
Web Scraping
Веб-скрапинг с помощью безголового браузера: Скрапинг динамических веб-сайтов 2024
С ростом зависимости от JavaScript-фреймворков, таких как React, Angular, Vue.js и других, многие веб-сайты перешли к динамическому контенту, загружаемому через Ajax-запросы. Это представляет собой значительное вызов для традиционных веб-скраперов.
Apr 23, 2024
В этом путешествии мы смещаем свое внимание на использование безголовых браузеров для скрапинга динамических веб-сайтов. Безголовой браузер - это браузер без графического интерфейса пользователя, который может имитировать действия пользователя, такие как клики, прокрутка и заполнение форм. Эта функциональность позволяет нам скрапить веб-сайты, требующие взаимодействия пользователя. Каковы доступные инструменты для этой цели и как мы можем эффективно использовать их? По пути мы столкнемся с различными вызовами, а также обнаружим ценные советы и хитрости для их преодоления.
Что такое динамическая веб-страница?
Одним из самых распространенных вопросов по скрапингу веб-сайтов является: "Почему мой скрейпер не видит данные, которые я вижу в своем веб-браузере?
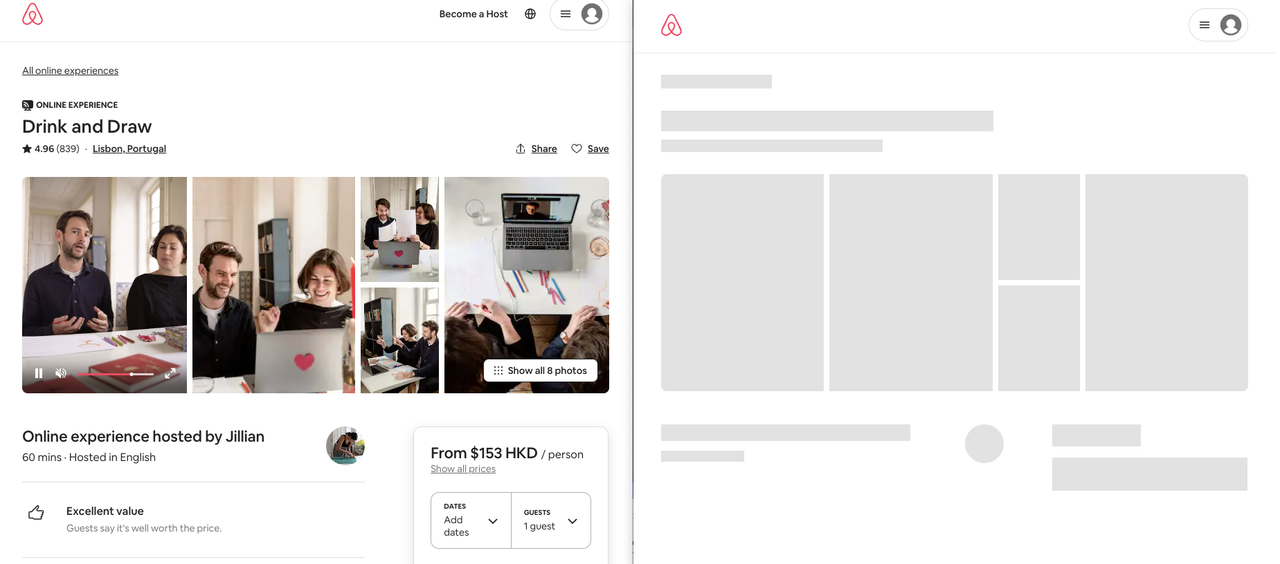
Слева мы видим то, что видим в браузере, а справа - то, что получает наш скрейпер. Итак, куда деваются остальные данные?
Динамические веб-страницы используют сложные технологии на основе JavaScript для перераспределения обработки на сторону клиента. Другими словами, они предоставляют пользователям данные и логику, но требуют их сборки для визуализации полной страницы. Вот почему наш скрейпер видит только пустую страницу.
