
Web Scraping
Urllib vs Urllib3 vs Requests: какой из них лучше всего подходит для парсинга веб-страниц?
Urllib, urllib3 и Requests — три замечательные и распространенные библиотеки Python. В чем разница между этими тремя? Прочтите эту статью и найдите тот, который подойдет именно вам!
Jul 17, 2024Luke Ulyanov
Вы всегда используете Python для веб-скрапинга? Тогда, вероятно, вы также сталкивались с вопросом о том, какой HTTP-клиент лучше использовать: Urllib, Urllib3 или Requests, как и я.
Да, в программировании на Python обработка HTTP-запросов - это обычное требование.
Python предоставляет несколько библиотек для выполнения этой функции, и Urllib, Urllib3 и Requests - это три наиболее распространенные библиотеки.
Чем они отличаются друг от друга? Какая из них подходит вам?
Каждая из них имеет свои особенности, преимущества и недостатки. Давайте разберемся!
Общие сравнения
| Библиотека | Urllib | Urllib3 | Requests |
|---|---|---|---|
| Требуется установка | Нет | Да | Да |
| Скорость | Умеренная | Быстрая | Умеренная |
| Обработка ответа | Обычно требуется декодирование ответа | Дополнительных декодирование не требуется | Дополнительных декодирование не требуется |
| Пул соединений | Не поддерживается | Поддерживается | Поддерживается |
| Простота использования | Больше синтаксических конструкций, что усложняет кривую обучения | Прост в использовании | Прост в использовании и более дружелюбен для начинающих |
1. Urllib
Urllib является частью стандартной библиотеки Python для обработки URL-адресов, и для его использования не требуется установка дополнительных библиотек.
При отправке запроса с использованием Urllib возвращается массив байт объекта ответа. Однако следует отметить, что этот возвращаемый массив байт требует дополнительного этапа декодирования, что может быть сложным для начинающих.
Чем особенен Urllib?
Urllib позволяет более тонко управлять процессом с использованием низкоуровневого интерфейса, но это также означает, что требуется написание большего количества кода. Пользователи часто должны вручную управлять кодированием URL, настройками заголовков запросов и декодированием ответов.
Однако не стоит волноваться! Urllib предоставляет основные функции HTTP-запросов, такие как GET и POST, поддерживает разбор, кодирование и декодирование URL-адресов.
Преимущества и недостатки
Преимущества:
- Не требуется дополнительная установка. Поскольку это часть стандартной библиотеки Python, для его использования не требуется установка дополнительных библиотек.
- Обширные функции. Поддерживает обработку URL-запросов, ответов и разбора.
Недостатки:
- Высокая сложность. Шаги отправки запросов и обработки ответов являются громоздкими.
- Необходимость вручную обрабатывать массивы байт. Возвращаемый ответ требует ручного декодирования, что добавляет дополнительный этап.
Для чего подходит Urllib?
Urllib подходит для простых задач HTTP-запросов, особенно если не требуется установка сторонних библиотек.
Это также помогает изучать и понимать основные принципы. Пользователи могут использовать его для изучения и понимания внутренней реализации HTTP-запросов.
Однако, поскольку Urllib не обладает продвинутыми функциями, такими как управление пулом соединений, стандартное сжатие и обработка JSON, его использование относительно громоздко, особенно для сложных HTTP-запросов.
2. Urllib3
Urllib3 предоставляет высокоуровневые абстракции, включая API запросов, пул соединений, стандартное сжатие, кодирование и декодирование JSON и многое другое.
Применение этих функций очень просто! Вы можете настроить HTTP-запросы всего несколькими строками кода. Urllib3 использует расширения на языке C для улучшения производительности. Поэтому он является самым быстрым среди трех.
Чем особенен Urllib3?
Urllib3 предоставляет более продвинутый интерфейс. Он также поддерживает продвинутые функции, такие как пул соединений, автоматическая повторная попытка, настройка SSL и загрузка файлов:
- Пул соединений: Управление пулами соединений для снижения повторных накладных расходов на TCP-соединение.
- Механизм повторной попытки: Автоматически повторяет запросы для улучшения стабильности.
