
Web Scraping
Tutorial de Web Scraping con Python y Selenium
¿Cómo hacer scraping web con Python y Selenium? Sólo 3 pasos para terminar tu tarea de web scraping.
Jun 05, 2024Carlos Rivera
Si tu trabajo de hoy es extraer información de las páginas de precios de los sitios web de tus competidores, ¿cómo lo lograrías? ¿Copiando y pegando? ¿Ingresando datos manualmente? ¡En realidad no! Estos métodos consumen la mayor parte de tu tiempo y pueden generar errores.
Es necesario señalar que Python se ha convertido en uno de los lenguajes de programación más populares para la extracción de datos. ¿Cuáles son sus encantos?
¡Comencemos a disfrutar del mundo del web scraping con Python!
¿Qué es el Web Scraping?
El web scraping es un proceso de extracción de datos de sitios web. Esto puede hacerse manualmente, pero es mejor utilizar algunas herramientas automatizadas o scripts para recopilar grandes cantidades de datos de manera eficiente y precisa. Copiar y pegar desde las páginas también es, de hecho, web scraping.
¿Por qué Python para Web Scraping?
Python es considerado una de las mejores opciones para el web scraping por varias razones:
- Fácil de usar: Debido a su claridad e intuición, Python es accesible incluso para principiantes.
- Bibliotecas potentes: Python cuenta con un rico conjunto de bibliotecas como Beautiful Soup, Scrapy y Selenium que simplifican las tareas de web scraping.
- Soporte de la comunidad: Python tiene una comunidad grande y activa. Proporciona abundantes recursos y apoyo para solucionar problemas y aprender.
Java también es un lenguaje importante para el web scraping. Puedes aprender 3 maravillosos métodos en el tutorial de Web Scraping con Java.
Hoja de ruta para el Web Scraping con Python
¿Estás listo para comenzar tu viaje en el web scraping con Python? Antes de determinar los pasos esenciales, asegúrate de saber qué esperar y cómo proceder.
Pasos Esenciales para Dominar el Web Scraping
El web scraping implica un proceso sistemático que comprende cuatro tareas principales:
1. Inspeccionar las Páginas Objetivo
Antes de extraer datos, necesitas entender el diseño del sitio web y la estructura de datos:
- Explorar el Sitio
- Analizar los Elementos HTML
- Identificar Datos Clave
2. Recuperar el Contenido HTML
Para hacer scraping de un sitio web, primero necesitas acceder a su contenido HTML:
- Usar Bibliotecas Cliente HTTP
- Hacer Solicitudes HTTP GET
- Verificar la Recuperación HTML
3. Extraer Datos del HTML
Una vez que tengas el HTML, el siguiente paso es extraer la información deseada:
- Analizar el Contenido HTML
- Seleccionar Datos Relevantes
- Escribir Lógica de Extracción
- Manejar Múltiples Páginas
4. Almacenar Datos Extraídos
Después de extraer los datos, es crucial almacenarlos en un formato accesible:
- Convertir Formatos de Datos
- Exportar Datos
Consejo: Los sitios web son dinámicos, así que revisa y actualiza regularmente tu proceso de scraping para mantener los datos actuales.
Casos de Uso para el Web Scraping
El web scraping con Python se puede aplicar en varios escenarios, incluyendo:
- Análisis de Competidores: Monitorear productos, servicios y estrategias de marketing de los competidores recopilando datos de sus sitios web.
- Comparación de Precios: Recopilar y comparar precios de diferentes plataformas de comercio electrónico para encontrar las mejores ofertas.
- Análisis de Redes Sociales: Obtener datos de plataformas de redes sociales para analizar la popularidad y participación de hashtags, palabras clave o influenciadores específicos.
- Generación de Clientes Potenciales: Extraer detalles de contacto de sitios web para crear listas de marketing dirigidas, teniendo en cuenta consideraciones legales.
- Análisis de Sentimientos: Recopilar noticias y publicaciones en redes sociales para rastrear la opinión pública sobre un tema o marca.
Superando los Desafíos del Web Scraping
El web scraping tiene su propio conjunto de desafíos:
- Estructuras Web Diversas: Cada sitio web tiene un diseño único, lo que requiere scripts de scraping personalizados.
- Cambios en las Páginas Web: Los sitios web pueden cambiar su estructura sin previo aviso, lo que requiere ajustes en tu lógica de scraping.
- Problemas de Escalabilidad: A medida que aumenta el volumen de datos, asegúrate de que tu scraper siga siendo eficiente mediante el uso de sistemas distribuidos, scraping paralelo u optimización de código.