Вот простой пример:
html
<!DOCTYPE html
<html>
<head>
<title>Пример динамической страницы</title>
</head>
<body>
<div id="content">Загрузка...</div>
<script>
var data = {
name: "John Doe",
age: 30,
city: "Нью-Йорк",
};
document.addEventListener("DOMContentLoaded", function () {
var content = document.getElementById("content");
content.innerHTML = "<h1>" + data.name + "</h1>";
content.innerHTML += "<p>Возраст: " + data.age + "</p>";
content.innerHTML += "<p>Город: " + data.city + "</p>";
});
</script>
</body>
</html>Когда мы открываем страницу и отключаем JavaScript, мы видим "Загрузка...". Но когда JavaScript включен, мы видим "John Doe", "Возраст: 30" и "Город: Нью-Йорк". Это потому, что JavaScript выполняется после загрузки страницы, поэтому наш скрейпер видит только "Загрузка...". Следовательно, скрейпер не видит полностью отрисованную страницу, так как ему не хватает возможности загрузить страницу с помощью JavaScript, как делает веб-браузер.
Как мы можем скрапить динамические веб-сайты?
Мы можем скрапить динамические веб-сайты, интегрируя реальный браузер и управляя им. Существует несколько инструментов, доступных для этой цели, таких как Puppeteer, Selenium и Playwright. Эти инструменты предоставляют API для управления браузером, что позволяет нам имитировать поведение пользователя.
Как работает автоматизированный браузер?
Современные браузеры, такие как Chrome и Firefox, поставляются с встроенными протоколами автоматизации, которые позволяют другим программам управлять ими.
В настоящее время существует два протокола автоматизации для браузеров:
- Новый Протокол Chrome DevTools (CDP): Это протокол автоматизации для Chrome, который позволяет другим программам управлять браузером Chrome.
- Старый протокол WebDriver: Это протокол для управления браузерами, перехватывающий запросы на действия и выполняющий команды управления браузером.
Пример скрапинга
Чтобы проиллюстрировать этот вызов, давайте возьмем реальный пример скрапинга в
еб-страницы. Мы будем скрапить онлайн-сайт, такой как Airbnb experiences. Мы кратко опишем задачу демонстрации и исследуем, как полностью отрисовать страницу с опытом, например, https://www.airbnb.com/experiences/1653933, и получить полностью отрисованный контент для дальнейшей обработки.
Airbnb является одним из динамически генерируемых сайтов, построенных с использованием React по всему миру. Это означает, что наш краулер не сможет видеть полностью отрисованную страницу. Без безголового браузера нам пришлось бы проводить обратную разработку кода сайта для скрапинга его полного HTML-содержимого. Однако с появлением безголовых браузеров мы можем имитировать поведение пользователя для скрапинга динамических веб-сайтов, что делает наш процесс гораздо проще.
- Запустите браузер (например, Chrome или Firefox).
- Перейдите на веб-сайт https://www.airbnb.com/experiences/1653933.
- Дождитесь полной загрузки страницы.
- Получите полный исходный код страницы и разберите содержимое с использованием BeautifulSoup библиотеки для парсинга.
Давайте теперь попробуем использовать четыре различных инструмента автоматизации браузера: Puppeteer, Selenium, Playwright и Nstbrowser.
Puppeteer
Puppeteer - это библиотека Node.js, разработанная командой Google Chrome, которая предоставляет высокоуровневый API для управления Chrome или Chromium через протокол DevTools. Это безголовый браузер, что означает, что у него нет графического пользовательского интерфейса, но он может имитировать поведение пользователя.
По сравнению с Selenium, Puppeteer поддерживает меньше языков и браузеров, но он полностью реализует протокол CDP и получает преимущества от сильной команды Google, стоящей за ним.
Puppeteer также описывает себя как общий клиент автоматизации браузера, а не подходящий для нишевого рынка тестирования веб-приложений - хорошая новость, так как проблемы с веб-скрапингом получают официальную поддержку.
Посмотрим, как наш пример airbnb.com выглядит в Puppeteer и JavaScript:
javascript
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://airbnb.com/experiences/1653933');
await page.waitForSelector("h1");
await page.content();
await browser.close();
})();Selenium
Selenium был одним из первых крупных клиентов автоматизации, созданных для автоматизации тестирования веб-сайтов. Он поддерживает два протокола управления браузером: WebDriver и CDP (только с версии Selenium V4+).
