử lý và là cuộc gọi lại ở cuối tác vụ thu thập dữ liệu.
3. Gọi lại OnHTML:
- Hàm gọi lại được sử dụng phổ biến nhất, được đăng ký bằng cách sử dụng Bộ chọn CSS, khi Colly tìm thấy một phần tử khớp trong DOM HTML, hàm gọi lại được đăng ký sẽ được gọi.
- Colly sử dụng thư viện
goqueryđể phân tích cú pháp HTML và khớp các bộ chọn CSS, và API củagoquerytương tự như jQuery, do đó các bộ chọn kiểu jQuery có thể được sử dụng để trích xuất dữ liệu từ trang.
Bạn có bất kỳ ý tưởng tuyệt vời và nghi ngờ nào về thu thập dữ liệu web và Browserless?
Hãy xem những gì các nhà phát triển khác đang chia sẻ trên Discord và Telegram!
Cách thu thập dữ liệu từ web bằng Golang?
Bước 1. Chuẩn bị môi trường
Cài đặt Golang
Truy cập Trang web chính thức của Golang và chọn phiên bản phù hợp để tải xuống và cài đặt. Chúng tôi khuyên bạn nên sử dụng go1.20+. Hướng dẫn này sử dụng go1.23.1.
Sau khi cài đặt hoàn tất, bạn có thể xác minh xem cài đặt đã thành công hay chưa bằng cách sử dụng terminal:
Shell
go versionKết quả đầu ra thành công của thông tin phiên bản go cho thấy cài đặt đã thành công.
Chọn IDE phù hợp
Chọn IDE phù hợp theo sở thích của bạn. Visual Studio được khuyến nghị.
Bước 2. Xây dựng dự án
Tiếp theo, bắt đầu tạo một dự án.
- Tạo một thư mục dự án:
Shell
mkdir gocolly-browserless && cd gocolly-browserless- Khởi tạo dự án Go:
Shell
go mod init colly-scraperLệnh trên thực thi go mod init để khởi tạo một dự án go có tên là colly-scraper và tạo một tệp go.mod trong thư mục dự án với nội dung sau:
Go
module colly-scraper
go 1.23.1- Sau đó, tạo
main.govà tạo phương thức chính:
Go
package main
import "fmt"
func main() {
fmt.Println("Hello Nstbrowser!")
}- Chạy phương thức chính:
Shell
go run main.goNếu bạn thấy thông tin in ra thành công, điều đó có nghĩa là hoạt động đã thành công. Dự án đã được xây dựng thành công.
Bước 3. Sử dụng Colly
Tuyệt vời! Tất cả các công đoạn chuẩn bị đã hoàn tất. Tiếp theo, chúng ta sẽ chính thức bắt đầu sử dụng Colly để hoàn thành một số thu thập dữ liệu đơn giản.
Cài đặt Colly
Nhập lệnh sau dưới đường dẫn gốc của dự án để hoàn thành việc cài đặt Colly:
Shell
go get github.com/gocolly/collyNếu quá trình cài đặt báo lỗi rằng phiên bản go hiện tại không được hỗ trợ, bạn có thể chọn cài đặt phiên bản Colly thấp hơn hoặc nâng cấp Golang lên phiên bản tương ứng. Sau khi cài đặt Colly, go.mod sẽ như sau:
Go
module colly-scraper
go 1.23.1
require (
github.com/gocolly/colly v1.2.0 // indirect
...
)Nguyên tắc cốt lõi
Nguyên tắc hoạt động cốt lõi của Colly là thu thập nội dung trang web thông qua các yêu cầu HTTP và sau đó phân tích cú pháp cấu trúc DOM trong trang web để trích xuất dữ liệu cụ thể mà chúng ta cần. Luồng công việc của nó có thể được chia thành các bước sau:
- Tạo Collector: Đây là đối tượng cốt lõi được Colly sử dụng để khởi tạo các yêu cầu HTTP và xử lý phản hồi.
- Xác định các hàm gọi lại: Colly xử lý các phần tử hoặc sự kiện cụ thể (như nhấp vào liên kết, phân tích cú pháp biểu mẫu, v.v.) khi phân tích cú pháp HTML bằng cách đăng ký các hàm gọi lại.
- Truy cập trang web đích: Bằng cách gọi phương thức Visit(), Collector sẽ khởi tạo một yêu cầu đến URL được chỉ định.
- Xử lý dữ liệu phản hồi: Xử lý dữ liệu HTML trong hàm gọi lại để trích xuất thông tin cần thiết.
