
Web Scraping
Error 403 Forbidden: ¿Qué es? ¿Cómo solucionarlo?
¡El error 403 es súper molesto! ¿Qué es el error 403 forbidden? ¿Cómo solucionarlo? Hay de todo en este blog.
Jul 12, 2024Robin Brown
¡El código de error 403 seguramente te resulta familiar! ¡Este error puede causar pérdida de tráfico e incluso oportunidades de negocio!
¿Qué? ¿Tienes un error 403 en tu propio sitio web? ¡Soluciónalo de inmediato! Pero, ¿cuál es la causa de este error? ¿Cómo resolverlo? Ambas preguntas son importantes y pueden resultar confusas.
¡Esta entrada de blog está aquí para ayudarte!
Al leer este blog, aprenderás:
- ¿Cuál es la causa del error 403?
- ¿Cómo solucionar el error 403?
¡Comienza a desplazarte hacia abajo ahora!
¿Qué es el error 403?
El error 403 significa que el servidor puede entender claramente tu solicitud, pero aún así no puedes acceder al sitio web objetivo. Esto generalmente se debe a permisos insuficientes del lado del servidor o credenciales de autenticación faltantes.
En otras palabras, tu servidor sabe exactamente lo que quieres hacer, pero por alguna razón no tienes los permisos necesarios.
Es como si quisieras asistir a un evento privado, pero por alguna razón, tu nombre fue eliminado erróneamente de la lista de invitados.
¿Cuál es la causa del error 403?
Cinco causas comunes del error 403:
- Permisos de archivos o carpetas incorrectos
- Archivo
.htaccessincorrecto - Problema con la dirección IP
- Conflicto de complementos
- Falta de una página de índice
1. Permisos de archivos o carpetas incorrectos
Si intentas acceder a un archivo, carpeta o incluso a un directorio completo, y el servidor no reconoce los permisos proporcionados por el cliente, se denegará el acceso.
Para evitar este error, verifica y cambia los permisos de archivos o carpetas.
Bash
# Para directorios, establece permisos a 755
chmod 755 /path/to/directory
# Para archivos, establece permisos a 644
chmod 644 /path/to/file2. Archivo .htaccess incorrecto
Un archivo .htaccess mal configurado o dañado (por ejemplo, infectado por malware) puede causar diversos problemas.
¿Cómo solucionarlo? Revisa y repara el archivo .htaccess, o crea uno nuevo.
Apache
# Ejemplo de contenido para el archivo .htaccess
<Directory "/path/to/directory">
AllowOverride All
Require all granted
</Directory>3. Problema con la dirección IP
¡Detente! ¿Una dirección IP de dominio incorrecta o expirada también puede causar el error 403? ¡Sí!
Por lo tanto, verifica la configuración DNS del dominio para asegurarte de que apunta a la dirección IP correcta.
4. Problema con complementos de WordPress
Los errores suelen aparecer cuando los usuarios intentan acceder a sitios web configurados incorrectamente por complementos de WordPress. Esto generalmente está relacionado con incompatibilidades de complementos o configuraciones incorrectas.
¡Oh! Esto también podría deberse a que el host no puede acceder a la carpeta wp-content del directorio principal de WordPress.
Es hora de deshabilitar todos los complementos y habilitarlos uno por uno para identificar cuál está causando el problema.
PHP
// Añade el siguiente código en wp-config.php para deshabilitar todos los complementos
define('WP_ALLOW_REPAIR', true);5. Falta de una página de índice
La última causa es que, si mi página de inicio del sitio web no está nombrada como "index.php" o "index.html", también me encontraré con el error 403.
Por lo tanto, necesitas asegurarte de que el archivo de la página de inicio del sitio web esté nombrado correctamente.
¿Cómo evitar fácilmente el bloqueo de sitios web para un acceso sin restricciones?
¡Empieza a usar Nstbrowser gratis ahora!
¿Tienes ideas y dudas interesantes sobre el web scraping y el Browserless?