Будучи самым старым инструментом в списке на сегодняшний день, Selenium имеет достаточно большое сообщество и много функций. Он поддерживается практически в каждом языке программирования и может работать практически на любом веб-браузере:
python
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.expected_conditions import visibility_of_element_located
chrome_options = Options()
chrome_options.add_argument("--headless")
browser = webdriver.Chrome(chrome_options) # start a web browser
browser.get("https://www.airbnb.com/experiences/1653933") # navigate to URL
# wait for page to load
# by waiting for <h1> element to appear on the page
title = (
WebDriverWait(driver=browser, timeout=10)
.until(visibility_of_element_located((By.CSS_SELECTOR, "h1")))
.text
)
# retrieve fully rendered HTML content
content = browser.page_source
browser.close()
# we then could parse it with beautifulsoup
from bs4 import BeautifulSoup
soup = BeautifulSoup(content, "html.parser")
print(soup.find("h1").text) # you will see the "Drink and Draw"
Выше мы сначала запускаем окно веб-браузера, затем переходим на страницу опыта Airbnb. Затем мы ждем, пока страница загрузится, ожидая появления первого элемента h1 на странице. Наконец, мы извлекаем HTML-содержимое страницы и парсим его с помощью BeautifulSoup.
Playwright
Playwright - это синхронная и асинхронная библиотека автоматизации веб-браузера, предоставляемая Microsoft на нескольких языках программирования.
Основная цель Playwright - это надежное тестирование
современных веб-приложений от начала до конца, хотя она все еще реализует все общие функции автоматизации браузера (как Puppeteer и Selenium) и имеет растущее сообщество по скрапингу веба.
python
from playwright.sync_api import sync_playwright
with sync_playwright() as pw:
browser = pw.chromium.launch(headless=True)
context = browser.new_context(viewport={"width": 1920, "height": 1080})
page = context.new_page()
page.goto("https://airbnb.com/experiences/1653933") # go to url
page.wait_for_selector('h1')
title = page.inner_text('h1')
print(title) # you will see "Drink and Draw"В приведенном выше коде мы сначала запускаем браузер Chromium, затем переходим на страницу опыта Airbnb. Затем мы ждем, пока страница загрузится, и затем извлекаем HTML-содержимое страницы.
Nstbrowser
Nstbrowser - это мощный браузер с функцией антидетекции, предназначенный для профессионалов, управляющих несколькими учетными записями, обеспечивая безопасное и эффективное управление несколькими учетными записями. Nstbrowser включает в себя ряд передовых технологий, включая браузеры с антидетекцией, множественные учетные записи, виртуальные браузеры, браузерные отпечатки и управление учетными записями, обеспечивая пользователям новый опыт просмотра. Ниже мы воспользуемся его браузером для извлечения содержимого веб-страницы в безголовом режиме.
Предварительные требования
- Вам нужно зарегистрироваться как пользователь Nstbrowser. Зарегистрируйтесь здесь.
- Получите API-ключ. Как получить API-ключ? После входа в систему в Nstbrowser перейдите в меню API и скопируйте свой API-ключ.
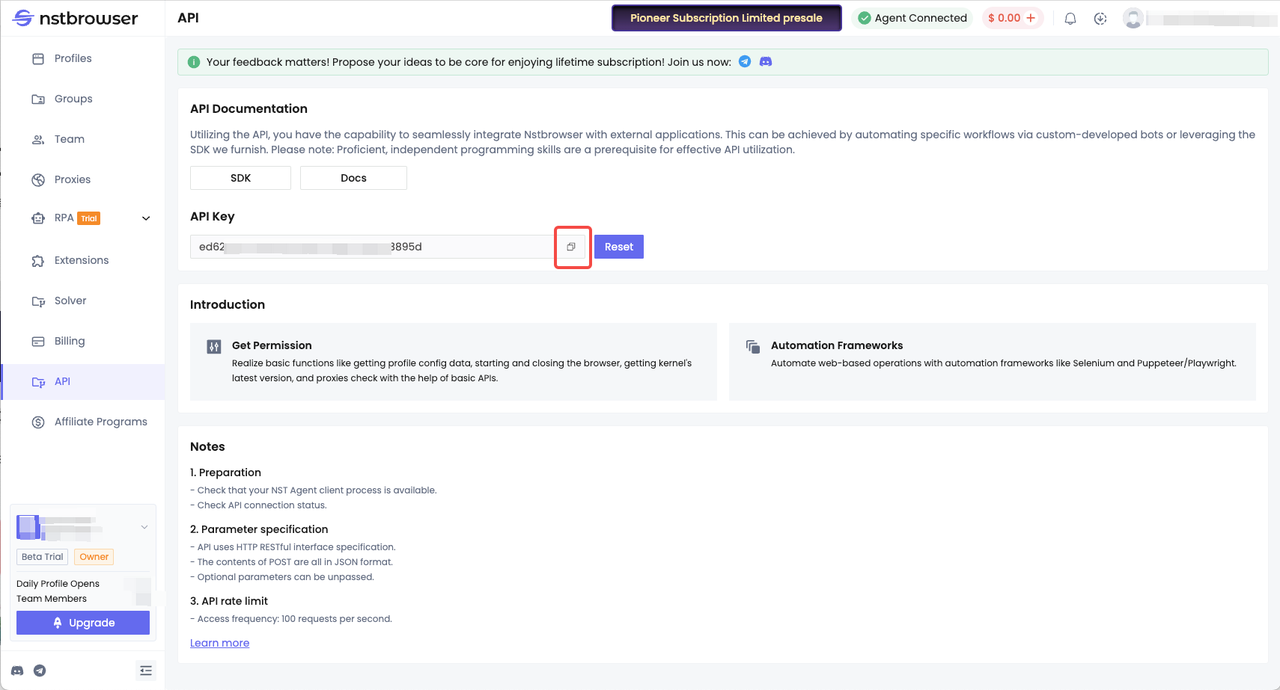
- На основе технологии Playwright, которую мы узнали выше, мы продолжим использовать Nstbrowser для извлечения содержимого веб-страницы.
