
Web Scraping
Лучший браузер-антидетектор для веб-скрапинга 2024
Браузер-антиопределитель поможет вам скрыть отпечаток пальца браузера при соскабливании веб-страницы. Это действительно упрощает ваши задачи. Читайте этот блог и узнайте больше!
Jul 19, 2024Vasilisa Samsonova
Браузерные отпечатки — один из наиболее значимых способов идентификации вашей онлайн-жизни. Они отслеживают ваш профиль в разных сессиях и на разных веб-сайтах. Поэтому, когда вы хотите заниматься веб-скрапингом, вас неизбежно обнаружат.
Чтобы легко и эффективно собирать данные, были созданы антидетект-браузеры (или браузеры с защитой от отпечатков).
Этот блог поможет вам понять:
- Преимущества антидетект-браузера
- Как он помогает с веб-скрапингом
- Шаги для эффективного сбора данных с Nstbrowser
Что такое антидетект-браузер?
Антидетект-браузер способен создавать и запускать несколько цифровых идентичностей, которые не распознаются социальными платформами. Это требует значительной работы разработчиков, поэтому такие инструменты обычно не предоставляются бесплатно.
Они созданы для борьбы с отслеживанием и аналитикой, чтобы вы могли заниматься своими делами в приватности. Другими словами, антидетект-браузер улучшает конфиденциальность, сохраняет ваши данные и веб-активности анонимными и помогает вашим инструментам веб-скрапинга избегать блокировок.
Попробуйте бесплатный антидетект-браузер — Nstbrowser!
Разблокируйте 99.9% веб-сайтов с помощью множества эффективных решений
Упростите веб-скрапинг и автоматизацию
Есть ли у вас хорошие идеи или вопросы о веб-скрейпинге и Browserless?
Посмотрите чем делятся другие разработчики в Discord и Telegram!
Как антидетект-браузеры помогают в сборе данных?
Антидетект-браузер помогает снизить влияние веб-перехвата. Он минимизирует или даже предотвращает распознавание пользователей веб-сайтами и отслеживание их онлайн-активности.
Поскольку веб-сайты имеют системы защиты от скрапинга, когда вы используете бота для прямого сбора данных, вас обнаружат и заблокируют. Людям отдают предпочтение перед ботами, и некоторые веб-сайты не поощряют сбор данных другими компаниями.
В результате несколько организаций объединяют технологии веб-скрапинга и антидетект-браузеры с мерами конфиденциальности, такими как прокси-серверы, чтобы скрыть ботов.
Что такое Nstbrowser?
Nstbrowser — это полностью бесплатный браузер с защитой от отпечатков, интегрированный с антидетект-ботом, Web Unblocker и интеллектуальными прокси. Он поддерживает кластеризацию облачных контейнеров, безголовый режим работы и корпоративное облачное браузерное решение, совместимое с Windows/Mac/Linux.
Как выполнять веб-скрапинг с помощью антидетект-браузера?
Давайте рассмотрим пример скрапинга с использованием Nstbrowser. Всего 5 простых шагов:
Шаг 1. Подготовка
Перед скрапингом необходимо выполнить следующие приготовления:
Shell
pip install pyppeteer requests jsonПосле установки pyppeteer нужно создать новый файл: scraping.py, и импортировать библиотеки, которые мы только что установили, а также некоторые системные библиотеки:
Python
import asyncio
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from pyppeteer import launcherМожем ли мы использовать pyppeteer сейчас?
Пожалуйста, сохраняйте спокойствие!
Мы потратили несколько минут на подключение к Nstbrowser, который предоставляет API для возврата webSocketDebuggerUrl для pyppeteer.
Python
# get_debugger_url: Получить URL отладки
def get_debugger_url(url: str):
try:
resp = requests.get(url).json()
if resp['data'] is None:
raise Exception(resp['msg'])
webSocketDebuggerUrl = resp['data']['webSocketDebuggerUrl']
return webSocketDebuggerUrl
except HTTPError:
raise Exception(HTTPError.response)
async def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'your api key'
config = {
'once': True,
'headless': False,
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # требуется
'name': 'custom browser',
'platform': 'windows', # поддержка: windows, mac, linux
'kernel': 'chromium', # поддержка: chromium
'kernelMilestone': '120', # поддержка: 113, 115, 118, 120
'hardwareConcurrency': 4, # поддержка: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # поддержка: 2, 4, 8
'proxy': '', # формат ввода: schema://user:password@host:port например: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # требуется
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
browser_ws_endpoint = get_debugger_url(url)
print("browser_ws_endpoint: " + browser_ws_endpoint) # pyppeteer подключение Nstbrowser с browser_ws_endpoint
(
asyncio
.get_event_loop()
.run_until_complete(create_and_connect_to_browser())
)Отлично! Мы успешно получили webSocketDebuggerUrl для Nstbrowser!
