
Web Scraping
Web Crawler на Java: пошаговое руководство 2024
Java web Crawler помогает легко выполнять задачи веб-скрапинга и автоматизации. Как выполнять веб-скрапинг с помощью Java web Crawler? Здесь есть все, что вам понравится!
Aug 16, 2024Vasilisa Samsonova
Какой эффективный способ получить полезную информацию с веб-сайта? Очевидно, что это веб-сканер на Java!
В этом блоге вы узнаете:
- В чем разница между веб-сканером и веб-скрапингом?
- Как использовать Jsoup для анализа и извлечения данных с веб-страниц?
- Как избежать обнаружения и улучшить эффективность и стабильность сканирования?
Можно ли выполнять веб-скрапинг на Java?
Да! Java, как зрелый и широко используемый язык программирования, предоставляет мощную поддержку, которая делает веб-скрапинг эффективным и надежным. Java может полагаться на множество библиотек. Это значит, что вы можете выбрать любую из множества библиотек для веб-скрапинга на Java.
Вот некоторые основные преимущества веб-скрапинга на Java:
- Богатые библиотеки и фреймворки. Java предоставляет мощные библиотеки и фреймворки, такие как Jsoup, Selenium и Apache HttpClient. Они могут помочь разработчикам легко скрапить и анализировать веб-данные.
- Отличная производительность. Эффективное управление памятью и поддержка многопоточности в Java обеспечивают хорошую производительность при обработке больших объемов данных.
- Кросс-платформенные возможности. Java обладает независимостью от платформы, что позволяет запускать её на различных операционных системах, будь то Windows, Linux или macOS, обеспечивая согласованность и совместимость инструментов для скрапинга.
- Мощные возможности обработки данных. Возможности Java по обработке данных очень мощные, она легко справляется с сложными структурами данных и большими наборами данных. Будь то простой парсинг текста или сложное преобразование данных, Java может предоставить эффективные решения.
- Безопасность. Функции безопасности Java, такие как модель песочницы и менеджер безопасности, обеспечивают дополнительную защиту для сканеров в сетевой среде, так что безопасность вашей системы не подвергается угрозе.
С этими преимуществами Java является идеальным выбором для создания надежных и эффективных инструментов веб-сканирования. Будь то сканирование статических веб-данных или обработка динамического контента, Java может предоставить разработчикам надежное решение.
Что такое веб-сканер на Java?
В Java веб-сканер — это автоматическая программа, используемая для сбора данных из Интернета. Она извлекает информацию с веб-страниц, имитируя процесс посещения пользователями веб-страниц, и сохраняет или обрабатывает её для последующего использования.
Основные функции веб-сканера на Java:
- Отправка HTTP-запросов. С помощью библиотеки HTTP-клиента Java (например, HttpURLConnection или Apache HttpClient) сканер может отправлять запросы на целевой веб-сайт для получения контента веб-страницы.
- Анализ контента веб-страницы. Используя библиотеки анализа HTML (например, Jsoup), сканер может анализировать контент веб-страницы в управляемую структуру DOM, чтобы извлечь из нее необходимую информацию.
- Обработка данных. Извлеченная информация может быть дополнительно обработана, сохранена или проанализирована. Например, данные могут быть сохранены в базе данных, сгенерированы отчеты или проведен статистический анализ.
- Следование по ссылкам. Сканер может следовать по ссылкам на веб-странице и рекурсивно сканировать несколько веб-страниц для получения более полной информации.
Основное отличие между веб-скрапингом и веб-сканером
Веб-скрапинг нацелен на извлечение данных с веб-страниц, тогда как веб-сканирование нацелено на индексацию и поиск веб-страниц.
Веб-скрапинг подразумевает написание программы, которая может тайно собирать данные с нескольких веб-сайтов. В отличие от этого, веб-сканирование включает в себя постоянное следование за ссылками на основе гиперссылок.
У вас есть идеи или сомнения по поводу веб-скрапинга и Browserless?
Посмотрим, что другие разработчики обсуждают на Discord и Telegram!
Как выполнять веб-скрапинг с помощью Jsoup и Nstbrowser API?
Возьмем в качестве примера захват основной информации и цен на криптовалюты на главной странице CoinmarketCap, чтобы показать, как использовать Jsoup и Selenium в веб-сканере на Java через Nstbrowser API, в частности, используя LaunchExistBrowser API.
