
Web Scraping
Как сделать веб-скрэйпинг на Golang с помощью Colly?
Golang – один из самых мощных инструментов для веб-скрапинга. И Colly очень помогает при работе с Go. Прочитайте этот блог и узнайте самую подробную информацию о Colly, а также о том, как скрапить сайты с помощью Colly.
Sep 30, 2024Luke Ulyanov
Что такое Colly?
Go — это универсальный язык с пакетами и фреймворками, которые могут сделать практически все.
Сегодня мы будем использовать фреймворк под названием Colly, который представляет собой эффективный и мощный фреймворк для веб-скрейпинга, написанный на Go для извлечения данных из Интернета. Он предоставляет простой и удобный API, который позволяет разработчикам быстро создавать краулеры для посещения веб-страниц и извлечения необходимой информации.
Что такое Colly?
Colly предоставляет набор удобных и мощных инструментов для извлечения данных с веб-сайтов, автоматизации сетевых взаимодействий и создания инструментов веб-скрейпинга.
В этой статье вы получите практический опыт использования Colly и узнаете, как скачивать данные из Интернета с помощью Golang: Colly.
Как работает Colly?
Основная часть Colly — это Collector. Он отвечает за выполнение HTTP-запросов и позволяет вам определить, как обрабатывать запросы и ответы. Вызывая c := colly.NewCollector(), вы можете создать новый экземпляр Collector, который затем можно использовать для инициирования сетевых запросов и обработки данных.
Основные функции:
1. Методы Visit и Request:
Visit: Это наиболее часто используемый метод запроса, который непосредственно обращается к целевой веб-странице.Request: Позволяет вам прикрепить некоторую дополнительную информацию (например, пользовательские заголовки или параметры) при отправке запроса, что используется для более сложных сценариев запросов.
2. Механизм обратного вызова: Colly полагается на функции обратного вызова для выполнения на разных этапах жизненного цикла запроса. Collector предоставляет различные методы регистрации обратного вызова, в основном включающие следующие шесть:
OnRequest: Запускается перед отправкой HTTP-запроса, вы можете добавить пользовательские заголовки, напечатать информацию о запросе и т. д.OnError: Запускается, когда во время процесса запроса возникает ошибка, используется для захвата и обработки сбоев запросов.OnResponse: Запускается после получения ответа сервера, который можно использовать для обработки данных ответа.OnHTML: Запускается при получении HTML-содержимого и совпадении с указанным селектором CSS, используется для извлечения данных из HTML-страниц.OnXML: Запускается, когда содержимое ответа является XML или HTML и может использоваться для обработки содержимого в формате XML.OnScraped: Запускается после обработки всех запрошенных данных и является обратным вызовом в конце задачи сканирования.
3. Обратный вызов OnHTML:
- Наиболее часто используемая функция обратного вызова, зарегистрированная с помощью селектора CSS, когда Colly находит совпадающий элемент в DOM HTML, вызывается зарегистрированная функция обратного вызова.
- Colly использует библиотеку
goqueryдля разбора HTML и сопоставления селекторов CSS, а APIgoqueryаналогичен jQuery, поэтому селекторы в стиле jQuery можно использовать для извлечения данных со страницы.
Есть ли у вас замечательные идеи и сомнения по поводу веб-скрейпинга и Browserless?
Давайте посмотрим, чем делятся другие разработчики на Discord и Telegram!
Как скачивать данные из Интернета с помощью Golang?
Шаг 1. Подготовка среды
Установка Golang
Перейдите на официальный сайт Golang и выберите подходящую версию для загрузки и установки. Мы рекомендуем go1.20+. В этом руководстве используется go1.23.1.
После завершения установки вы можете проверить, была ли установка успешной, используя терминал:
Shell
go versionУспешный вывод информации о версии go означает, что установка прошла успешно.
Выберите подходящую IDE
Выберите подходящую IDE в соответствии со своими предпочтениями. Рекомендуется Visual Studio.
Шаг 2. Создание проекта
Далее, начните создавать проект.
- Создайте каталог проекта:
Shell
mkdir gocolly-browserless && cd gocolly-browserless- Инициализируйте проект Go:
Shell
go mod init colly-scraperВышеуказанная команда выполняет go mod init для инициализации проекта go с именем colly-scraper и генерирует файл go.mod в каталоге проекта со следующим содержимым:
Go
module colly-scraper
go 1.23.1- Затем создайте
main.goи создайте основной метод:
Go
package main
import "fmt"
func main() {
fmt.Println("Hello Nstbrowser!")