Теперь пора подключить pyppeteer к Nstbrowser:
Python
async def exec_pyppeteer(wsEndpoint: str):
browser = await launcher.connect(browserWSEndpoint = wsEndpoint)
page = await browser.newPage()Запустите написанный код в терминале: python scraping.py, и мы успешно открыли Nstbrowser и создали в нем новую вкладку.
Все готово, теперь мы можем официально начать скрапинг!
Шаг 2. Посещение целевого веб-сайта
Например: https://www.yahoo.com/
Python
options = {'timeout': 60000}
await page.goto('https://www.yahoo.com/', options)Шаг 3. Выполнение кода
Выполните код еще раз, и мы получим доступ к нашему целевому веб-сайту через Nstbrowser.
Теперь нам нужно открыть Devtool, чтобы увидеть конкретную информацию, которую мы хотим собрать, и мы можем видеть, что все они являются элементами с одинаковой DOM-структурой.
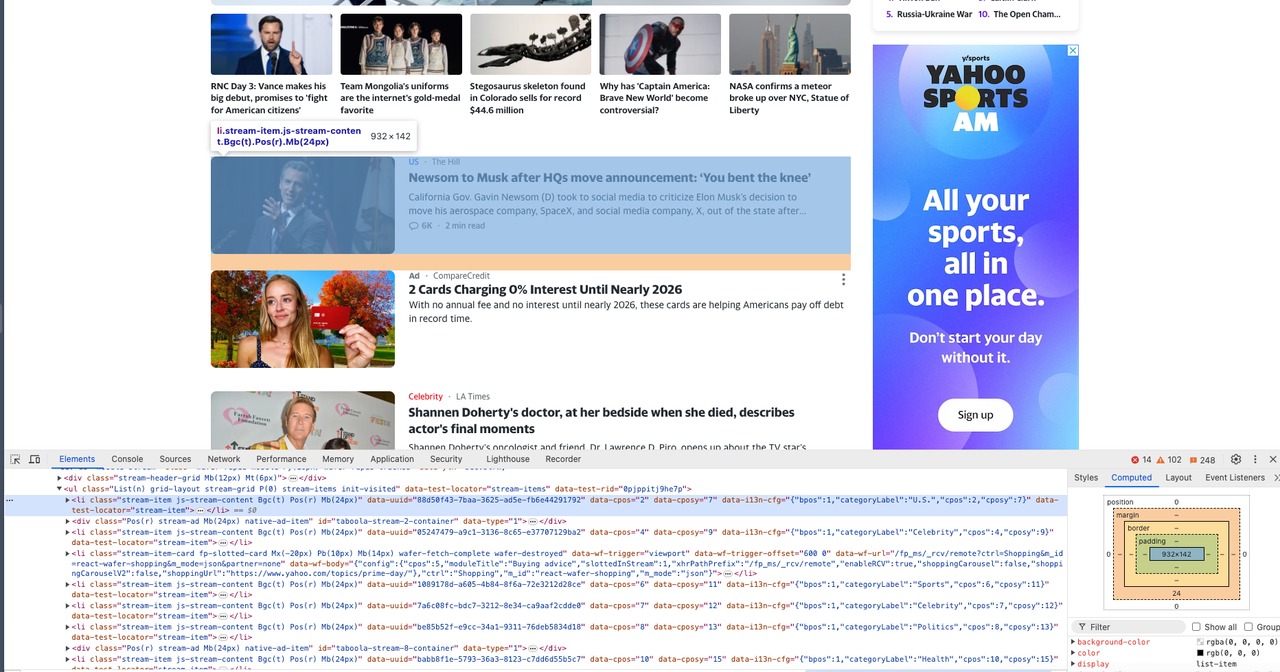
Шаг 4. Скрапинг веб-страницы
Теперь настало время использовать Pyppeteer для скрапинга этих DOM-структур и анализа их содержимого:
Python
news = await page.JJ('li.stream-item')
for row in news:
title = await row.J('a:not([data-test-locator])')
content = await row.J('p')
comment = await row.J('span[data-test-locator="stream-comment"]')
title_text = await page.evaluate('item => item.textContent', title)
content_text = await page.evaluate('item => item.textContent', content)
comment_text = await page.evaluate('item => item.textContent', comment)
pringt('title: ', title_text)
pringt('content: ', content_text)
pringt('comment: ', comment_text)Конечно, просто вывод данных в терминал явно не является нашей конечной целью. Нам также нужно сохранить данные.
