
Web Scraping
Urllib vs Urllib3 vs Requests: ¿Cuál es mejor para usted cuando realiza Web Scraping?
Urllib, urllib3 y request son tres bibliotecas de Python maravillosas y comunes. ¿Cuáles son las diferencias de estos 3? ¡Lea este artículo y encuentre el que mejor se adapte a sus necesidades!
Jul 17, 2024Robin Brown
¿Siempre utilizas Python para el web scraping? Entonces, seguramente también te confundes sobre cuál es el mejor cliente HTTP entre Urllib, Urllib3 y Requests, ¿verdad?
Sí, en la programación Python, manejar solicitudes HTTP es un requisito común.
Python proporciona múltiples bibliotecas para cumplir esta función, y Urllib, Urllib3 y Requests son las 3 bibliotecas más comunes.
¿Qué tiene de especial cada una? ¿Cuál es la más adecuada para ti?
Todas tienen sus características únicas, pros y contras. ¡Comienza a leer este artículo y descúbrelo!
Comparaciones Generales
| Biblioteca | Urllib | Urllib3 | Requests |
|---|---|---|---|
| Instalación Requerida | No | Sí | Sí |
| Velocidad | Moderada | Rápida | Moderada |
| Manejo de Respuestas | La respuesta generalmente requiere pasos de decodificación adicionales | No se requieren pasos de decodificación adicionales | No se requieren pasos de decodificación adicionales |
| Pool de Conexiones | No soportado | Soportado | Soportado |
| Facilidad de Uso | Más sintaxis complican la curva de aprendizaje | Fácil de usar | Fácil de usar y más amigable para principiantes |
1. Urllib
Urllib es parte de la biblioteca estándar de Python para manejar URLs, y no necesitas instalar bibliotecas adicionales para usarla.
Cuando utilizas Urllib para enviar una solicitud, devuelve una matriz de bytes del objeto de respuesta. Sin embargo, hay que decir que su matriz de bytes devuelta requiere un paso de decodificación adicional, lo que puede ser desafiante para los principiantes.
¿Cuáles son las especialidades de Urllib?
Urllib permite un control más fino con una interfaz de bajo nivel, pero también significa que se necesita escribir más código. Por lo tanto, los usuarios generalmente deben manejar manualmente la codificación de URL, la configuración de encabezados de solicitud y la decodificación de respuestas.
Pero ¡no te preocupes! Urllib proporciona funciones básicas de solicitud HTTP como solicitudes GET y POST, y también admite el análisis, codificación y decodificación de URL.
Pros y Contras
Pros:
- No se requiere instalación adicional. Como es parte de la biblioteca estándar de Python, no necesitas instalar bibliotecas adicionales para usarla.
- Funciones completas. Soporta procesamiento de solicitudes URL, respuestas y análisis.
Contras:
- Alta complejidad. Los pasos para enviar solicitudes y manejar respuestas son engorrosos.
- Matrices de bytes necesitan ser procesadas manualmente. La respuesta devuelta debe ser decodificada manualmente, lo que añade un paso adicional.
¿Para qué se puede usar Urllib?
Urllib es adecuado para tareas simples como solicitudes HTTP, especialmente cuando no deseas instalar bibliotecas de terceros.
También puede aprender y entender los principios subyacentes. Por lo tanto, los usuarios pueden usarlo para aprender y comprender la implementación subyacente de las solicitudes HTTP.
Sin embargo, debido a que Urllib carece de características avanzadas como el manejo de pool de conexiones, compresión por defecto y procesamiento JSON, es relativamente engorroso de usar, especialmente para solicitudes HTTP complejas.
2. Urllib3
Urllib3 proporciona abstracciones de alto nivel, incluyendo API de solicitud, pool de conexiones, compresión por defecto, codificación y decodificación JSON, entre otros.
¡Aplicar estas características es muy simple! Puedes personalizar solicitudes HTTP con solo unas pocas líneas de código. Urllib3 utiliza extensiones C para modificar el rendimiento. Por lo tanto, es el más rápido de los tres.
¿Cuáles son las especialidades de Urllib3?
Urllib3 proporciona una interfaz más avanzada. También soporta características avanzadas como pool de conexiones, reintentos automáticos, configuración SSL y carga de archivos:
- Pool de conexiones: Administra pools de conexiones para reducir la sobrecarga de conexiones TCP repetidas.
