
Web Scraping
Python Web Crawler - пошаговый самоучитель 2024
Python предоставляет очень мощные возможности для разработки веб-краулеров и является одним из самых популярных языков для краулеров. Прочитайте эту статью, чтобы узнать, как использовать Python для создания веб-краулеров.
Jun 13, 2024Luke Ulyanov
Web crawler - это мощная техника, которая позволяет нам собирать всевозможные данные и информацию, посещая веб-страницы и обнаруживая URL-адреса на сайтах. Python имеет различные библиотеки и фреймворки, поддерживающие веб-краулеры. В этой статье мы узнаем:
- Что такое Python crawler
- Как использовать Python crawler и API Nstbrowser для сбора информации со страниц
- Как бороться с блокировками при использовании Python для сбора данных
- Примеры Python-краулинга
Что такое Python Web Crawler?
Python предлагает очень мощные возможности для разработки веб-краулеров и является одним из самых популярных языков для этого. Python web crawler - это автоматизированная программа для просмотра веб-сайта или Интернета с целью сбора веб-страниц. Это скрипт Python, который исследует страницы, обнаруживает ссылки и следует по ним, чтобы увеличить количество данных, которые можно извлечь из соответствующих веб-сайтов.
Поисковые системы полагаются на роботов для сбора информации и поддержания индексов своих страниц, в то время как инструменты веб-краулинга используют их для доступа и поиска всех страниц для применения логики извлечения данных.
Веб-краулеры на Python в основном реализуются с помощью ряда сторонних библиотек. Распространенные библиотеки Python web crawler включают:
-
urllib/urllib2/requests: Эти библиотеки обеспечивают базовую функциональность веб-краулинга, позволяя отправлять HTTP-запросы и получать ответы.
-
BeautifulSoup: Это библиотека для разбора HTML- и XML-документов, она может помочь краулеру извлекать полезную информацию на веб-странице.
-
Scrapy: Это мощный фреймворк для веб-краулинга, который обеспечивает извлечение данных, обработку конвейера, распределенный краулинг и другие расширенные функции.
-
Selenium: Это инструмент для автоматизации веб-браузера, который может имитировать ручную работу в браузере. Этот краулер всегда используется для сбора данных с динамических страниц с JavaScript-контентом.
Всегда заблокированы при скрейпинге?
Разблокировка и решения для анти-обнаружения от Nstbrowser
Попробуйте бесплатно!
Есть ли у вас хорошие идеи или вопросы о веб-скрейпинге и Browserless?
Посмотрите чем делятся другие разработчики в Discord и Telegram!
Вот перевод на русский язык:
4 популярных варианта использования веб-краулера:
-
Поисковые системы (например, Googlebot, Bingbot, Yandex Bot...) собирают всю HTML-разметку важных частей веба, данные индексируются для последующего поиска.
-
Инструменты для SEO-анализа собирают метаданные в дополнение к HTML, такие как время отклика и состояние ответа, чтобы обнаруживать неработающие страницы и связи между разными доменами для сбора обратных ссылок.
-
Инструменты для мониторинга цен обходят сайты электронной коммерции, чтобы находить страницы товаров и извлекать метаданные, особенно цены. Страницы товаров затем периодически повторно просматриваются.
-
Common Crawl поддерживает открытое хранилище данных веб-обхода. Например, архив за май 2022 года содержит 3,45 миллиарда веб-страниц.
Итак, как использовать инструмент автоматизации Python Pyppeteer для веб-обхода?
Продолжайте читать!
Как собирать данные из веба с помощью Pyppeteer и API Nstbrowser?
Шаг 1. Предварительные условия
Перед началом обхода необходимо выполнить некоторые подготовительные действия:
Shell
pip install pyppeteer requests jsonПосле установки необходимых библиотек создайте новый файл scraping.py и импортируйте установленные библиотеки, а также некоторые системные библиотеки:
python
import asyncio
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from pyppeteer import launcherПрежде чем использовать pyppeteer, нам необходимо подключиться к Nstbrowser, который предоставляет API для возврата webSocketDebuggerUrl для pyppeteer.
