
Web Scraping
Trình thu thập dữ liệu web Python - Hướng dẫn từng bước 2024
Python cung cấp khả năng phát triển trình thu thập dữ liệu web rất mạnh mẽ và hiện là một trong những ngôn ngữ trình thu thập thông tin phổ biến nhất. Đọc bài viết này để tìm hiểu cách sử dụng Python để quét web.
Jun 13, 2024Triệu Lệ Chi
Web crawler là một kỹ thuật mạnh mẽ cho phép chúng ta thu thập mọi loại dữ liệu và thông tin bằng cách truy cập các trang web và khám phá các URL trên các trang web. Python có các thư viện và frameworks khác nhau hỗ trợ web crawler. Trong bài viết này, chúng ta sẽ tìm hiểu về:
- Python crawler là gì
- Cách sử dụng Python crawler và Nstbrowser API để khám phá trang web
- Cách xử lý khi bị chặn khi crawl với python
- Ví dụ về python crawling
Python Web Crawler là gì?
Python cung cấp các khả năng phát triển web crawler rất mạnh mẽ và là một trong những ngôn ngữ crawling phổ biến nhất hiện nay. Một Python web crawler là một chương trình tự động để duyệt web hoặc Internet để lấy các trang web. Đó là một đoạn mã Python khám phá trang, khám phá liên kết và theo dõi chúng để tăng lượng dữ liệu có thể được trích xuất từ các trang web liên quan.
Các công cụ tìm kiếm phụ thuộc vào các con robot crawling để xây dựng và duy trì các chỉ mục trang của họ, trong khi các công cụ crawling web sử dụng chúng để truy cập và tìm tất cả các trang để áp dụng logic trích xuất dữ liệu.
Các web crawler trong Python chủ yếu được thực hiện thông qua việc sử dụng một số thư viện bên thứ ba. Các thư viện web crawler Python phổ biến bao gồm:
-
urllib/urllib2/requests: Các thư viện này cung cấp chức năng cơ bản cho việc crawling web, cho phép bạn gửi các yêu cầu HTTP và lấy các phản hồi.
-
BeautifulSoup: Đây là một thư viện để phân tích tài liệu HTML và XML, bạn có thể giúp cho crawler trích xuất thông tin hữu ích trên trang web.
-
Scrapy: Đây là một framework web crawler mạnh mẽ cung cấp trích xuất dữ liệu, xử lý đường ống, crawling phân tán và các tính năng nâng cao khác.
-
Selenium: Đó là một công cụ tự động hóa trình duyệt web, có thể mô phỏng các hoạt động thủ công của trình duyệt. Crawler này thường được sử dụng để crawl nội dung trang động được tạo bởi JavaScript.
Luôn bị chặn khi scraping?
Công cụ mở khóa web và giải pháp chống phát hiện của Nstbrowser
Thử miễn phí!
Bạn có suy nghĩ hoặc câu hỏi nào về việc thu thập dữ liệu web và Browseless không?
Hãy đến xem những gì các nhà phát triển khác đang chia sẻ trên Discord và Telegram!
4 Trường Hợp Sử Dụng Crawler Web Phổ Biến:
-
Các công cụ tìm kiếm (ví dụ: Googlebot, Bingbot, Yandex Bot...) thu thập toàn bộ HTML của các phần quan trọng của web, dữ liệu được lập chỉ mục để có thể tìm kiếm được.
-
Các công cụ phân tích SEO thu thập siêu dữ liệu bên cạnh HTML, như thời gian phản hồi và trạng thái phản hồi để phát hiện các trang và liên kết hỏng giữa các miền khác nhau để thu thập các liên kết đến.
-
Các công cụ theo dõi giá cả crawl các trang web thương mại điện tử để tìm trang sản phẩm và trích xuất siêu dữ liệu, đặc biệt là giá cả. Các trang sản phẩm sau đó được duyệt lại định kỳ.
-
Common Crawl duy trì một kho lưu trữ mở của dữ liệu crawling web. Ví dụ, bản lưu trữ tháng 5 năm 2022 chứa 3,45 tỷ trang web.
Vậy làm thế nào để sử dụng công cụ tự động hóa Python Pyppeteer để crawl web?
Tiếp tục cuộn xuống!
Làm thế nào để Cào Dữ liệu trên Web với Pyppeteer và API Nstbrowser?
Bước 1. Chuẩn bị
Trước khi bạn bắt đầu crawl, có một số chuẩn bị cần thực hiện:
Shell
pip install pyppeteer requests jsonSau khi cài đặt các thư viện cần thiết, tạo một file mới scraping.py và giới thiệu các thư viện chúng ta vừa cài đặt cũng như một số thư viện hệ thống vào file:
python
import asyncio
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from pyppeteer import launcherTrước khi sử dụng pyppeteer, chúng ta cần kết nối với Nstbrowser, cung cấp một API để trả về webSocketDebuggerUrl cho pyppeteer.
