
Web ScrapingRPA
Как соскрести результаты поиска Google Maps через Nstbrowser RPA?
Как выполнить веб-скраппинг наиболее эффективно? Да, инструменты RPA могут значительно повысить эффективность и сократить расходы. В этом блоге вы узнаете, как скрапировать результаты поиска по картам Google с помощью инструмента Nstbrowser RPA.
May 14, 2024
Использование инструментов RPA для сбора веб-данных является распространенным способом сбора данных, и RPA также может значительно повысить эффективность сбора данных и снизить стоимость сбора. Очевидно, что Nstbrowser RPA обеспечивает лучший опыт RPA и лучшую эффективность работы.
Прочитав это руководство, вы сможете:
- Поймете, как использовать RPA для сбора данных
- Узнаете, как сохранить данные, собранные RPA.
Шаг 1: Подготовка
Вам необходимо:
- иметь учетную запись Nstbrowser и войти в Клиент Nstbrowser.
- перейти на страницу рабочего процесса модуля RPA и нажать кнопку "Создать профиль".
Теперь мы можем приступить к настройке рабочего процесса для ползания RPA по результатам поиска на картах Google.
Шаг 2: Посетите целевой веб-сайт
Прежде чем приступить к поиску целевого содержимого, нам необходимо посетить целевой веб-сайт: https://www.google.com/maps.
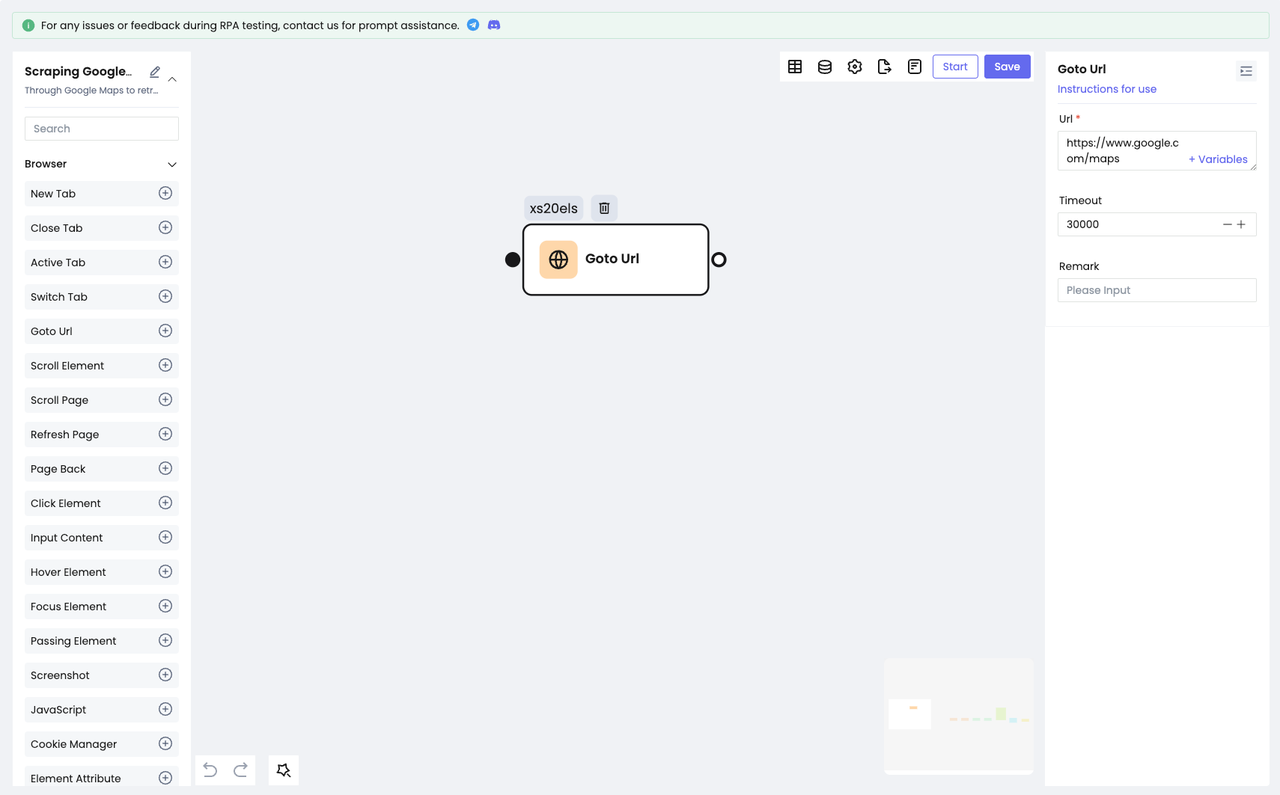
- Выберите узел
Goto Url. - Настройте URL-адрес веб-сайта.
Теперь вы можете посетить целевой сайт.
Шаг 3: Поиск целевого содержимого
После перехода на сайт нам нужно найти целевой адрес. Для этого нужно использовать инструмент Chrome Devtool, чтобы найти HTML-элементы.
Откройте DevTools и с помощью мыши выберите поле поиска. После этого мы сможем увидеть:
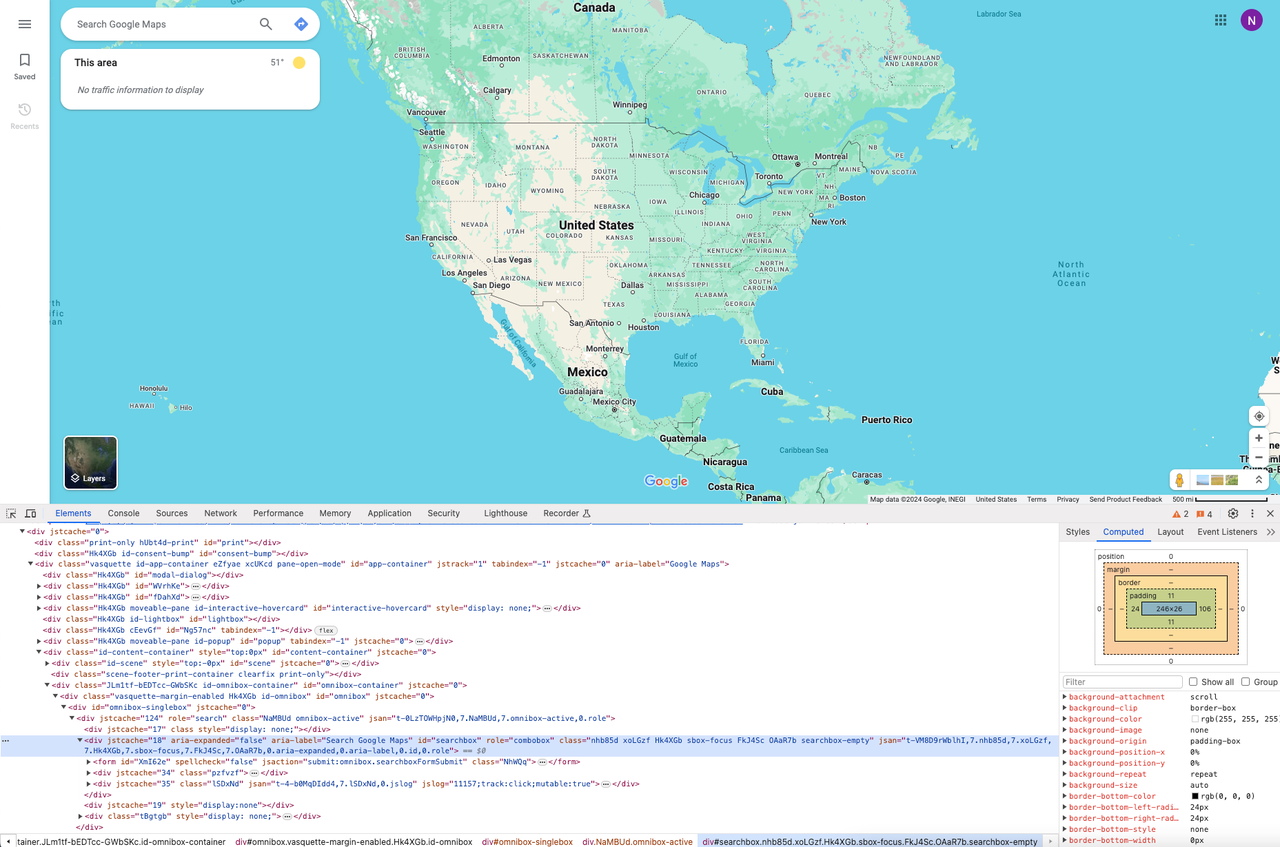
- Наш целевой элемент поля ввода имеет атрибут "
id", который может быть использован в качестве CSS-селектора для определения местоположения поля ввода.