- Mecanismo de reintentos: Reintenta automáticamente las solicitudes para mejorar la estabilidad.
- Compresión por defecto: Soporta compresión y descompresión de datos de solicitud y respuesta.
- Soporte JSON: Aunque no es una función incorporada, se puede utilizar junto con el módulo JSON para procesar datos JSON.
- Verificación SSL: Ofrece mejor soporte SSL y opciones de configuración.
Pros y Contras
Pros:
- Más características avanzadas. Ofrece más características avanzadas que Urllib, como pool de conexiones, carga de fragmentos de archivos, solicitud de reintentos, etc.
- Más fácil de usar. La sintaxis es más simple que Urllib, lo que reduce la complejidad del código.
Contras:
- Requiere instalación. Necesitas usar pip para instalar
urllib3(pip install urllib3).
¿Para qué se puede usar Urllib3?
Los usuarios pueden aplicar urllib3 para algunas solicitudes HTTP complejas, como el manejo de solicitudes concurrentes, gestión de pool de conexiones, etc.
Urllib3 también es adecuado para algunos requisitos que necesitan mayor rendimiento y estabilidad.
3. Requests
Requests es una biblioteca popular para enviar solicitudes HTTP. Es conocida por su diseño de API simple y funciones poderosas, lo que la hace muy fácil de interactuar con la red.
Las solicitudes HTTP enviadas a través de requests se vuelven muy simples e intuitivas. Además, tiene funciones integradas como manejo de cookies, sesiones, configuraciones de proxy y datos JSON, lo que asegura una experiencia amigable para el usuario.
También tiene algunas características poderosas:
- API simple: Proporciona la interfaz más simple y fácil de usar. Por eso las solicitudes HTTP son muy intuitivas.
- Pool de conexiones: Gestión de pool de conexiones integrada.
- Compresión por defecto: Maneja automáticamente la compresión de solicitudes y respuestas.
- Soporte JSON: Es muy conveniente manejar datos JSON con
requestsgracias a sus funciones integradas de codificación y decodificación JSON. - Funciones completas: Incluyendo carga de archivos, descarga en streaming, persistencia de sesiones, etc.
Pros y Contras
Pros:
- La sintaxis más concisa y amigable.
Requestsproporciona la API más simple y fácil de entender. Por lo tanto, enviar solicitudes HTTP será muy fácil. - Utiliza
urllib3integrado. Utilizaurllib3en el fondo, combinando alta eficiencia y funciones avanzadas mientras oculta la complejidad. - Popularidad y soporte de la comunidad. Debido a su amplio uso, hay mucha documentación, tutoriales y soporte de la comunidad.
Contras:
- Requiere instalación.
Requestsdebe instalarse conpip(pip install requests). - A pesar de sus características ricas, su rendimiento es relativamente lento debido a su abstracción de alto nivel.
¿Para qué se puede usar Requests?
Requests es adecuado para casi todos los escenarios de solicitud HTTP, especialmente para rastreadores web y solicitudes de API. Debido a su sintaxis concisa y su documentación completa, también es particularmente adecuado para principiantes.
