
Web Scraping
El Mejor Navegador Antidetect para Web Scraping 2024
Anti-detect browser le ayuda a ocultar la huella digital de su navegador al raspar la página web. Realmente simplifica tus tareas. ¡Lee este blog y descubre más!
Jul 19, 2024Robin Brown
Las huellas digitales del navegador son una de las formas más significativas de identificar tu vida en línea. Rastrean tu perfil a través de diferentes sesiones y sitios web. Así que cuando deseas hacer scraping web, es probable que te detecten.
Para rastrear datos de manera fácil y eficiente, se crearon navegadores anti-detección (o navegadores anti-huella digital).
Este blog te ayuda a entender:
- Las ventajas de un navegador anti-detección
- Cómo ayuda con el scraping web
- Pasos para un scraping de datos eficiente con Nstbrowser
¿Qué es un Navegador Anti-Detección?
Un navegador anti-detección es capaz de crear y ejecutar múltiples identidades digitales que no son reconocidas por las plataformas sociales. Esto requiere mucho trabajo de desarrollo personalizado, por lo que tales herramientas generalmente no están disponibles de forma gratuita.
Están creados para luchar contra el rastreo y la analítica para que puedas llevar a cabo tus actividades en privado. En otras palabras, un navegador anti-huella digital mejora la privacidad, mantiene tus datos y actividades web anónimos, y ayuda a tus herramientas de rastreo web a evitar ser bloqueadas.
¡Prueba el navegador anti-detección gratuito - Nstbrowser!
Desbloquea el 99.9% de los sitios web con numerosas soluciones efectivas
Simplifica el scraping web y la automatización
¿Tienes ideas y dudas interesantes sobre el web scraping y el Browserless?
¡Veamos qué comparten otros desarrolladores en Discord y Telegram!
¿Cómo Ayudan los Navegadores Anti-Detección en la Recolección de Datos?
Un navegador anti-detección ayuda a reducir el impacto de la interceptación web. Minimiza o incluso previene que los sitios web identifiquen a los usuarios y rastreen sus actividades en línea.
Dado que los sitios web tienen sistemas anti-crawler, cuando usas un bot de crawler para hacer scraping de datos directamente, serás detectado y bloqueado por el sitio web. Los usuarios humanos tienen prioridad sobre los bots y algunos sitios web no alientan a otras empresas a recolectar sus datos.
Como resultado, varias organizaciones combinan tecnologías de scraping web y navegadores anti-detección con medidas de privacidad como proxies para ayudar a ocultar los bots.
¿Qué es Nstbrowser?
Nstbrowser es un navegador anti-huella digital totalmente gratuito, integrado con un bot anti-detección, Web Unblocker y Proxies Inteligentes. Soporta Clústeres de Contenedores en la Nube, Browserless y una solución de navegador en la nube de nivel empresarial compatible con Windows/Mac/Linux.
¿Cómo Lograr el Scraping Web con un Navegador Anti-Detección?
A continuación, tomemos un ejemplo de scraping con Nstbrowser. Solo 5 pasos sencillos:
Paso 1. Requisitos Previos
Antes de hacer scraping, primero debes hacer las siguientes preparaciones:
Shell
pip install pyppeteer requests jsonDespués de instalar pyppeteer, necesitamos crear un nuevo archivo: scraping.py, e introducir las bibliotecas que acabamos de instalar así como algunas bibliotecas del sistema en el archivo:
Python
import asyncio
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from pyppeteer import launcher¿Podemos usar pyppeteer ahora?
¡Por favor, cálmate!
Hemos pasado unos minutos conectándonos a Nstbrowser, que proporciona una API para devolver el webSocketDebuggerUrl para pyppeteer.
Python
# get_debugger_url: Obtener la URL del depurador
def get_debugger_url(url: str):
try:
resp = requests.get(url).json()
if resp['data'] is None:
raise Exception(resp['msg'])
webSocketDebuggerUrl = resp['data']['webSocketDebuggerUrl']
return webSocketDebuggerUrl
except HTTPError:
raise Exception(HTTPError.response)
async def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'tu clave API'
config = {
'once': True,
'headless': False,
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # requerido
'name': 'navegador personalizado',
'platform': 'windows', # soporte: windows, mac, linux
'kernel': 'chromium', # solo soporte: chromium
'kernelMilestone': '120', # soporte: 113, 115, 118, 120
'hardwareConcurrency': 4, # soporte: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # soporte: 2, 4, 8
'proxy': '', # formato de entrada: esquema://usuario:contraseña@host:puerto ej: http://usuario:contraseña@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # requerido
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
browser_ws_endpoint = get_debugger_url(url)
print("browser_ws_endpoint: " + browser_ws_endpoint) # pyppeteer se conecta a Nstbrowser con browser_ws_endpoint
(
asyncio
.get_event_loop()
.run_until_complete(create_and_connect_to_browser())
)¡Genial! ¡Hemos obtenido con éxito el webSocketDebuggerUrl de Nstbrowser!
