
Web Scraping
Làm cách nào để vượt qua CAPTCHA và reCAPTCHA trong quá trình quét web?
Tại sao lại có CAPTCHA? Làm cách nào để vượt qua CAPTCHA? Mọi thứ hữu ích đã được chuẩn bị trong blog này!
Jul 03, 2024Triệu Lệ Chi
CAPTCHA là gì?
CAPTCHA, viết tắt của "Completely Automated Public Turing test to tell Computers and Humans Apart" (Kiểm tra Turing công cộng tự động hoàn toàn để phân biệt Máy tính và Con người), là một bài kiểm tra để xác định liệu khách truy cập trang web có phải là người thật hay không.
Đây là một sự gián đoạn phải được giải quyết trước khi tải trang yêu cầu và xuất hiện dưới nhiều hình thức khác nhau. Các trang web sử dụng chúng để xác định liệu bạn là người dùng thực hay là robot bằng cách kiểm tra độ chính xác của người dùng.
Đừng lo lắng! Họ không sử dụng sinh trắc học phức tạp và nhận diện khuôn mặt để xác thực.
Xác minh CAPTCHA thường xảy ra trong các tình huống sau:
- Sự tăng đột biến bất thường trong lưu lượng truy cập từ cùng một người dùng trong một khoảng thời gian ngắn.
- Tương tác đáng ngờ. Ví dụ, truy cập nhiều trang mà không cuộn.
- Kiểm tra ngẫu nhiên. Điều này xảy ra vì một số tường lửa bảo mật cao thực hiện kiểm tra để đảm bảo.
CAPTCHA hoạt động như thế nào?
CAPTCHA hoạt động bằng cách tạo ra các thử thách dễ nhận biết đối với con người nhưng khó phân tích đối với máy tính. Những thử thách này thường liên quan đến việc nhận diện văn bản bị biến dạng, chọn hình ảnh chứa các đối tượng cụ thể hoặc giải quyết các bài toán logic đơn giản.
Dưới đây là các bước và cơ chế chính mà CAPTCHA hoạt động:
1. Tạo thử thách:
- CAPTCHA văn bản. Tạo hình ảnh chứa văn bản bị biến dạng hoặc mờ, thường bao gồm các chữ cái và số sắp xếp ngẫu nhiên.
- Chọn hình ảnh. Cung cấp một tập hợp hình ảnh và yêu cầu người dùng chọn hình ảnh chứa một đối tượng cụ thể (ví dụ: đèn giao thông, ô tô, người đi bộ, v.v.).
- Bài toán logic. Đặt các câu hỏi toán học hoặc logic đơn giản và yêu cầu người dùng trả lời chúng.
- CAPTCHA âm thanh. Phát âm thanh chứa các chữ cái hoặc số ngẫu nhiên mà người dùng phải nghe và nhập.
2. Hiển thị thử thách:
Hệ thống CAPTCHA tạo và hiển thị thử thách khi người dùng truy cập một trang web yêu cầu xác thực. Người dùng phải nhập câu trả lời hoặc chọn hình ảnh vào ô chỉ định.
3. Xác minh phản hồi của người dùng:
Sau khi người dùng gửi câu trả lời, hệ thống sẽ so sánh đầu vào hoặc lựa chọn của người dùng với câu trả lời mong đợi. Xác minh thành công cho phép người dùng tiếp tục, trong khi xác minh thất bại yêu cầu người dùng thử lại.
4. Tạo thử thách mới:
Nếu người dùng không vượt qua được xác minh nhiều lần, hệ thống có thể tạo thử thách mới để đảm bảo rằng người dùng đang cố gắng vượt qua xác minh là con người.
Nstbrowser dễ dàng vượt qua xác thực CAPTCHA để Mở khóa trang web
Thử ngay miễn phí!
Bạn có suy nghĩ hoặc câu hỏi nào về việc thu thập dữ liệu web và Browseless không?
Hãy đến xem những gì các nhà phát triển khác đang chia sẻ trên Discord và Telegram!
6 loại CAPTCHA chính
CAPTCHA văn bản
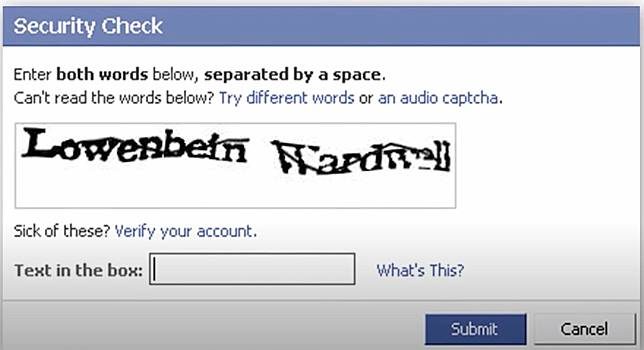
Tạo ngẫu nhiên một chuỗi ký tự và áp dụng các biến dạng, xoay, thay đổi màu sắc và các xử lý khác làm cho OCR (Nhận dạng ký tự quang học) khó phân tích chúng.