Comparación de Rendimiento
Según los resultados de la prueba de rendimiento, el rendimiento de estas tres bibliotecas en 100 iteraciones es el siguiente:
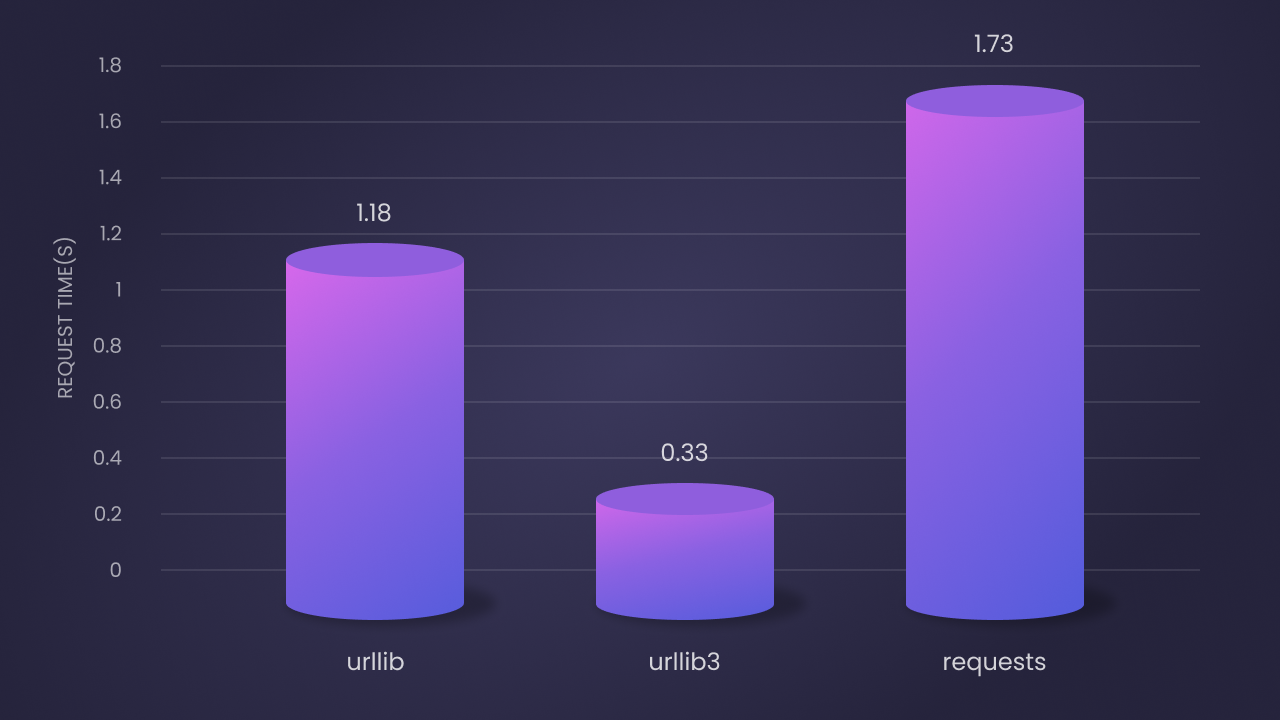
Urllibes el segundo más rápido: el tiempo promedio de solicitud es de 1.18 segundos. Aunque es una implementación pura de Python, tiene un mejor rendimiento debido a su implementación subyacente.Urllib3es el más rápido: el tiempo promedio de solicitud es de 0.33 segundos. Esto se debe a su extensión C y a una gestión eficiente de pool de conexiones.Requestses el más lento: el tiempo promedio de solicitud es de 1.73 segundos. Pero su facilidad de uso y funciones ricas compensan la falta de rendimiento.
Sugerencia de elección
-
Si prefieres depender de la menor cantidad posible de bibliotecas externas y los requisitos del proyecto son simples, puedes optar por
urllib. Forma parte de la biblioteca estándar de Python y no requiere instalación adicional. -
Si necesitas funciones avanzadas y alto rendimiento y no te importa realizar algunas operaciones técnicas adicionales,
urllib3es una buena elección. -
Para aquellos que buscan código mínimo y una interfaz fácil de usar, especialmente al manejar solicitudes HTTP complejas,
requestses ideal. Es la biblioteca más amigable para los usuarios y ampliamente utilizada para rastreadores web y solicitudes de API.
Métodos efectivos para evitar el bloqueo durante el web scraping
Muchos sitios web han integrado sistemas anti-bot para detectar y bloquear scripts automatizados como los rastreadores web. Por lo tanto, es esencial evitar estos bloqueos para acceder a los datos.
Una forma de evitar la detección es utilizar Nstbrowser para evitar el bloqueo IP. Urllib y urllib3 también tienen capacidades integradas para agregar proxies a las solicitudes HTTP.
Nstbrowser está diseñado con rotación de IP y desbloqueador web.
¡Prueba Nstbrowser gratis para evitar el bloqueo IP!
¿Tienes ideas y dudas interesantes sobre el web scraping y el Browserless?
¡Veamos qué comparten otros desarrolladores en Discord y Telegram!
Método 1: Usa Nstbrowser para pasar el sistema anti-bot
Antes de comenzar, debes cumplir algunas condiciones:
- Convertirse en usuario de Nstbrowser.
