
Web Scraping
Cómo hacer web scraping en Golang usando Colly?
Golang es una de las herramientas más poderosas para el scraping web. Y Colly ayuda mucho cuando se usa Go. Lee este blog y encuentra la información más detallada sobre Colly y aprende cómo raspar sitios web con Colly.
Sep 30, 2024Carlos Rivera
¿Qué es Colly?
Go es un lenguaje versátil con paquetes y marcos que pueden hacer casi cualquier cosa.
Hoy, utilizaremos un marco llamado Colly, que es un marco de raspado web eficiente y poderoso escrito en Go para raspar datos en la web. Proporciona una API simple y fácil de usar que permite a los desarrolladores construir rápidamente rastreadores para visitar páginas web y extraer la información requerida.
¿Qué es Colly?
Colly proporciona un conjunto de herramientas convenientes y potentes para extraer datos de sitios web, automatizar interacciones de red y construir herramientas de raspado web.
En este artículo, obtendrá experiencia práctica utilizando Colly y aprenderá cómo raspar datos de la web con Golang: Colly.
¿Cómo funciona Colly?
La parte central de Colly es Collector. Es responsable de ejecutar solicitudes HTTP y le permite definir cómo manejar las solicitudes y respuestas. Llamando a c := colly.NewCollector(), puede crear una nueva instancia de Collector, que luego se puede usar para iniciar solicitudes de red y procesar datos.
Funciones principales:
1. Métodos Visit y Request:
Visit: Este es el método de solicitud más utilizado, que accede directamente a la página web de destino.Request: Le permite adjuntar información adicional (como encabezados o parámetros personalizados) al enviar una solicitud, que se utiliza para escenarios de solicitud más complejos.
2. Mecanismo de devolución de llamada: Colly se basa en funciones de devolución de llamada para ejecutar en diferentes etapas del ciclo de vida de la solicitud. Collector proporciona una variedad de métodos de registro de devolución de llamada, principalmente incluyendo los siguientes seis:
OnRequest: Se activa antes de enviar una solicitud HTTP, puede agregar encabezados personalizados, imprimir información de la solicitud, etc.OnError: Se activa cuando ocurre un error durante el proceso de solicitud, se utiliza para capturar y manejar errores de solicitud.OnResponse: Se activa después de recibir la respuesta del servidor, que se puede utilizar para procesar los datos de la respuesta.OnHTML: Se activa cuando se recibe el contenido HTML y coincide con el selector CSS especificado, se utiliza para extraer datos de páginas HTML.OnXML: Se activa cuando el contenido de la respuesta es XML o HTML y se puede utilizar para procesar contenido con formato XML.OnScraped: Se activa después de que se procesan todos los datos solicitados y es la devolución de llamada al final de la tarea de rastreo.
3. Devolución de llamada OnHTML:
- La función de devolución de llamada más utilizada, registrada utilizando CSS Selector, cuando Colly encuentra un elemento coincidente en el DOM HTML, se llama a la función de devolución de llamada registrada.
- Colly utiliza la biblioteca
goquerypara analizar HTML y hacer coincidir los selectores CSS, y la APIgoqueryes similar a jQuery, por lo que se pueden utilizar los selectores de estilo jQuery para extraer datos de la página.
¿Tiene alguna idea maravillosa y dudas sobre el raspado web y Browserless?
¡Veamos qué están compartiendo otros desarrolladores en Discord y Telegram!
¿Cómo raspar datos de la web con Golang?
Paso 1. Preparación del entorno
Instalación de Golang
Vaya al sitio web oficial de Golang, y seleccione la versión adecuada para descargar e instalar. Recomendamos go1.20+. Este tutorial utiliza go1.23.1.
Una vez completada la instalación, puede verificar si la instalación fue exitosa utilizando el terminal:
Shell
go versionLa salida exitosa de la información de la versión de go indica que la instalación fue exitosa.
Elija un IDE adecuado
Elija un IDE adecuado de acuerdo con sus preferencias. Se recomienda Visual Studio.
Paso 2. Construcción del proyecto
A continuación, comience a crear un proyecto.
- Cree un directorio de proyecto:
Shell
mkdir gocolly-browserless && cd gocolly-browserless- Inicialice el proyecto Go:
Shell
go mod init colly-scraperEl comando anterior ejecuta go mod init para inicializar un proyecto go llamado colly-scraper, y genera un archivo go.mod en el directorio del proyecto con el siguiente contenido:
Go
module colly-scraper
go 1.23.1- Luego cree
main.goy cree el método principal:
Go
package main
import "fmt"
func main() {
fmt.Println("¡Hola Nstbrowser!")