Итак, нам нужно сделать следующее:
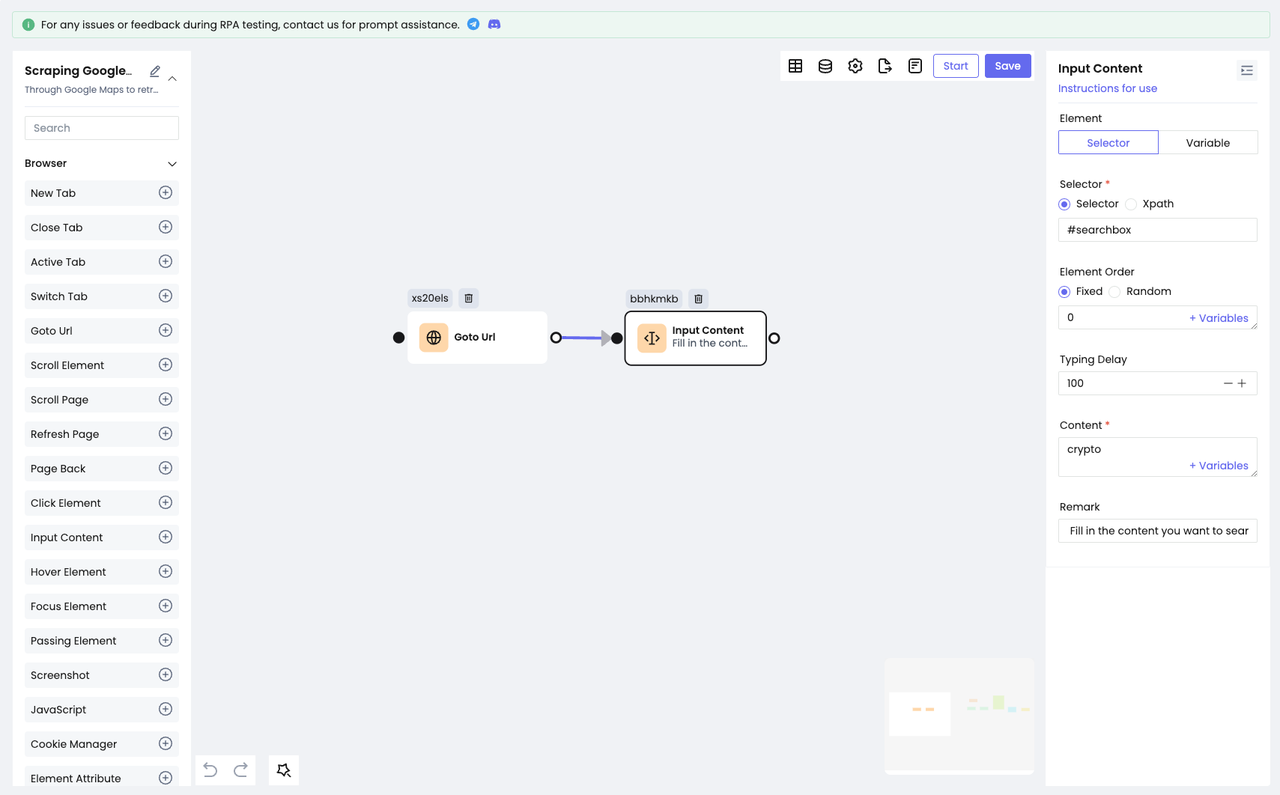
- Добавить узел
Input Content. Выберите "Selector" для параметра Element и Selector для параметра Selector. - Заполните значение идентификатора, который мы поместили в поле ввода, и введите содержимое, которое мы хотим
найти, в опции "Содержание".
Мы завершили действие по вводу текста в поле ввода:
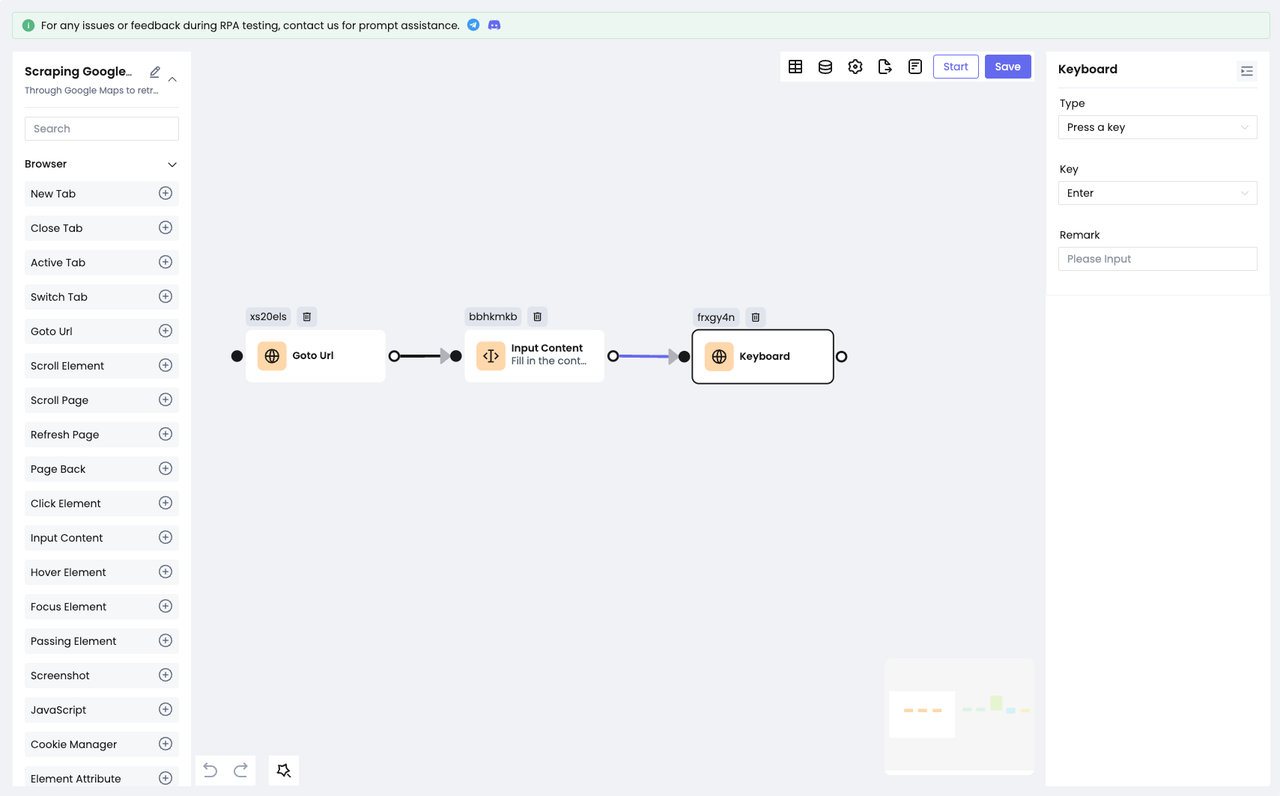
После ввода нам нужно заставить Google Maps искать содержимое, которое мы ввели:
- Это можно сделать быстро, используя узел
Клавиатурадля имитации нажатия клавиши "Enter" на клавиатуре.
Шаг 4: Скраппинг данных
Итак, мы успешно получили нужный нам контент, и следующим шагом будет соскабливание этого контента!
Понаблюдав, мы можем обнаружить, что результаты поиска Google Maps отображаются в виде списка (очень классический способ). Здесь отображается только часть важной информации, и если вы нажмете на один конкретный пункт, то рядом с ним появится вся подробная соответствующая информация.
