Веб-скраппинг с помощью Java в 2024 году - самое подробное руководство
Это руководство посвящено веб-скрапингу с помощью Java в 2024 году. В нем представлено подробное пошаговое руководство. Начните изучать прямо сейчас!
May 09, 2024Luke Ulyanov
Базовый самоучитель по веб-скрапингу
Это руководство посвящено веб-скраппингу с помощью Java в 2024 году. В нем дается пошаговое руководство по извлечению данных с веб-сайтов на примере сайта ScrapeMe. Используя Java и библиотеку jsoup, вы научитесь скрести статические ресурсы веб-страниц и извлекать специфическую информацию, такую как названия товаров, изображения, цены и подробности.
Это руководство даст вам необходимые навыки для сбора данных с аналогичных веб-сайтов и послужит основой для более продвинутых методов веб-скрепинга.
Будьте готовы использовать возможности Java для веб-скрепинга в современную эпоху!
Требования к окружению:
Важно отметить, что поскольку в этой статье мы будем использовать Java для демонстрационного проекта, перед началом работы убедитесь, что у вас есть следующие предварительные условия:
Рекомендуемая среда:
Java: Любая версия 8+ LTS
Инструменты сборки: Любая версия Gradle или Maven, совместимая с вашей локальной версией Java.
IDE: Любая из предпочитаемых вами, например Eclipse, IntelliJ IDEA, VS Code.
Примечание: Процесс установки среды опускается.
Пример окружения:
JDK 21
javascriptCopy
# java -version
java version "21.0.2" 2024-01-16 LTS
Java(TM) SE Runtime Environment (build 21.0.2+13-LTS-58)
Java HotSpot(TM) 64-Bit Server VM (build 21.0.2+13-LTS-58, mixed mode, sharing)
Инструмент для сборки: Gradle
javascriptCopy
# gradle -version
Gradle 8.7
Build time: 2024-03-22 15:52:46 UTC
Revision: 650af14d7653aa949fce5e886e685efc9cf97c10
Kotlin: 1.9.22
Groovy: 3.0.17
Ant: Apache Ant(TM) version 1.10.13 compiled on January 4 2023
JVM: 21.0.2 (Oracle Corporation 21.0.2+13-LTS-58)
OS: Mac OS X 14.4.1 aarch64
IDE: IntelliJ IDEA
Создание проекта:
Информация о проекте
После создания ваш проект может выглядеть следующим образом:
Добавлены зависимости, и на данный момент достаточно jsoup (jsoup: Java HTML Parser):
Теперь самое время поскрести сайт! Здесь я пройдусь по ScrapeMe, просто для примера. Вы можете просмотреть весь прогресс, а затем завершить свой проект.
Анализ целевого сайта:
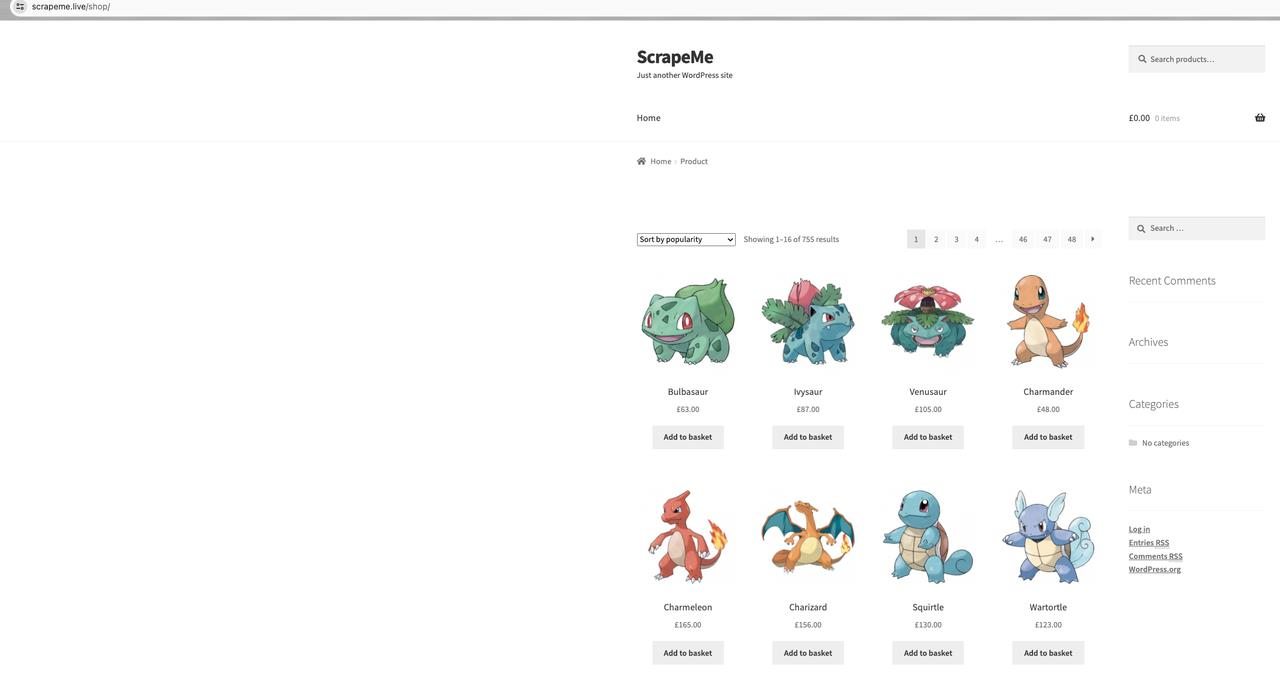
Сначала давайте посмотрим на данные, которые мы хотим соскрести с сайта Scrapeme. Откройте сайт в браузере и просмотрите исходный код, чтобы проанализировать целевые элементы. Затем извлеките нужные элементы с помощью кода.