Ví dụ bắt đầu
Dưới đây là một ví dụ đơn giản về việc truy cập Trang web chính thức của Nstbrowser
Go
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
// Tạo một trình thu thập dữ liệu mới
c := colly.NewCollector()
// Hàm gọi lại, được gọi khi trình thu thập dữ liệu tìm thấy một phần tử <title>
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Tiêu đề trang:", e.Text)
})
// Xử lý lỗi
c.OnError(func(_ *colly.Response, err error) {
fmt.Println("Lỗi:", err)
})
// Truy cập trang đích
c.Visit("https://nstbrowser.io")
}Sau khi thực thi mã trên, trình thu thập dữ liệu sẽ xuất ra nội dung của phần tử title của trang. Đây là luồng công việc cơ bản của Colly, cho phép nó dễ dàng phân tích cú pháp HTML và trích xuất thông tin bạn cần. Chạy go run main.go sẽ in ra thông tin tương tự như sau:
Plain Text
Tiêu đề trang: Nstbrowser - Trình duyệt chống phát hiện nâng cao cho thu thập dữ liệu web và quản lý nhiều tài khoảnCài đặt chung
Colly là một framework thu thập dữ liệu Golang mạnh mẽ và linh hoạt có thể kiểm soát hành vi của trình thu thập dữ liệu thông qua cấu hình. Dưới đây sẽ giới thiệu chi tiết các tùy chọn cấu hình thường được sử dụng trong Colly và giải thích các kịch bản sử dụng và phương thức triển khai của nó.
- Cấu hình trình thu thập dữ liệu
colly.NewCollector được sử dụng để tạo một thể hiện Collector mới, đây là phần cốt lõi của trình thu thập dữ liệu. Bằng cách truyền các tùy chọn cấu hình khác nhau, bạn có thể tùy chỉnh hành vi của trình thu thập dữ liệu, chẳng hạn như giới hạn tên miền được thu thập, độ sâu thu thập dữ liệu tối đa, thu thập dữ liệu không đồng bộ, v.v.
Ví dụ
Go
c := colly.NewCollector(
colly.AllowedDomains("example.com"), // Giới hạn trong một số miền nhất định
colly.MaxDepth(3), // Giới hạn độ sâu của thu thập dữ liệu
colly.Async(true), // Cho phép thu thập dữ liệu không đồng bộ
colly.IgnoreRobotsTxt(), // Bỏ qua các quy tắc robots.txt
colly.DisallowedURLFilters(regexp.MustCompile(".*.jpg")), // Bỏ qua một số URL
...
)- Cấu hình yêu cầu
Colly cung cấp nhiều phương thức để cấu hình hành vi yêu cầu HTTP, chẳng hạn như đặt tiêu đề yêu cầu tùy chỉnh, proxy, cookie, v.v. Thông qua các cài đặt này, trình thu thập dữ liệu có thể mô phỏng hành vi của người dùng thực và bỏ qua một số cơ chế chống thu thập dữ liệu.
Tiêu đề UA tùy chỉnh
Bạn có thể đặt thông tin tiêu đề HTTP tùy chỉnh cho mỗi yêu cầu thông qua phương thức Headers.Set. Ví dụ: đặt User-Agent để mô phỏng hành vi truy cập của trình duyệt để tránh bị chặn bởi các cơ chế chống thu thập dữ liệu.
Go
c.OnRequest(func(r *colly.Request) {
r.Headers.Set("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
...
})Quản lý Cookie
Colly tự động xử lý cookie theo mặc định, nhưng bạn cũng có thể đặt cookie cụ thể theo cách thủ công. Ví dụ: khi thu thập dữ liệu một số trang yêu cầu đăng nhập, bạn có thể đặt trước cookie sau khi đăng nhập.
Go
c.SetCookies("http://example.com", []*http.Cookie{
&http.Cookie{
Name: "session_id",
Value: "1234567890",
Domain: "example.com",
},
})Thiết lập proxy
Sử dụng máy chủ proxy có thể ẩn địa chỉ IP thực của bạn và bỏ qua các chính sách chặn IP của một số trang web. Colly hỗ trợ proxy đơn và chuyển đổi proxy động.
Go
c.SetProxy("url proxy của bạn")Đặt thời gian chờ yêu cầu
Khi trang web phản hồi chậm, việc đặt thời gian chờ yêu cầu có thể ngăn chương trình bị treo trong thời gian dài. Theo mặc định, thời gian chờ của Colly là 10 giây và bạn có thể điều chỉnh thời gian chờ theo nhu cầu.