Перед началом сканирования данных нам необходимо:
- Заранее загрузить и установить Nstbrowser и сгенерировать ваш API ключ.
- Создать профиль и нажать, чтобы запустить профиль, чтобы автоматически загрузить соответствующую версию ядра.
- Единственный шаг, который остался — это загрузить chromedriver соответствующей версии ядра перед использованием Selenium, что можно найти здесь: Как использовать Selenium в Nstbrowser.
Анализ страницы
Начнем с анализа сайта и посмотрим, как выглядит страница, которую мы хотим сканировать:
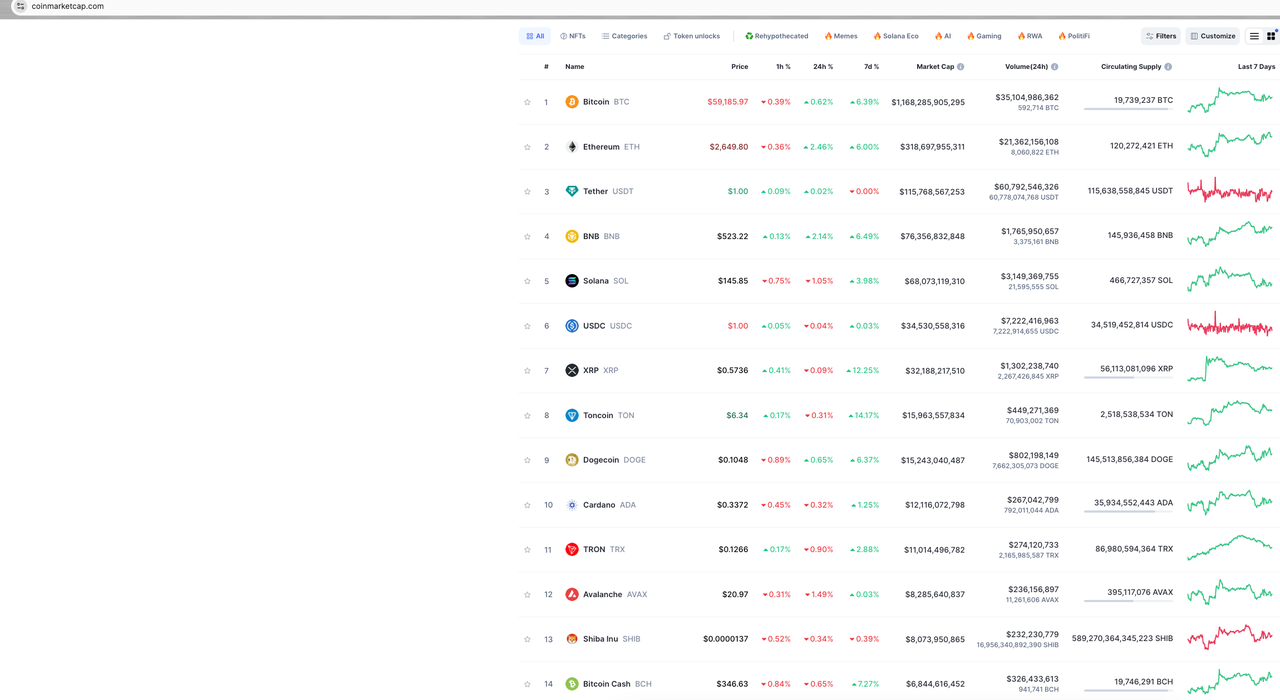
Наша целевая информация — это данные на главной странице CoinmarketCap. Мы только захватим некоторые данные для демонстрации, такие как ранжирование криптовалют, логотипы криптовалют, символы криптовалют и цены на валюту.
Далее мы поэтапно проанализируем каждую часть данных, которые нам нужны.