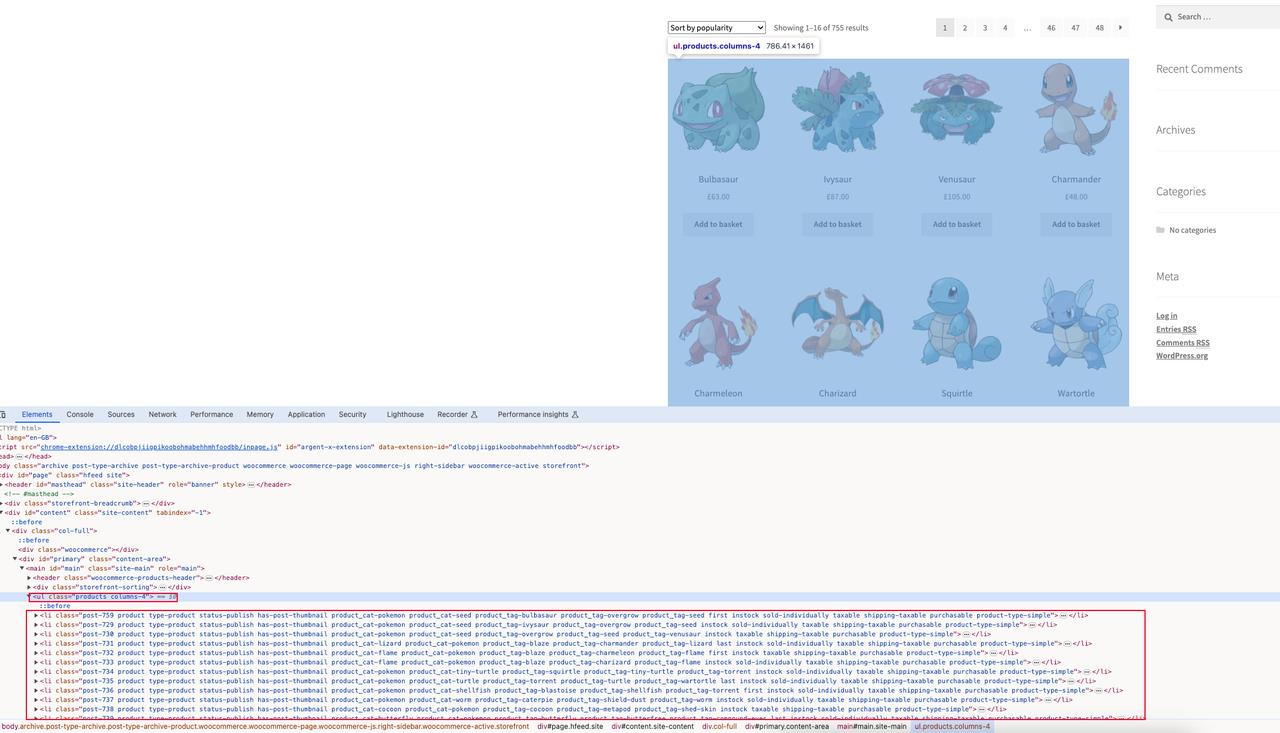
ScrapeMe Homepage Список продуктов:
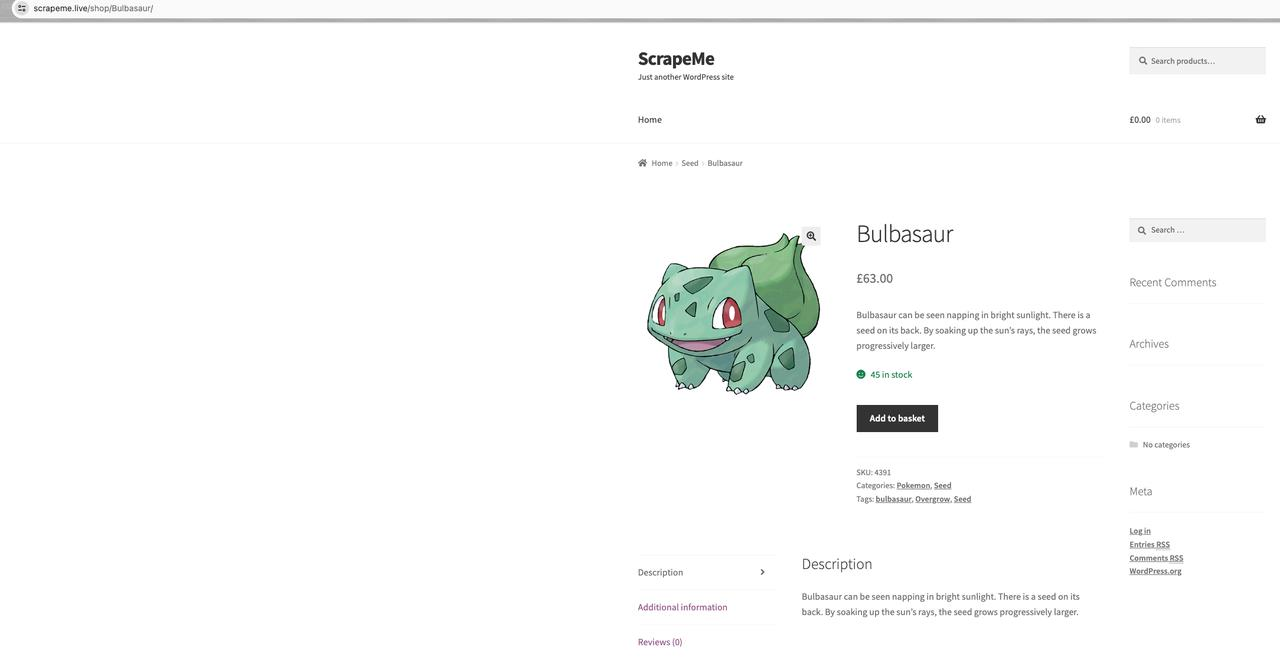
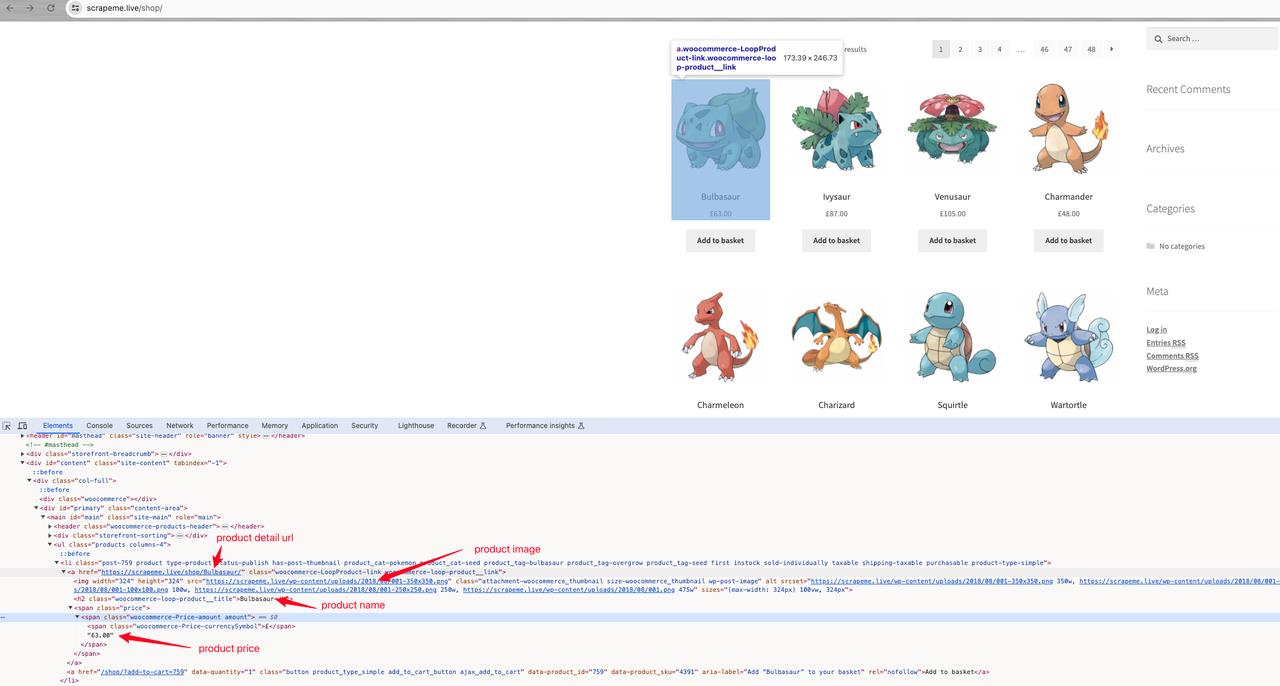
ScrapeMe Подробнее о продукте:
Наша цель - расшарить на главной странице информацию об этих продуктах, включая название продукта, изображения продукта, его цену и адрес для подробной информации о продукте.