}- Ejecute el método principal:
Shell
go run main.goSi ve la información impresa con éxito, significa que la operación fue exitosa. El proyecto se ha construido correctamente.
Paso 3. Use Colly
¡Bien hecho! Todas las preparaciones se han completado. A continuación, comenzaremos oficialmente a utilizar Colly para completar algunos raspados de datos simples.
Instalar Colly
Ingrese el siguiente comando en la ruta raíz del proyecto para completar la instalación de Colly:
Shell
go get github.com/gocolly/collySi el proceso de instalación informa un error de que la versión actual de go no es compatible, puede optar por instalar una versión inferior de Colly o actualizar Golang a la versión correspondiente. Después de instalar Colly, el go.mod es el siguiente:
Go
module colly-scraper
go 1.23.1
require (
github.com/gocolly/colly v1.2.0 // indirecto
...
)Principio central
El principio de funcionamiento central de Colly es obtener el contenido de la página web a través de solicitudes HTTP y luego analizar la estructura DOM en la página web para extraer los datos específicos que necesitamos. Su flujo de trabajo se puede dividir en los siguientes pasos:
- Crear Collector: Este es el objeto central utilizado por Colly para iniciar solicitudes HTTP y procesar respuestas.
- Definir funciones de devolución de llamada: Colly procesa elementos o eventos específicos (como hacer clic en enlaces, analizar formularios, etc.) al analizar HTML registrando funciones de devolución de llamada.
- Visitar el sitio web de destino: Llamando al método Visit(), el Collector iniciará una solicitud a la URL especificada.
- Procesar los datos de la respuesta: Procesar los datos HTML en la función de devolución de llamada para extraer la información requerida.
Ejemplo de inicio
El siguiente es un simple ejemplo de visitar el sitio web oficial de Nstbrowser
Go
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
// Crea un nuevo recolector
c := colly.NewCollector()
// Función de devolución de llamada, invocada cuando el rastreador encuentra un elemento <title>
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Título de la página:", e.Text)
})
// Manejar errores
c.OnError(func(_ *colly.Response, err error) {
fmt.Println("Error:", err)
})
// Visita la página de destino
c.Visit("https://nstbrowser.io")
}Después de ejecutar el código anterior, el rastreador imprimirá el contenido del elemento title de la página. Este es el flujo de trabajo básico de Colly, que le permite analizar fácilmente HTML y extraer la información que necesita. Ejecutar go run main.go imprimirá información similar a la siguiente:
Plain Text
Título de la página: Nstbrowser - Navegador Anti-Detect Avanzado para Raspado Web y Gestión de Múltiples CuentasConfiguraciones comunes
Colly es un marco de rastreo Golang potente y flexible que puede controlar el comportamiento del rastreador mediante la configuración. A continuación, se presentarán las opciones de configuración comúnmente utilizadas en Colly en detalle, y se explicarán sus escenarios de uso y métodos de implementación.
- Configuración del recolector
El colly.NewCollector se utiliza para crear una nueva instancia de Collector, que es la parte central del rastreador. Al pasar diferentes opciones de configuración, puede personalizar el comportamiento del rastreador, como limitar los nombres de dominio rastreados, la profundidad máxima de rastreo, el rastreo asincrónico, etc.
Ejemplo
Go
c := colly.NewCollector(
colly.AllowedDomains("example.com"), // Restringir a ciertos dominios
colly.MaxDepth(3), // Limitar la profundidad del rastreo
colly.Async(true), // Habilitar el raspado asincrónico
colly.IgnoreRobotsTxt(), // Ignorar las reglas de robots.txt
colly.DisallowedURLFilters(regexp.MustCompile(".*.jpg")), // Omitir ciertas URL
...
)- Configuración de la solicitud
Colly proporciona varios métodos para configurar el comportamiento de la solicitud HTTP, como establecer encabezados de solicitud personalizados, proxys, cookies, etc. A través de estas configuraciones, el rastreador puede simular el comportamiento de los usuarios reales y eludir algunos mecanismos anti-rastreadores.
Encabezado UA personalizado
Puede establecer información de encabezado HTTP personalizada para cada solicitud a través del método Headers.Set. Por ejemplo, establezca User-Agent para simular el comportamiento de acceso del navegador para evitar ser interceptado por mecanismos anti-rastreadores.
Go
c.OnRequest(func(r *colly.Request) {
r.Headers.Set("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
...
})Gestión de cookies
Colly maneja las cookies automáticamente de forma predeterminada, pero también puede establecer manualmente cookies específicas. Por ejemplo, al rastrear ciertas páginas que requieren un inicio de sesión, puede preestablecer cookies después del inicio de sesión.
