
Web Scraping
Ошибка 403 Forbidden: Что это такое? Как ее исправить?
Ошибка 403 очень раздражает! Что такое ошибка 403 forbidden? Как ее решить? В этом блоге есть все.
Jul 12, 2024Robin Brown
Вы должны быть знакомы с ошибкой 403! Это приведет к потере трафика и даже к некоторым упущенным бизнес-возможностям!
Что? Вы столкнулись с ошибкой 403 на вашем сайте? Исправьте это немедленно! Однако что её вызывает? Как её решить? Оба этих вопроса важны, но вызывают путаницу.
Именно это может помочь наш блог!
Из этого блога вы узнаете:
- Почему возникает ошибка 403?
- Как исправить ошибку 403?
Начните прокручивать вниз сейчас!
Что такое ошибка 403?
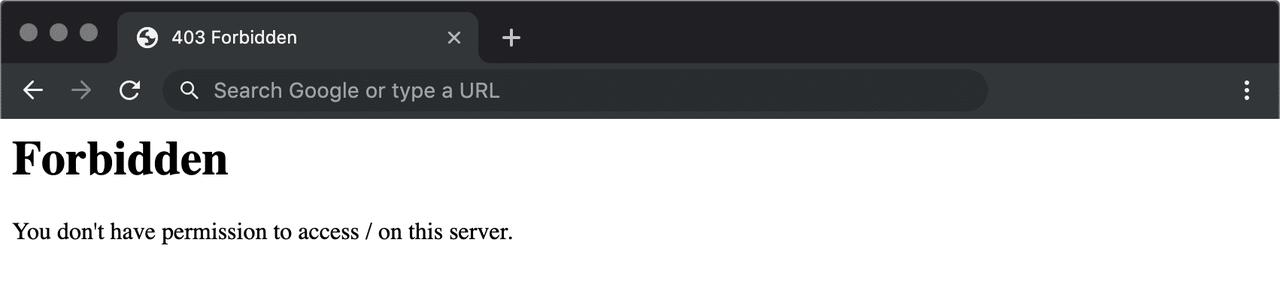
Ошибка 403 означает, что сервер может четко понять ваш запрос, но вы всё равно не можете получить доступ к целевому сайту. Это обычно происходит из-за недостаточных прав или учетных данных аутентификации на стороне сервера.
Другими словами, ваш сервер точно знает, что вы пытаетесь сделать, но это не работает.
Почему?
Потому что по какой-то причине у вас нет самого основного разрешения.
Это похоже на то, как если бы вы хотели попасть на частное мероприятие, но ваше имя случайно было удалено из списка гостей по какой-то причине.
Что вызывает ошибки 403?
5 распространенных причин ошибки HTTP 403:
- Ошибка прав доступа к файлам или папкам
- Ошибка в файле
.htaccess - Проблемы с IP-адресом
- Конфликты плагинов
- Отсутствие страницы индекса
1. Ошибка прав доступа к файлам или папкам
Когда вы пытаетесь получить доступ к файлу, папке или даже целому каталогу, вас могут отклонить, если сервер не распознает права доступа, указанные клиентом.
Чтобы избежать этой ошибки, проверьте и измените права доступа к файлам или папкам.
Bash
# для каталогов установите права доступа 755
chmod 755 /path/to/directory
# для файлов установите права доступа 644
chmod 644 /path/to/file2. Ошибка в файле .htaccess
Если файл .htaccess неправильно настроен или поврежден (заражен вредоносным ПО), то это может вызвать различные проблемы.
Как это решить? Проверьте и исправьте файл .htaccess или создайте новый конфигурационный файл.
Apache
# пример содержимого .htaccess
<Directory "/path/to/directory">
AllowOverride All
Require all granted
</Directory>3. Неправильный IP-адрес
Стоп! Неправильный или устаревший доменный IP-адрес также может вызвать ошибку 403? Да! Это так.
Поэтому проверьте настройки DNS доменного имени, чтобы убедиться, что оно указывает на правильный IP-адрес.
4. Проблема с плагином WordPress
Эти ошибки обычно возникают, когда пользователь пытается получить доступ к сайту, неправильно настроенному плагином WordPress. Это обычно связано с несовместимостью плагина WordPress с другими плагинами или неправильной настройкой.