¡Veamos qué comparten otros desarrolladores en Discord y Telegram!
10 formas del error 403
- Error 403 – Prohibido: Error de acceso general.
- 403 – Prohibido: Acceso denegado por el servidor, puede ser un problema de permisos o configuración incorrecta.
- 403 Prohibido – nginx: Error general de acceso denegado.
- Prohibido – No tienes permiso para acceder a /ruta en este servidor: Problema de permisos en el directorio raíz del servidor o falta de un archivo de índice.
- 403 – Error prohibido – No tienes permiso para acceder a esta dirección: Acceso denegado a una dirección específica.
- Error HTTP 403 – Prohibido – No tienes permiso para acceder al documento o programa solicitado: Acceso deshabilitado al documento o programa solicitado.
- 403 Prohibido – El acceso al recurso en este servidor está prohibido: Acceso prohibido al recurso en el servidor.
- 403. Esto es un error. Tu cliente no tiene permiso para obtener la URL / de este servidor: El cliente no tiene permiso para acceder a la URL especificada.
- No tienes permiso para ver esta página: No tienes permiso para ver la página.
- Parece que no tienes permiso para acceder a esta página: No tienes permiso para acceder a la página objetivo.
¿Cómo solucionar el error 403?
¿Cómo evitar el error 403? ¡Aquí hay cinco métodos!
Método 1. Evita el error 403 usando Nstbrowser:
El método más efectivo es usar un navegador antidetec para evitar el error 403. ¡Está equipado con múltiples medidas antirrobot!
Nstbrowser ofrece la solución más completa, incluyendo renderizado de JavaScript, rotación inteligente de proxy y detección de robots efectiva. Esto te ayuda a evitar el error 403 y no ser bloqueado.
