
Web Scraping
Rastreador web en Java: tutorial paso a paso 2024
El rastreador web de Java facilita las tareas de extracción de datos web y automatización. ¿Cómo hacer extracción de datos web con el rastreador web de Java? ¡Aquí tienes todo lo que te gustará!
Aug 16, 2024Robin Brown
¿Cuál es la forma más eficiente de obtener información útil de un sitio web? ¡Obviamente, es un rastreador web en Java!
En este blog, aprenderás:
- ¿Cuál es la diferencia entre un rastreador web y un extractor de datos?
- ¿Cómo usar Jsoup para analizar y extraer datos de las páginas web?
- ¿Cómo evitar la detección y mejorar la eficiencia y estabilidad del rastreo?
¿Puedes hacer web scraping con Java?
¡Sí! Como un lenguaje de programación maduro y ampliamente utilizado, Java ofrece un soporte poderoso que hace que el web scraping sea eficiente y confiable, y Java puede depender de una variedad de bibliotecas. Esto significa que puedes elegir entre múltiples bibliotecas de web scraping en Java.
Aquí tienes algunas de las principales ventajas del web scraping con Java:
- Bibliotecas y marcos de trabajo ricos. Java proporciona bibliotecas y marcos de trabajo poderosos como Jsoup, Selenium y Apache HttpClient. Estos pueden ayudar a los desarrolladores a extraer y analizar datos web con facilidad.
- Excelente rendimiento. La eficiente gestión de memoria y el soporte para multihilos en Java le permiten desempeñarse bien cuando se procesa una gran cantidad de datos.
- Capacidades multiplataforma. Java es independiente de la plataforma. Esto significa que puede ejecutarse en diferentes sistemas operativos, ya sea en Windows, Linux o macOS, garantizando la consistencia y compatibilidad de las herramientas de scraping.
- Capacidades de procesamiento de datos potentes. Las capacidades de procesamiento de datos de Java son muy poderosas y pueden manejar fácilmente estructuras de datos complejas y grandes conjuntos de datos. Ya sea un análisis de texto simple o una conversión de datos compleja, Java puede proporcionar soluciones eficientes.
- Seguridad. Las características de seguridad de Java, como el modelo de sandbox y el gestor de seguridad, ofrecen protección adicional para los rastreadores en un entorno de red, por lo que la seguridad de tu sistema no se ve amenazada.
Con estas ventajas, Java es una opción ideal para construir herramientas de rastreo web robustas y eficientes. Ya sea rastreando datos web estáticos o procesando contenido dinámico, Java puede proporcionar a los desarrolladores una solución confiable.
¿Qué es un rastreador web en Java?
En Java, un rastreador web es un programa automatizado utilizado para recopilar datos de Internet. Extrae información de las páginas web simulando el proceso de los usuarios al visitar dichas páginas, y la almacena o procesa para su uso posterior.
Las funciones principales de un rastreador en Java son:
- Enviar solicitudes HTTP. A través de la biblioteca de clientes HTTP de Java (como HttpURLConnection o Apache HttpClient), el rastreador puede enviar solicitudes al sitio web objetivo para obtener el contenido de las páginas.
- Analizar el contenido de la página web. Utilizando bibliotecas de análisis HTML (como Jsoup), se analiza el contenido de la página en una estructura DOM operable para extraer la información requerida.
- Procesar datos. La información extraída puede ser procesada, almacenada o analizada. Por ejemplo, guardar datos en una base de datos, generar informes o realizar análisis estadísticos.
- Seguir enlaces. Un rastreador puede seguir enlaces en una página web y rastrear recursivamente varias páginas web para obtener datos más completos.
Principal diferencia entre un extractor de datos y un rastreador web
El objetivo del web scraping es extraer datos de páginas web, mientras que el objetivo del rastreo web es indexar y encontrar páginas web.
El web scraping implica escribir un programa que pueda recopilar datos de múltiples sitios web de manera encubierta. En contraste, el rastreo web implica seguir permanentemente enlaces basados en hipervínculos.
¿Tienes alguna idea maravillosa o dudas sobre el web scraping y Browserless?
¡Veamos lo que otros desarrolladores están compartiendo en Discord y Telegram!
¿Cómo hacer web scraping con Jsoup y la API de Nstbrowser?