- Стандартное сжатие: Поддерживает сжатие и разжатие данных запросов и ответов.
- Поддержка JSON: Хотя это не встроенная функция, ее можно использовать с модулем JSON для обработки данных JSON.
- Подтверждение SSL: Предоставляет лучшую поддержку SSL и опции конфигурации.
Преимущества и недостатки
Преимущества:
- Более продвинутые функции. Предоставляет более продвинутые возможности, чем Urllib, такие как управление пулом соединений, загрузка фрагментов файлов, повтор запросов и т. д.
- Прост в использовании. Синтаксис проще, чем у Urllib, что уменьшает сложность кодирования.
Недостатки:
- Требуется установка. Для использования
Urllib3необходимо установить с помощьюpip(pip install urllib3).
Для чего подходит Urllib3?
Пользователи могут использовать urllib3 для сложных HTTP-запросов, таких как обработка параллельных запросов, управление пулом соединений и т. д.
Urllib3 также подходит для задач, где требуется высокая производительность и стабильность.
3. Requests
Requests - это популярная библиотека для отправки HTTP-запросов. Она известна своим простым дизайном API и мощными функциями, что делает взаимодействие с сетью очень простым.
HTTP-запросы, отправленные через Requests, становятся очень простыми и интуитив
но понятными. Кроме того, она имеет встроенные функции, такие как обработка куки, сессий, настройка прокси и обработка JSON-данных, что обеспечивает удобный пользовательский опыт.
У Requests также есть некоторые мощные функции:
- Простой API: Предоставляет самый простой и легкий в использовании интерфейс. Поэтому HTTP-запросы становятся очень интуитивно понятными.
- Пул соединений: Встроенное управление пулом соединений.
- Стандартное сжатие: Автоматическая обработка сжатия запросов и ответов.
- Поддержка JSON: Очень удобно обрабатывать JSON-данные с помощью встроенных функций кодирования и декодирования JSON.
Преимущества и недостатки
Преимущества:
- Самый консистентный и дружественный синтаксис.
Requestsпредоставляет самый простой и понятный API, поэтому отправка HTTP-запросов становится очень простой. - Использует
urllib3в основе. Используетurllib3в качестве основы, комбинируя высокую производительность и продвинутые функции, скрывая при этом сложность.
Недостатки:
- Требуется установка.
Requestsнужно установить с помощьюpip(pip install requests). - Несмотря на богатые функции, производительность относительно медленная из-за высокоуровневой абстракции.
Для чего подходит Requests?