Шаг 1. Откройте консоль браузера и начните просмотр элементов страницы:
Общий анализ
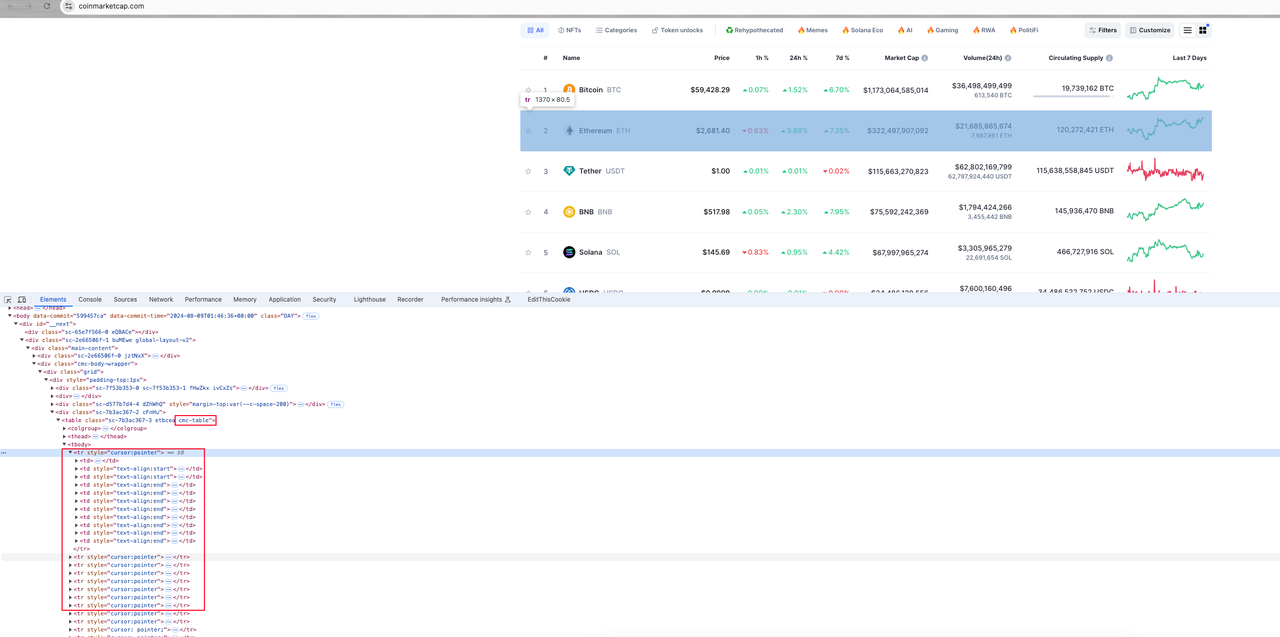
Вся информация о валюте на странице содержится в элементе table с именем класса cmc-rable. Элемент страницы, соответствующий каждой информации о валюте, — это строка таблицы tr под элементом таблицы. Каждая строка таблицы содержит несколько элементов столбца таблицы td. Наша цель — проанализировать целевые данные из этих элементов td.