Tomemos el ejemplo de extraer la información básica y los precios de las criptomonedas en la página principal de CoinmarketCap para demostrar cómo usar Jsoup y Selenium en un rastreador web en Java a través de la API de Nstbrowser, utilizando específicamente la API de LaunchExistBrowser.
Antes de comenzar a rastrear datos, necesitamos:
- Descargar e instalar Nstbrowser de antemano y generar tu clave API.
- Crear un perfil y hacer clic para iniciar el perfil para descargar automáticamente la versión correspondiente del kernel.
- El único paso que queda es descargar el chromedriver de la versión del kernel correspondiente antes de usar selenium, lo cual se puede consultar en: Cómo usar Selenium en Nstbrowser.
Análisis de la página
Comencemos analizando el sitio y veamos cómo se ve la página que queremos rastrear:
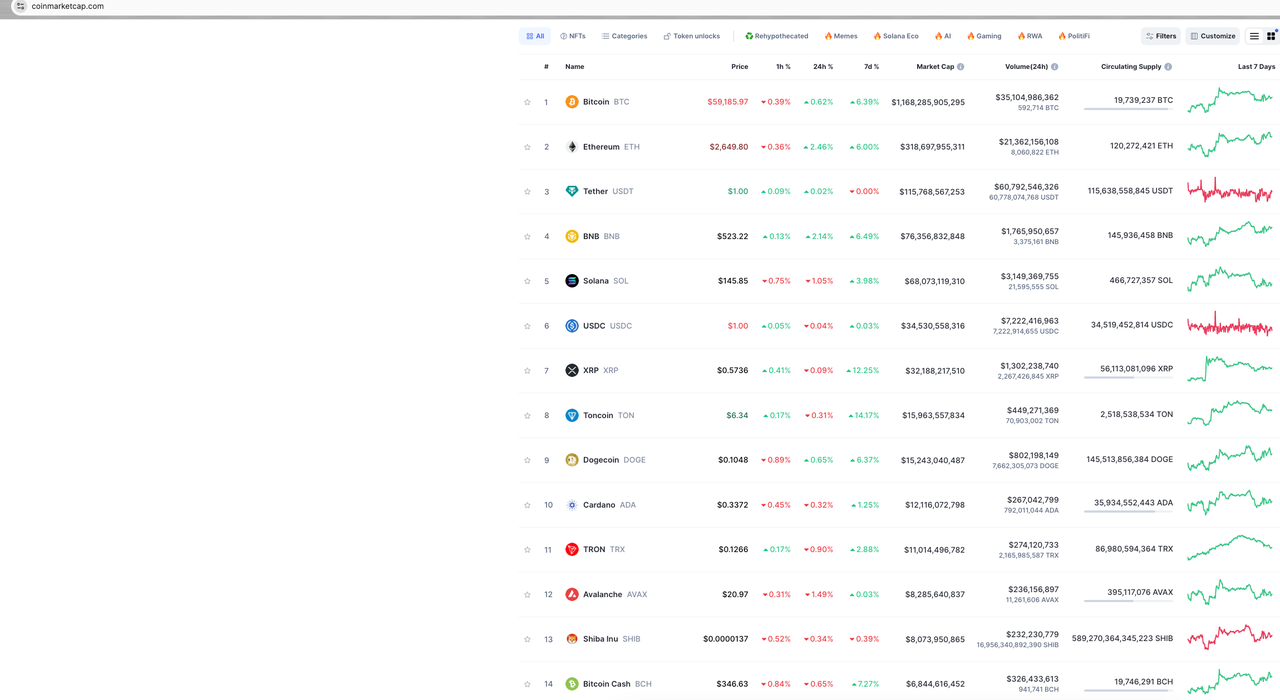
Nuestros datos objetivo son los datos en la página principal de CoinmarketCap. Aquí solo capturamos algunos de los datos para la demostración, como el ranking de criptomonedas, los logotipos de criptomonedas, las monedas de criptomonedas y los precios de las monedas.
A continuación, analizaremos cada dato necesario paso a paso.