Go
c.SetCookies("http://example.com", []*http.Cookie{
&http.Cookie{
Name: "session_id",
Value: "1234567890",
Domain: "example.com",
},
})Configurar un proxy
El uso de un servidor proxy puede ocultar su dirección IP real y eludir las políticas de bloqueo de IP de algunos sitios web. Colly admite un solo proxy y el cambio de proxy dinámico.
Go
c.SetProxy("tu URL de proxy")Establecer tiempo de espera de la solicitud
Cuando el sitio web responde lentamente, establecer un tiempo de espera de la solicitud puede evitar que el programa se cuelgue durante mucho tiempo. De forma predeterminada, el tiempo de espera de Colly es de 10 segundos, y puede ajustar el tiempo de espera según sea necesario.
Go
c.SetRequestTimeout(30 * time.Second)Devoluciones de llamada
Colly admite el procesamiento de devolución de llamada para varios eventos, como el éxito de la carga de la página, el elemento encontrado, el error de la solicitud, etc. A través de estas devoluciones de llamada, puede manejar de forma flexible el contenido rastreado o manejar errores en el proceso de rastreo.
Ejemplos comunes de devolución de llamada:
- OnRequest
Esta devolución de llamada se llamará antes de que se envíe cada solicitud. Puede establecer dinámicamente el encabezado de la solicitud u otros parámetros aquí.
Go
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visitando:", r.URL.String())
})- OnResponse
Esta devolución de llamada se llama cuando se recibe una respuesta para procesar los datos de respuesta HTTP originales.
Go
c.OnResponse(func(r *colly.Response) {
fmt.Println("Recibido:", string(r.Body))
})- OnHTML
Se utiliza para procesar elementos específicos en páginas HTML. Cuando aparece un elemento HTML coincidente en la página, se llamará a esta devolución de llamada para extraer la información requerida.
Go
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Título de la página:", e.Text)
})- OnError
Esta devolución de llamada se llama cuando ocurre un error en la solicitud. Puede manejar la excepción aquí.
Go
c.OnError(func(_ *colly.Response, err error) {
fmt.Println("Error:", err)
})- Limitación de solicitud
Colly también proporciona algunas opciones para optimizar el rendimiento del rastreador, como limitar la cantidad de solicitudes concurrentes, aumentar la velocidad de rastreo y establecer un retraso entre solicitudes.
Go
c.Limit(&colly.LimitRule{
DomainGlob: "*", // DomainRegexp es un patrón de glob para hacer coincidir los dominios
Delay: 3 * time.Second, // Delay es la duración de la espera antes de crear una nueva solicitud a los dominios coincidentes
Parallelism: 2, // Parallelism es la cantidad de solicitudes concurrentes permitidas máximas de los dominios coincidentes
})Para más configuraciones, consulte la documentación oficial de Colly.
Ejemplo avanzado
Combinando el conocimiento que hemos aprendido antes, rastreemos los datos de información clasificada en la página de inicio de Wikipedia e imprimamos los resultados:
- Análisis del elemento de la página
Después de ingresar a la página de inicio, haga clic derecho -> inspeccione o presione la tecla de acceso directo F12 para ingresar al análisis del elemento de la página:
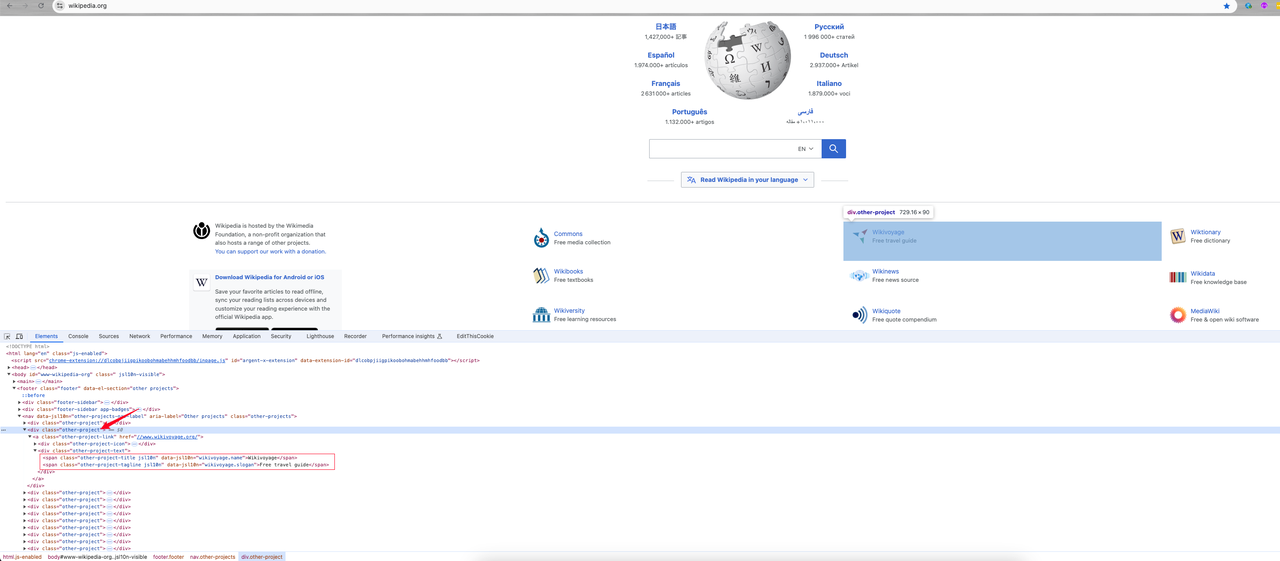
Podemos encontrar:
- La información de categoría que necesito es el elemento
divcon el nombre de claseother-project, donde el enlace de categoría es el valor del atributohrefen la etiqueta a. Su nombre de clase esother-project-link. - Continúe haciendo un seguimiento de este elemento y muestra que los dos nombres de clase
span(other-project-titleyother-project-tagline) debajo del elemento de clase .other-project-text son su nombre de categoría e introducción.
A continuación, comience a codificar para obtener los datos que necesitamos.
- Codificación
Go
package main
import (
"fmt"
"time"
"github.com/gocolly/colly"
)
func main() {
// Crea un nuevo recolector
c := colly.NewCollector()
// Manejar errores
c.OnError(func(_ *colly.Response, err error) {
fmt.Println("Error:", err)
})
// Encabezado de solicitud personalizado: User-Agent
c.OnRequest(func(r *colly.Request) {
r.Headers.Set("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
})
// Establecer proxy
c.SetProxy("tu proxy")
// Establecer tiempo de espera de la solicitud
c.SetRequestTimeout(30 * time.Second)
c.Limit(&colly.LimitRule{
DomainGlob: "*", // DomainRegexp es un patrón de glob para hacer coincidir los dominios
Delay: 1 * time.Second, // Delay es la duración de la espera antes de crear una nueva solicitud a los dominios coincidentes
Parallelism: 2, // Parallelism es la cantidad de solicitudes concurrentes permitidas máximas de los dominios coincidentes
})
// Esperar a que aparezcan los elementos con la clase "other-project-text"
c.OnHTML("div.other-project", func(e *colly.HTMLElement) {
link := e.ChildAttrs(".other-project-link", "href")
title := e.ChildText(".other-project-link .other-project-text .other-project-title")
tagline := e.ChildText(".other-project-link .other-project-text .other-project-tagline") // lema del proyecto
fmt.Println(fmt.Sprintf("%s => %s(%s)", title, tagline, link))
})
// Visita la página de destino
c.Visit("https://wikipedia.org")
}- Proyecto en ejecución
Shell
go run main.go- Resultado
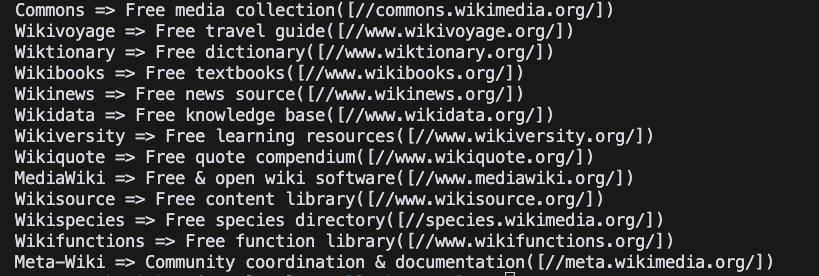
Conclusiones
¡Paren aquí queridos! Nstbrowser siempre te ayuda a simplificar cada paso difícil de las tareas de raspado web y automatización. En este maravilloso blog, hemos aprendido que:
- Cómo construir el entorno básico de Colly.
- Configuración y métodos de uso comunes de Colly.
- Use Colly para completar la visita al sitio web oficial de Nstbrowser y rastrear los datos de clasificación de Wiki de la página de inicio de Wikipedia.
A través de ejemplos simples, hemos experimentado la simplicidad y las potentes capacidades de rastreo de datos de Colly. Para un uso más avanzado, consulte el Colly oficial.
Más