Python
# get_debugger_url: Lấy đường dẫn debugger
def get_debugger_url(url: str):
try:
resp = requests.get(url).json()
if resp['data'] is None:
raise Exception(resp['msg'])
webSocketDebuggerUrl = resp['data']['webSocketDebuggerUrl']
return webSocketDebuggerUrl
except HTTPError:
raise Exception(HTTPError.response)
async def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'khóa API của bạn'
config = {
'once': True,
'headless': False,
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # yêu cầu
'name': 'trình duyệt tùy chỉnh',
'platform': 'windows', # hỗ trợ: windows, mac, linux
'kernel': 'chromium', # chỉ hỗ trợ: chromium
'kernelMilestone': '120', # hỗ trợ: 113, 115, 118, 120
'hardwareConcurrency': 4, # hỗ trợ: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # hỗ trợ: 2, 4, 8
'proxy': '', # định dạng đầu vào: schema://user:password@host:port ví dụ: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # yêu cầu
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
browser_ws_endpoint = get_debugger_url(url)
print("browser_ws_endpoint: " + browser_ws_endpoint) # pyppeteer kết nối với Nstbrowser qua browser_ws_endpoint
(
asyncio
.get_event_loop()
.run_until_complete(create_and_connect_to_browser())
)Sau khi thành công lấy được webSocketDebuggerUrl từ Nstbrowser, kết nối pyppeteer với Nstbrowser:
Python
async def exec_pyppeteer(wsEndpoint: str):
browser = await launcher.connect(browserWSEndpoint = wsEndpoint)
page = await browser.newPage()Chạy đoạn mã chúng ta vừa viết trong terminal: python scraping.py, bạn sẽ thấy chúng ta đã mở thành công một Nstbrowser và tạo một tab mới trong Nstbrowser.
Mọi thứ đã sẵn sàng, và bây giờ, chúng ta có thể chính thức bắt đầu crawl!
Bước 2. Truy cập vào trang web mục tiêu
https://www.imdb.com/chart/top
Python
await page.goto('https://www.imdb.com/chart/top')Bước 3. Thực thi mã
Thực thi mã của chúng ta một lần nữa và bạn sẽ thấy rằng chúng ta đã truy cập vào trang web mục tiêu của mình thông qua Nstbrowser. Mở Devtool để xem thông tin cụ thể chúng ta muốn crawl và bạn sẽ thấy rằng chúng có cùng cấu trúc dom.
Bước 4. Crawl trang web
Chúng ta có thể sử dụng Pyppeteer để crawl những cấu trúc dom này và phân tích nội dung của chúng:
Python
movies = await page.JJ('li.cli-parent')
for row in movies:
title = await row.J('.ipc-title-link-wrapper')
year = await row.J('span.cli-title-metadata-item')
rate = await row.J('.ipc-rating-star')
title_text = await page.evaluate('item => item.textContent', title)
year_text = await page.evaluate('item => item.textContent', year)
rate_text = await page.evaluate('item => item.textContent', rate)
pringt('titile: ', title_text)
pringt('year: ', title_text)
pringt('rate: ', title_text)Tất nhiên, chỉ đơn giản là đầu ra dữ liệu ở terminal không phải là mục tiêu cuối cùng của chúng ta, những gì chúng ta muốn là lưu trữ dữ liệu.
Bước 5. Lưu trữ dữ liệu
Chúng ta sử dụng thư viện json để lưu trữ dữ liệu vào một tệp json cục bộ:
Python
movies = await page.JJ('li.cli-parent')
movies_info = []
for row in movies:
title = await row.J('.ipc-title-link-wrapper')
year = await row.J('span.cli-title-metadata-item')
rate = await row.J('.ipc-rating-star')
title_text = await page.evaluate('item => item.textContent', title)
year_text = await page.evaluate('item => item.textContent', year)
rate_text = await page.evaluate('item => item.textContent', rate)
move_item = {
"title": title_text,
"year": year_text,
"rate": rate_text
}
movies_info.append(move_item)
# tạo tệp json
json_file = open("movies.json", "w")
# chuyển đổi movies_info thành JSON
json.dump(movies_info, json_file)
# giải phóng tài nguyên tệp
json_file.close()Chạy mã của chúng ta và sau đó mở thư mục chứa mã. Bạn sẽ thấy một tệp mới có tên movies.json xuất hiện. Mở nó để kiểm tra nội dung. Nếu bạn thấy nó như này:
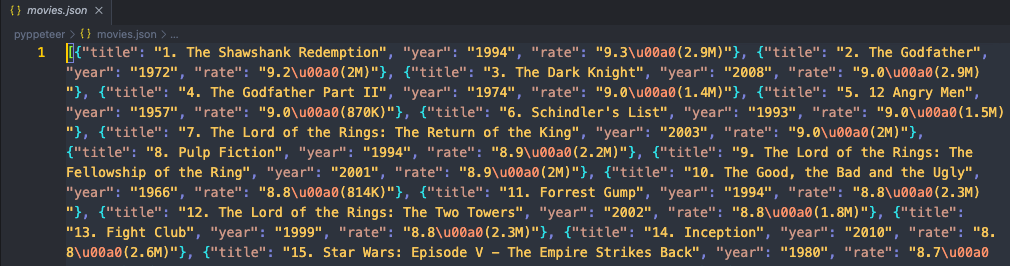
Điều đó có nghĩa là chúng ta đã crawl thành công trang web mục tiêu bằng Pyppeteer và Nstbrowser!