Paso 1. Abre la consola del navegador y comienza a ver los elementos de la página:
Análisis general
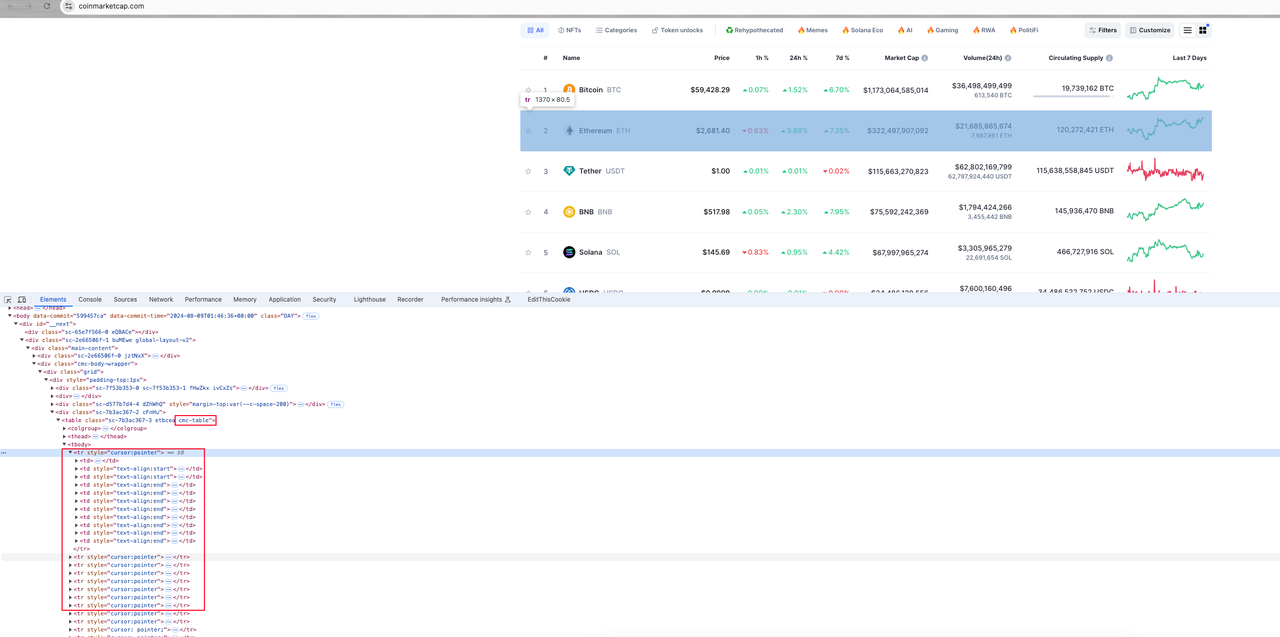
Toda la información de la moneda en la página está contenida en un elemento table con un nombre de clase cmc-rable. El elemento de fila de la tabla tr en el elemento table corresponde a la información de cada moneda. Cada fila de la tabla contiene varios elementos de columna de la tabla td. Nuestro objetivo es analizar los datos deseados desde estos elementos td.
Paso 2. Buscaremos y analizaremos cada dato objetivo:
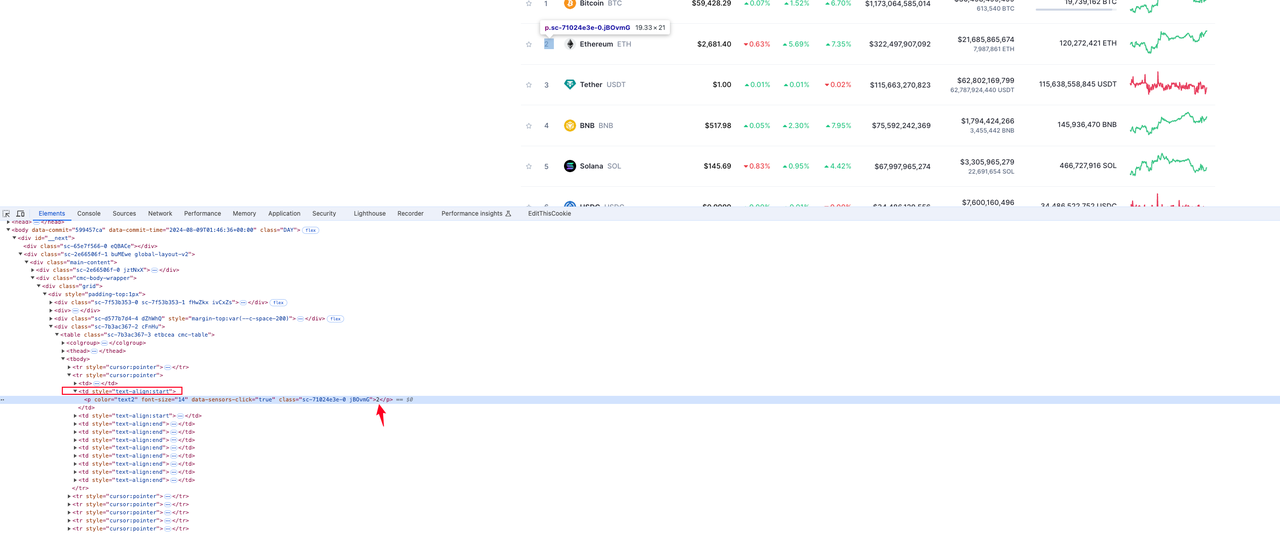
Ranking de la moneda
En la imagen a continuación, podemos ver que el elemento donde se encuentra la clasificación de la moneda está en el valor de la etiqueta p bajo el segundo td en tr:
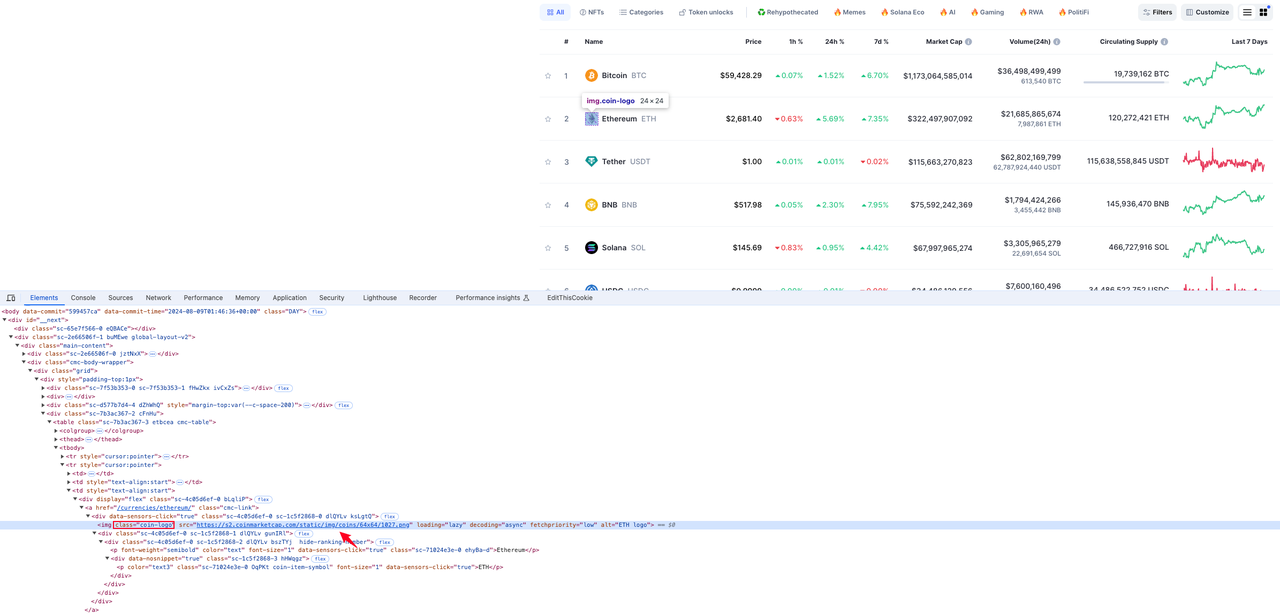
Logotipo de la moneda
El elemento donde se encuentra el icono del logotipo de la moneda está en el valor del atributo src de la etiqueta img con el nombre de clase coin-logo en el elemento tr de la fila:
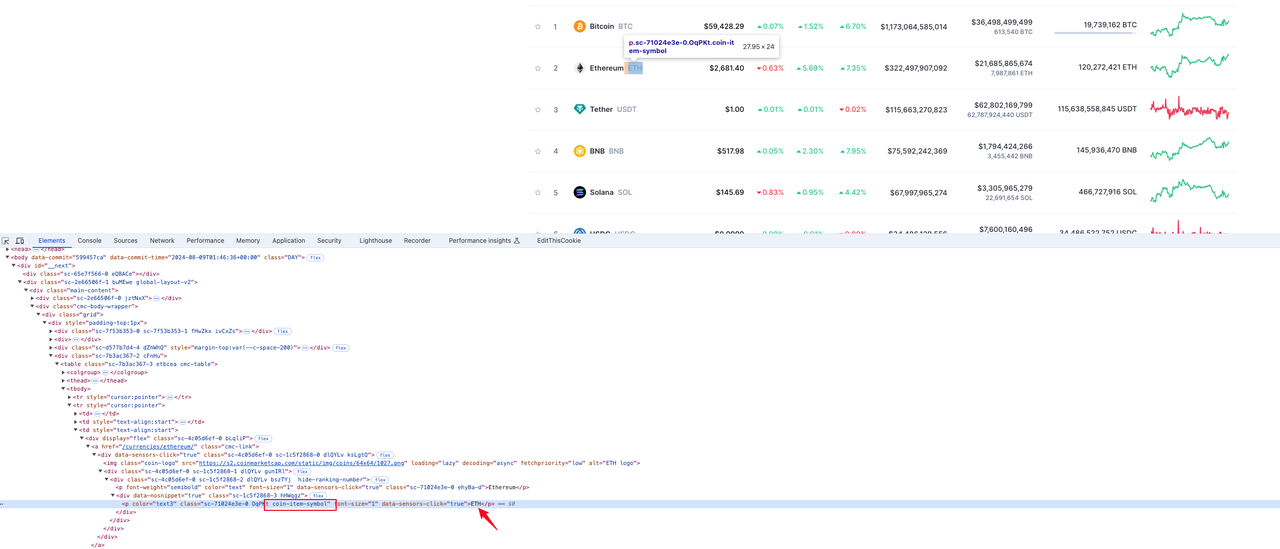
Símbolo de la moneda