- Obtener la API Key de Nstbrowser.
- Ejecute el servicio Nstbrowserless de forma local.
A continuación se presentan los pasos específicos. Tomaremos el ejemplo de extraer el título del contenido de una página en el sitio web de Amazon.
Si necesitamos extraer el contenido del título h3 de la siguiente página web:
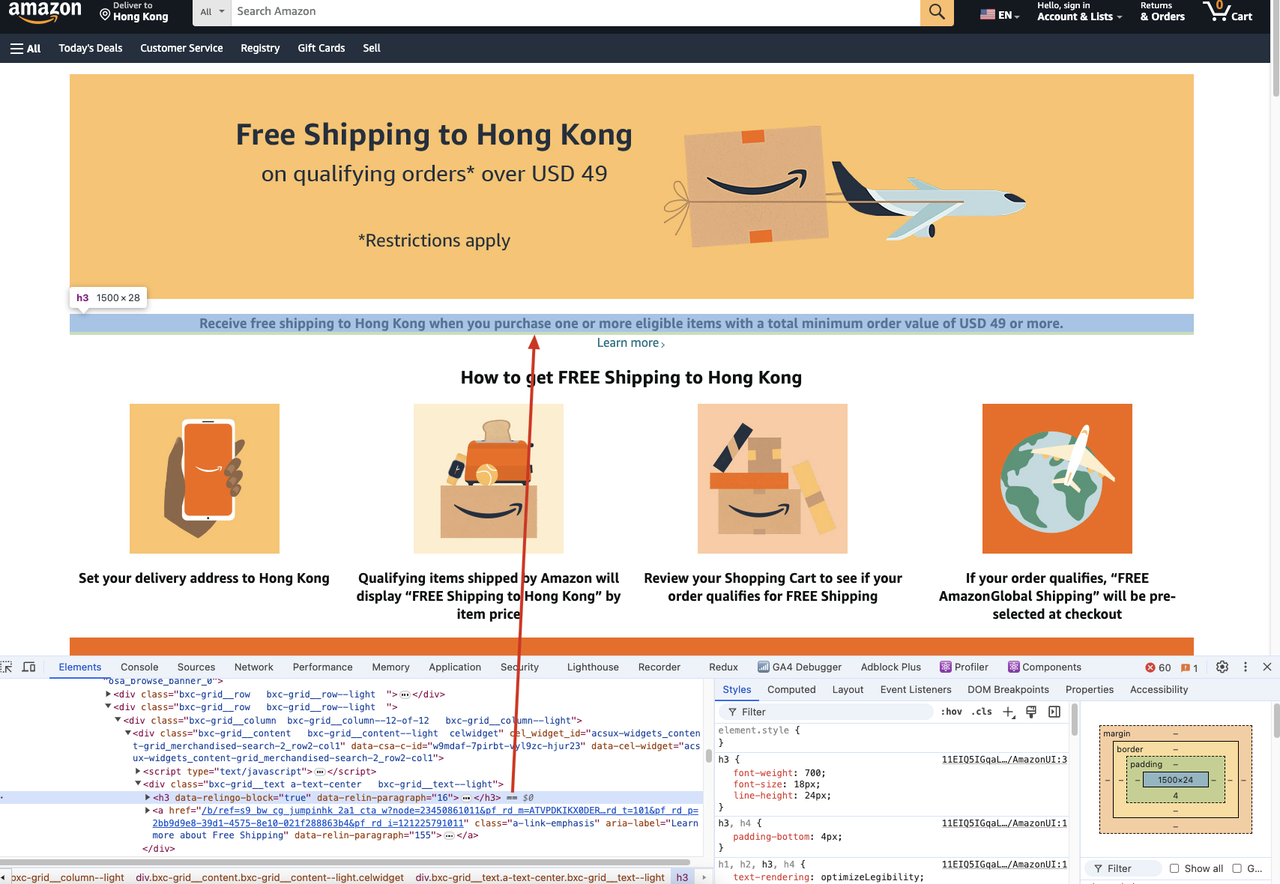
Deberíamos ejecutar el siguiente código:
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # establecer modo sin cabeza
"autoClose": True,
"args": {"--disable-gpu": "", "--no-sandbox": ""}, # los argumentos del navegador deben ser un diccionario
"fingerprint": {
"name": 'amazon_scraper',
"platform": 'mac', # soporte: windows, mac, linux
"kernel": 'chromium', # solo soporte: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8,
"deviceMemory": 8,
},
}
query = {'config': json.dumps(config)}
profileUrl = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
print("Profile URL: ", profileUrl)
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profileUrl)
try:
page = await browser.new_page()
await page.goto("https://www.amazon.com/b/?_encoding=UTF8&node=121225791011&pd_rd_w=Uoi8X&content-id=amzn1.sym.dde8a7c4-f315-46af-87af-ab98d7f18222&pf_rd_p=dde8a7c4-f315-46af-87af-ab98d7f18222&pf_rd_r=CM6698M8C3J02BBVTVM3&pd_rd_wg=olMbe&pd_rd_r=ff5d2eaf-26db-4aa4-a4dd-e74ea389f355&ref_=pd_hp_d_atf_unk&discounts-widget=%2522%257B%255C%2522state%255C%2522%253A%257B%255C%2522refinementFilters%255C%2522%253A%257B%257D%257D%252C%255C%2522version%255C%2522%253A1%257D%2522")
await page.wait_for_selector('h3')
title = await page.inner_text('h3')
print(title)
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())En el código anterior, realizamos principalmente los siguientes pasos:
- Creamos el servicio Nstbrowser y configuramos el modo sin cabeza y algunos parámetros básicos de inicio en la configuración de inicio.