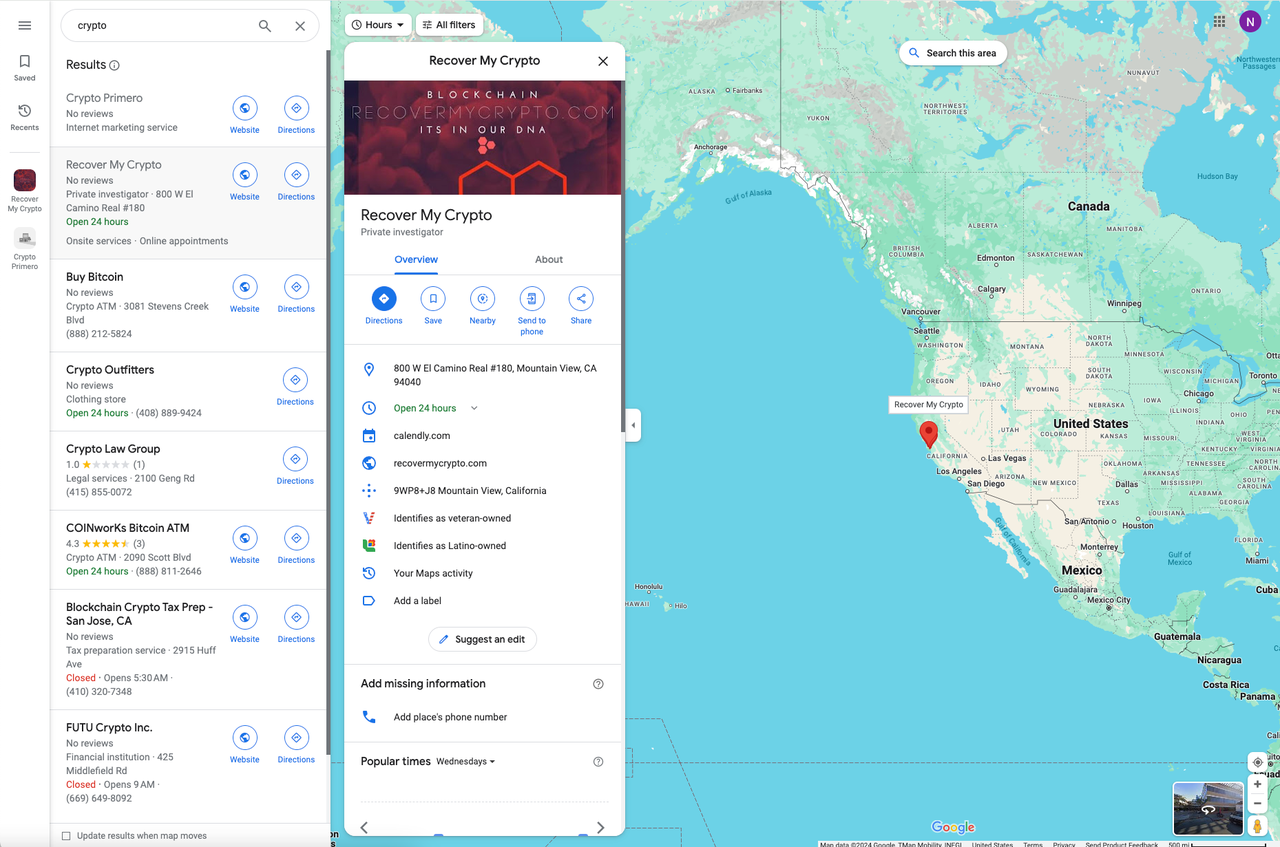
Снова откройте DevTools, чтобы найти каждый результат в списке:
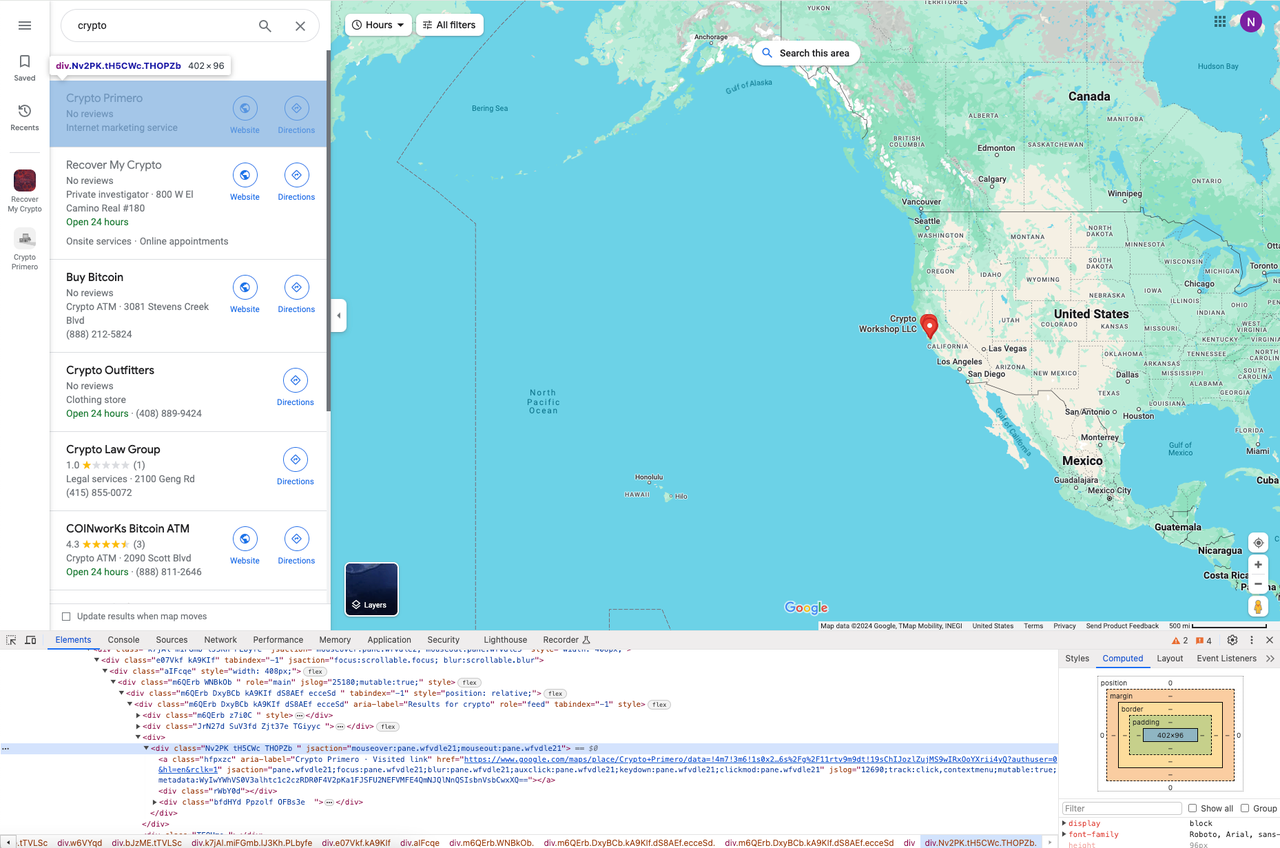
Итерация по всем результатам
Поскольку каждый элемент списка использует HTML-макет, нам нужно использовать узел Loop Element для итерации по всем результатам запроса:
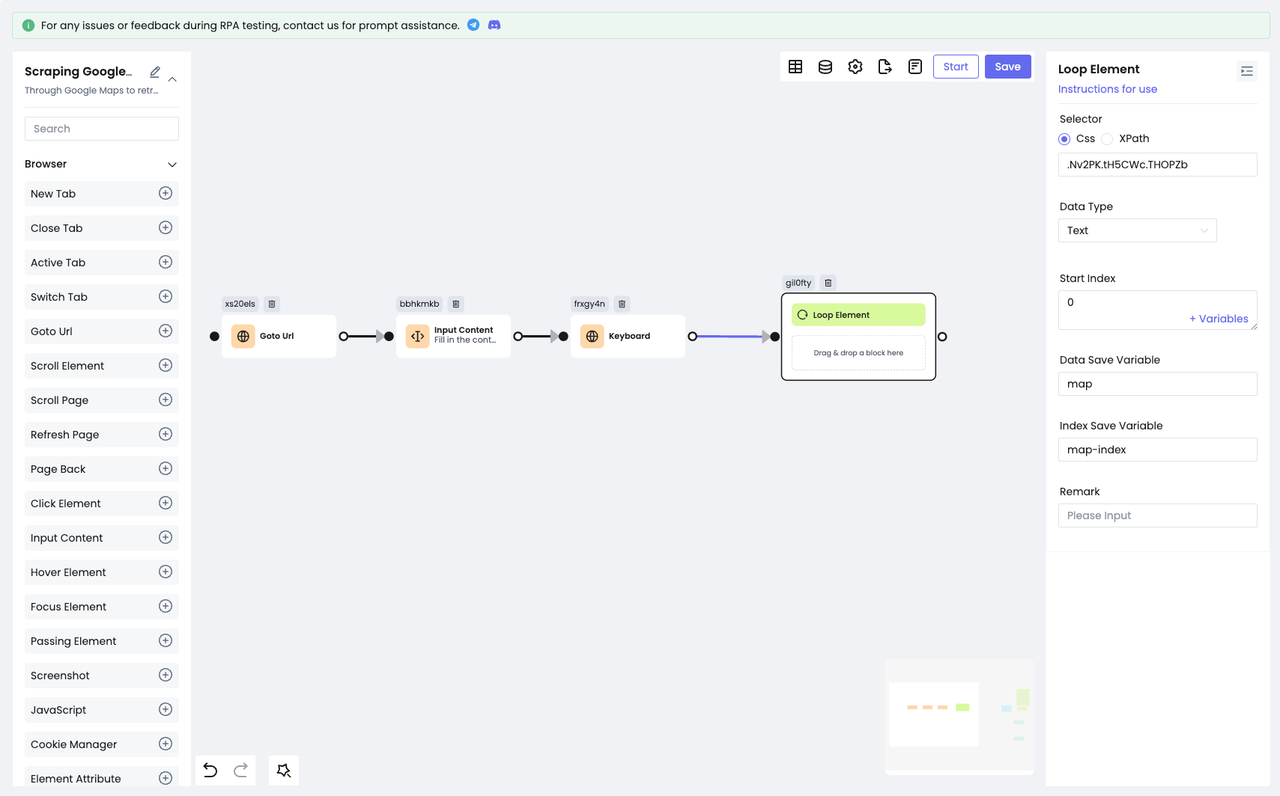
Мы должны сохранить каждый из пройденных элементов в переменной map и индекс каждого элемента в map-index обхода для последующего использования.