Шаг 2. Мы будем искать и анализировать каждую целевую информацию:
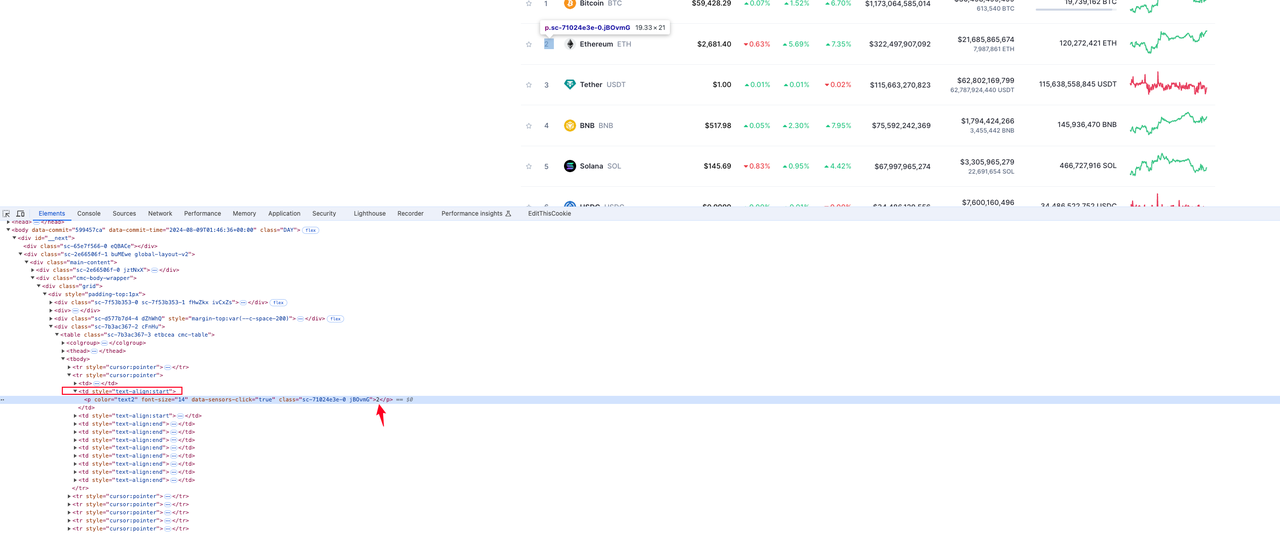
Ранг криптовалюты
На рисунке ниже видно, что элемент, в котором находится ранжирование валюты, находится в значении тега p под вторым элементом td в tr:
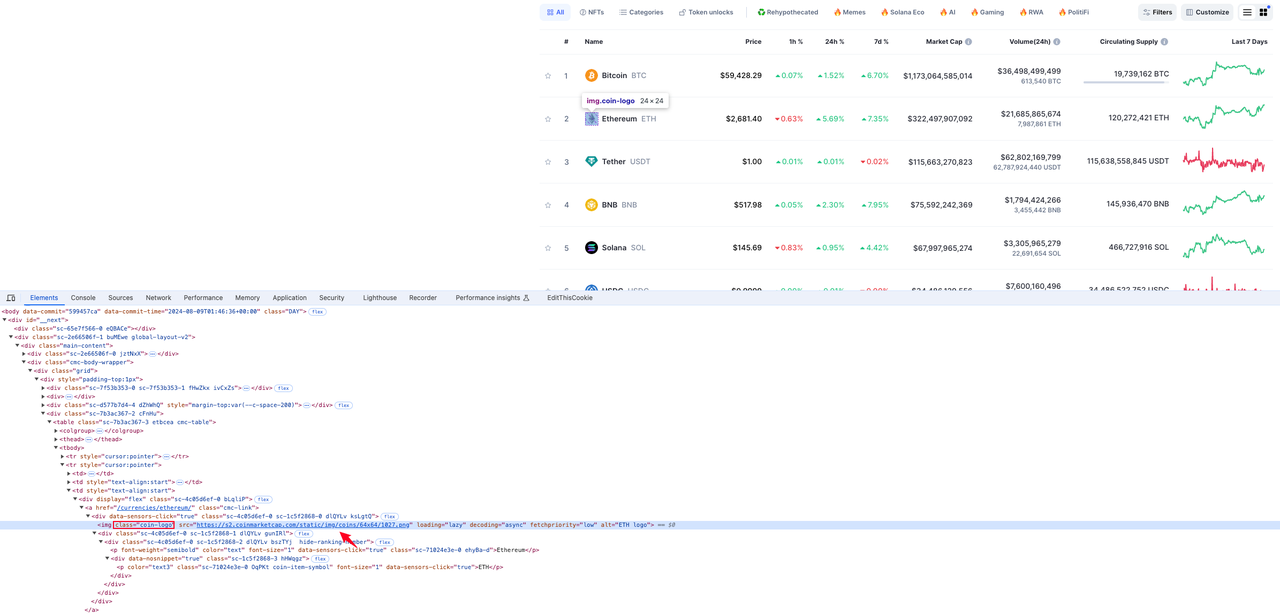
Логотип криптовалюты
Элемент, в котором находится значок логотипа валюты, находится в значении атрибута src тега img с именем класса coin-logo в элементе строки tr:
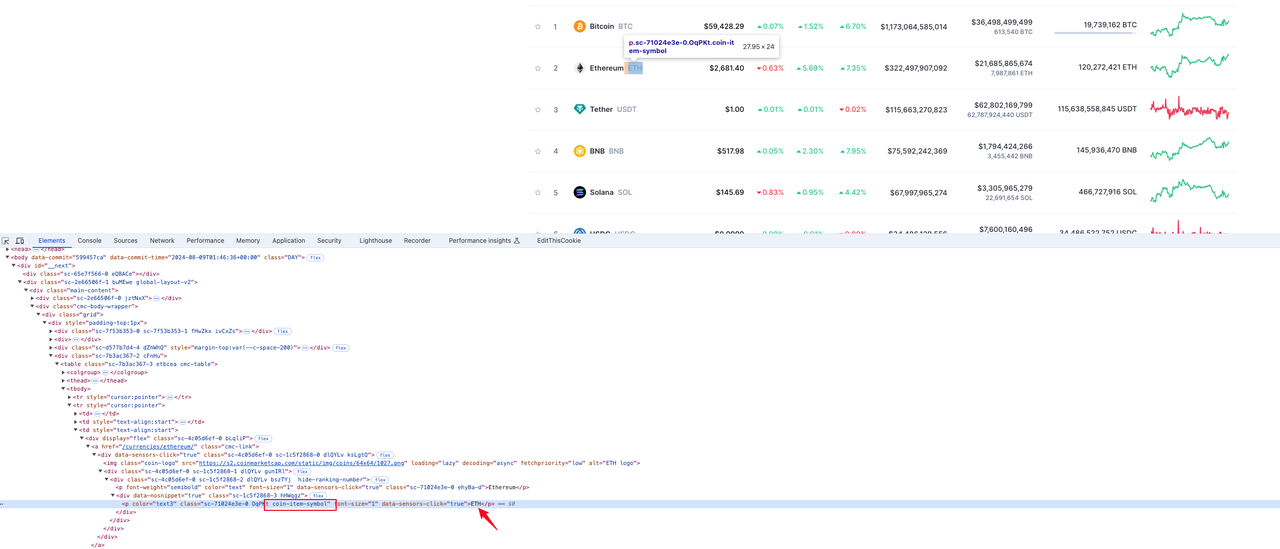