Opción 1: Crea diferentes huellas dactilares del navegador
Nstbrowser proporciona huellas dactilares de navegador realistas, lo cual puede resolver el error 403 en solo tres pasos después de registrarse:
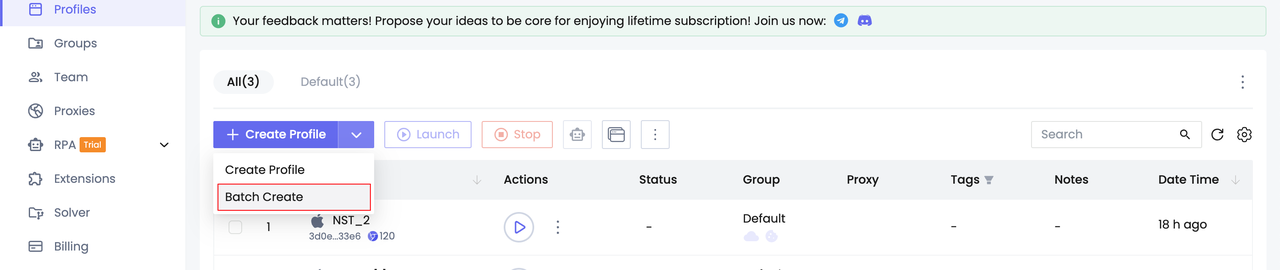
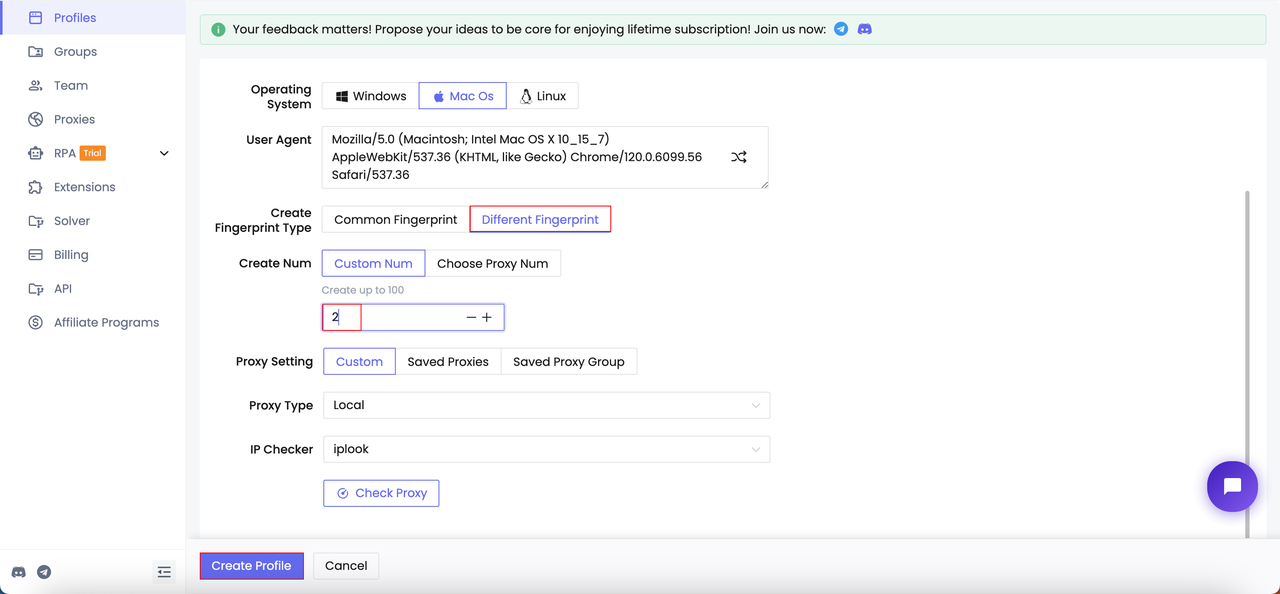
Paso 1. Crea múltiples perfiles
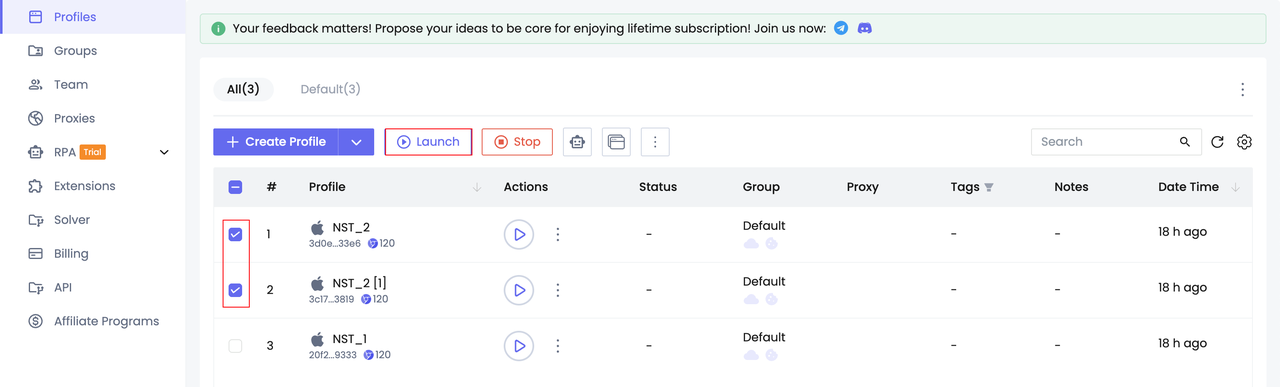
Paso 2. Inicia el perfil
Paso 3. Accede al sitio web objetivo
Opción 2: Obtén un proxy dinámico
También puedes usar Nstbrowser para configurar un proxy en tus perfiles, logrando proxies dinámicos en masa para evitar que tu navegador reciba advertencias de error 403. Solo necesitas seguir estos pasos:
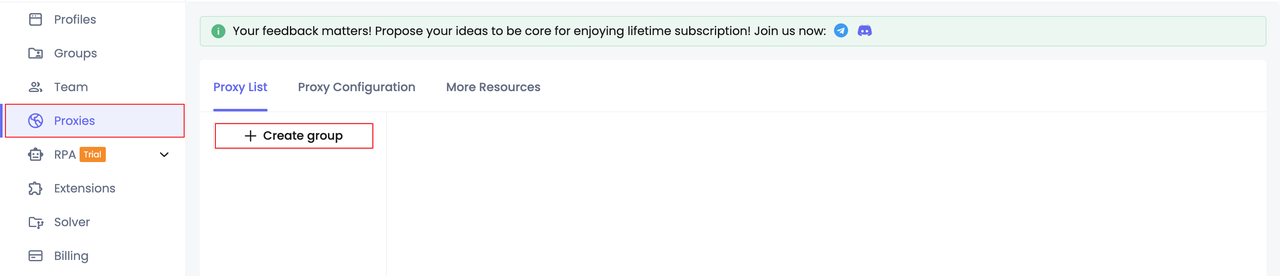
Paso 1. Configura el grupo de proxies
- Crear grupo de proxies
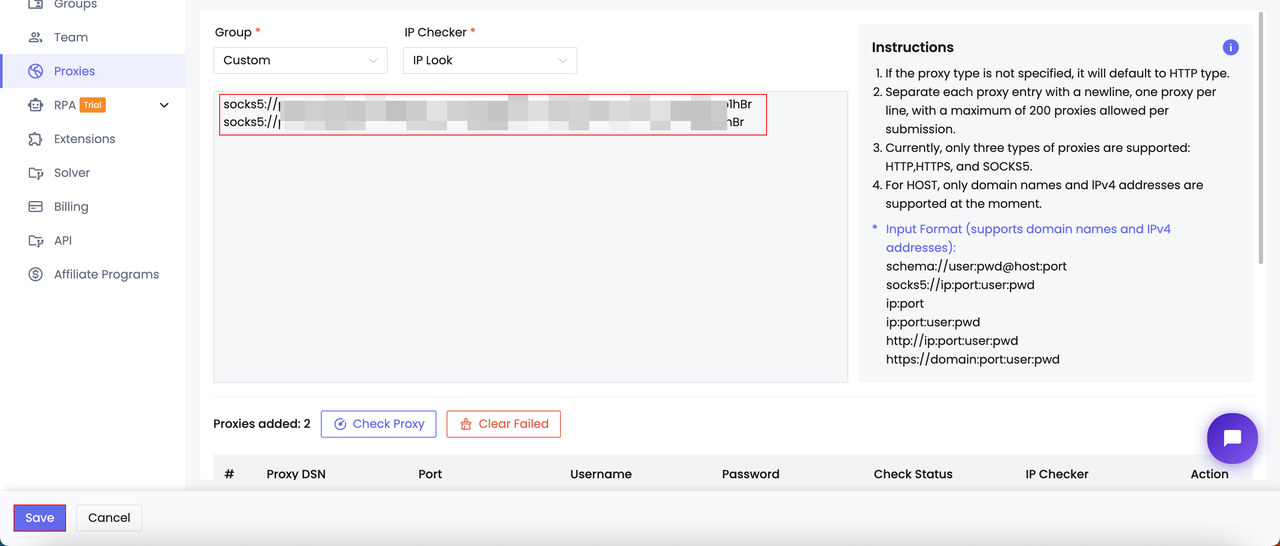