Все результаты поиска получаются через веб-запрос, поэтому мы должны добавить действие "ждать" перед обходом, чтобы убедиться, что мы получим последний и правильный элемент. Nstbrowser RPA предоставляет два действия ожидания: Wait Time и Wait Request.
Wait Time: используется для ожидания в течение определенного периода времени. Вы можете выбрать фиксированное или случайное время в зависимости от конкретной ситуации.Wait Request: используется для ожидания окончания сетевого запроса. Применяется в случае получения данных через сетевой запрос.
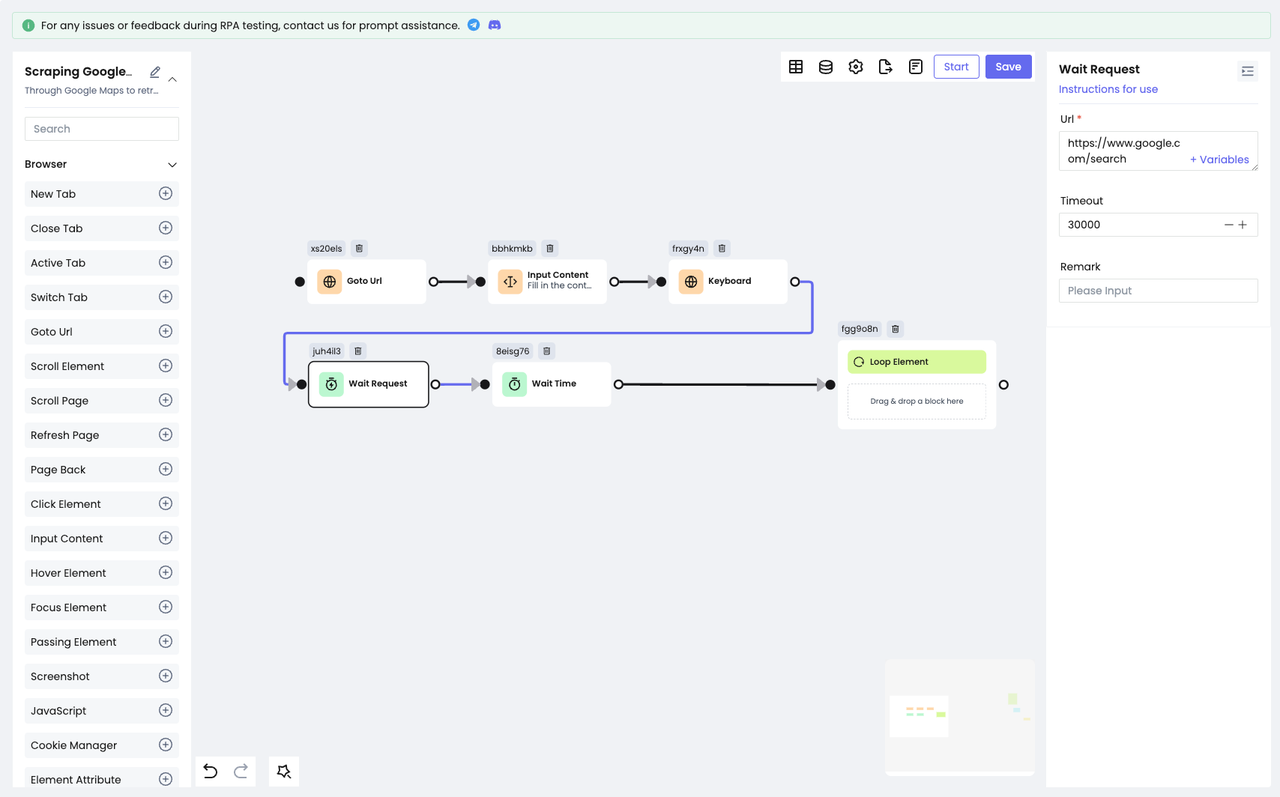
Щелчок по элементу списка
После просмотра результатов для каждого элемента нам нужно собрать данные.
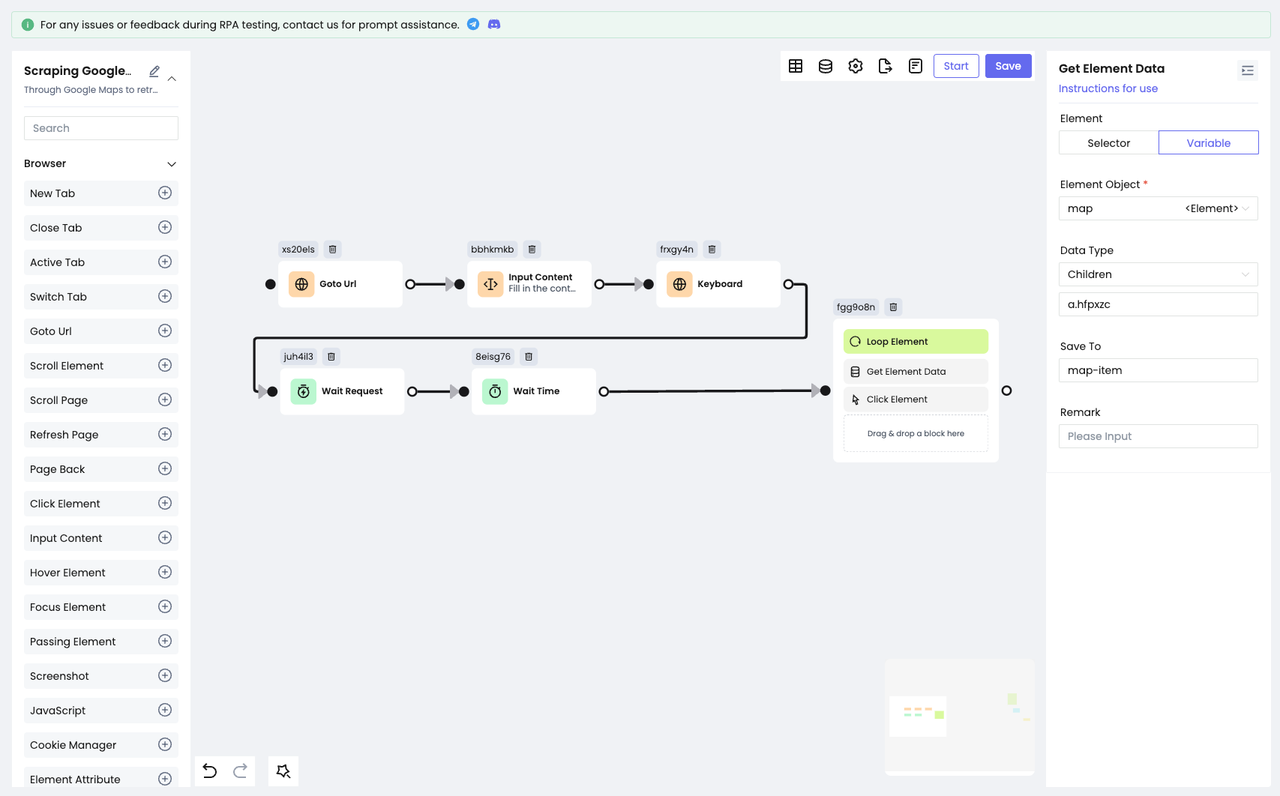
Чтобы получить полную информацию, щелкните на элементе "список". Здесь нам нужно использовать узел Get Element Data, чтобы найти целевой элемент для щелчка на основе элементов, сохраненных в переменной map:
Затем используйте узел Click Element для имитации "щелчка":
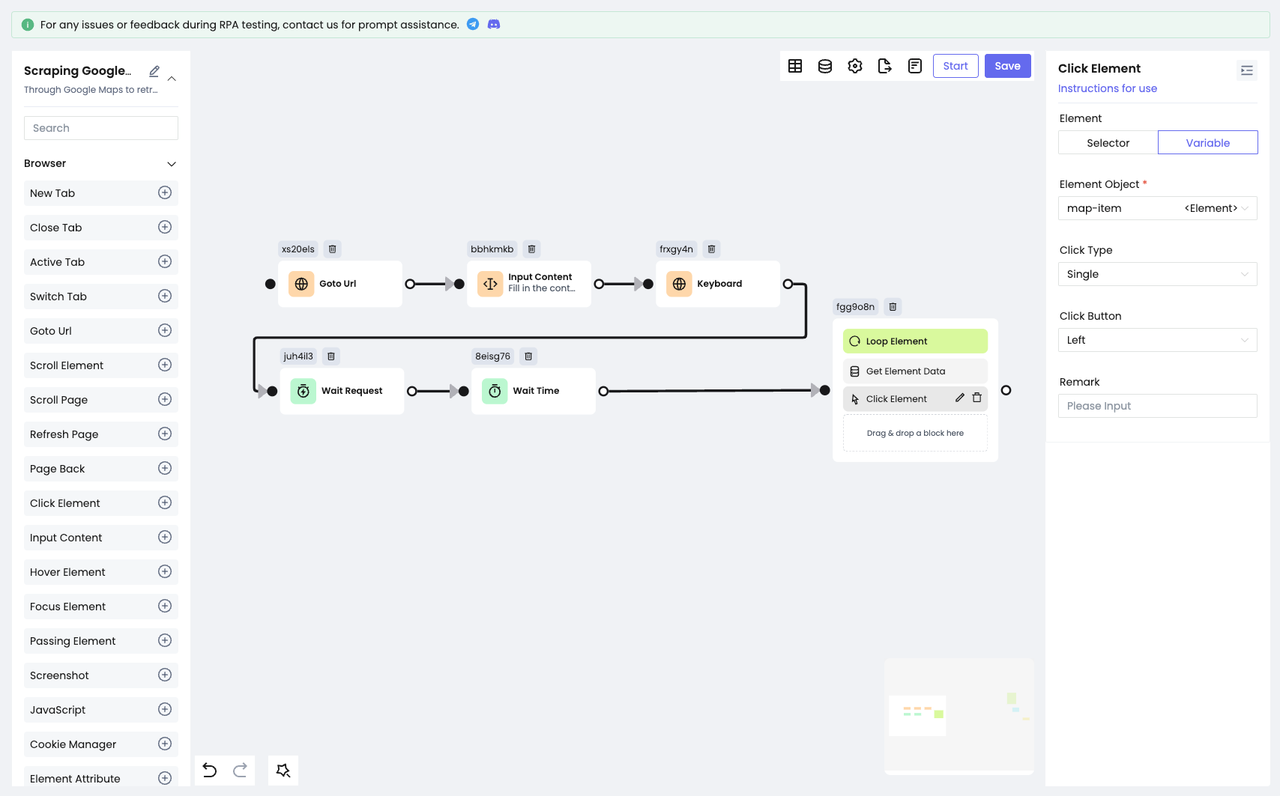
- Перетащите указанные выше узлы внутрь элемента Loop, чтобы эти узлы выполнялись внутри цикла.
Получить данные об элементе
После выполнения описанных выше действий мы уже можем видеть конкретную информацию о каждом результате поиска! Теперь пришло время использовать узел Get Element Data для получения нужных нам данных:
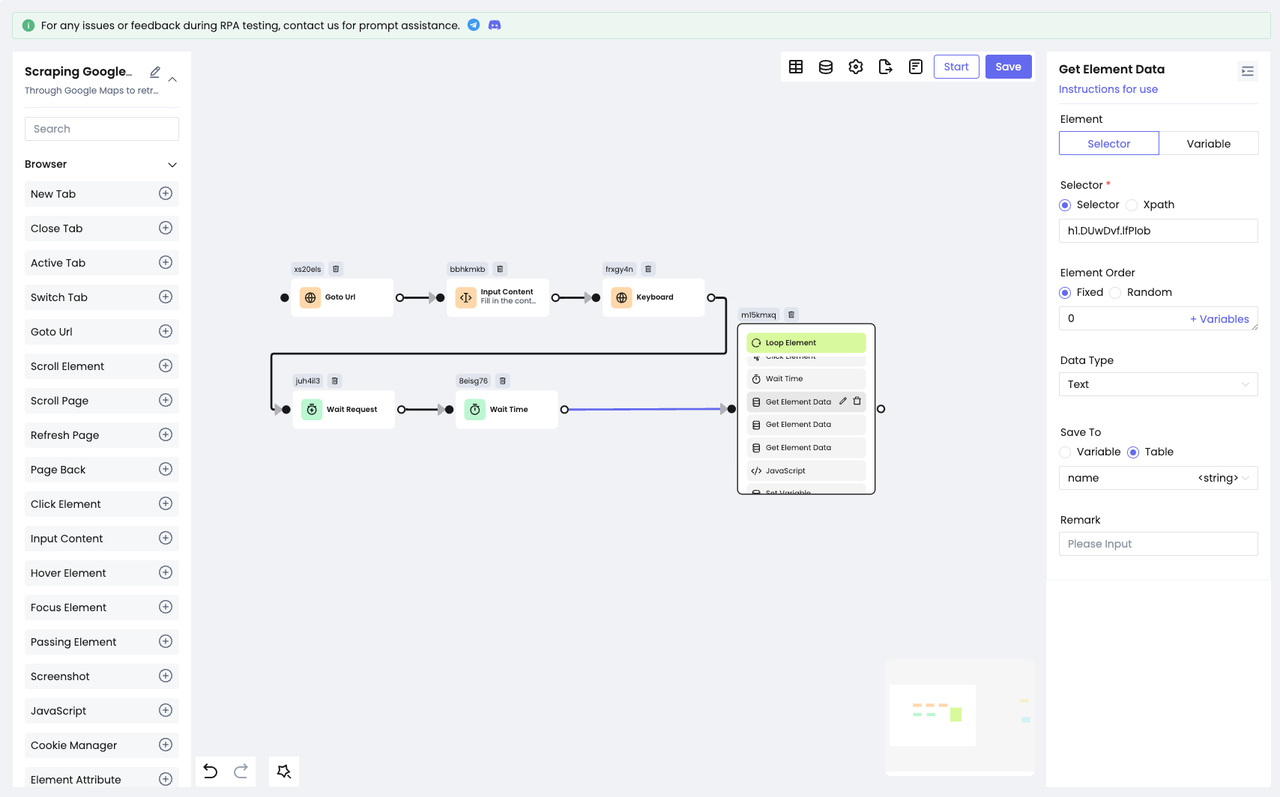
- С помощью DevTools снова позиционируйте наш целевой элемент.
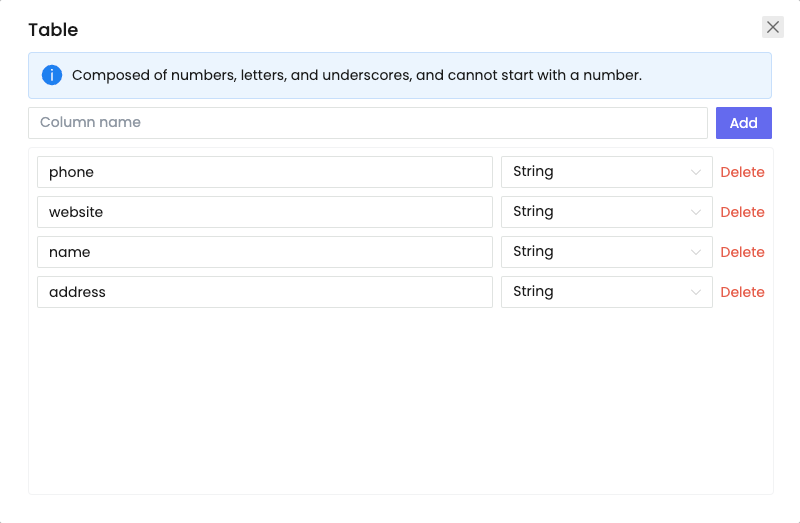
- Примените узел, чтобы получить содержимое элемента и сохранить информацию в нашей предварительно разработанной таблице:
Поздравляем!
На этом мы закончили сбор информации из одного результата поиска!