python
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui
import WebDriverWait
from selenium.webdriver.support.expected_conditions import visibility_of_element_located
from selenium.webdriver.chrome.service import Service as ChromeService
# get_debugger_port: Get the debugger port
def get_debugger_port(url: str):
try:
resp = requests.get(url).json()
if resp['data'] is None:
raise Exception(resp['msg'])
port = resp['data']['port']
return port
except HTTPError:
raise Exception(HTTPError.response)
def exec_selenium(debugger_address: str):
options = webdriver.ChromeOptions()
options.add_experimental_option("debuggerAddress", debugger_address)
# Replace with the corresponding version of WebDriver path.
chrome_driver_path = r'/Users/xxx/Desktop/chrome_web_driver/chromedriver_mac_arm64/chromedriver'
service = ChromeService(chrome_driver_path)
driver = webdriver.Chrome(service=service, options=options)
driver.get("https://www.airbnb.com/experiences/1653933")
# wait for page to load
# by waiting for <h1> element to appear on the page
title = (
WebDriverWait(driver=driver, timeout=10)
.until(visibility_of_element_located((By.CSS_SELECTOR, "h1")))
.text
)
content = driver.page_source
# we then could parse it with beautifulsoup
from bs4 import BeautifulSoup
soup = BeautifulSoup(content, "html.parser")
print(soup.find("h1").text) # you will see the "Drink and Draw"
driver.close()
driver.quit()
def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'Your API Key Here' # got it from https://app.nstbrowser.io/
config = {
'headless': True, # open browser in headless mode
'remoteDebuggingPort': 9222,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
# userAgent supportted since v0.15.0
'fingerprint': { # required
'name': 'custom browser',
'platform': 'mac', # support: windows, mac, linux
'kernel': 'chromium', # only support: chromium
'kernelMilestone': '113', # support: 113, 115, 118, 120
'hardwareConcurrency': 4, # support: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # support: 2, 4, 8
'proxy': '', # input format: schema://user:password@host:port eg: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # required
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
print('devtool url: ' + url)
port = get_debugger_port(url)
debugger_address = f'{host}:{port}'
print("debugger_address: " + debugger_address)
exec_selenium(debugger_address)
create_and_connect_to_browser()После успешного запуска мы увидим следующие результаты в консоли:
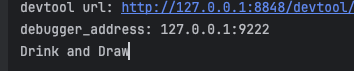
Вы можете увидеть, что мы можем успешно извлечь содержимое страницы, включая заголовок "Drink and Draw".
Заключение
Динамические веб-сайты представляют собой значительный вызов для скраперов, но использование безголовых браузеров позволяет нам преодолеть это ограничение. Мы исследовали различные инструменты, такие как Puppeteer, Selenium, Playwright и Nstbrowser, и рассмотрели, как они могут быть использованы для скрапинга динамических веб-сайтов. Каждый из этих инструментов имеет свои преимущества и ограничения, и выбор конкретного инструмента зависит от ваших конкретных потребностей. Надеюсь, эта статья поможет вам выбрать подходящий инструмент для ваших проектов скрапинга.
Больше