}- Запустите основной метод:
Shell
go run main.goЕсли вы видите напечатанную информацию успешно, значит, операция прошла успешно. Проект успешно построен.
Шаг 3. Используйте Colly
Отлично! Все приготовления завершены. Далее мы официально начнем использовать Colly для завершения простого скачивания данных.
Установите Colly
Введите следующую команду в корневом каталоге проекта, чтобы завершить установку Colly:
Shell
go get github.com/gocolly/collyЕсли во время установки возникнет ошибка, что текущая версия go не поддерживается, вы можете выбрать установку более ранней версии Colly или обновить Golang до соответствующей версии. После установки Colly go.mod выглядит следующим образом:
Go
module colly-scraper
go 1.23.1
require (
github.com/gocolly/colly v1.2.0 // indirect
...
)Основной принцип
Основной принцип работы Colly заключается в получении содержимого веб-страницы через HTTP-запросы, а затем в разборе DOM-структуры на веб-странице для извлечения необходимых нам конкретных данных. Его рабочий процесс можно разделить на следующие шаги:
- Создайте Collector: Это основной объект, используемый Colly для инициирования HTTP-запросов и обработки ответов.
- Определите функции обратного вызова: Colly обрабатывает определенные элементы или события (например, щелчки по ссылкам, разбор форм и т. д.) при разборе HTML, регистрируя функции обратного вызова.
- Посетите целевой веб-сайт: Вызывая метод Visit(), Collector инициирует запрос к указанному URL.
- Обработайте данные ответа: Обработайте HTML-данные в функции обратного вызова, чтобы извлечь необходимую информацию.
Пример начала работы
Ниже приведен простой пример посещения официального сайта Nstbrowser
Go
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
// Создайте новый коллектор
c := colly.NewCollector()
// Функция обратного вызова, вызываемая, когда краулер находит элемент <title>
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Page Title:", e.Text)
})
// Обработка ошибок
c.OnError(func(_ *colly.Response, err error) {
fmt.Println("Error:", err)
})
// Посетите целевую страницу
c.Visit("https://nstbrowser.io")
}После выполнения вышеуказанного кода краулер выведет содержимое элемента title страницы. Это основной рабочий процесс Colly, который позволяет легко анализировать HTML и извлекать необходимую информацию. Выполнение go run main.go выведет информацию, аналогичную следующей:
Plain Text
Page Title: Nstbrowser - Advanced Anti-Detect Browser for Web Scraping and Multiple Accounts ManagingОбщие настройки
Colly — это мощный и гибкий фреймворк для сканирования Golang, который может управлять поведением краулера с помощью конфигурации. Ниже подробно представлены часто используемые параметры конфигурации в Colly и объяснены их сценарии использования и методы реализации.
- Конфигурация Collector
colly.NewCollector используется для создания нового экземпляра Collector, который является основной частью краулера. Передавая различные параметры конфигурации, вы можете настроить поведение краулера, например, ограничив сканируемые доменные имена, максимальную глубину сканирования, асинхронное сканирование и т. д.
Пример
Go
c := colly.NewCollector(
colly.AllowedDomains("example.com"), // Ограничение определенными доменами
colly.MaxDepth(3), // Ограничение глубины сканирования
colly.Async(true), // Включение асинхронного сканирования
colly.IgnoreRobotsTxt(), // Игнорирование правил robots.txt
colly.DisallowedURLFilters(regexp.MustCompile(".*.jpg")), // Пропуск определенных URL
...
)- Конфигурация запроса
Colly предоставляет несколько методов для настройки поведения HTTP-запросов, например, установку пользовательских заголовков запросов, прокси, куки и т. д. С помощью этих настроек краулер может имитировать поведение реальных пользователей и обходить некоторые механизмы защиты от краулеров.
Пользовательский заголовок UA
Вы можете установить пользовательские сведения об HTTP-заголовке для каждого запроса с помощью метода Headers.Set. Например, установите User-Agent для имитации поведения доступа браузера, чтобы избежать перехвата механизмами защиты от краулеров.
Go
c.OnRequest(func(r *colly.Request) {
r.Headers.Set("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
...
})Управление куки
Colly автоматически обрабатывает куки по умолчанию, но вы также можете вручную установить определенные куки. Например, при сканировании определенных страниц, которые требуют входа в систему, вы можете предварительно установить куки после входа в систему.