Requests подходит для практически всех сценариев HTTP-запросов, особенно для веб-скрапинга и API-запросов. Благодаря простому синтаксису и обширной документации она также особенно подходит для начинающих.
Сравнение производительности
Согласно результатам бенчмарка, производительность этих трех библиотек за 100 итераций следующая:
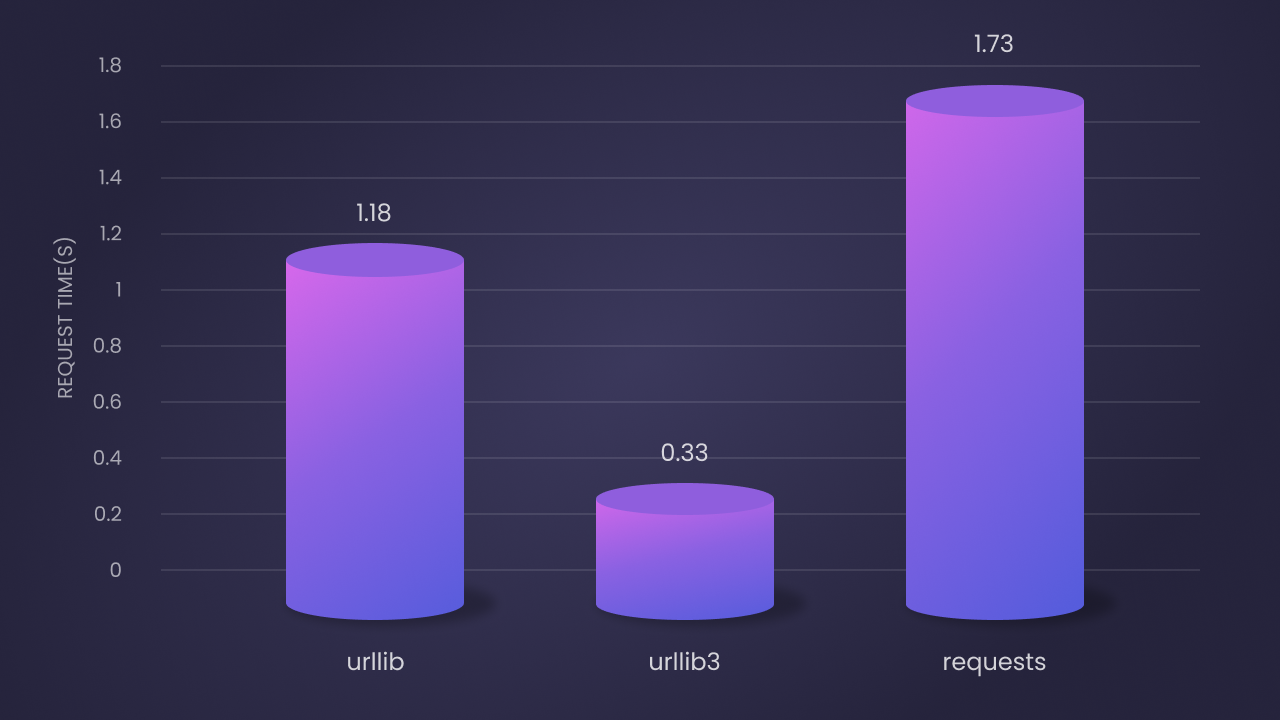
Urllib- второй по скорости: среднее время запроса 1.18 секунды. Несмотря на то, что это чистая реализация на Python, благодаря внутренней реализации его производительность лучше.Urllib3- самый быстрый: среднее время запроса 0.33 секунды. Это связано с его расширением на языке C и эффективным управлением пулом соединений.Requests- самый медленный: среднее время запроса 1.73 секунды. Но ее легкость в использовании и богатые функции компенсируют это.
Рекомендации по выбору
- Если вы хотите обойтись без сторонних библиотек и требования к проекту просты, вы можете выбрать
Urllib. Это часть стандартной библиотеки и не требует отдельной установки. - Если вам нужны высокая производительность и продвинутые функции и вы не против выполнения технических операций, то
Urllib3- отличный выбор. - Если вы стремитесь к минимальному количеству кода и простому в использовании интерфейсу, особенно при работе с сложными HTTP-запросами, то
Requestsидеален. Это самая простая для использования библиотека, широко используемая для веб-скрапинга и API-запросов.
2 Эффективных Метода Избежать Блокировки При Скрапинге
Многие веб-сайты интегрировали системы антиботов для обнаружения и блокировки автоматизированных скриптов, таких как веб-скраперы. Поэтому важно обходить эти блокировки для доступа к данным!
Один из способов избежать обнаружения - использовать Nstbrowser для избегания блокировки IP. Urllib и urllib3 также имеют встроенные возможности для добавления прокси к HTTP-запросам.
Nstbrowser разработан с функцией смены IP и разблокировки веб-страниц.
Попробуйте бесплатный Nstbrowser для избежания блокировки IP!
Есть ли у вас хорошие идеи или вопросы о веб-скрейпинге и Browserless?
Посмотрите чем делятся другие разработчики в Discord и Telegram!
Метод 1: Использование Nstbrowser для обхода системы антиботов
Перед началом работы вам нужно выполнить несколько условий:
- Стать пользователем Nstbrowser.
- Получить API-ключ от Nstbrowser.
- Запустить сервис Nstbrowserless локально.
Ниже приведены конкретные шаги. В качестве примера возьмем скрапинг заголовка контента страницы на веб-сайте Amazon.