Python
# get_debugger_url: Получить URL отладчика
def get_debugger_url(url: str):
try:
resp = requests.get(url).json()
if resp['data'] is None:
raise Exception(resp['msg'])
webSocketDebuggerUrl = resp['data']['webSocketDebuggerUrl']
return webSocketDebuggerUrl
except HTTPError:
raise Exception(HTTPError.response)
async def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'ваш API-ключ'
config = {
'once': True,
'headless': False,
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # обязательно
'name': 'custom browser',
'platform': 'windows', # поддерживается: windows, mac, linux
'kernel': 'chromium', # поддерживается только: chromium
'kernelMilestone': '120', # поддерживается: 113, 115, 118, 120
'hardwareConcurrency': 4, # поддерживается: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # поддерживается: 2, 4, 8
'proxy': '', # формат ввода: schema://user:password@host:port, например: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # обязательно
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
browser_ws_endpoint = get_debugger_url(url)
print("browser_ws_endpoint: " + browser_ws_endpoint) # pyppeteer подключается к Nstbrowser через browser_ws_endpoint
(
asyncio
.get_event_loop()
.run_until_complete(create_and_connect_to_browser())
)После успешного получения webSocketDebuggerUrl Nstbrowser подключите pyppeteer к Nstbrowser:
Python
async def exec_pyppeteer(wsEndpoint: str):
browser = await launcher.connect(browserWSEndpoint = wsEndpoint)
page = await browser.newPage()Запустив написанный нами код в терминале: python scraping.py, вы увидите, что мы успешно открыли Nstbrowser и создали новую вкладку в Nstbrowser.
Все готово, и теперь мы можем официально начать обход!
Вот перевод текста на русский язык:
Шаг 2. Посетите целевой веб-сайт
https://www.imdb.com/chart/top
Python
await page.goto('https://www.imdb.com/chart/top')Шаг 3. Выполните код
Выполните наш код еще раз, и вы увидите, что мы получили доступ к нашему целевому веб-сайту через Nstbrowser. Откройте Devtool, чтобы увидеть конкретную информацию, которую мы хотим собрать, и вы увидите, что это элементы с той же структурой DOM.