- Utilizamos Playwright para conectarnos a Nstbrowser.
- Navegamos a la página correspondiente que se necesita rascar para obtener su contenido.
Después de ejecutar el código anterior, finalmente notará la siguiente salida:

Método 2: Utilice encabezados de solicitud personalizados para imitar un navegador real
Paso 1. Deberíamos usar Playwright y Nstbrowser para visitar un sitio web que puede obtener la información actual del encabezado de solicitud.
- Demonstración de código:
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # set headless mode
"autoClose": True,
"args": {"--disable-gpu": "", "--no-sandbox": ""}, # browser args should be a dictionary
"fingerprint": {
"name": 'amazon_scraper',
"platform": 'mac', # support: windows, mac, linux
"kernel": 'chromium', # only support: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8,
"deviceMemory": 8,
},
}
query = {'config': json.dumps(config)}
profileUrl = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
print("Profile URL: ", profileUrl)
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profileUrl)
try:
page = await browser.new_page()
await page.goto("https://httpbin.org/headers")
await page.wait_for_selector('pre')
content = await page.inner_text('pre')
print(content)
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())A través del código anterior, veremos la siguiente salida:
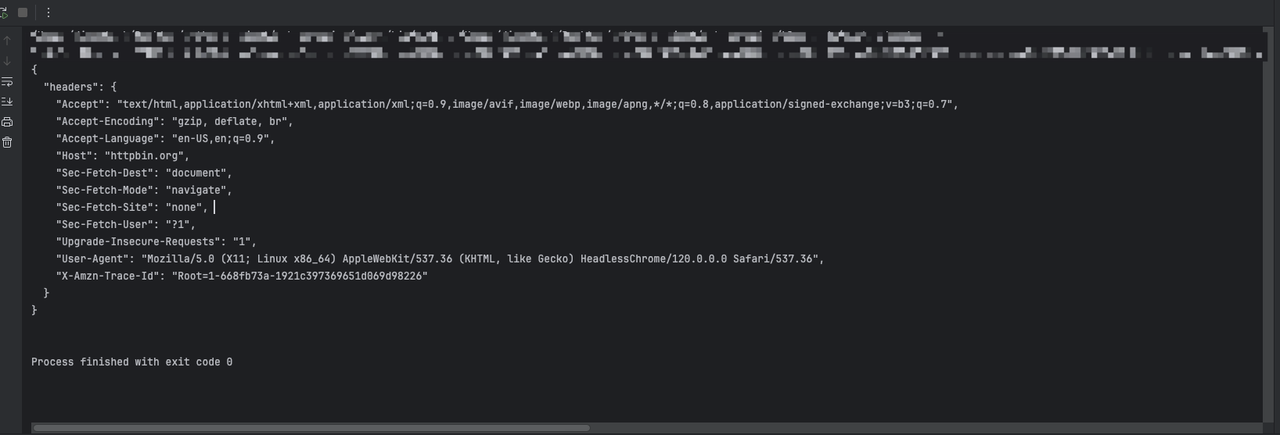
Paso 2. Necesitamos usar Playwright para agregar información adicional del encabezado de solicitud configurando la intercepción de solicitud al crear la página:
Python
{
'sec-ch-ua': '\'Not A(Brand\';v=\'99\', \'Google Chrome\';v=\'121\', \'Chromium\';v=\'121\'',
'accept-Language': 'zh-CN,en;q=0.9'
}- Demostración de código:
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
extra_headers = {
'sec-ch-ua': '\'Not A(Brand\';v=\'99\', \'Google Chrome\';v=\'121\', \'Chromium\';v=\'121\'',