Если нам нужно скрепить содержимое заголовка h3 на следующей веб-странице:
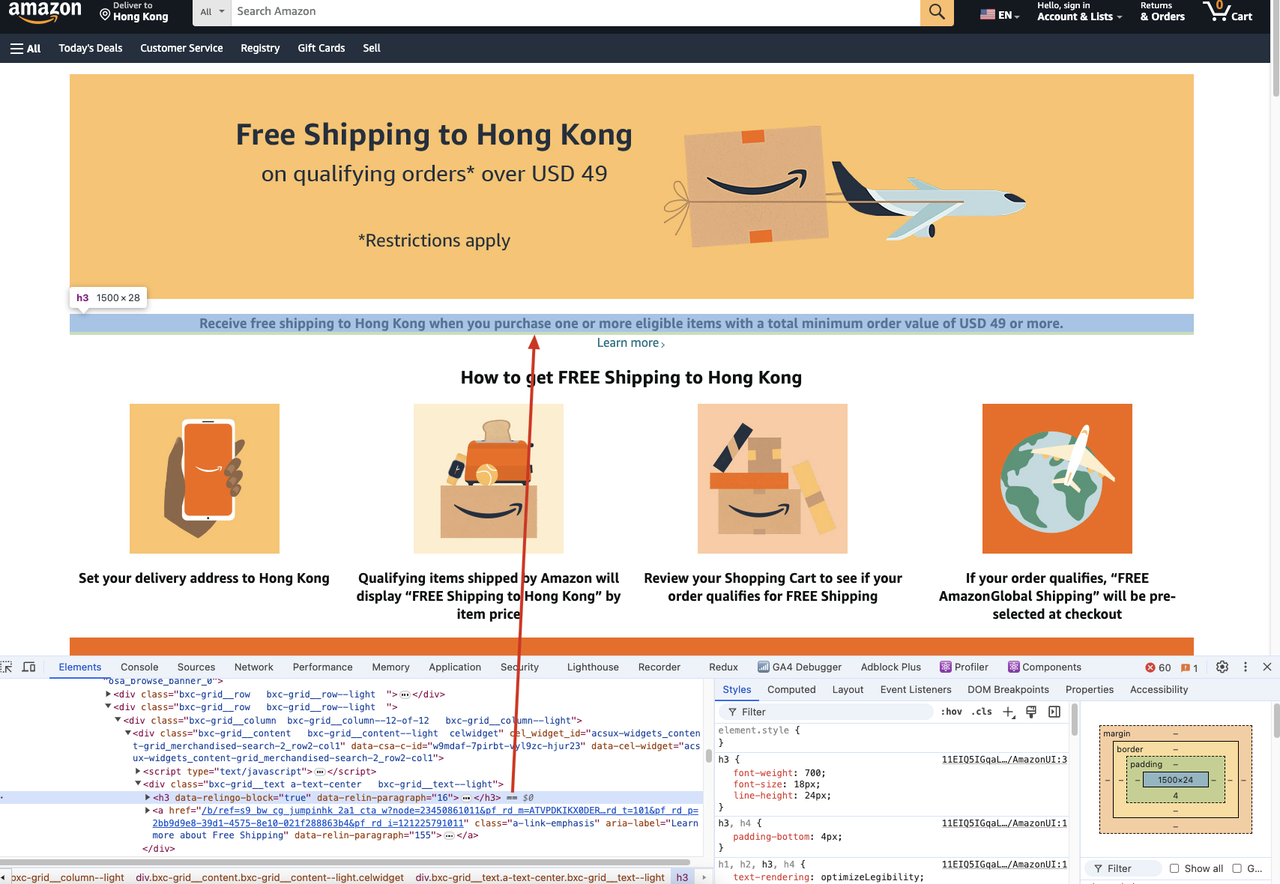
Нам нужно выполнить следующий код:
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # установите безголовый режим
"autoClose": True,
"args": {"--disable-gpu": "", "--no-sandbox": ""}, # аргументы браузера должны быть словарем
"fingerprint": {
"name": 'amazon_scraper',
"platform": 'mac', # поддержка: windows, mac, linux
"kernel": 'chromium', # поддержка: только chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8,
"deviceMemory": 8,
},
}
query = {'config': json.dumps(config)}
profileUrl = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
print("URL профиля: ", profileUrl)
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profileUrl)
try:
page = await browser.new_page()
await page.goto("https://www.amazon.com/b/?_encoding=UTF8&node=121225791011&pd_rd_w=Uoi8X&content-id=amzn1.sym.dde8a7c4-f315-46af-87af-ab98d7f18222&pf_rd_p=dde8a7c4-f315-46af-87af-ab98d7f18222&pf_rd_r=CM6698M8C3J02BBVTVM3&pd_rd_wg=olMbe&pd_rd_r=ff5d2eaf-26db-4aa4-a4dd-e74ea389f355&ref_=pd_hp_d_atf_unk&discounts-widget=%2522%257B%255C%2522state%255C%2522%253A%257B%255C%2522refinementFilters%255C%2522%253A%257B%257D%257D%252C%255C%2522version%255C%2522%253A1%257D%2522")
await page.wait_for_selector('h3')
title = await page.inner_text('h3')
print(title)
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())В приведенном выше коде мы в основном сделали следующие шаги:
- Создали сервис Nstbrowser, установили безголовый режим и некоторые основные параметры запуска в конфигурации запуска.