Go
c.SetRequestTimeout(30 * time.Second)Gọi lại
Colly hỗ trợ xử lý gọi lại cho nhiều sự kiện, chẳng hạn như tải trang thành công, tìm thấy phần tử, lỗi yêu cầu, v.v. Thông qua các cuộc gọi lại này, bạn có thể linh hoạt xử lý nội dung thu thập dữ liệu hoặc giải quyết lỗi trong quá trình thu thập dữ liệu.
Các ví dụ về cuộc gọi lại phổ biến:
- OnRequest
Cuộc gọi lại này sẽ được gọi trước khi mỗi yêu cầu được gửi đi. Bạn có thể đặt tiêu đề yêu cầu động hoặc các tham số khác ở đây.
Go
c.OnRequest(func(r *colly.Request) {
fmt.Println("Đang truy cập:", r.URL.String())
})- OnResponse
Cuộc gọi lại này được gọi khi nhận được phản hồi để xử lý dữ liệu phản hồi HTTP ban đầu.
Go
c.OnResponse(func(r *colly.Response) {
fmt.Println("Đã nhận:", string(r.Body))
})- OnHTML
Được sử dụng để xử lý các phần tử cụ thể trong các trang HTML. Khi một phần tử HTML khớp xuất hiện trên trang, cuộc gọi lại này sẽ được gọi để trích xuất thông tin cần thiết.
Go
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Tiêu đề trang:", e.Text)
})- OnError
Cuộc gọi lại này được gọi khi lỗi xảy ra trong yêu cầu. Bạn có thể xử lý ngoại lệ ở đây.
Go
c.OnError(func(_ *colly.Response, err error) {
fmt.Println("Lỗi:", err)
})- Hạn chế yêu cầu
Colly cũng cung cấp một số tùy chọn để tối ưu hóa hiệu suất của trình thu thập dữ liệu, chẳng hạn như giới hạn số lượng yêu cầu đồng thời, tăng tốc độ thu thập dữ liệu và đặt độ trễ giữa các yêu cầu.
Go
c.Limit(&colly.LimitRule{
DomainGlob: "*", // DomainRegexp là mẫu glob để khớp với miền
Delay: 3 * time.Second, // Delay là thời gian chờ trước khi tạo yêu cầu mới cho các miền khớp
Parallelism: 2, // Parallelism là số lượng yêu cầu đồng thời tối đa được phép của các miền khớp
})Để biết thêm cài đặt, vui lòng tham khảo Tài liệu chính thức của Colly.
Ví dụ nâng cao
Kết hợp kiến thức mà chúng ta đã học trước đó, hãy thu thập dữ liệu thông tin phân loại trên trang chủ của Wikipedia và in ra kết quả:
- Phân tích yếu tố trang
Sau khi vào trang chủ, chúng ta nhấp chuột phải -> kiểm tra hoặc nhấn phím tắt F12 để vào phần phân tích yếu tố trang:
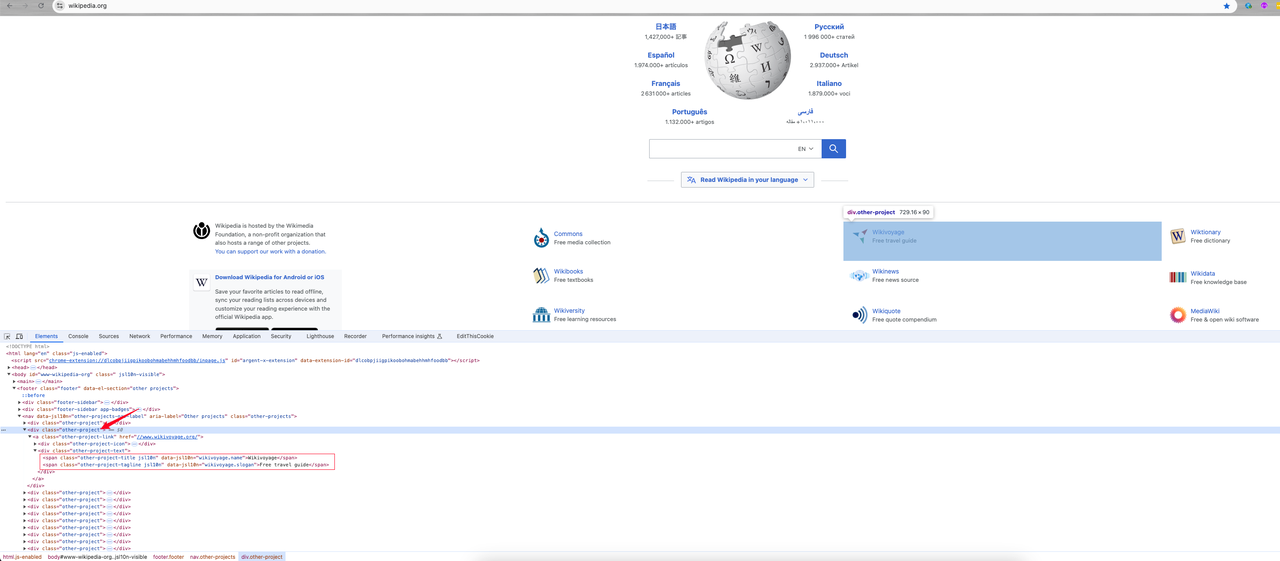
Chúng ta có thể thấy:
- Thông tin danh mục mà tôi cần là phần tử
divcó tên lớp làother-project, nơi liên kết danh mục là giá trị thuộc tínhhreftrong thẻ a. Tên lớp của nó làother-project-link. - Tiếp tục theo dõi phần tử này và nó cho thấy hai tên lớp
span(other-project-titlevàother-project-tagline) dưới phần tử lớp .other-project-text là tên danh mục và giới thiệu của nó.