Go
c.SetCookies("http://example.com", []*http.Cookie{
&http.Cookie{
Name: "session_id",
Value: "1234567890",
Domain: "example.com",
},
})Настройка прокси
Использование прокси-сервера может скрыть ваш реальный IP-адрес и обойти политики блокировки IP некоторых веб-сайтов. Colly поддерживает одиночный прокси и динамическое переключение прокси.
Go
c.SetProxy("ваш URL прокси")Установите время ожидания запроса
Когда веб-сайт медленно отвечает, установка времени ожидания запроса может предотвратить зависание программы в течение длительного времени. По умолчанию время ожидания Colly составляет 10 секунд, и вы можете по своему усмотрению настроить время ожидания.
Go
c.SetRequestTimeout(30 * time.Second)Обратные вызовы
Colly поддерживает обработку обратного вызова для различных событий, таких как успешная загрузка страницы, обнаружение элемента, ошибка запроса и т. д. С помощью этих обратных вызовов вы можете гибко обрабатывать скачанный контент или обрабатывать ошибки в процессе сканирования.
Общие примеры обратных вызовов:
- OnRequest
Этот обратный вызов будет вызван перед отправкой каждого запроса. Здесь вы можете динамически установить заголовок запроса или другие параметры.
Go
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting:", r.URL.String())
})- OnResponse
Этот обратный вызов вызывается при получении ответа для обработки исходных данных HTTP-ответа.
Go
c.OnResponse(func(r *colly.Response) {
fmt.Println("Received:", string(r.Body))
})- OnHTML
Используется для обработки конкретных элементов на HTML-страницах. Когда на странице появляется соответствующий HTML-элемент, этот обратный вызов будет вызван для извлечения необходимой информации.
Go
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Page Title:", e.Text)
})- OnError
Этот обратный вызов вызывается, когда в запросе возникает ошибка. Здесь вы можете обработать исключение.
Go
c.OnError(func(_ *colly.Response, err error) {
fmt.Println("Error:", err)
})- Ограничение запросов
Colly также предоставляет некоторые параметры для оптимизации производительности краулера, например, ограничения количества одновременных запросов, увеличение скорости сканирования и установка задержки между запросами.
Go
c.Limit(&colly.LimitRule{
DomainGlob: "*", // DomainRegexp - это шаблон глобуса для сопоставления с доменами
Delay: 3 * time.Second, // Delay - это продолжительность ожидания перед созданием нового запроса к соответствующим доменам
Parallelism: 2, // Parallelism - это количество максимально допустимых одновременных запросов соответствующих доменов
})Дополнительные настройки см. в официальной документации Colly.
Расширенный пример
Сочетая знания, которые мы получили ранее, давайте сканируем данные классифицированной информации на главной странице Википедии и выведем результаты:
- Анализ элементов страницы
После входа на главную страницу мы щелкаем правой кнопкой мыши -> Inspect или нажимаем сочетание клавиш F12, чтобы перейти к анализу элементов страницы:
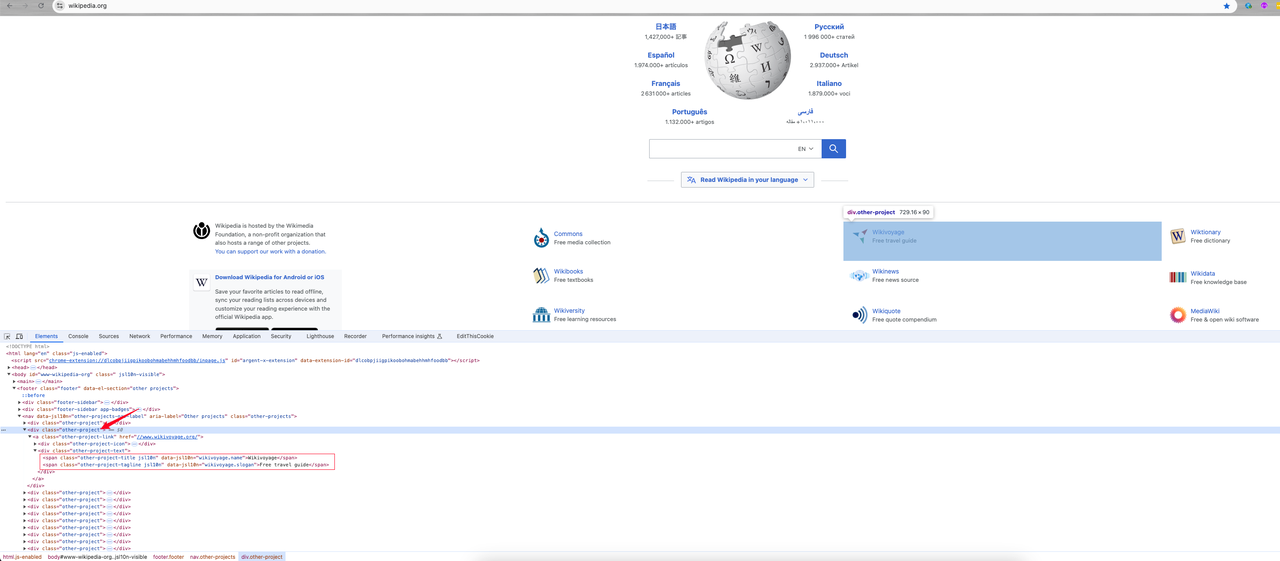
Мы можем найти:
- Информация о категории, которая мне нужна, - это элемент
divс именем классаother-project, где ссылка категории - это значение атрибутаhrefв теге a. Его имя класса -other-project-link. - Продолжайте отслеживать этот элемент, и он покажет, что два имени класса
span(other-project-titleиother-project-tagline) в элементе класса .other-project-text - это его имя категории и введение.
Далее, начните кодирование, чтобы получить нужные нам данные.
- Кодирование
Go
package main
import (
"fmt"
"time"
"github.com/gocolly/colly"
)
func main() {
// Создайте новый коллектор
c := colly.NewCollector()
// Обработка ошибок
c.OnError(func(_ *colly.Response, err error) {
fmt.Println("Error:", err)
})
// Пользовательский заголовок запроса: User-Agent
c.OnRequest(func(r *colly.Request) {
r.Headers.Set("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
})
// Установка прокси
c.SetProxy("ваш прокси")
// Установка времени ожидания запроса
c.SetRequestTimeout(30 * time.Second)
c.Limit(&colly.LimitRule{
DomainGlob: "*", // DomainRegexp - это шаблон глобуса для сопоставления с доменами
Delay: 1 * time.Second, // Delay - это продолжительность ожидания перед созданием нового запроса к соответствующим доменам
Parallelism: 2, // Parallelism - это количество максимально допустимых одновременных запросов соответствующих доменов
})
// Ожидайте появления элементов с классом "other-project-text"
c.OnHTML("div.other-project", func(e *colly.HTMLElement) {
link := e.ChildAttrs(".other-project-link", "href")
title := e.ChildText(".other-project-link .other-project-text .other-project-title")
tagline := e.ChildText(".other-project-link .other-project-text .other-project-tagline") // проект tagline
fmt.Println(fmt.Sprintf("%s => %s(%s)", title, tagline, link))
})
// Посетите целевую страницу
c.Visit("https://wikipedia.org")
}- Запуск проекта
Shell
go run main.go- Результат
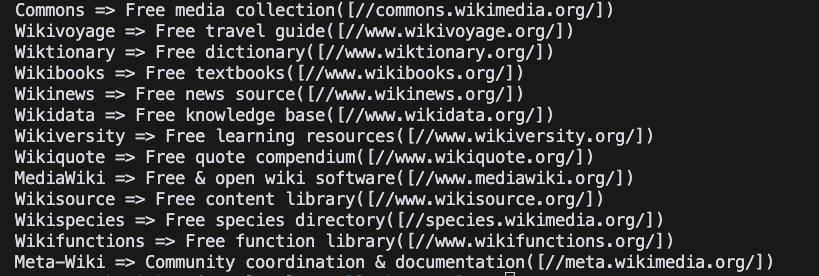
Итоги
Остановимся здесь, дорогие! Nstbrowser всегда помогает вам упростить каждый сложный шаг веб-скрейпинга и автоматизации задач. В этом замечательном блоге мы узнали:
- Как создать базовую среду Colly.
- Общие методы конфигурации и использования Colly.
- Используйте Colly для завершения посещения официального сайта Nstbrowser и скачивания данных классификации Wiki с главной страницы Википедии.
На примерах мы увидели простоту и мощные возможности скачивания данных Colly. Дополнительные сведения об использовании см. в официальной документации Colly.
Больше