- Использовали Playwright для подключения к Nstbrowser.
- Перешли на соответствующую страницу, которую нужно было скрепить, чтобы получить ее содержимое.
После выполнения указанного выше кода вы в конечном итоге заметите следующий вывод:

Метод 2: Использование настраиваемых заголовков запроса для имитации настоящего браузера
Шаг 1. Мы должны использовать Playwright и Nstbrowser для посещения сайта, который может получить информацию о текущих заголовках запроса.
- Демонстрация кода:
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # установите безголовый режим
"autoClose": True,
"args": {"--disable-gpu": "", "--no-sandbox": ""}, # аргументы браузера должны быть словарем
"fingerprint": {
"name": 'amazon_scraper',
"platform": 'mac', # поддержка: windows, mac, linux
"kernel": 'chromium', # поддержка: только chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8,
"deviceMemory": 8,
},
}
query = {'config': json.dumps(config)}
profileUrl = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
print("URL профиля: ", profileUrl)
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profileUrl)
try:
page = await browser.new_page()
await page.goto("https://httpbin.org/headers")
await page.wait_for_selector('pre')
content = await page.inner_text('pre')
print(content)
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
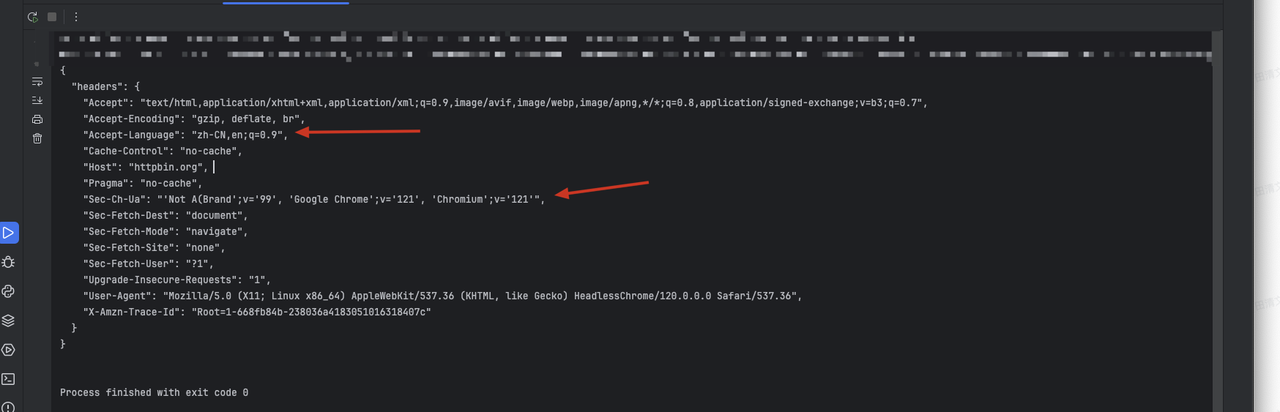
asyncio.run(main())Через указанный выше код мы увидим следующий результат:
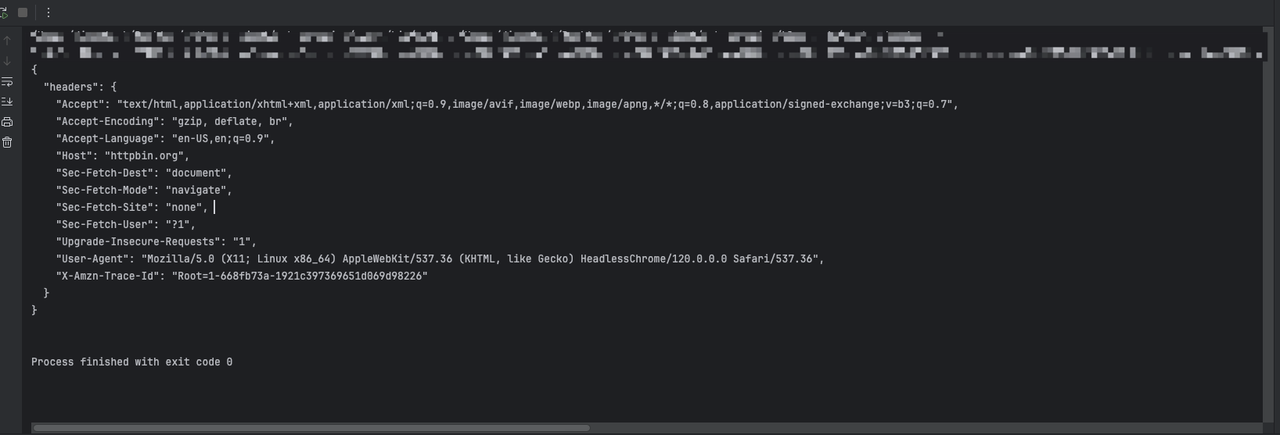
Шаг 2. Нам нужно использовать Playwright для добавления дополнительной информации в заголовки запроса, устанавливая перехват запросов при создании страницы:
Python
{
'sec-ch-ua': '\'Not A(Brand\';v=\'99\', \'Google Chrome\';v=\'121\', \'Chromium\';v=\'121\'',
'accept-Language': 'zh-CN,en;q=0.9'
}- Демонстрация кода:
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