- Añadir proxies

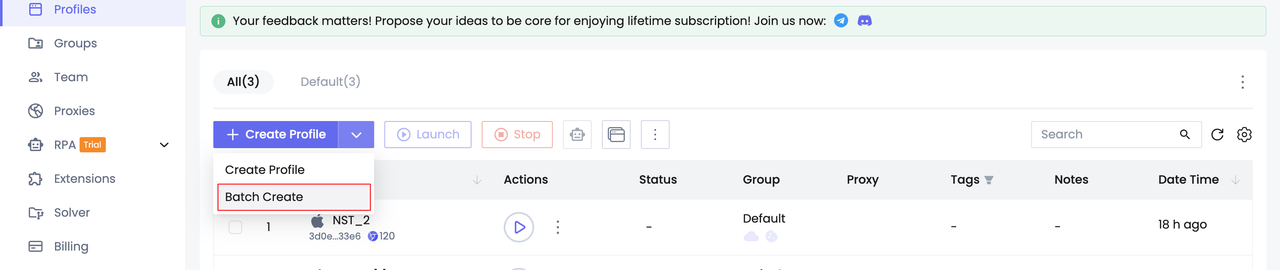
- Crear perfiles
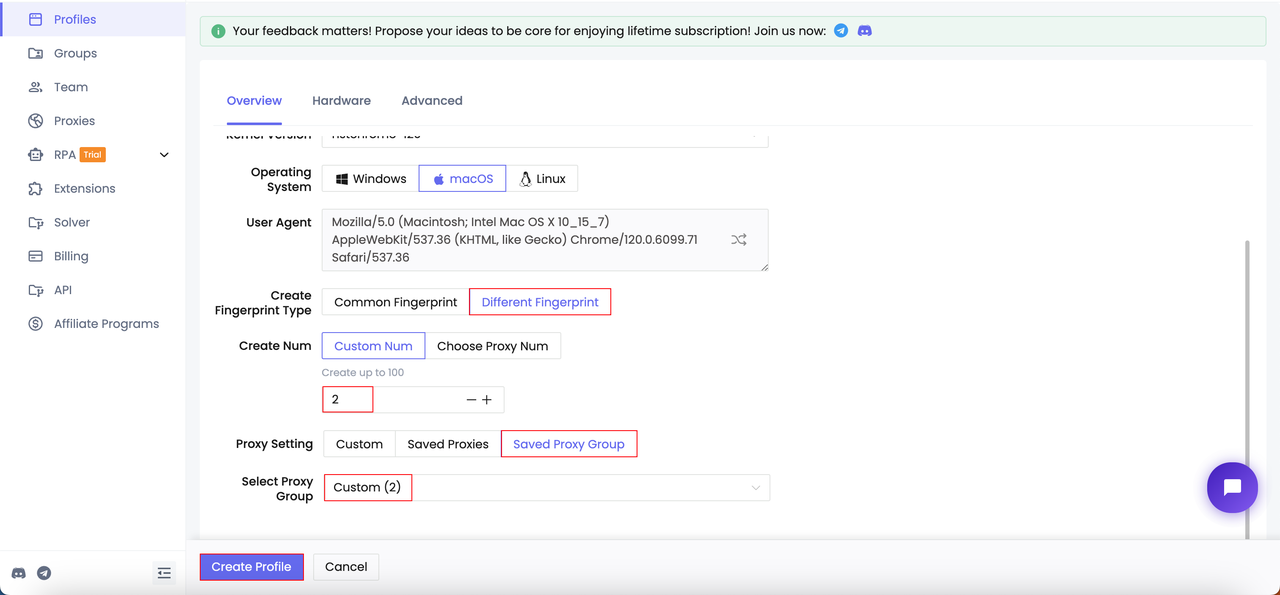
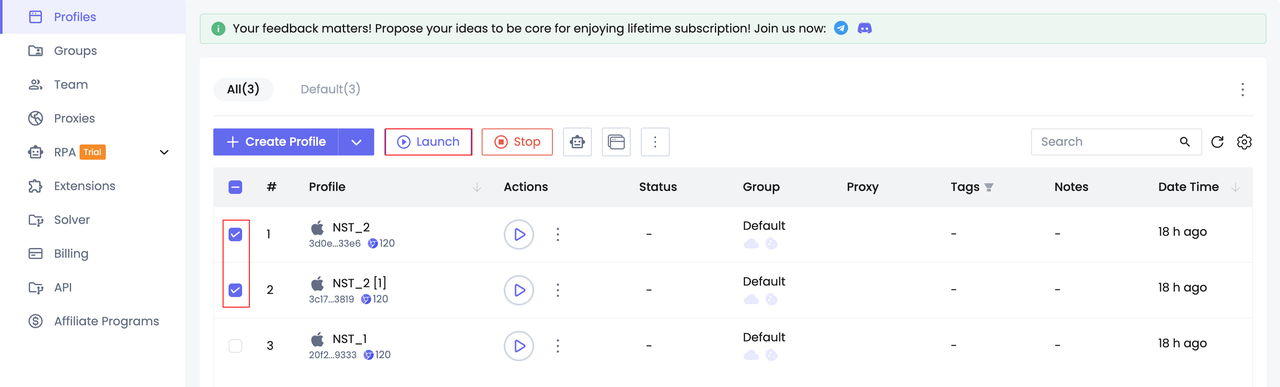
Paso 2. Inicia el perfil
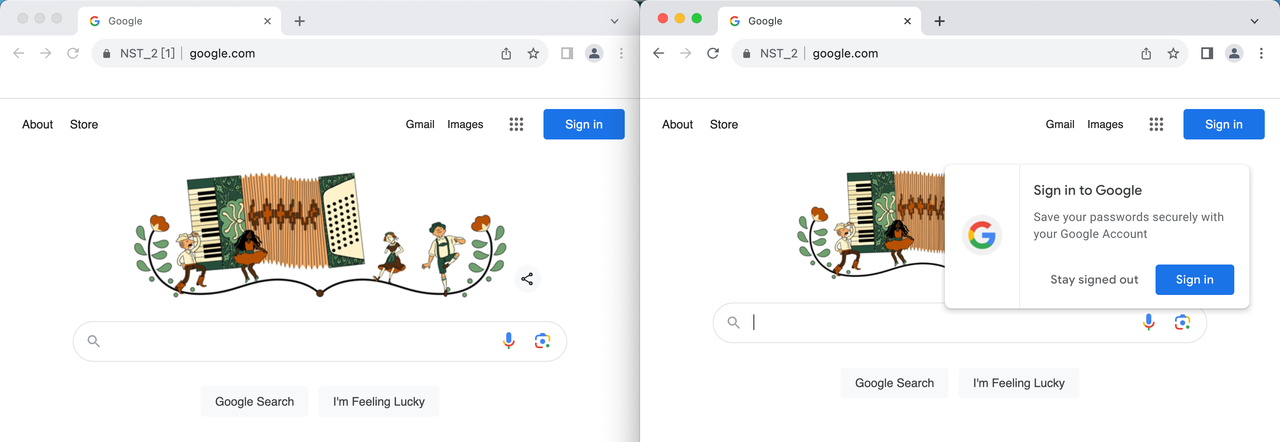
Paso 3. Accede al sitio web objetivo
Método 2. Falsificar el UserAgent
Dado que los servidores pueden decidir si permitir el acceso en función del user agent, falsificar el user agent puede ayudar en algunos casos a evitar el error HTTP 403.
- Usando la biblioteca requests
Python
import requests
url = 'http://example.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
print(response.status_code)
print(response.text)- Usando Puppeteer
JavaScript
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36');
await page.goto('http://example.com');
const content = await page.content();
console.log(content);
await browser.close();
})();Método 3. Completar los encabezados de la solicitud
Cuando se realizan solicitudes usando Selenium y Python Requests, los encabezados predeterminados pueden no contener todos los datos comunes de las solicitudes de usuarios.
Esto puede hacer que tu solicitud parezca muy sospechosa. Por lo tanto, es muy probable que encuentres un error 403.
Por lo tanto, al usar herramientas de automatización, el paso más importante es completar los encabezados de la solicitud para simular las solicitudes de un usuario real.
- User-Agent: Identifica el tipo de aplicación cliente, el sistema operativo, el proveedor del software o la versión del software.
- Referer: Indica la URL desde la que se realizó la solicitud.
- Accept: Indica los tipos de contenido que puede manejar el cliente.