El elemento donde se encuentra la información de la moneda está en el valor de la etiqueta p con el nombre de clase coin-item-symbol en el elemento tr de la fila:
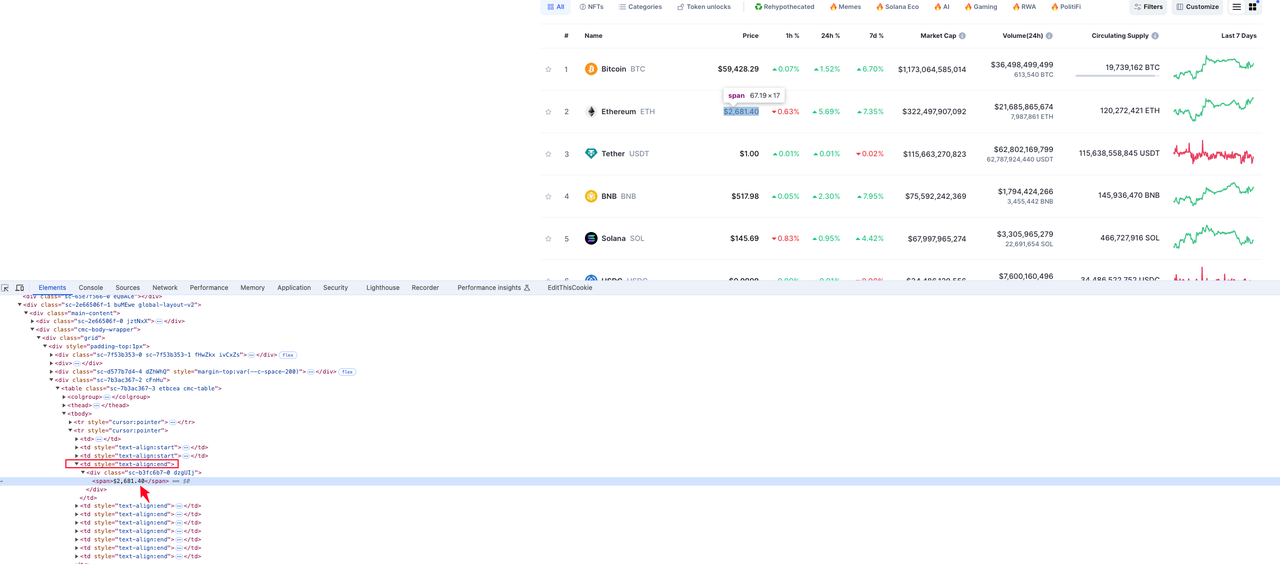
Precio de la moneda
El elemento donde se encuentra la información de la moneda está en el valor del elemento div span bajo el cuarto elemento td en el elemento tr de la fila:
Después del análisis, hemos obtenido los elementos donde se encuentran los datos objetivo deseados. Puedes estudiar más análisis de elementos de datos por ti mismo.