О! Это может быть также из-за того, что сам хост не может получить доступ к папке wp-content в домашнем каталоге WordPress.
Пора отключить все плагины и включать их по одному, чтобы проверить, какой плагин вызывает проблему.
PHP
// добавьте следующий код в wp-config.php, чтобы отключить все плагины
define('WP_ALLOW_REPAIR', true);5. Отсутствие страницы индекса
По последней причине я обнаружил, что когда главная страница моего сайта не названа "index.php" или "index.html", я также сталкиваюсь с ошибкой 403.
Итак, вам нужно убедиться, что файл главной страницы сайта назван правильно.
Как легко обойти блокировку веб-сайта для беспрепятственного доступа?
Начните использовать Nstbrowser бесплатно сейчас!
Есть ли у вас хорошие идеи или вопросы о веб-скрейпинге и Browserless?
Посмотрите чем делятся другие разработчики в Discord и Telegram!
10 вариантов ошибки 403
- Ошибка 403 – Запрещено: Общая ошибка доступа.
- 403 – Запрещено: Доступ запрещен: доступ запрещен сервером, возможно, из-за проблемы с правами или ошибкой конфигурации.
- 403 Запрещено – nginx: Общая ошибка отказа в доступе.
- Запрещено – У вас нет разрешения на доступ к / на этом сервере: Неправильно установлены права доступа к корневому каталогу сервера или нет индексных файлов.
- 403 – Запрещено Ошибка – Вам не разрешено доступ к этому адресу: Доступ запрещен для конкретного адреса.
- HTTP Ошибка 403 – Запрещено – У вас нет разрешения на доступ к запрашиваемому документу или программе: Доступ к запрашиваемому документу или программе отключен.
- 403 Запрещено – Доступ к этому ресурсу на сервере запрещен: Доступ к ресурсу запрещен сервером.
- 403. Это ошибка. Ваш клиент не имеет разрешения на получение URL / с этого сервера: Клиент не имеет разрешения на доступ к указанному URL.
- Вы не авторизованы для просмотра этой страницы: У вас нет полномочий для просмотра страницы.
- Кажется, у вас нет разрешения на доступ к этой странице: У вас нет разрешения на доступ к целевой странице.