CAPTCHA 3D
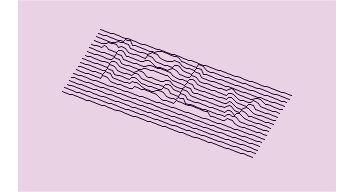
Công nghệ mới này là sự phát triển của thử thách văn bản, sử dụng các ký tự 3D, khó nhận biết hơn đối với máy tính.
reCAPTCHA
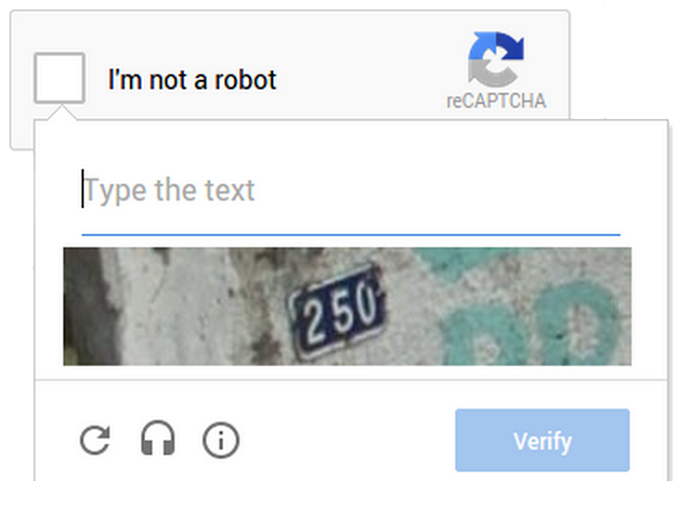
Google cung cấp hệ thống CAPTCHA tiên tiến với cả thành phần lựa chọn hình ảnh và nhận diện văn bản.
Sử dụng xác minh người dùng trong khi giúp cải thiện kỹ thuật nhận diện hình ảnh và số hóa văn bản.
Thử thách toán học
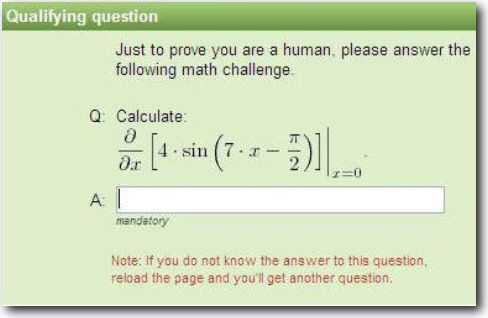
Người dùng cần giải các phương trình toán học hoặc câu hỏi tính toán để đạt được xác minh.
CAPTCHA chọn hình ảnh
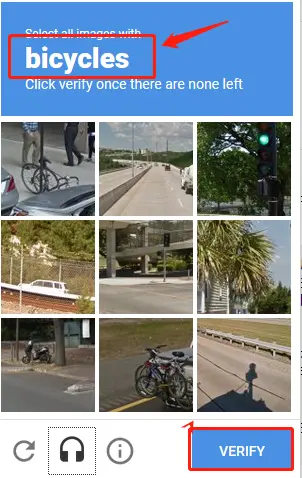
Khi đăng nhập, hệ thống hiển thị một tập hợp hình ảnh và yêu cầu người dùng chọn hình ảnh chứa một đối tượng cụ thể. Phương pháp này sử dụng các kỹ thuật học sâu để phân tích mức độ phù hợp giữa lựa chọn của người dùng và câu trả lời mong đợi.
CAPTCHA âm thanh
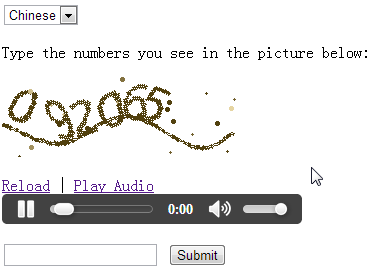
Loại xác minh này được thiết kế cho người dùng khiếm thị. Hệ thống phát một đoạn âm thanh chứa các chữ cái hoặc số mà người dùng cần nghe và nhập.
Làm thế nào để vượt qua CAPTCHA?
Phương pháp 1. Tránh bẫy Honeypot
Bẫy Honeypot là một chiến lược để ngăn chặn bot quét nội dung bằng cách sử dụng các liên kết hoặc biểu mẫu ẩn để phát hiện và gắn cờ các công cụ tự động. Do đó, nếu bạn nhấp vào chúng, bạn sẽ bị đánh dấu là bot.