'accept-Language': 'en-US,en;q=0.9'
}
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # establecer modo sin cabeza
"autoClose": True,
"args": ["--disable-gpu", "--no-sandbox"], # los argumentos del navegador deben ser una lista
"fingerprint": {
"name": 'amazon_scraper',
"platform": 'mac', # soporte: windows, mac, linux
"kernel": 'chromium', # solo soporte: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8,
"deviceMemory": 8,
},
}
query = {'config': json.dumps(config)}
profileUrl = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
print("Profile URL: ", profileUrl)
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profileUrl)
try:
context = await browser.new_context()
page = await context.new_page()
# Agregar intercepción de solicitud para establecer encabezados adicionales
await page.route('**/*', lambda route, request: route.continue_(headers={**request.headers, **extra_headers}))
response = await page.goto("https://httpbin.org/headers")
print(await response.text())
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
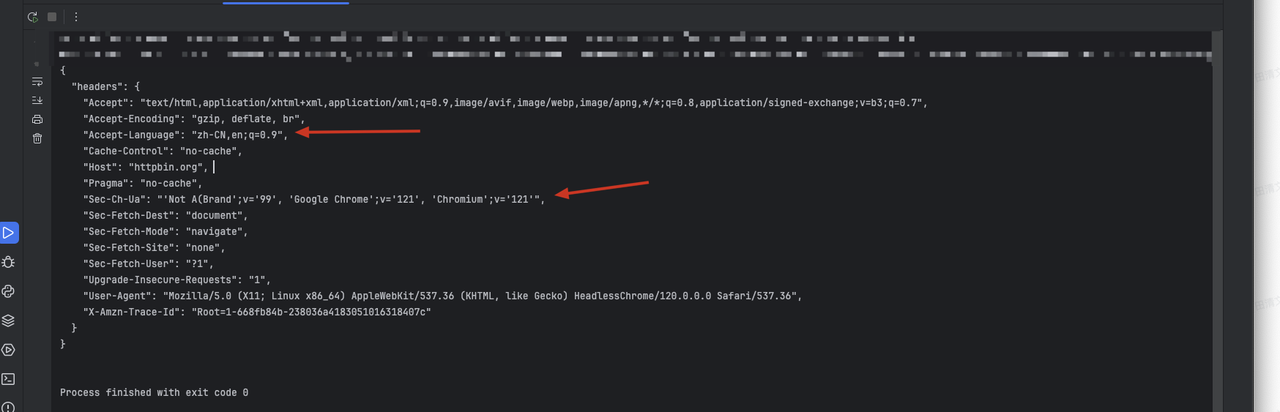
asyncio.run(main())A través del código anterior, veremos la siguiente información devuelta, en la que se agregará la información de encabezado personalizada:
- El encabezado
sec-ch-ua. - El contenido original del encabezado acepta el lenguaje.
Notas finales
En resumen:
Requestsse ha convertido en la primera opción para la mayoría de los desarrolladores debido a su facilidad de uso y funcionalidad completa.Urllib3destaca cuando se requiere rendimiento y características más avanzadas.- Como parte de la biblioteca estándar,
urllibes adecuado para proyectos con altos requisitos de dependencia.
Dependiendo de tus necesidades y escenarios específicos, elegir la herramienta más adecuada te ayudará a manejar las solicitudes HTTP de manera más eficiente.
Más