Как исправить ошибку 403?
Как избежать ошибки 403? Вот 5 методов!
Метод 1. Используйте Nstbrowser для обхода ошибки 403:
Самый эффективный способ обойти ошибки 403 при веб-скрапинге – использовать антидетект браузер! Он разработан с многочисленными мерами против ботов.
Nstbrowser предлагает самое полное решение, включая рендеринг JavaScript, интеллектуальную ротацию прокси и эффективное обнаружение ботов. Это позволяет вам избегать ошибок 403 и скрапить без блокировок.
Вариант 1: Создайте разные отпечатки браузера
Nstbrowser предоставляет реальные отпечатки браузера, и это решит ошибку 403 всего за 3 шага после регистрации:
Шаг 1. Создайте несколько профилей
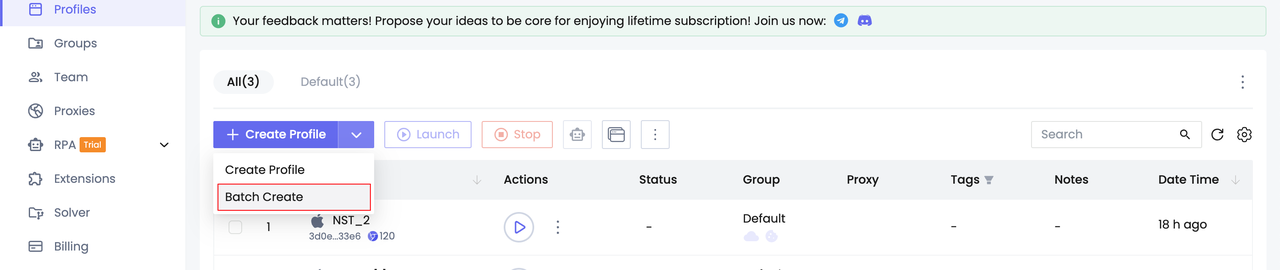
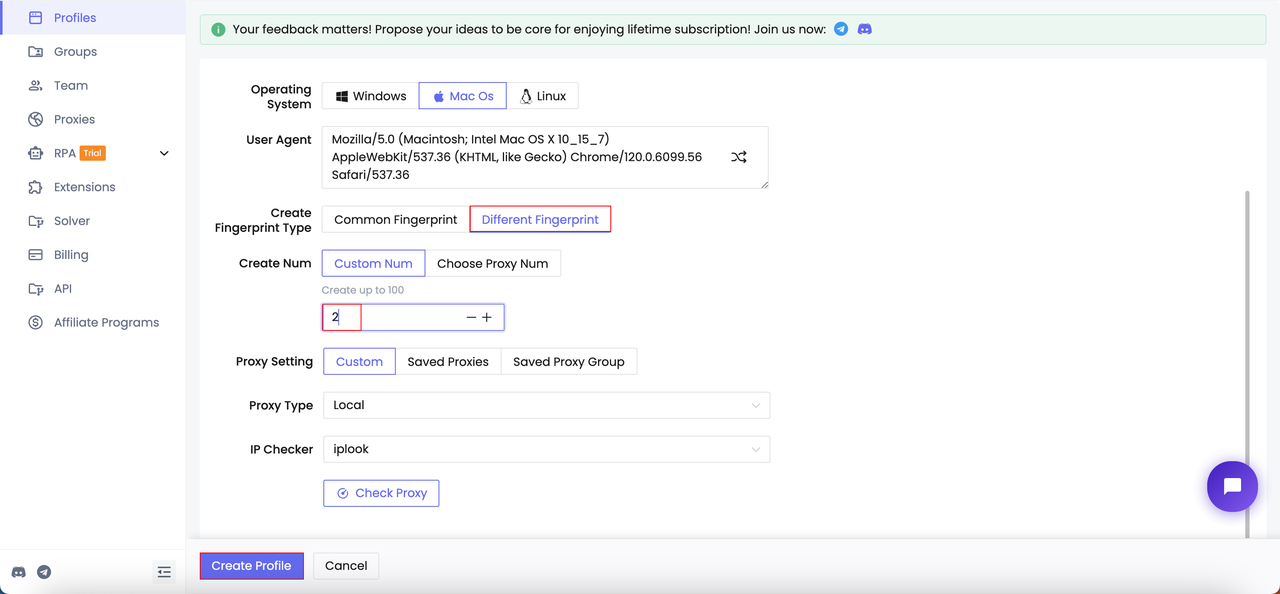
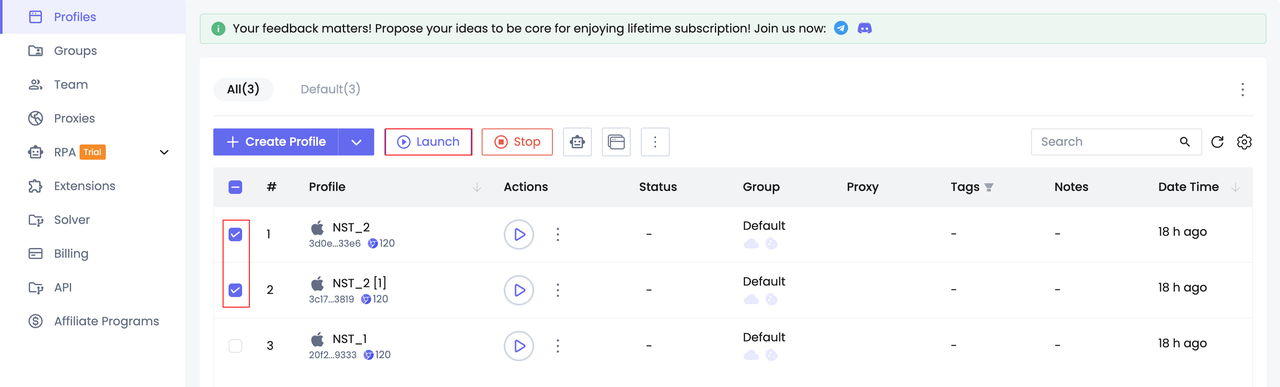
Шаг 2. Запустите профили
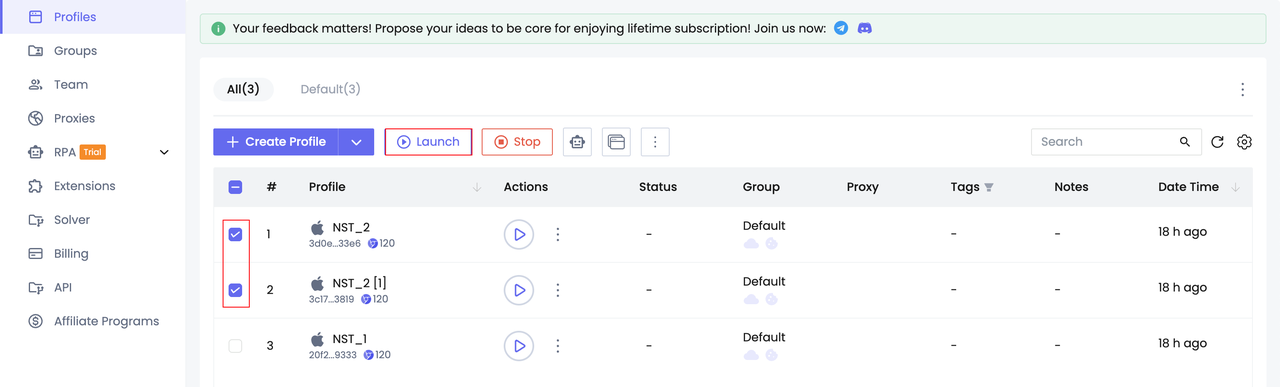
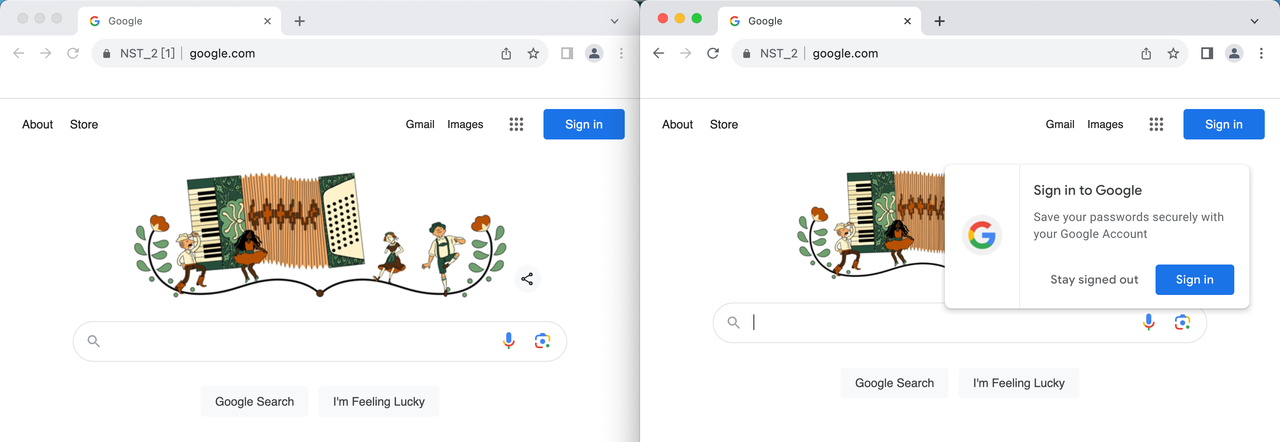
Шаг 3. Доступ к целевому сайту
Вариант 2: Получите динамические прокси