Codificación
Sin más preámbulos, vamos directamente al código:
dependencias (build.gradle)
Java
dependencies {
implementation 'com.squareup.okhttp3:okhttp:4.12.0'
implementation 'com.google.code.gson:gson:2.10.1'
implementation 'org.jsoup:jsoup:1.17.2'
implementation "org.seleniumhq.selenium:selenium-java:4.14.1"
}CmcRank.java
Java
public class CMCRank {
// rango de la moneda
private Integer rank;
// símbolo de la moneda
private String coinSymbol;
// logo de la moneda
private String coinLogo;
// precio de la moneda
private String price;
// getters y setters omitidos
}CmcScraper.java
Java
import com.google.gson.Gson;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
import org.openqa.selenium.*;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class CmcScraper {
// cliente http
private static final OkHttpClient client = new OkHttpClient();
// gson
private static final Gson gson = new Gson();
// tu apiKey
private static final String API_KEY = "tu apikey";
// tu profileId
private static final String PROFILE_ID = "tu profileId";
// url del sitio web de cmc
private static final String BASE_URL = "https://coinmarketcap.com";
// url base de la API de nstbrowser
private final String baseUrl;
// ruta del archivo webdriver
private final String webdriverPath;
public CmcScraper(String baseUrl, String webdriverPath) {
this.baseUrl = baseUrl;
this.webdriverPath = webdriverPath;
}
public void scrape() {
String url = String.format("%s/devtool/launch/%s", this.baseUrl, PROFILE_ID);
Request request = new Request.Builder()
.url(url)
.get()
.addHeader("Content-Type", "application/json")
.addHeader("x-api-key", API_KEY)
.build();
try (Response response = client.newCall(request).execute()) {
if (!response.isSuccessful()) {
throw new IOException("Código inesperado " + response);
}
Map<String, Object> responseBody = gson.fromJson(response.body().string(), Map.class);
Map<String, Object> data = (Map<String, Object>) responseBody.get("data");
Double port = (Double) data.get("port"); // obtener el puerto del navegador
if (port != null) {
this.execSelenium("localhost:" + port.intValue());
} else {
throw new IOException("Puerto no encontrado en la respuesta");
}
} catch (IOException e) {
throw new RuntimeException("Fallo al hacer scraping", e);
}
}
public void execSelenium(String debuggerAddress) {
System.setProperty("webdriver.chrome.driver", this.webdriverPath);
ChromeOptions options = new ChromeOptions();
options.setExperimentalOption("debuggerAddress", debuggerAddress);
try {
WebDriver driver = new ChromeDriver(options);
driver.get(BASE_URL);
WebElement cmcTable = driver.findElement(By.cssSelector("table.cmc-table"));