Символ криптовалюты
Элемент, в котором находится информация о валюте, находится в значении тега p с именем класса coin-item-symbol в элементе строки tr:
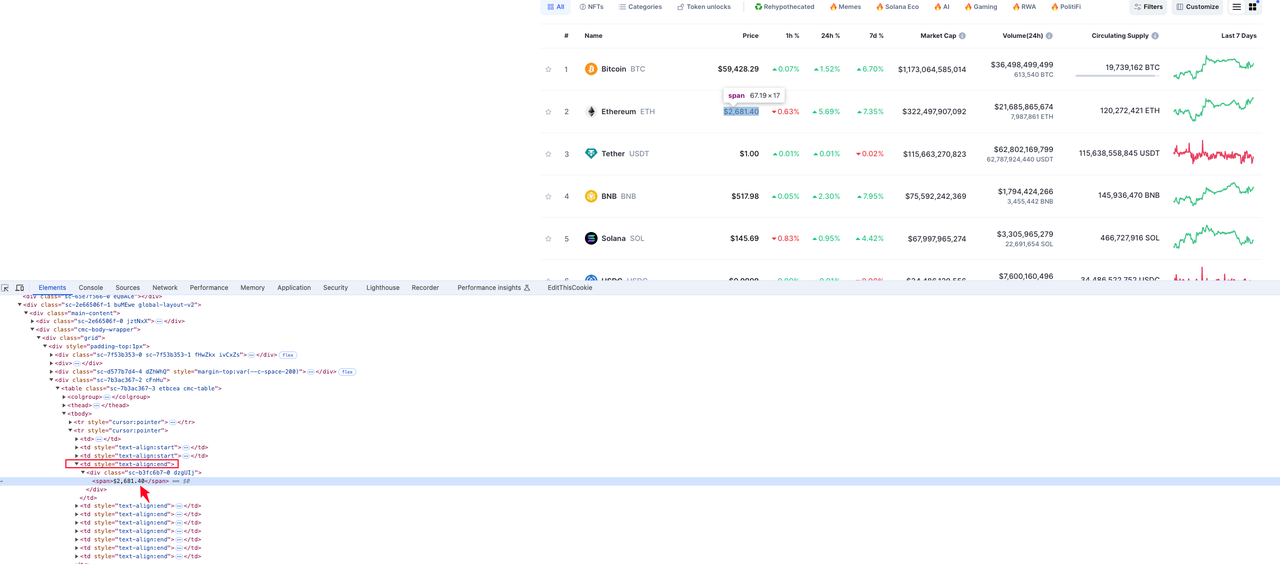
Цена криптовалюты
Элемент, в котором находится информация о валюте, — это значение элемента div span под четвертым элементом td в строке элемента tr:
После анализа мы получили элементы, в которых находятся целевые данные, которые нам нужны. Вы можете самостоятельно изучить анализ других элементов данных.