- Bỏ qua các yếu tố ẩn
Đảm bảo rằng các tập lệnh bot bỏ qua các yếu tố có các thuộc tính CSS như display: none hoặc visibility: hidden. Các yếu tố này có thể được lọc bằng cách sử dụng bộ chọn sau:
Python
hidden_elements = driver.find_elements_by_css_selector("[style*='display:none'], [style*='visibility:hidden']")- Phát hiện các biểu mẫu ẩn
Bot cũng nên bỏ qua các biểu mẫu và hộp nhập liệu ẩn:
Python
hidden_forms = driver.find_elements_by_css_selector("input[type='hidden']")- Tránh nhấp vào các liên kết đáng ngờ
Trước khi nhấp vào các liên kết, hãy kiểm tra xem chúng có thuộc tính ẩn không:
Python
links = driver.find_elements_by_tag_name("a")
for link in links:
if "display:none" in link.get_attribute("style") hoặc "visibility:hidden" trong link.get_attribute("style"):
continue # Bỏ qua liên kết ẩn
link.click() # Nhấp vào liên kết hiện- Sử dụng
robots.txt
Tuân theo các quy tắc trong tệp robots.txt trên trang web của bạn để tránh quét các phần bị cấm.
- Mô phỏng tương tác giữa con người và máy tính
Mô phỏng hành vi thực của người dùng, chẳng hạn như nhấp chuột và cuộn ở các khoảng thời gian ngẫu nhiên, để tránh bị phát hiện là bot.
- Phân tích log
Thường xuyên phân tích log của bot để xem nó có bị chặn hoặc chuyển hướng hay không, để điều chỉnh chiến lược.
Phương pháp 2. Sử dụng tiêu đề thực
Nhận dạng đúng các tiêu đề yêu cầu là một cách phổ biến để phát hiện bot quét web, đặc biệt khi sử dụng các trình duyệt không đầu như Selenium và Puppeteer. Để tránh bị nhận dạng là bot, bạn có thể thay đổi tiêu đề User-Agent để mô phỏng trình duyệt của người dùng thực.
Phương pháp 3. Xoay IP hoặc tiêu đề
Một lượng lớn yêu cầu từ cùng một tiêu đề HTTP trong một khoảng thời gian ngắn phải đáng ngờ, phải không?
Một lượng lớn yêu cầu đến từ cùng một địa chỉ IP cũng đáng ngờ! Bởi vì người dùng thực không thể truy cập 1000 trang web trong năm phút.
Để thuyết phục trang web rằng bạn là người dùng thực, hãy xoay tiêu đề hoặc địa chỉ IP của bạn để bạn không dễ dàng bị nhận dạng bởi trang web.
Nstbrowser được thiết kế với tính năng xoay IP thông minh để tránh chặn web.
Thử ngay miễn phí!
Phương pháp 4. Sử dụng Nstbrowserless
[Nstbrowserless](https://www.n
stbrowser.io/en/product/browserless) cung cấp cách hiệu quả để chạy các tập lệnh tự động hóa trình duyệt không đầu trong khi tránh bị phát hiện là bot. Dịch vụ trình duyệt không đầu dựa trên đám mây này mô phỏng hành vi của người dùng thực để giúp vượt qua CAPTCHA và các cơ chế chống bot khác.
Nstbrowser dễ dàng giải quyết nhận dạng CAPTCHA với sự trợ giúp của Selenium và Puppeteer. Cho phép bạn truy cập và quét trang web một cách liền mạch.
Phương pháp 5. Vô hiệu hóa các chỉ số tự động hóa
Hầu hết các công cụ tự động hóa trình duyệt như Selenium và Puppeteer có một số cờ cụ thể như navigator.webdriver hiển thị thực tế rằng chúng là các công cụ tự động hóa.
Đây là lúc bạn cần sử dụng một plugin như Puppeteer-stealth để hiệu quả che giấu các dấu vết này.
Phương pháp 6. Mô phỏng hành vi người dùng thực
Cuối cùng, các trang web theo dõi điều hướng của người dùng, di chuyển chuột qua các yếu tố và thậm chí cả tọa độ nhấp chuột để phân tích hành vi của người dùng. Vì vậy, việc mô phỏng hành vi duyệt web của con người là rất quan trọng để tránh bị phát hiện.
Một số hành vi bạn có thể thử thiết lập là:
- Ngẫu nhiên hóa các hành động như cuộn trang.
- Nhấp chuột.
- Gõ phím.
- Sử dụng các khoảng thời gian ngẫu nhiên giữa các hành động.
Lưu ý quan trọng
CAPTCHA là gì, tại sao nó xảy ra và cách vượt qua nó? Bạn đã học được kiến thức toàn diện nhất về CAPTCHA trong bài viết này. Xoay tiêu đề và IP là cách hiệu quả và dễ dàng nhất để tránh CAPTCHA.
Để làm cho việc quét web dễ dàng hơn cho bạn, hãy sử dụng Nstbrowser để dễ dàng mở khóa các trang web, xoay IP một cách thông minh và vượt qua xác thực CAPTCHA.
Hơn