extra_headers = {
'sec-ch-ua': '\'Not A(Brand\';v=\'99\', \'Google Chrome\';v=\'121\', \'Chromium\';v=\'121\'',
'accept-Language': 'en-US,en;q=0.9'
}
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # установите безголовый режим
"autoClose": True,
"args": ["--disable-gpu", "--no-sandbox"], # аргументы браузера должны быть списком
"fingerprint": {
"name": 'amazon_scraper',
"platform": 'mac', # поддержка: windows, mac, linux
"kernel": 'chromium', # поддержка: только chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8,
"deviceMemory": 8,
},
}
query = {'config': json.dumps(config)}
profileUrl = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
print("URL профиля: ", profileUrl)
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profileUrl)
try:
context = await browser.new_context()
page = await context.new_page()
# Добавление перехвата запросов для установки дополнительных заголовков
await page.route('**/*', lambda route, request: route.continue_(headers={**request.headers, **extra_headers}))
response = await page.goto("https://httpbin.org/headers")
print(await response.text())
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())Через указанный выше код мы увидим следующий возвращенный результат, в котором будет добавлена установленная нами информация:
sec-ch-ua.- Замененное содержание исходного заголовка
accept-Language.
Заключительные заметки
В общем:
Requestsстала первым выбором для большинства разработчиков благодаря своей простоте использования и богатым функциям.Urllib3выделяется, когда требуется производительность и более продвинутые функции.- В качестве части стандартной библиотеки
urllibподходит для проектов с высокими требованиями к зависимостям.
В зависимости от ваших конкретных потребностей и сценариев выбор наиболее подходящего инструмента поможет более эффективно управлять HTTP-запросами.
Больше