- Accept-Language: El idioma natural preferido del cliente.
- Accept-Encoding: Los tipos de codificación de contenido que el cliente puede manejar.
- Connection: Controla la forma en que se manejan las conexiones (por ejemplo, mantener la conexión activa).
- Cache-Control: Mecanismo de caché utilizado para las solicitudes y respuestas.
- Host: Nombre de dominio y número de puerto del servidor.
- Upgrade-Insecure-Requests: Indica que el cliente desea que el servidor actualice a HTTPS.
Método 4. Evitar el bloqueo de IP
En un período de tiempo determinado, realizar múltiples solicitudes desde la misma dirección IP probablemente resultará en el bloqueo de la IP.
La mayoría de los sitios web utilizan limitación de velocidad para controlar el tráfico y el uso de recursos. Por lo tanto, exceder los límites establecidos por el sitio web resultará en un bloqueo.
En este caso, puedes prevenir el bloqueo de IP configurando intervalos o retrasos entre solicitudes consecutivas e implementando limitaciones de velocidad (limitando la cantidad de solicitudes que se pueden enviar en un período de tiempo específico).
Cambia IPs automáticamente para evitar el bloqueo de IP y sortear fácilmente el error 403.
¡Empieza a usar Nstbrowser gratis ahora!
- JavaScript
En Node.js, puedes usar la función setTimeout() para introducir un retraso:
JavaScript
const axios = require('axios');
const url = 'http://example.com';
const headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
};
// Definir el rango de tiempo de retraso aleatorio
const minDelay = 1000; // Tiempo mínimo de retraso (milisegundos)
const maxDelay = 5000; // Tiempo máximo de retraso (milisegundos)
// Hacer la solicitud
axios.get(url, { headers })
.then(response => {
console.log(response.data);
})
.catch(error => {
console.error(error);
})
.finally(() => {
// Esperar un tiempo aleatorio antes de hacer la siguiente solicitud
const delay = Math.random() * (maxDelay - minDelay) + minDelay;
setTimeout(() => {
// Hacer la siguiente solicitud u otras acciones
}, delay);
});- Python
En Python, usa la función time.sleep() para introducir un retraso aleatorio:
Python
import requests
import time
import random
url = 'http://example.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# Definir el rango de tiempo de retraso aleatorio
min_delay = 1 # Tiempo mínimo de retraso (segundos)
max_delay = 5 # Tiempo máximo de retraso (segundos)
# Hacer la solicitud
response = requests.get(url, headers=headers)
# Procesar la respuesta
print(response.status_code)
print(response.text)
# Esperar un tiempo aleatorio antes de hacer la siguiente solicitud
delay = random.uniform(min_delay, max_delay)
time.sleep(delay)Método 5. Usar Nstbrowserless
Nstbrowserless es un navegador sin cabeza que puede sortear fácilmente el error HTTP 403. La clave es configurar correctamente los encabezados de solicitud y simular el comportamiento humano para evitar que el servidor te detecte como un bot.
- Configurar los encabezados de solicitud: Asegúrate de configurar los campos User-Agent, Referer, etc., para simular el acceso de un usuario real.
- Simular el comportamiento humano: Introduce intervalos aleatorios, movimientos del mouse, clics, etc., para simular el modo de operación humana al ejecutar tareas de scraping web o automatización.
- Manejar la renderización de JavaScript: Nstbrowserless puede manejar la renderización de JavaScript para asegurar que el contenido de la página se cargue completamente.
- Evitar solicitudes frecuentes: Configura una frecuencia de solicitudes adecuada para evitar enviar solicitudes demasiado frecuentes al mismo sitio web.
Conclusión
El error 403 significa: sé quién eres, pero no tienes permiso para acceder aquí.
Hay 5 formas efectivas de solucionar este problema, pero la más efectiva es usar Nstbrowser.
Evita fácilmente la detección a través de una potente rotación de IPs y funciones de desbloqueo de sitios web, asegurando que no encuentres errores 403.
Más