Шаг 5: Повторный скраппинг
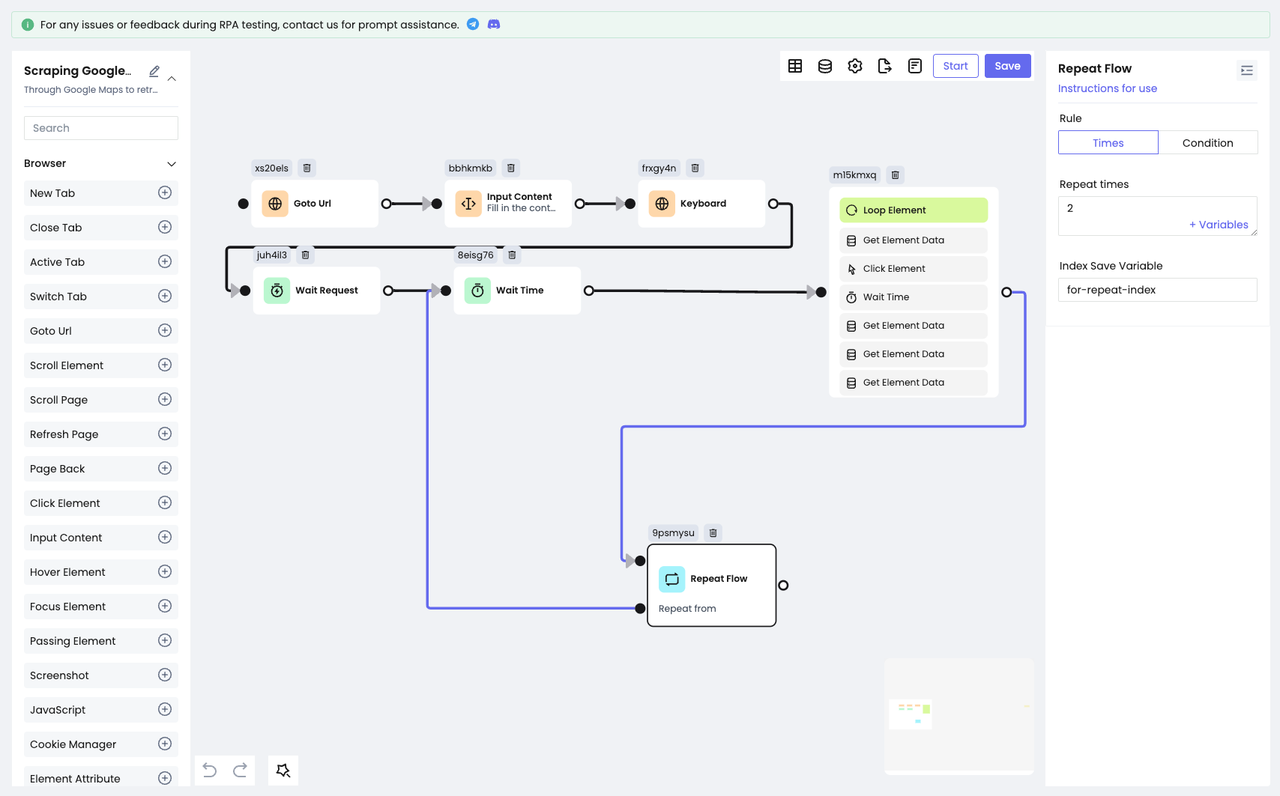
Конечно, одного сбора данных недостаточно, и функциональность RPA в Nstbrowser облегчает эту повторяющуюся работу с помощью всего одного узла!
- Узел
Repeat Flowиспользуется для повторного выполнения уже существующего узла. Все, что вам нужно сделать, - это настроить количество повторений или конечное условие. В результате Nstbrowser сможет автоматически повторять действия в соответствии с вашими потребностями.
Предположим, нам нужно собрать данные еще для 2 запросов, тогда просто настройте количество повторений на 2:
Шаг 6: Сохраните результаты
К этому моменту мы получили все данные, которые хотели собрать, и настало время их сохранить.
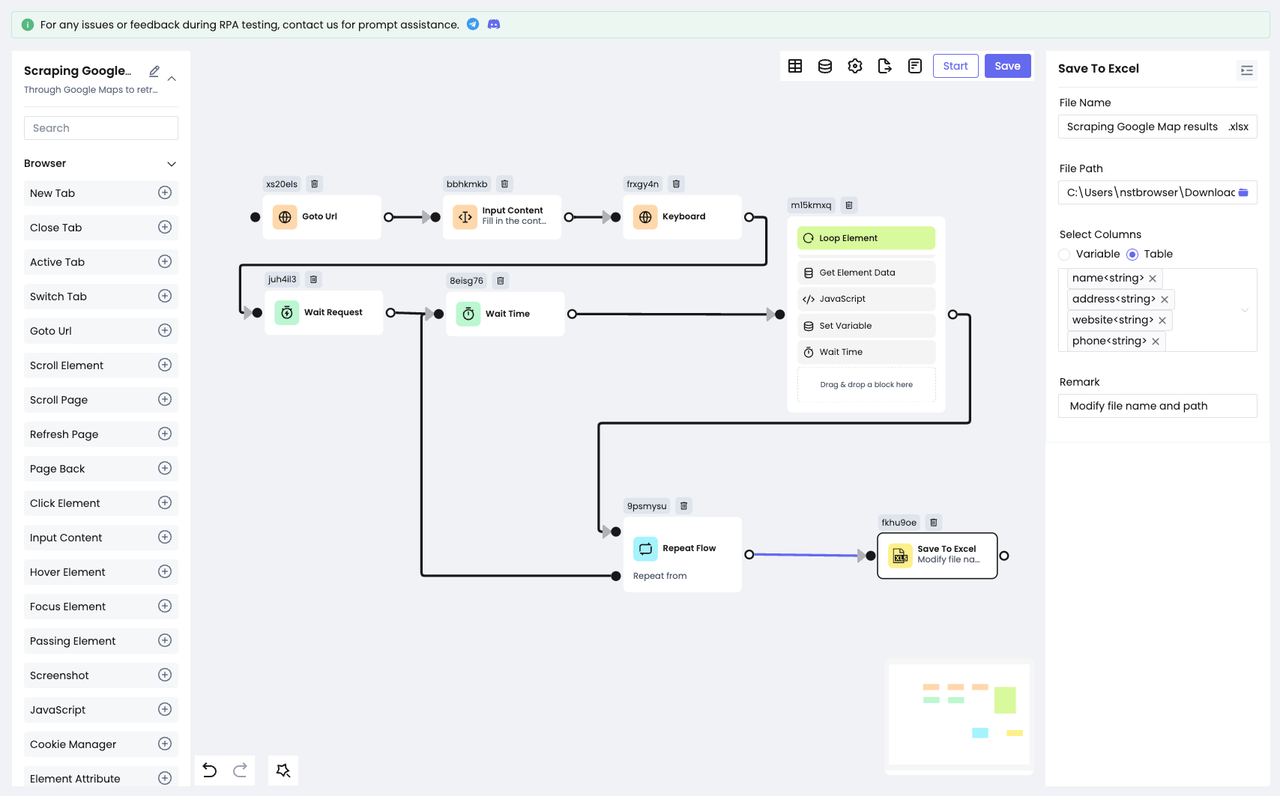
Nstbrowser RPA предоставляет два способа сохранения данных: Сохранить в файл и Сохранить в Excel.
Сохранить в файлпредлагает три типа файлов на выбор: .txt, . csv, .json.- С другой стороны, функция
Сохранить в Excelпозволяет сохранять данные только в файл Excel.
Для удобства просмотра мы решили сохранить Сохранить в Excel:
- Добавьте узел Сохранить в Excel.
- Настройте путь к файлу и имя файла, который нужно сохранить.
- Выберите содержимое таблицы для сохранения.
Шаг 7: Выполнение RPA
Как выполнить его автоматически? Нам нужно:
- Сохранить настроенный рабочий процесс.
- Создать новое расписание.
- Нажать кнопку запуска.
После этого мы можем начать сбор данных с Google Maps!