Вы также можете использовать Nstbrowser для настройки прокси для профиля, чтобы реализовать групповую динамическую прокси, чтобы ваш браузер не получал предупреждений об ошибке 403. Всё, что вам нужно сделать, это:
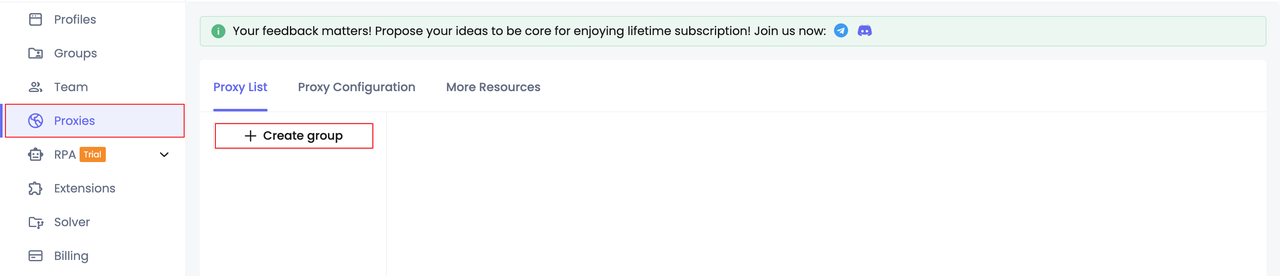
Шаг 1. Настройка группы прокси
- Создание группы
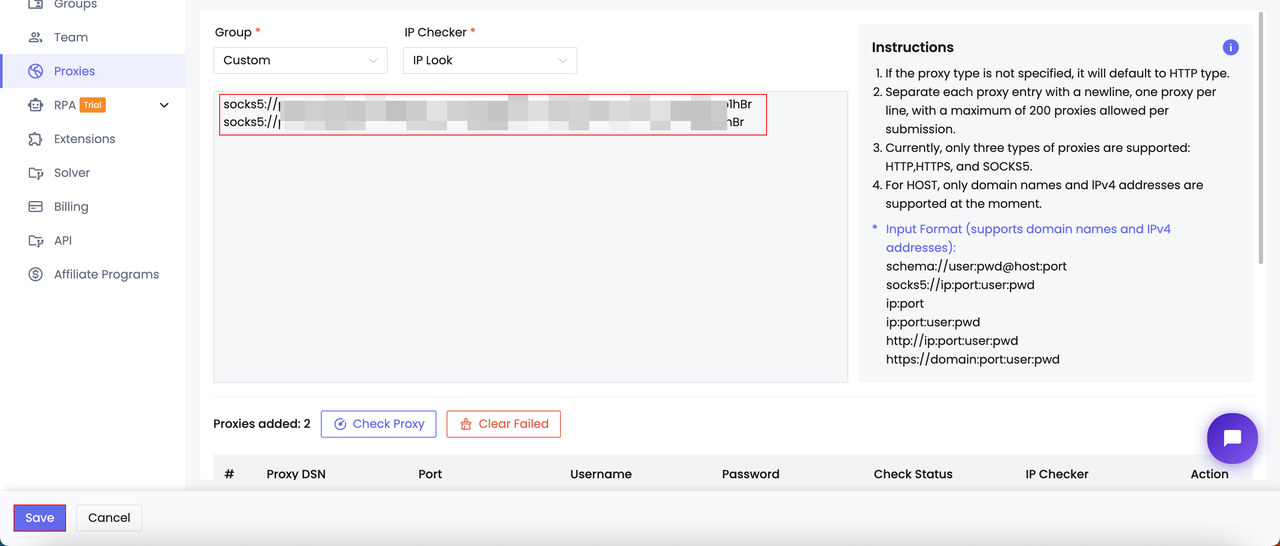
- Добавить прокси

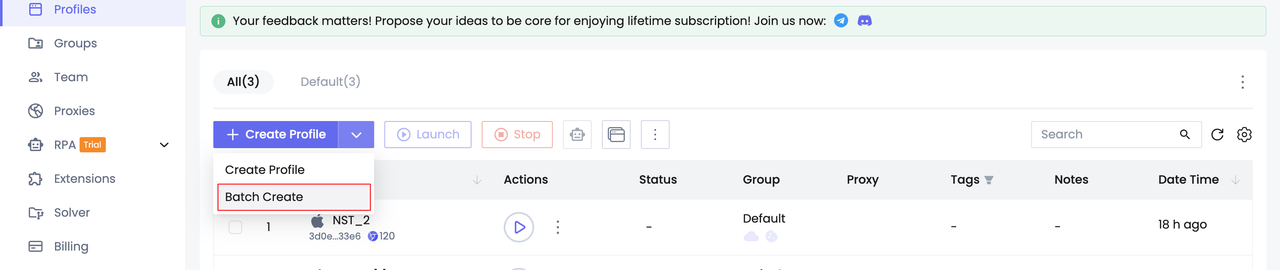
- Создание профилей
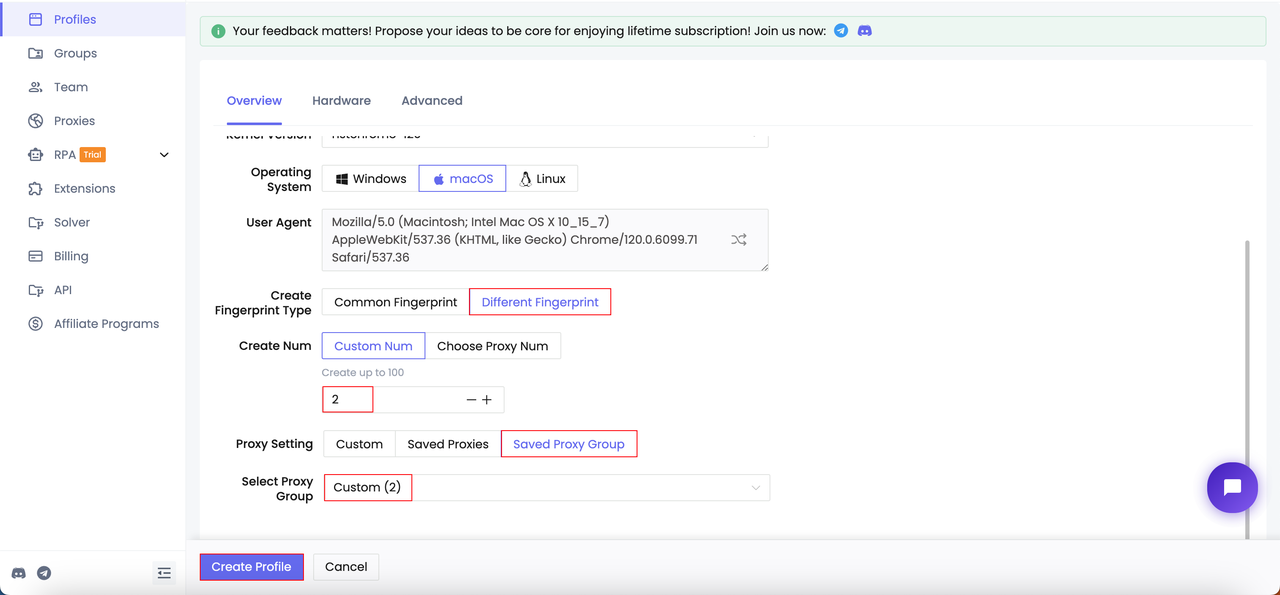
Шаг 2. Запустите профили
Шаг 3. Посетите целевой сайт
Метод 2. Настройка поддельного UserAgent
Поскольку сервер может решать, разрешить ли доступ на основе user agent, поддельный user agent может помочь обойти ошибку HTTP 403 в некоторых случаях.
- Использование библиотеки requests
Python
import requests
url = 'http://example.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, как Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
print(response.status_code)
print(response.text)- Использование Selenium
Python
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, как Gecko) Chrome/91.0.4472.124 Safari/537.36')
driver = webdriver.Chrome(options=options)
driver.get('http://example.com')
print(driver.page_source)- Использование Puppeteer
JavaScript
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, как Gecko) Chrome/91.0.4472.124 Safari/537.36');
await page.goto('http://example.com');
const content = await page.content();
console.log(content);
await browser.close();
})();Метод 3. Завершение заголовков
При выполнении запросов с использованием Selenium и Python Requests, например, по умолчанию заголовок не содержит всех обычных данных в запросе пользователя.
Это может сделать ваш запрос очень подозрительным. В результате, вы с высокой вероятностью столкнетесь с ошибкой 403.
Поэтому при использовании автоматизированного инструмента самым важным шагом является уточнение заголовков запросов, чтобы имитировать запрос реального пользователя.