Шаг 5. Сохранение данных
Мы используем библиотеку json, чтобы сохранить данные в локальный файл json:
Python
news = await page.JJ('li.stream-item')
news_info = []
for row in news:
title = await row.J('a:not([data-test-locator])')
content = await row.J('p')
comment = await row.J('span[data-test-locator="stream-comment"]')
title_text = await page.evaluate('item => item.textContent', title)
content_text = await page.evaluate('item => item.textContent', content)
comment_text = await page.evaluate('item => item.textContent', comment)
news_item = {
"title": title_text,
"content": content_text,
"comment": comment_text
}
news_info.append(news_item)
# создать json файл
json_file = open("news.json", "w")
# преобразовать movies_info в JSON
json.dump(news_info, json_file)
# освободить ресурсы файла
json_file.close()Запустите наш код, затем откройте папку, где находится код. Вы увидите новый файл news.json. Откройте его, чтобы проверить содержимое!
Если вы обнаружите, что он выглядит так:
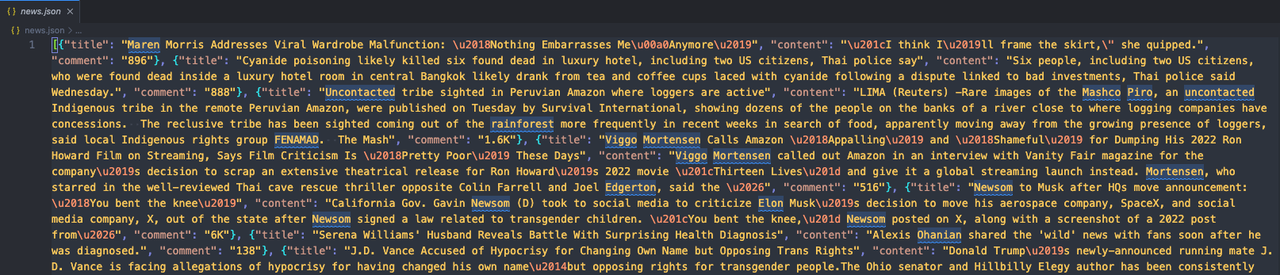
Это значит, что мы успешно скрапировали целевой веб-сайт с использованием Pyppeteer и Nstbrowser!
Почему антидетект-браузер лучше всего подходит для веб-скрапинга?
Антидетект-браузер очень эффективен для веб-скрапинга благодаря способности имитировать поведение человека в Интернете и избегать обнаружения веб-сайтами. Позвольте мне показать вам 6 основных функций:
1. Избежание блокировки IP
Веб-сайты часто отслеживают и ограничивают количество запросов с одного IP-адреса. Антидетект-браузеры могут интегрироваться с прокси-сервисами, позволяя скраперам автоматически менять IP-адреса и избегать превышения лимитов запросов или блокировок.
2. Обход отпечатков браузера
Веб-сайты используют отпечатки браузера, чтобы обнаруживать и блокировать автоматизированный трафик. Антидетект-браузеры могут изменять характеристики браузера, такие как user-agent, разрешение экрана и установленные плагины, создавая уникальные отпечатки, которые делают автоматизированные запросы похожими на запросы от разных пользователей.
3. Человеко-подобное взаимодействие
Антидетект-браузеры могут имитировать взаимодействие человека, например, движения мыши, клики и ввод с клавиатуры. Это поведение помогает избегать механизмов обнаружения, которые мониторят нехарактерные для человека действия, делая процесс скрапинга более естественным и менее вероятным для блокировки.
4. Ротация user-agent
Любой антидетект-браузер позволяет менять строки user-agent, что помогает скрыть активность скрапера. Таким образом, запросы будут распознаваться как запросы с разных браузеров и устройств. Это разнообразие user-agent делает сложнее для веб-сайтов идентифицировать и блокировать скрапера.
5. Выполнение JavaScript
Многие современные веб-сайты сильно зависят от JavaScript для динамического отображения контента. Антидетект-браузеры могут выполнять JavaScript, что обеспечивает доступ и взаимодействие с контентом, который недоступен в исходном HTML-коде.
6. Решение капчи
Антидетект-браузеры часто поддерживают интеграцию с сервисами решения капчи. Эта функция важна для обхода капчи, которую веб-сайты используют для предотвращения автоматизированного скрапинга.
Заключительные мысли
С учетом того, что любой человек может поджидать удобного момента, чтобы украсть ваши данные, и любая компания готовится собрать вашу информацию для продвижения своего бизнеса, конфиденциальность жизненно важна.
Антидетект-браузеры — отличный способ защитить ваши данные без обнаружения ботами. Они также могут помочь вам улучшить задачи веб-скрапинга.
Пришло время использовать Nstbrowser, чтобы помочь вам защитить конфиденциальность и быстро и эффективно выполнять веб-скрапинг!
Вам также может понравиться:
Управление несколькими учетными записями с помощью антидетект-браузера
Больше