Además, los sitios web utilizan medidas anti-bot como bloqueo de IP, desafíos de JavaScript y CAPTCHAs. Estos pueden sortearse con técnicas como proxies rotativos y navegadores headless.
¿Atascado en problemas de rastreo web?
Evita la detección anti-bot para simplificar el web scraping y la automatización
¡Prueba Nstbrowser gratis!
¿Tienes ideas y dudas interesantes sobre el web scraping y el Browserless?
¡Veamos qué comparten otros desarrolladores en Discord y Telegram!
Alternativas al Web Scraping
Aunque el web scraping es versátil, existen alternativas:
- APIs: Algunos sitios web ofrecen APIs para solicitar y obtener datos. Las APIs son estables y generalmente no están protegidas contra el scraping, pero ofrecen datos limitados y no todos los sitios web las proporcionan.
- Conjuntos de Datos Listos para Usar: Comprar conjuntos de datos en línea es otra opción, aunque no siempre cumplen con tus necesidades específicas.
A pesar de estas alternativas, el web scraping sigue siendo una opción popular debido a su flexibilidad y amplias capacidades de acceso a datos.
¡Emprende tu viaje en el web scraping con Python y desbloquea el vasto potencial de los datos en línea!
¿Cómo Hacer Web Scraping con Python y Selenium?
Paso 1. Prerrequisitos
Al principio, necesitamos instalar nuestra shell:
Shell
pip install selenium requests jsonDespués de completar la instalación, crea un nuevo archivo scraping.py e importa la biblioteca que acabamos de instalar en el archivo:
Python
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import ByPaso 2. Conectar a Nstbrowser
Para obtener una demostración exacta, utilizaremos Nstbrowser, un navegador totalmente gratuito con anti-detección como herramienta para completar nuestra tarea:
Python
def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'xxxxxxx' # tu clave de API
config = {
'once': True,
'headless': False, # sin cabeza
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # requerido
'name': 'custom browser',
'platform': 'windows', # soporte: windows, mac, linux
'kernel': 'chromium', # solo soporte: chromium
'kernelMilestone': '120',
'hardwareConcurrency': 4, # soporte: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # soporte: 2, 4, 8
'proxy': '', # formato de entrada: schema://user:password@host:port ej: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # requerido
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
print('devtool url: ' + url)
port = get_debugger_port(url)
debugger_address = f'{host}:{port}'
print("debugger_address: " + debugger_address)Después de conectarse a Nstbrowser, nos conectamos a Selenium a través de la dirección del depurador que nos devolvió Nstbrowser:
Python
def exec_selenium(debugger_address: str):
options = webdriver.ChromeOptions()
options.add_experimental_option("debuggerAddress", debugger_address)
# Reemplaza con la ruta correspondiente del controlador WebDriver.
chrome_driver_path = r'./chromedriver' # tu ruta del controlador de Chrome
service = ChromeService(executable_path=chrome_driver_path)
driver = webdriver.Chrome(service=service, options=options)Paso 3. Hacer Scraping de la Web
¡Desde ahora hemos iniciado correctamente Nstbrowser a través de Selenium. ¡Comienza a rastrear ahora!
- Visita nuestro sitio web objetivo, por ejemplo: https://www.imdb.com/chart/top
Python
driver.get("https://www.imdb.com/chart/top")- Ejecutando el código que acabamos de escribir:
Python
python scraping.pyComo puedes ver, hemos iniciado correctamente Nstbrowser y visitado nuestro sitio objetivo.
- Abre Devtool para ver la información específica que queremos rastrear. Sí, obviamente son elementos con la misma estructura DOM.