4 Mẹo để Sửa Lỗi Một Python Crawler Bị Chặn
Thách thức lớn nhất khi thực hiện Python web crawler là bị chặn. Nhiều trang web bảo vệ quyền truy cập của họ với các biện pháp chống bot nhận diện và ngăn chặn các ứng dụng tự động, ngăn chúng khỏi việc truy cập trang.
Tránh chặn Web và chặn IP với Nstbrowser.
Thử miễn phí ngay bây giờ!
Dưới đây là một số gợi ý để vượt qua chống crawling:
- **Thay
đổi User-Agent**: Thay đổi liên tục tiêu đề User-Agent trong các yêu cầu có thể giúp mô phỏng các trình duyệt web khác nhau và tránh phát hiện là một bot.
Thông tin UA có thể được thay đổi bằng cách sửa đổi config khi bắt đầu Nstbrowser:
Python
config = {
'once': True,
'headless': False,
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # yêu cầu
'name': 'trình duyệt tùy chỉnh2',
'platform': 'mac', # hỗ trợ: windows, mac, linux
'kernel': 'chromium', # chỉ hỗ trợ: chromium
'kernelMilestone': '120', # hỗ trợ: 113, 115, 118, 120
'hardwareConcurrency': 8, # hỗ trợ: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 2, # hỗ trợ: 2, 4, 8
}
}-
Chạy trong giờ thấp điểm: Bắt đầu crawler trong giờ thấp điểm và thêm độ trễ giữa các yêu cầu giúp ngăn chặn máy chủ web bị quá tải và kích hoạt cơ chế chặn.
-
Tôn trọng
robots.txt: Tuân theo chỉ thịrobots.txttrên một trang web thể hiện hành vi crawling đạo đức. Ngoài ra, điều này giúp tránh truy cập vào các khu vực bị hạn chế và làm cho các yêu cầu từ script trở nên đáng nghi. -
Tránh bẫy bot: Không phải tất cả các liên kết đều được tạo ra bằng cách nhau và một số trong số chúng ẩn bẫy bot. Bằng cách theo dõi chúng, bạn sẽ bị đánh dấu là một bot.
Tuy nhiên, những mẹo này rất hữu ích cho các kịch bản đơn giản, nhưng không đủ cho các kịch bản phức tạp hơn. Xem bài viết của chúng tôi về Cào dữ liệu Web đầy đủ hơn.
Việc vượt qua tất cả các phòng thủ không dễ dàng và đòi hỏi rất nhiều công sức. Hơn nữa, một giải pháp hoạt động hôm nay có thể không hoạt động vào ngày mai. Nhưng chờ đã, còn giải pháp tốt hơn nữa!
Nstbrowser giúp ngăn chặn các trang web nhận ra và chặn hoạt động crawling thông qua Mô phỏng Trình duyệt, Xoay UA, và nhiều tính năng khác. Đăng ký dùng thử miễn phí ngay hôm nay!
3 Công Cụ Cào Dữ Liệu Web Python Phổ Biến
Có một số công cụ cào dữ liệu web hữu ích có thể giúp quá trình khám phá liên kết và truy cập trang dễ dàng hơn. Dưới đây là danh sách những công cụ cào dữ liệu web Python tốt nhất có thể giúp bạn:
-
Nstbrowser: cung cấp vân tay trình duyệt thực. Kết hợp các kỹ thuật mở khóa trang web và tránh bot, và có thể xoay thông minh IP để giảm đáng kể khả năng bị phát hiện.
-
Scrapy: Một trong những lựa chọn thư viện Python cào m
ạnh mẽ nhất cho người mới bắt đầu. Nó cung cấp một framework tiên tiến cho việc xây dựng crawler có khả năng mở rộng và hiệu quả.
- Selenium: một thư viện trình duyệt headless phổ biến cho cào và crawl dữ liệu web. Không giống như BeautifulSoup, nó có thể tương tác với các trang web trong trình duyệt giống như một người dùng con người.
Kết Luận
Từ bài viết này, bạn phải hoàn toàn hiểu biết về cơ bản của cào dữ liệu web. Điều quan trọng là phải nhớ rằng dù crawler của bạn thông minh đến đâu, các biện pháp chống bot có thể phát hiện và chặn nó.
Tuy nhiên, bạn có thể vượt qua mọi thách thức bằng cách sử dụng Nstbrowser, một trình duyệt chống nhận diện đa năng với các tính năng tự động, Xác định Dấu Vân tay Trình duyệt, Giải quyết Captcha, Xoay UA, và nhiều tính năng bắt buộc khác để tránh bị chặn.
Cào dữ liệu chưa bao giờ dễ dàng hơn! Bắt đầu sử dụng Nstbrowser ngay bây giờ để trở thành một chuyên gia cào dữ liệu web!
Hơn