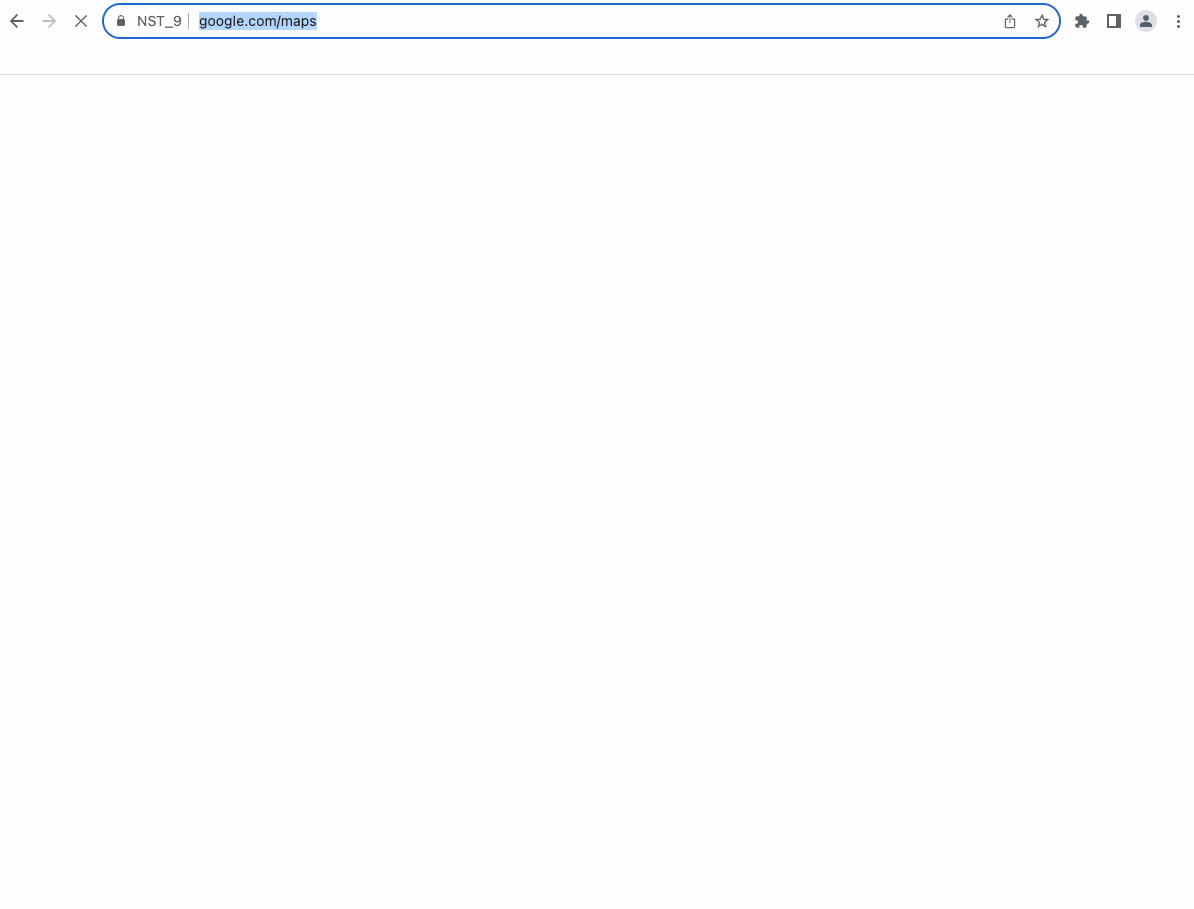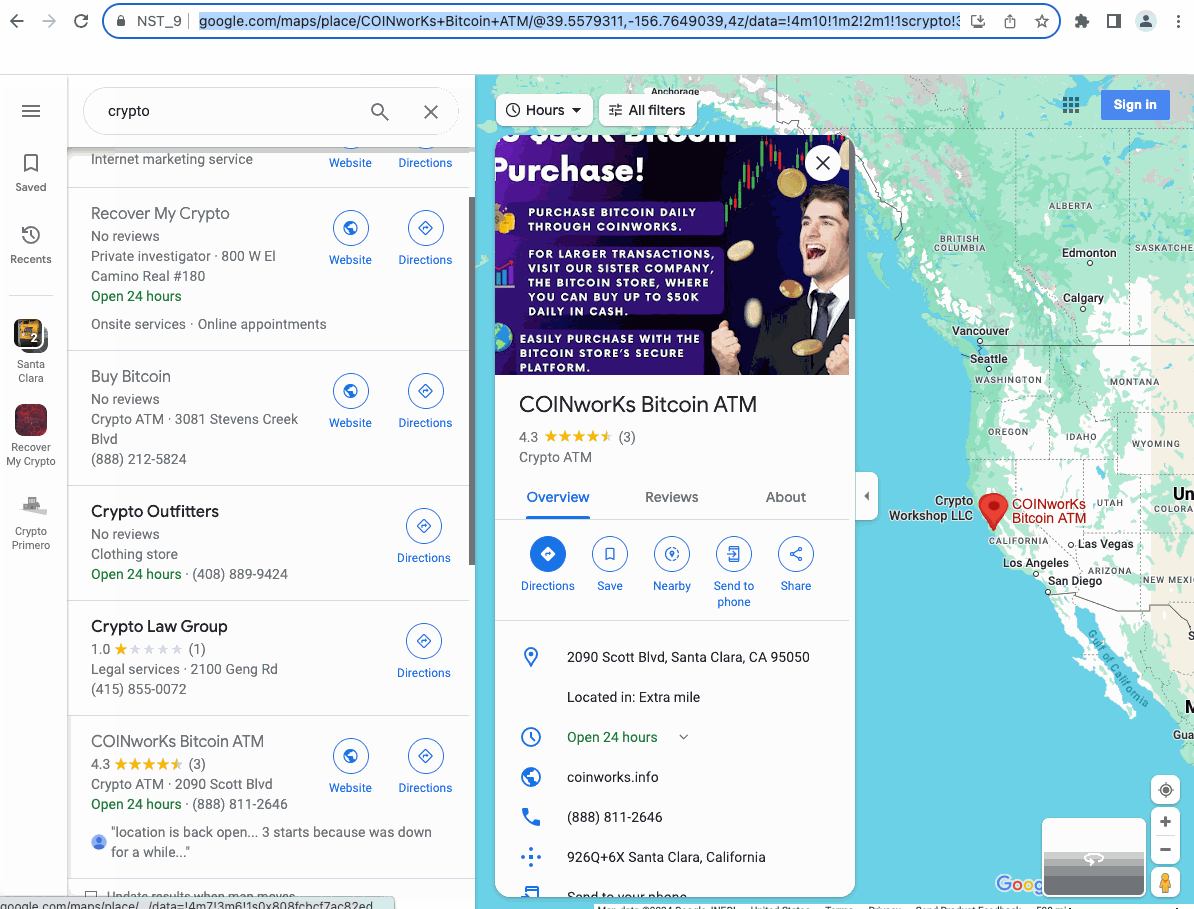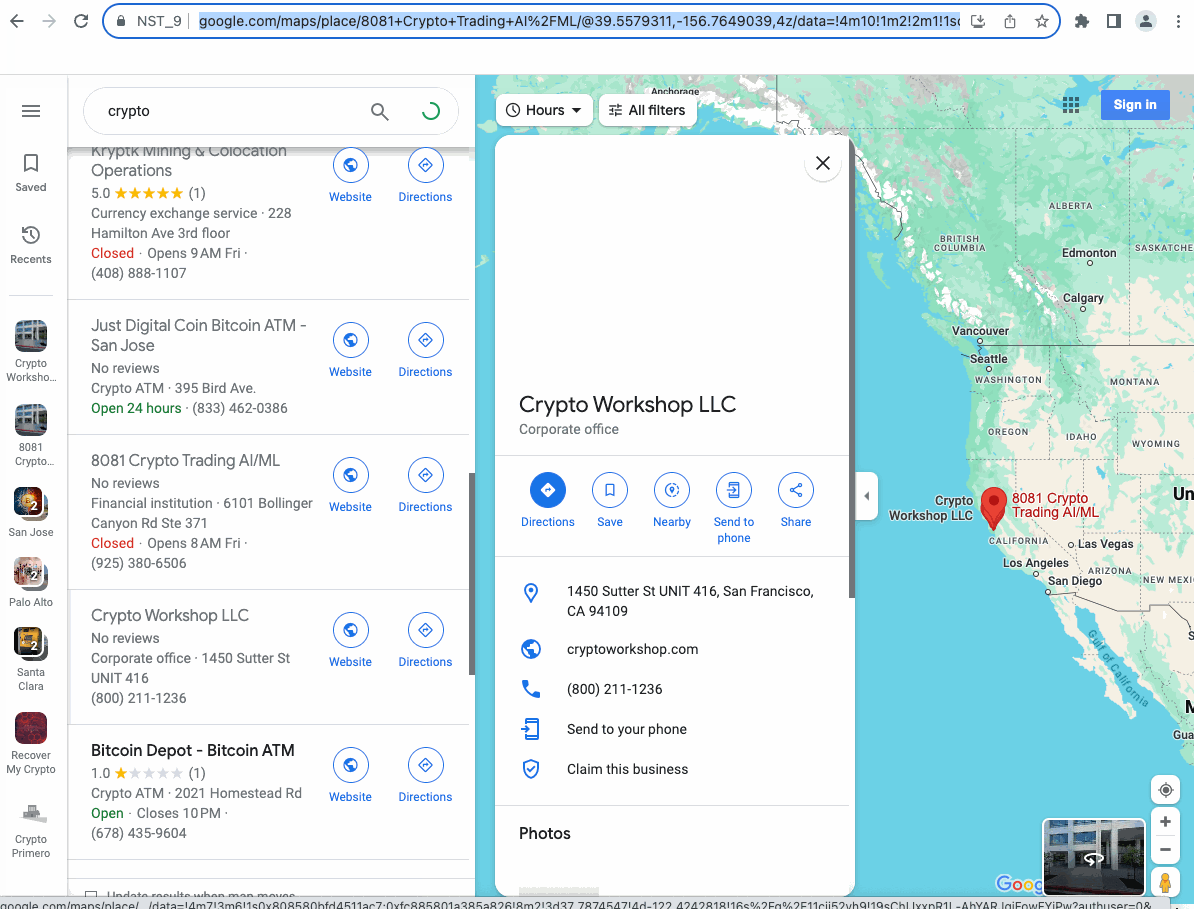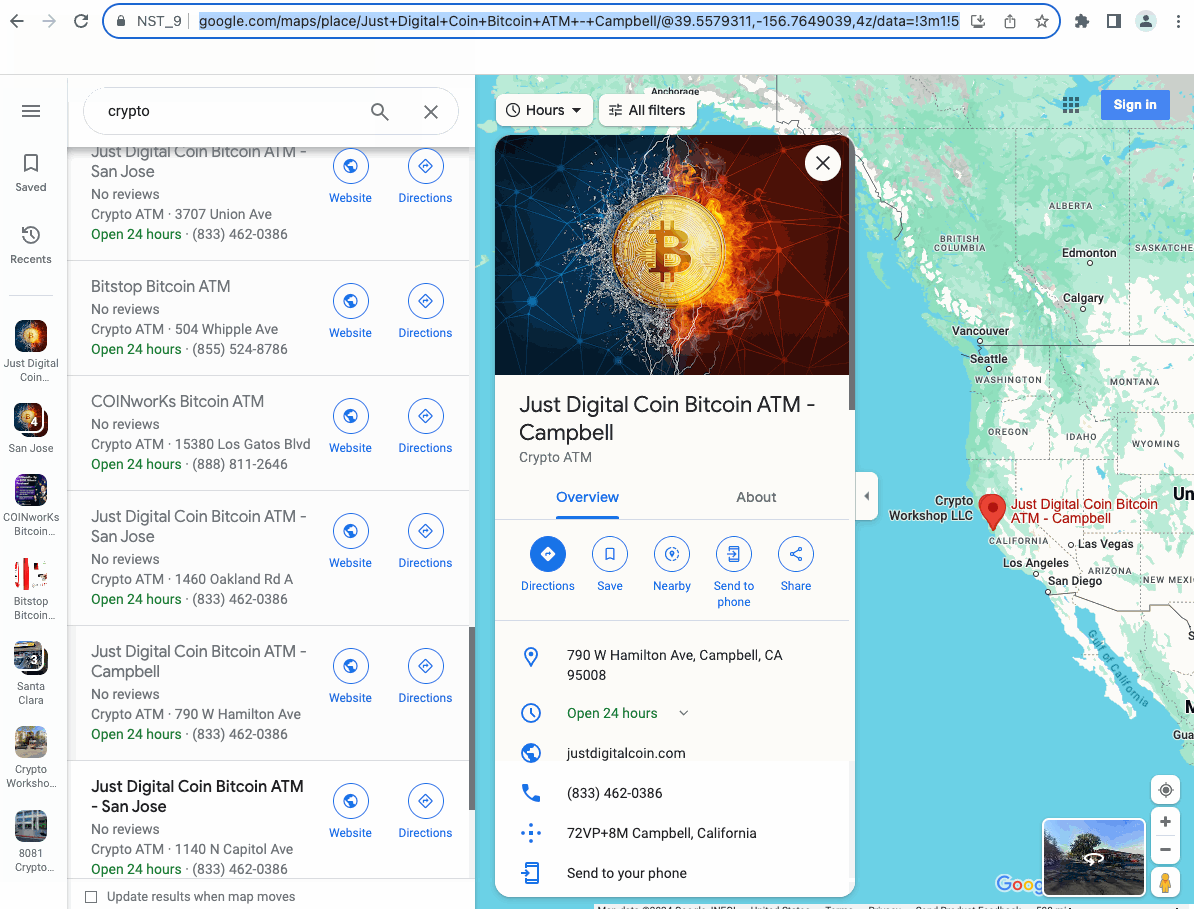
После завершения работы давайте посмотрим на результаты, которые мы собрали:
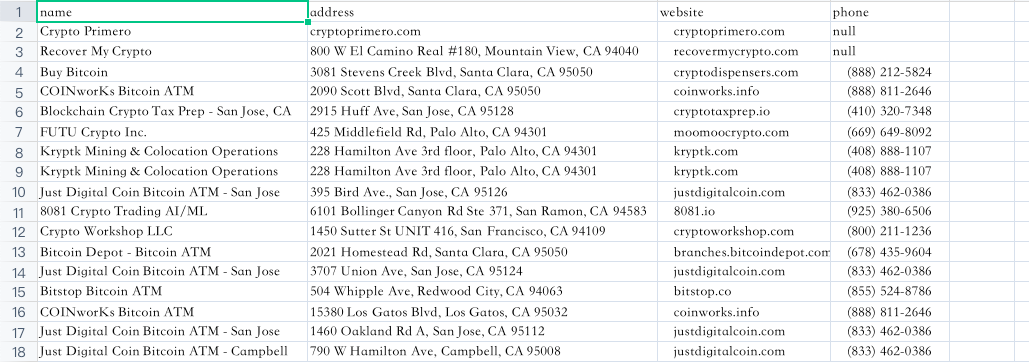
Очень круто, не правда ли?
Вам нужно только один раз настроить рабочий процесс, а затем вы можете заниматься сбором данных в любое время. Вот почему Nstbrowser RPA очарователен!