Es hora de conectar pyppeteer a Nstbrowser:
Python
async def exec_pyppeteer(wsEndpoint: str):
browser = await launcher.connect(browserWSEndpoint = wsEndpoint)
page = await browser.newPage()Ejecutando el código que acabamos de escribir en la terminal: python scraping.py, hemos abierto con éxito un Nstbrowser y creado una nueva pestaña en él.
¡Todo está listo, y ahora, podemos comenzar oficialmente el rastreo!
Paso 2. Visita el sitio web objetivo
Por ejemplo: https://www.yahoo.com/
Python
options = {'timeout': 60000}
await page.goto('https://www.yahoo.com/', options)Paso 3. Ejecutar el código
Ejecuta el código una vez más y luego accederemos a nuestro sitio web objetivo a través de Nstbrowser.
Ahora necesitamos abrir Devtool para ver la información específica que queremos rastrear y podemos ver que todos son elementos con la misma estructura DOM.
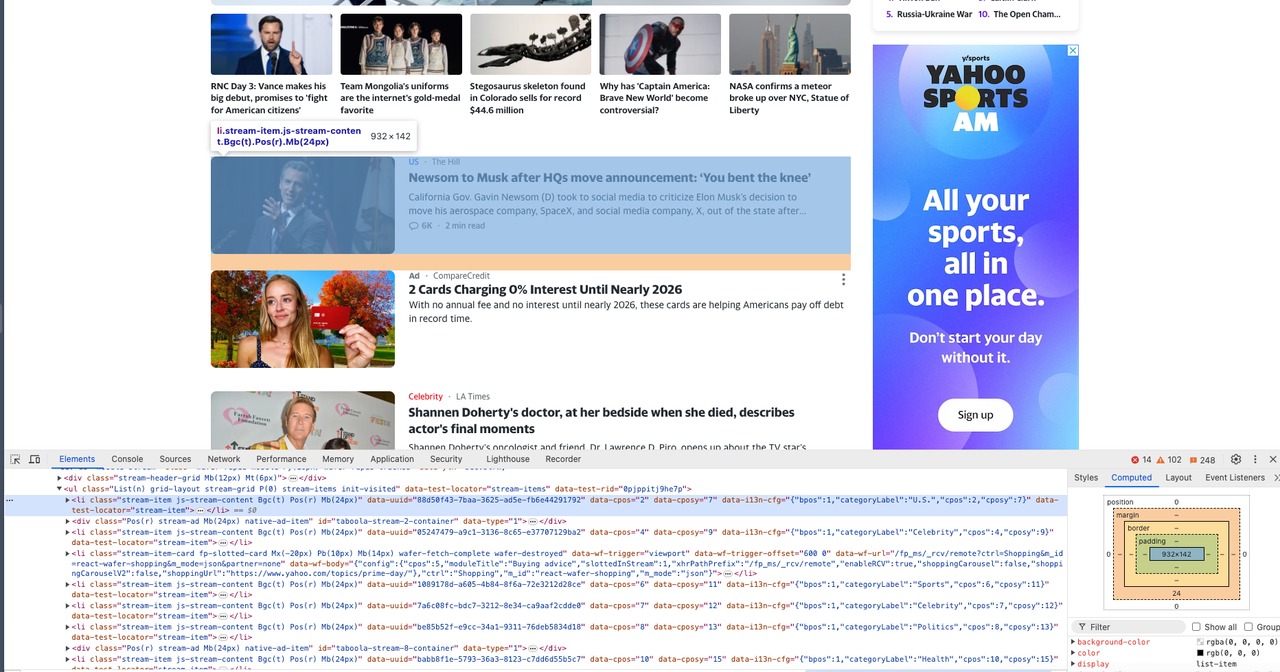
Paso 4. Rastrear la página web
Ahora, es nuestro buen momento para usar Pyppeteer para rastrear estas estructuras DOM y analizar su contenido:
Python
news = await page.JJ('li.stream-item')
for row in news:
title = await row.J('a:not([data-test-locator])')
content = await row.J('p')
comment = await row.J('span[data-test-locator="stream-comment"]')
title_text = await page.evaluate('item => item.textContent', title)
content_text = await page.evaluate('item => item.textContent', content)
comment_text = await page.evaluate('item => item.textContent', comment)
pringt('titile: ', title_text)
pringt('content: ', content_text)
pringt('comment: ', comment_text)Por supuesto, simplemente imprimir los datos en la terminal no es nuestro objetivo final, también necesitamos guardar los datos.