Анализ исходного кода страницы
Элементы страницы
Анализируя элементы страницы, мы знаем, что на текущей странице есть все элементы страницы товара: ul.products, и каждый элемент детализации товара: li.product.
Детали продукта
Дальнейший анализ показывает, что название продукта: a h2, изображение продукта: a img.src, цена продукта: a span, адрес подробностей продукта: a.href.
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.*;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class Scraper {
// scrapeme site url
private static final String SCRAPEME_SITE_URL = "https://scrapeme.live/shop";
public static List<ScrapeMeProduct> scrape() {
// html doc for scrapeme page
Document doc;
// products data
List<ScrapeMeProduct> pokemonProducts = new ArrayList<>();
try {
doc = Jsoup.connect(SCRAPEME_SITE_URL)
.userAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36") // mock userAgent header
.header("Accept-Language", "*") // mock Accept-Language header
.get();
// select product nodes
Elements products = doc.select("li.product");
for (Element product : products) {
ScrapeMeProduct pokemonProduct = new ScrapeMeProduct();
pokemonProduct.setUrl(product.selectFirst("a").attr("href")); // parse and set product url
pokemonProduct.setImage(product.selectFirst("img").attr("src")); // parse and set product image
pokemonProduct.setName(product.selectFirst("h2").text()); // parse and set product name
pokemonProduct.setPrice(product.selectFirst("span").text()); // parse and set product price
pokemonProducts.add(pokemonProduct);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
return pokemonProducts;
}
}
Main.java
javaCopy
import io.xxx.basic.ScrapeMeProduct;
import io.xxx.basic.Scraper;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<ScrapeMeProduct> products = Scraper.scrape();
products.forEach(System.out::println);
// continue coding
}
}
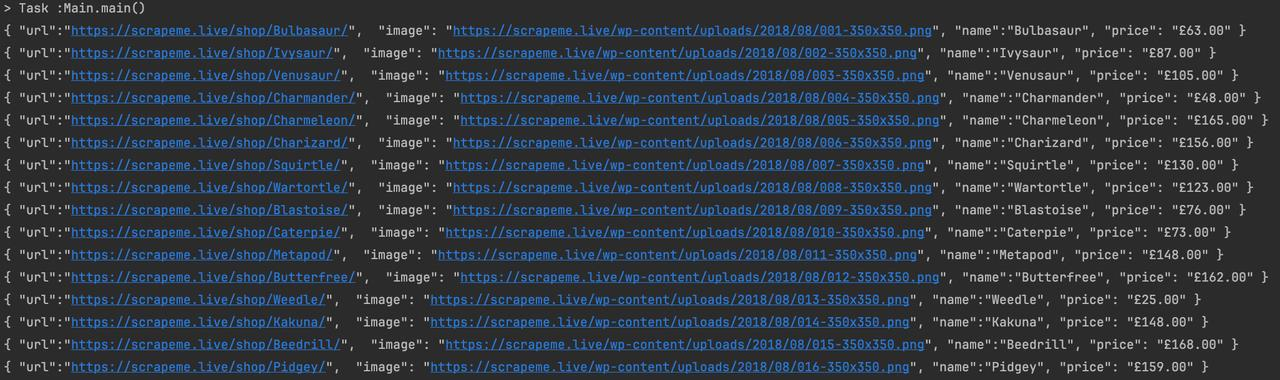
Результаты Экспрессия
Заключение
До сих пор мы научились использовать Java для простого статического ползания по страницам, дальше мы будем продвигаться на этой основе, используя Java для одновременного ползания по ScrapeMe, прежде всего по данным о продуктах, а также использовать Java-код, подключенный к браузеру Nstbrowser для ползания данных, потому что в продвинутой главе будет использоваться Nstbrowser в безголовом браузере и другие возможности.