- User-Agent: Идентифицирует тип клиентского приложения, операционную систему, поставщика программного обеспечения или версию программного обеспечения.
- Referer: Указывает URL, откуда был сделан запрос.
- Accept: Указывает тип контента, который клиент может обрабатывать.
- Accept-Language: Предпочтительный естественный язык клиента.
- Accept-Encoding: Кодировка контента, которую клиент может обрабатывать.
- Connection: Управляет тем, как управляется соединение (например, поддержка активного соединения).
- Cache-Control: Механизм кэширования для запросов и ответов.
- Host: Доменное имя и номер порта сервера.
- Upgrade-Insecure-Requests: Указывает, что клиент хочет, чтобы сервер перешел на HTTPS.
Метод 4. Избегание блокировки IP
Многочисленные запросы с одного и того же IP-адреса за определенный период времени, вероятно, приведут к блокировке IP-адреса.
Большинство сайтов обычно используют ограничение скорости запросов для контроля трафика и использования ресурсов. Поэтому превышение лимита, установленного сайтом, приведет к вашему бану.
В этом случае вы можете предотвратить блокировку IP, установив интервалы или задержки между последовательными запросами и реализовав ограничение запросов (ограничивая количество запросов, которые вы можете сделать в определенный промежуток времени).
Автоматически меняйте IP, чтобы эффективно избежать блокировки IP и легко обойти ошибки 403.
Используйте Nstbrowser бесплатно сейчас!
- Java
В Node.js задержки можно реализовать с помощью функции setTimeout():
JavaScript
const axios = require('axios');
const url = 'http://example.com';
const headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, как Gecko) Chrome/91.0.4472.124 Safari/537.36'
};
// определение диапазона случайного времени задержки
const minDelay = 1000; // минимальная задержка в мс
const maxDelay = 5000; // максимальная задержка в мс
// инициирование запроса
axios.get(url, { headers })
.then(response => {
console.log(response.data);
})
.catch(error => {
console.error(error);
})
.finally(() => {
// ожидание случайного периода времени перед инициированием следующего запроса
const delay = Math.random() * (maxDelay - minDelay) + minDelay;
setTimeout(() => {
// инициирование следующего запроса или другого действия
}, delay);
});- Python
Используйте функцию time.sleep() в Python, чтобы ввести случайные задержки:
Python
import requests
import time
import random
url = 'http://example.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, как Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# определение диапазона случайного времени задержки
min_delay = 1 # минимальная задержка в секундах
max_delay = 5 # максимальная задержка в секундах
# инициирование запроса
response = requests.get(url, headers=headers)
# обработка ответа
print(response.status_code)
print(response.text)
# ожидание случайного периода времени перед инициированием следующего запроса
delay = random.uniform(min_delay, max_delay)
time.sleep(delay)Метод 5. Использование Nstbrowserless
Nstbrowserless – это браузер без интерфейса. Он может легко обойти ошибку HTTP 403. Ключ в том, чтобы правильно настроить заголовки запросов и имитировать поведение человека, чтобы избежать обнаружения как бота сервером.
- Настройка заголовков запросов: Убедитесь, что вы установили соответствующие поля заголовков запросов, такие как User-Agent, Referer и т.д., чтобы имитировать визит реального пользователя.
- Имитировать поведение человека: Введите случайные интервалы, движения мыши, клики и т.д., чтобы имитировать шаблоны операций человека при выполнении веб-скрапинга или автоматизированных задач.
- Обработка рендеринга JavaScript: Nstbrowserless может обрабатывать рендеринг JavaScript, чтобы обеспечить загрузку полного содержимого страницы.
- Избегание частых запросов: Установите соответствующую частоту запросов, чтобы избежать слишком частых запросов к одному и тому же сайту.
Заключение
Ошибка 403 означает: я знаю, кто вы, но вам не разрешено быть здесь.
Существует 5 эффективных способов обойти эту проблему, но наиболее стоящий способ – это Nstbrowser.
Легко обходите обнаружение с помощью мощной ротации IP и разблокировки веб-сайтов, чтобы гарантировать, что вы не столкнетесь с ошибкой 403.
Больше