Paso 5. Guardar los datos
Usamos la biblioteca json para guardar los datos en un archivo json local:
Python
news = await page.JJ('li.stream-item')
news_info = []
for row in news:
title = await row.J('a:not([data-test-locator])')
content = await row.J('p')
comment = await row.J('span[data-test-locator="stream-comment"]')
title_text = await page.evaluate('item => item.textContent', title)
content_text = await page.evaluate('item => item.textContent', content)
comment_text = await page.evaluate('item => item.textContent', comment)
news_item = {
"title": title_text,
"content": content_text,
"comment": comment_text
}
news_info.append(news_item)
# crear el archivo json
json_file = open("news.json", "w")
# convertir news_info a JSON
json.dump(news_info, json_file)
# liberar los recursos del archivo
json_file.close()Ejecuta nuestro código y luego abre la carpeta donde se encuentra el código. Verás aparecer un nuevo archivo news.json. ¡Ábrelo para verificar el contenido!
Si encuentras que se ve así:
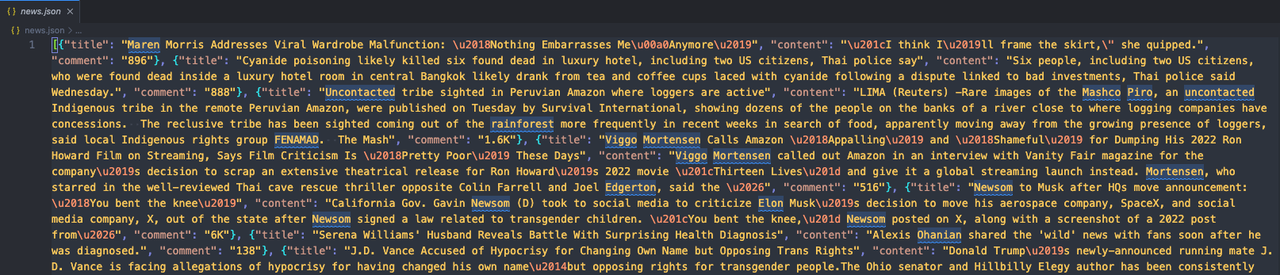
¡Significa que hemos rastreado con éxito el sitio web objetivo usando Pyppeteer y Nstbrowser!
¿Por qué el Navegador Anti-Detección es el Mejor para el Web Scraping?
Un navegador anti-detección es muy efectivo para el scraping web debido a su capacidad para simular el comportamiento de navegación humana y evadir la detección por parte de los sitios web. Permíteme mostrarte las 6 características principales:
1. Evitar el Bloqueo de IP
Los sitios web a menudo rastrean y limitan el número de solicitudes desde una sola dirección IP. Los navegadores anti-detección pueden integrarse con servicios de proxy, lo que permite a los scrapers rotar automáticamente las direcciones IP y evitar activar límites de tasa o bloqueos.
2. Eludir la Huella Digital del Navegador
Los sitios web usan huellas digitales del navegador para detectar y bloquear tráfico automatizado. El navegador anti-detección puede modificar las características del navegador, como el user-agent, la resolución de pantalla y los complementos instalados, creando huellas digitales únicas que hacen que las solicitudes automatizadas parezcan venir de diferentes usuarios humanos.
3. Interacción Similar a la Humana
Los navegadores anti-detección pueden simular interacciones humanas como movimientos del ratón, clics e ingresos de teclado. Este comportamiento puede ayudar a evadir mecanismos de detección que monitorean patrones no humanos, haciendo que el proceso de scraping parezca más natural y menos propenso a ser bloqueado.
4. Rotación de Agentes de Usuario
Cualquier navegador anti-huella digital permite la rotación de cadenas de user-agent, lo que ayuda a disfrazar la actividad de scraping. Así, las solicitudes serán reconocidas desde diferentes navegadores y dispositivos. Esta diversidad en los agentes de usuario hace que sea más difícil para los sitios web identificar y bloquear los bots de scraping.
5. Ejecución de JavaScript
Muchos sitios web modernos dependen en gran medida de JavaScript para renderizar contenido dinámicamente. Los navegadores anti-detección pueden ejecutar JavaScript, asegurando que el scraper pueda acceder e interactuar con contenido que no está disponible en el código fuente HTML inicial.
6. Resolución de Captchas
Los navegadores anti-detección a menudo admiten la integración con servicios de resolución de captchas. Esta característica es crucial para eludir los desafíos de captcha que los sitios web implementan para prevenir el scraping automatizado.
Pensamientos Finales
Con cualquier individuo esperando la oportunidad de robar tus datos y cualquier empresa preparándose para recolectar tu información para avanzar en sus propios negocios, la privacidad es vital.
Los navegadores anti-detección son una excelente manera de proteger tus datos sin ser detectado por los bots de detección. También pueden ayudarte a mejorar tus tareas de scraping web.
¡Es hora de usar Nstbrowser para ayudarte a proteger tu privacidad y realizar el rastreo web de manera rápida y eficiente!
También te puede gustar:
Gestiona múltiples cuentas con un navegador anti-detección
Más