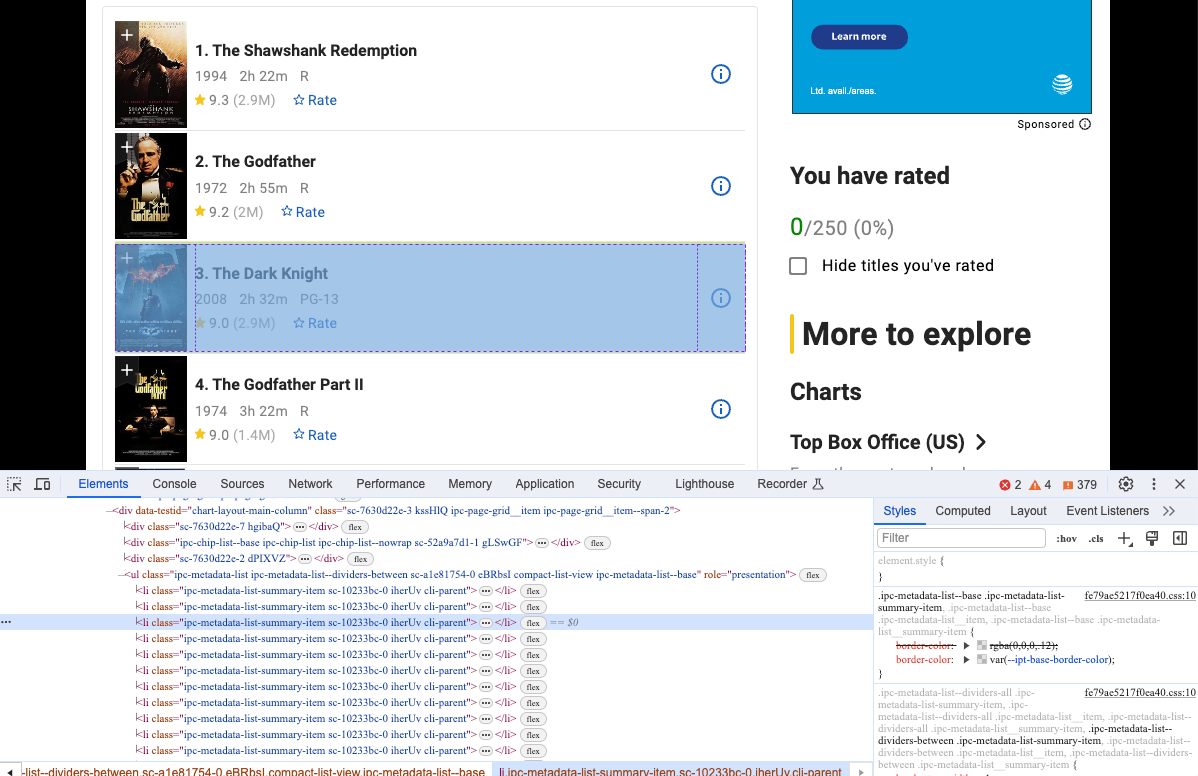
Podemos usar Selenium para obtener este tipo de estructura DOM y analizar su contenido:
Python
movies = driver.find_elements(By.CSS_SELECTOR, "li.cli-parent")
for row in movies:
title = row.find_element(By.CLASS_NAME, 'ipc-title-link-wrapper') # obtener título
year = row.find_element(By.CSS_SELECTOR, 'span.cli-title-metadata-item') # obtener año de creación
rate = row.find_element(By.CLASS_NAME, 'ipc-rating-star') # obtener clasificación
move_item = {
"title": title.text,
"year": year.text,
"rate": rate.text
}
print(move_item)- Ejecuta nuestro código nuevamente, y verás que la terminal ya ha mostrado la información que queremos obtener.
Por supuesto, la salida de esta información en la terminal no es nuestro objetivo. A continuación, necesitamos guardar los datos que hemos rastreado.
Usamos la biblioteca JSON para guardar los datos recuperados en un archivo JSON:
Python
movies = driver.find_elements(By.CSS_SELECTOR, "li.cli-parent")
movies_info = []
for row in movies:
title = row.find_element(By.CLASS_NAME, 'ipc-title-link-wrapper')
year = row.find_element(By.CSS_SELECTOR, 'span.cli-title-metadata-item')
rate = row.find_element(By.CLASS_NAME, 'ipc-rating-star')
move_item = {
"title": title.text,
"year": year.text,
"rate": rate.text
}
movies_info.append(move_item)
# crear el archivo JSON
json_file = open("movies.json", "w")
# convertir movies_info a JSON
json.dump(movies_info, json_file)
# liberar los recursos del archivo
json_file.close()- Ejecuta el código y abre el archivo. Verás que hay un archivo adicional movies.json junto a scraping.py, lo que significa que hemos utilizado con éxito Selenium para conectarnos a Nstbrowser y rastrear los datos de nuestro sitio objetivo!
Conclusiones
¿Cómo hacer web scraping con Python y Selenium? Este tutorial detallado cubrió todo lo que estás buscando. Para tener una comprensión completa, hablamos sobre el concepto y las ventajas de Python para el web scraping. Luego, pasamos a los pasos específicos tomando como ejemplo un navegador con anti-detección gratuito - Nstbrowser. ¡Estoy seguro de que ahora has aprendido mucho sobre el web scraping con Python! Es hora de operar tu proyecto y recopilar datos.
Más