Вот перевод на русский:
Кодирование
Без лишних слов, давайте сразу перейдём к коду:
зависимости (build.gradle)
Java
dependencies {
implementation 'com.squareup.okhttp3:okhttp:4.12.0'
implementation 'com.google.code.gson:gson:2.10.1'
implementation 'org.jsoup:jsoup:1.17.2'
implementation "org.seleniumhq.selenium:selenium-java:4.14.1"
}CmcRank.java
Java
public class CMCRank {
// ранг монеты
private Integer rank;
// символ монеты
private String coinSymbol;
// логотип монеты
private String coinLogo;
// цена монеты
private String price;
// геттеры и сеттеры опущены
}CmcScraper.java
Java
import com.google.gson.Gson;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
import org.openqa.selenium.*;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class CmcScraper {
// http-клиент
private static final OkHttpClient client = new OkHttpClient();
// gson
private static final Gson gson = new Gson();
// ваш apiKey
private static final String API_KEY = "your apikey";
// ваш profileId
private static final String PROFILE_ID = "your profileId";
// url сайта cmc
private static final String BASE_URL = "https://coinmarketcap.com";
// базовый url API nstbrowser
private final String baseUrl;
// путь к файлу webdriver
private final String webdriverPath;
public CmcScraper(String baseUrl, String webdriverPath) {
this.baseUrl = baseUrl;
this.webdriverPath = webdriverPath;
}
public void scrape() {
String url = String.format("%s/devtool/launch/%s", this.baseUrl, PROFILE_ID);
Request request = new Request.Builder()
.url(url)
.get()
.addHeader("Content-Type", "application/json")
.addHeader("x-api-key", API_KEY)
.build();
try (Response response = client.newCall(request).execute()) {
if (!response.isSuccessful()) {
throw new IOException("Unexpected code " + response);
}
Map<String, Object> responseBody = gson.fromJson(response.body().string(), Map.class);
Map<String, Object> data = (Map<String, Object>) responseBody.get("data");
Double port = (Double) data.get("port"); // получаем порт браузера
if (port != null) {
this.execSelenium("localhost:" + port.intValue());
} else {
throw new IOException("Port not found in response");
}
} catch (IOException e) {
throw new RuntimeException("Failed to scrape", e);
}
}
public void execSelenium(String debuggerAddress) {
System.setProperty("webdriver.chrome.driver", this.webdriverPath);
ChromeOptions options = new ChromeOptions();
options.setExperimentalOption("debuggerAddress", debuggerAddress);
try {
WebDriver driver = new ChromeDriver(options);
driver.get(BASE_URL);