Наслаждайтесь Nstbrowser уже сейчас!
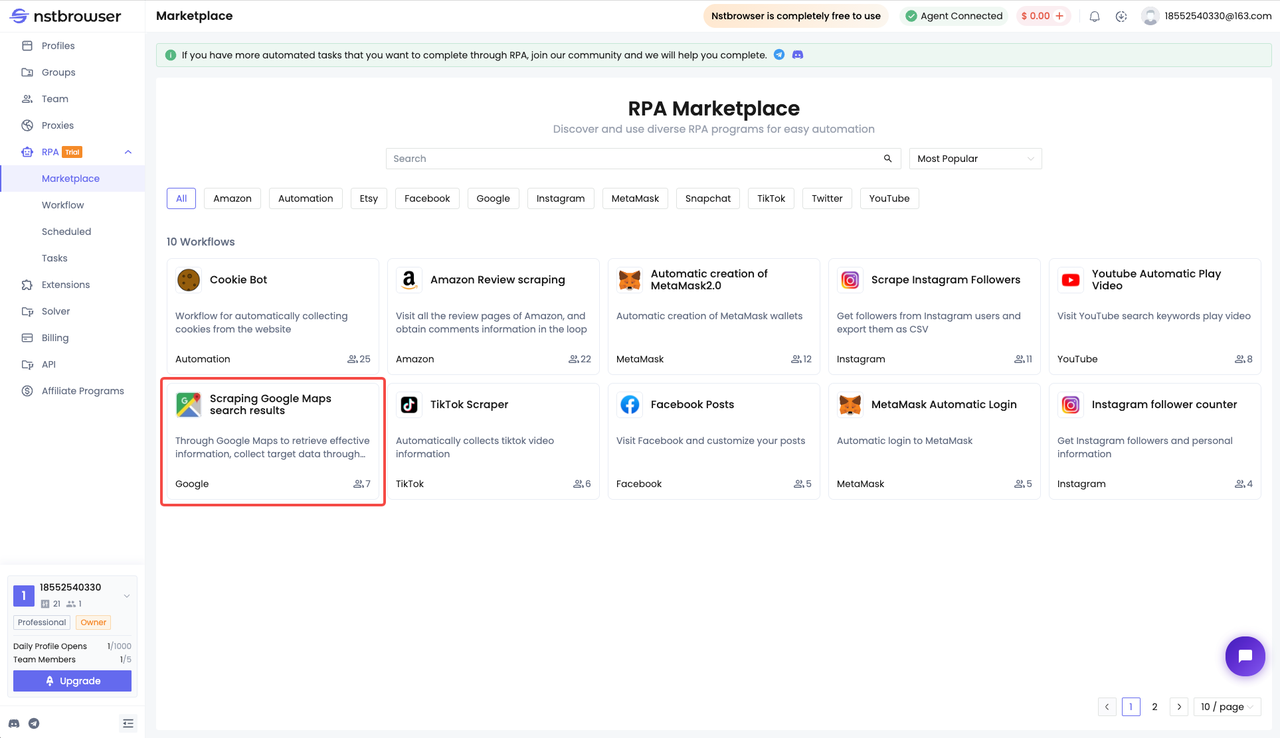
Скраппинг результатов поиска Google Maps теперь доступен на рынке RPA Nstbrowser, и вы можете перейти на рынок RPA, чтобы получить его напрямую! Просто измените содержимое, которое вы хотите искать, и путь к файлу, который вы хотите сохранить после получения, и вы можете начать свое путешествие по RPA-скраппингу.
Больше