if (cmcTable != null) {
List<WebElement> tableRows = cmcTable.findElements(By.cssSelector("tbody tr"));
List<CMCRank> cmcRanks = new ArrayList<>(tableRows.size());
for (WebElement row : tableRows) {
CMCRank cmcRank = extractCMCRank(row);
if (cmcRank != null) {
System.out.println(gson.toJson(cmcRank));
cmcRanks.add(cmcRank);
}
}
// TODO
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
private CMCRank extractCMCRank(WebElement row) {
try {
CMCRank cmcRank = new CMCRank();
List<WebElement> tds = row.findElements(By.tagName("td"));
if (tds.size() > 1) {
WebElement rankElem = tds.get(1).findElement(By.tagName("p"));
// encontrar rango de la moneda
if (rankElem != null && !rankElem.getText().isEmpty()) {
cmcRank.setRank(Integer.valueOf(rankElem.getText()));
}
// encontrar logo de la moneda
WebElement logoElem = row.findElement(By.cssSelector("img.coin-logo"));
if (logoElem != null) {
cmcRank.setCoinLogo(logoElem.getAttribute("src"));
}
// encontrar símbolo de la moneda
WebElement symbolElem = row.findElement(By.cssSelector("p.coin-item-symbol"));
if (symbolElem != null && !symbolElem.getText().isEmpty()) {
cmcRank.setCoinSymbol(symbolElem.getText());
}
// encontrar precio de la moneda
WebElement priceElem = tds.get(3).findElement(By.cssSelector("div span"));
if (priceElem != null) {
cmcRank.setPrice(priceElem.getText());
}
}
return cmcRank;
} catch (NoSuchElementException e) {
System.err.println("Fallo al extraer la información de la moneda: " + e.getMessage());
return null;
}
}
}Main.java
Java
public class Main {
public static void main(String[] args) {
String baseUrl = "http://localhost:8848";
String webdriverPath = "ruta de tu archivo chromedriver";
CmcScraper scraper = new CmcScraper(baseUrl, webdriverPath);
scraper.scrape();
}
}Ejecuta el programa
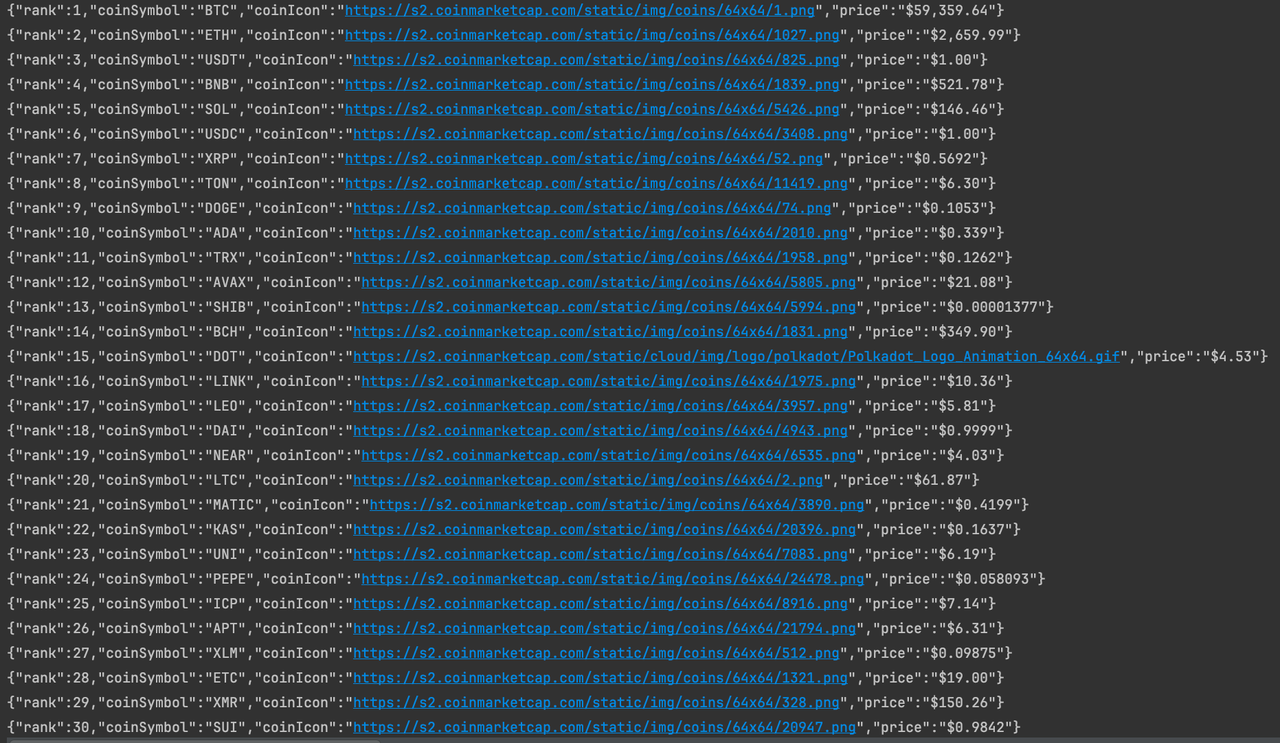
Hasta ahora, hemos recopilado con éxito los datos de información de monedas en la página de inicio de CoinmarketCap. Si estás interesado, puedes analizar la página en profundidad para recopilar más datos.
Es Un Wrap
¿Por qué Java es un excelente lenguaje de programación para el rastreo web? ¿Cómo rastrear un sitio web completo utilizando Java? ¿Cuál es la diferencia entre un rastreador web y la extracción web? No importa, has aprendido todo lo que necesitas saber para realizar un rastreo web profesional con Java en este blog.
Sin embargo, lo más importante al hacer rastreo web es: tu rastreador web debe ser capaz de eludir los sistemas anti-bot. Por eso necesitas un navegador anti-detect que pueda eludir el bloqueo de sitios web.
Nstbrowser proporciona todo lo maravilloso para el scraping web.
Más