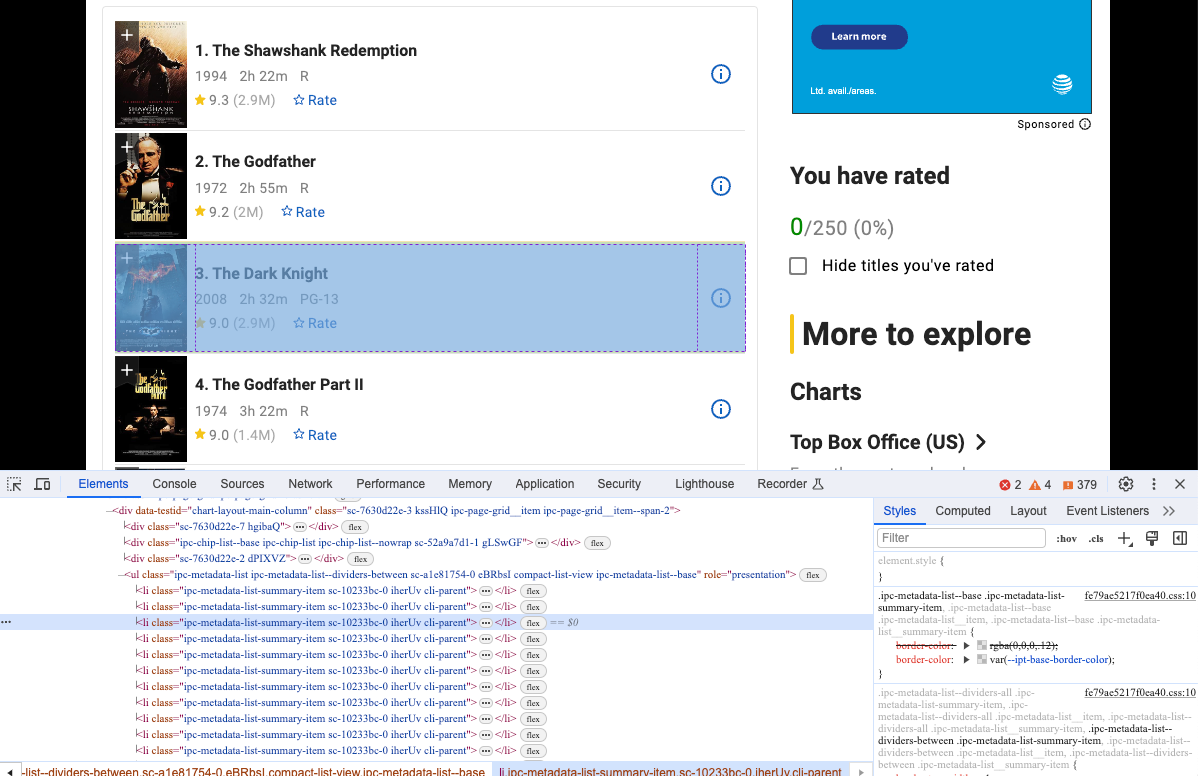
Шаг 4. Собрать веб-страницу
Мы можем использовать Pyppeteer, чтобы собрать эти структуры DOM и проанализировать их содержимое:
Python
movies = await page.JJ('li.cli-parent')
for row in movies:
title = await row.J('.ipc-title-link-wrapper')
year = await row.J('span.cli-title-metadata-item')
rate = await row.J('.ipc-rating-star')
title_text = await page.evaluate('item => item.textContent', title)
year_text = await page.evaluate('item => item.textContent', year)
rate_text = await page.evaluate('item => item.textContent', rate)
pringt('titile: ', title_text)
pringt('year: ', title_text)
pringt('rate: ', title_text)Конечно, просто выводить данные в терминал явно не является нашей конечной целью, то, что мы хотим сделать, - это сохранить данные.
Шаг 5. Сохраните данные
Мы используем библиотеку json для сохранения данных в локальный файл json:
Python
movies = await page.JJ('li.cli-parent')
movies_info = []
for row in movies:
title = await row.J('.ipc-title-link-wrapper')
year = await row.J('span.cli-title-metadata-item')
rate = await row.J('.ipc-rating-star')
title_text = await page.evaluate('item => item.textContent', title)
year_text = await page.evaluate('item => item.textContent', year)
rate_text = await page.evaluate('item => item.textContent', rate)
move_item = {
"title": title_text,
"year": year_text,
"rate": rate_text
}
movies_info.append(move_item)
# create the json file
json_file = open("movies.json", "w")
# convert movies_info to JSON
json.dump(movies_info, json_file)
# release the file resources
json_file.close()Запустите наш код, а затем откройте папку, в которой находится код. Вы увидите новый файл movies.json. Откройте его, чтобы проверить содержимое. Если вы найдете, что это выглядит так:
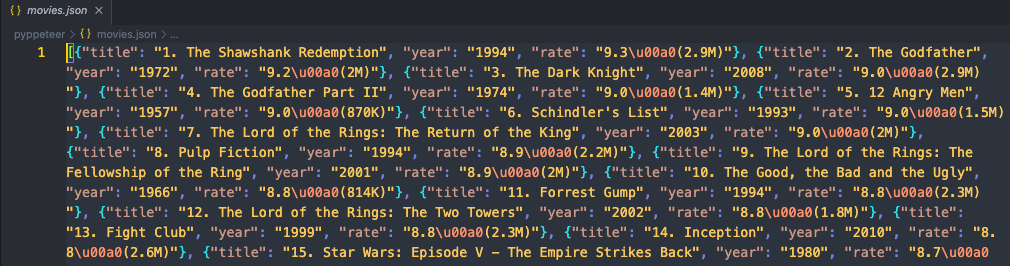
Это означает, что мы успешно собрали целевой веб-сайт с использованием Pyppeteer и Nstbrowser!