WebElement cmcTable = driver.findElement(By.cssSelector("table.cmc-table"));
if (cmcTable != null) {
List<WebElement> tableRows = cmcTable.findElements(By.cssSelector("tbody tr"));
List<CMCRank> cmcRanks = new ArrayList<>(tableRows.size());
for (WebElement row : tableRows) {
CMCRank cmcRank = extractCMCRank(row);
if (cmcRank != null) {
System.out.println(gson.toJson(cmcRank));
cmcRanks.add(cmcRank);
}
}
// TODO
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
private CMCRank extractCMCRank(WebElement row) {
try {
CMCRank cmcRank = new CMCRank();
List<WebElement> tds = row.findElements(By.tagName("td"));
if (tds.size() > 1) {
WebElement rankElem = tds.get(1).findElement(By.tagName("p"));
// находим ранг монеты
if (rankElem != null && его текст не пустой) {
cmcRank.setRank(Integer.valueOf(rankElem.getText()));
}
// находим логотип монеты
WebElement logoElem = row.findElement(By.cssSelector("img.coin-logo"));
if (logoElem != null) {
cmcRank.setCoinLogo(logoElem.getAttribute("src"));
}
// находим символ монеты
WebElement symbolElem = row.findElement(By.cssSelector("p.coin-item-symbol"));
if (symbolElem != null && его текст не пустой) {
cmcRank.setCoinSymbol(symbolElem.getText());
}
// находим цену монеты
WebElement priceElem = tds.get(3).findElement(By.cssSelector("div span"));
if (priceElem != null) {
cmcRank.setPrice(priceElem.getText());
}
}
return cmcRank;
} catch (NoSuchElementException e) {
System.err.println("Не удалось извлечь информацию о монете: " + e.getMessage());
return null;
}
}
}Main.java
Java
public class Main {
public static void main(String[] args) {
String baseUrl = "http://localhost:8848";
String webdriverPath = "ваш путь к файлу chromedriver";
CmcScraper scraper = new CmcScraper(baseUrl, webdriverPath);
scraper.scrape();
}
}Запуск программы
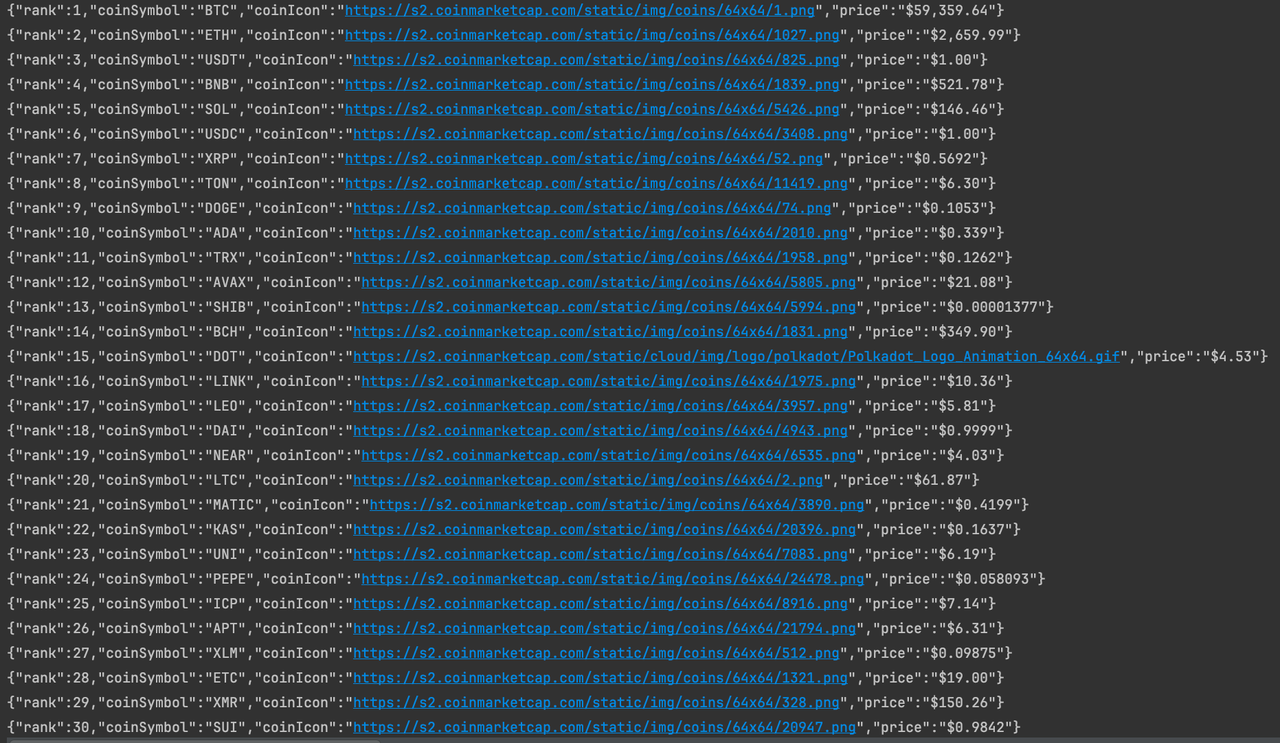
Итак, мы успешно собрали данные о валюте на главной странице CoinmarketCap. Если вас это заинтересовало, вы можете более детально проанализировать страницу для сбора дополнительных данных.
Подведем итоги
Почему Java является отличным языком программирования для веб-сканирования? Как сканировать весь сайт с помощью Java? В чем разница между веб-сканером и веб-скрапингом? Неважно, вы узнали все, что нужно для профессионального веб-сканирования с использованием Java в этом блоге.
Однако самое важное при веб-сканировании — это: ваш веб-сканер должен обходить антибот-системы. Именно поэтому вам нужен браузер с функцией анти-детекта, который может обходить блокировку сайтов.
Nstbrowser предоставляет все необходимое для веб-скрапинга.
Больше