Tiếp theo, bắt đầu mã hóa để lấy dữ liệu chúng ta muốn.
- Mã hóa
Go
package main
import (
"fmt"
"time"
"github.com/gocolly/colly"
)
func main() {
// Tạo một trình thu thập dữ liệu mới
c := colly.NewCollector()
// Xử lý lỗi
c.OnError(func(_ *colly.Response, err error) {
fmt.Println("Lỗi:", err)
})
// Tiêu đề yêu cầu tùy chỉnh: User-Agent
c.OnRequest(func(r *colly.Request) {
r.Headers.Set("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
})
// Đặt proxy
c.SetProxy("proxy của bạn")
// Đặt thời gian chờ yêu cầu
c.SetRequestTimeout(30 * time.Second)
c.Limit(&colly.LimitRule{
DomainGlob: "*", // DomainRegexp là mẫu glob để khớp với miền
Delay: 1 * time.Second, // Delay là thời gian chờ trước khi tạo yêu cầu mới cho các miền khớp
Parallelism: 2, // Parallelism là số lượng yêu cầu đồng thời tối đa được phép của các miền khớp
})
// Chờ các phần tử có lớp "other-project-text" xuất hiện
c.OnHTML("div.other-project", func(e *colly.HTMLElement) {
link := e.ChildAttrs(".other-project-link", "href")
title := e.ChildText(".other-project-link .other-project-text .other-project-title")
tagline := e.ChildText(".other-project-link .other-project-text .other-project-tagline") // dòng giới thiệu dự án
fmt.Println(fmt.Sprintf("%s => %s(%s)", title, tagline, link))
})
// Truy cập trang đích
c.Visit("https://wikipedia.org")
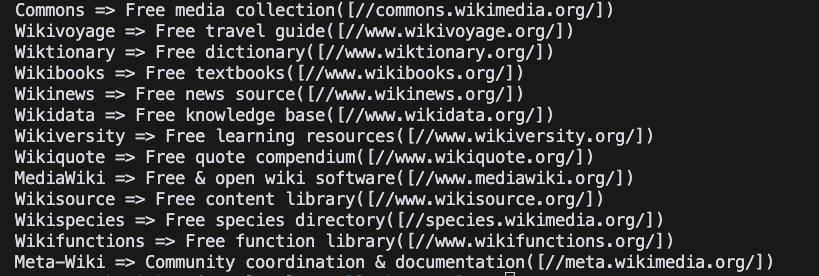
}- Chạy dự án
Shell
go run main.go- Kết quả
Kết luận
Dừng lại ở đây các bạn! Nstbrowser luôn giúp bạn đơn giản hóa mọi bước khó khăn trong thu thập dữ liệu web và tự động hóa tác vụ. Trong blog tuyệt vời này, chúng ta đã học được:
- Cách xây dựng môi trường cơ bản của Colly.
- Cấu hình và phương thức sử dụng Colly phổ biến.
- Sử dụng Colly để hoàn thành việc truy cập Trang web chính thức của Nstbrowser và thu thập dữ liệu phân loại Wiki trên trang chủ Wikipedia.
Thông qua các ví dụ đơn giản, chúng ta đã trải nghiệm sự đơn giản và khả năng thu thập dữ liệu mạnh mẽ của Colly. Để biết thêm cách sử dụng nâng cao, vui lòng tham khảo tài liệu chính thức của Colly.
Hơn