Вот как я могу перевести этот текст на русский язык:
4 совета, чтобы исправить заблокированный Python-краулер
Самая большая проблема при использовании Python-веб-краулера - это блокировка. Многие веб-сайты защищают свой доступ с помощью мер противодействия ботам, которые распознают и останавливают автоматизированные приложения, предотвращая их доступ к странице.
Избегайте блокировки веб-сайтов и блокировки IP с помощью Nstbrowser.
Попробуйте бесплатно!
Вот некоторые рекомендации, чтобы преодолеть противодействие краулингу:
- Ротация
User-Agent: Постоянное изменение заголовка User-Agent в запросах может помочь имитировать разные веб-браузеры и избежать обнаружения как бота.
Информацию о UA можно изменить, изменив config при запуске Nstbrowser:
Python
config = {
'once': True,
'headless': False,
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # required
'name': 'custom browser2',
'platform': 'mac', # support: windows, mac, linux
'kernel': 'chromium', # only support: chromium
'kernelMilestone': '120', # support: 113, 115, 118, 120
'hardwareConcurrency': 8, # support: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 2, # support: 2, 4, 8
}
}-
Запускайте во внепиковые часы: Запуск краулера во внепиковые часы и добавление задержек между запросами помогает предотвратить перегрузку веб-сервера и срабатывание механизма блокировки.
-
Соблюдайте
robots.txt: Соблюдение директивыrobots.txtна веб-сайте демонстрирует этичное поведение при краулинге. Кроме того, это помогает избежать доступа к ограниченным областям и делает запросы от скриптов подозрительными. -
Избегайте ловушек для ботов: Не все ссылки созданы равными, и некоторые из них скрывают ловушки для ботов. Следуя им, вы будете помечены как бот.
Однако эти советы полезны только для простых сценариев, но недостаточны для более сложных. Ознакомьтесь с нашей более полной статьей о веб-скрапинге.
Обойти все средства защиты не так-то просто и требует больших усилий. Кроме того, решение, которое работает сегодня, может не работать завтра. Но подождите, есть лучшие решения!
Nstbrowser помогает предотвратить распознавание и блокировку активности краулинга через эмуляцию браузера, ротацию User-Agent и многое другое. Зарегистрируйтесь для бесплатной пробной версии сегодня!
3 популярных Python-веб-краулера
Существует несколько полезных инструментов для веб-краулинга, которые могут упростить процесс обнаружения ссылок и посещения страниц. Вот список лучших Python-веб-краулеров, которые могут вам помочь:
-
Nstbrowser: предоставляет настоящие отпечатки браузера. Объединяет передовые методы разблокировки веб-сайтов и обхода ботов, а также может интеллектуально поворачивать IP-адреса, чтобы значительно снизить вероятность обнаружения.
-
Scrapy: Один из самых мощных вариантов библиотеки Python-краулинга для начинающих. Он предоставляет расширенную основу для построения масштабируемых и эффективных краулеров.
-
Selenium: популярная библиотека безголовых браузеров для веб-краулинга и скрапинга. В отличие от BeautifulSoup, он может взаимодействовать с веб-страницами в браузере, как пользователь-человек.
Основные выводы
Из этой статьи вы должны полностью понимать основы веб-краулинга. Важно отметить, что независимо от того, насколько умен ваш краулер, меры противодействия ботам могут обнаружить и заблокировать его.
Однако вы можете избавиться от любых проблем, используя Nstbrowser, универсальный антидетектный браузер с функциями автоматизации, отпечатка браузера, решения капчи, ротации UA и многими другими необходимыми функциями, чтобы избежать блокировки.
Краулинг никогда не был таким простым! Начните использовать Nstbrowser прямо сейчас, чтобы стать мастером веб-краулинга!
Больше





