
Web Scraping
Web Scraping with Python and Selenium Tutorial
How to scrape website with Python and Selenium? Just 3 steps to finish your web scraping task.
Jun 04, 2024Carlos Rivera
If your today's work is to scrape pricing page information from competitors' websites. How would you achieve it? Copying and pasting? Manually entering data? Actually no! They are absolutely spending your most time and may make some errors.
It is necessary to point out that Python has become one of the most popular programming languages for data scraping. What are the charms of it?
Let's get started to enjoy the world of web scraping with Python!
What Is Web Scraping?
Web scraping is a process of extracting data from websites. This can be done manually, but it's better to utilize some automated tools or scripts for collecting large amounts of data efficiently and accurately. Copy and paste from pages is also doing web scraping actually.
Why Python for Web Scraping?
Python is regarded as one of the best choice for web scraping due to several reasons:
- Easy to Use: Because of clarity and intuition, Python is accessible even for beginners.
- Powerful Libraries: Python has a rich system of libraries such as Beautiful Soup, Scrapy, and Selenium that simplify web scraping tasks.
- Community Support: Python has a large and active community. It provides abundant resources and supports for troubleshooting and learning.
Java is also an important language for web scraping. You can learn 3 wonderful methods in the Java Web Scraping tutorial.
Do you have any wonderful ideas and doubts about web scraping and Browserless?
Let's see what other developers are sharing on Discord and Telegram!
Roadmap for Python Web Scraping
Are you ready to start your journey into web scraping with Python? Before figuring out the essential steps, ensure you know what to expect and how to proceed.
Essential Steps to Master Web Scraping
Web scraping involves a systematic process comprising four main tasks:
1. Inspecting the Target Pages
Before extracting data, you need to understand the website's layout and data structure:
- Explore the Site
- Analyze HTML Elements
- Identify Key Data
2. Retrieving HTML Content
To scrape a website, you first need to access its HTML content:
- Use HTTP Client Libraries
- Make HTTP GET Requests
- Verify HTML Retrieval
3. Extracting Data from HTML
Once you have the HTML, the next step is to extract the desired information:
- Parse HTML Content
- Select Relevant Data
- Write Extraction Logic
- Handle Multiple Pages
4. Storing Extracted Data
After extracting the data, it’s crucial to store it in an accessible format:
- Convert Data Formats
- Export Data
Tip: Websites are dynamic, so regularly review and update your scraping process to keep the data current.
Use Cases for Web Scraping
Python web scraping can be applied in various scenarios, including:
- Competitor Analysis: Monitor competitors’ products, services, and marketing strategies by gathering website data.
- Price Comparison: Collect and compare prices from different e-commerce platforms to find the best deals.
- Social Media Analytics: Retrieve data from social media platforms to analyze the popularity and engagement of specific hashtags, keywords, or influencers.
- Lead Generation: Extract contact details from websites to create targeted marketing lists, keeping legal considerations in mind.
- Sentiment Analysis: Gather news and social media posts to track public opinion on a topic or brand.
Overcoming Web Scraping Challenges
Web scraping comes with its own set of challenges:
- Diverse Web Structures: Each website has a unique layout, requiring custom scraping scripts.
- Changing Web Pages: Websites can change their structure without notice, necessitating adjustments to your scraping logic.
- Scalability Issues: As data volume increases, ensure your scraper remains efficient using distributed systems, parallel scraping, or optimizing code.
Additionally, websites employ anti-bot measures like IP blocking, JavaScript challenges, and CAPTCHAs. These can be circumvented with techniques such as rotating proxies and headless browsers.
Stuck in web crawling trouble?
Bypass anti-bot detection to simplify web scraping and automation
Try Free Nstbrowser!
Alternatives to Web Scraping
While web scraping is versatile, there are alternatives:
- APIs: Some websites offer APIs to request and retrieve data. APIs are stable and not usually protected against scraping, but they offer limited data, and not all websites provide them.
- Ready-to-Use Datasets: Purchasing datasets online is another option, though they might not always meet your specific needs.
Despite these alternatives, web scraping remains a popular choice due to its flexibility and comprehensive data access capabilities.
Embark on your web scraping journey with Python, and unlock the vast potential of online data!
How to Do Web Scraping with Python and Selenium?
Step 1. Prerequisites
At the very beginning, we need to install our shell:
Shell
pip install selenium requests jsonAfter the installation is complete, please create a new scraping.py file and introduce the library we just installed in the file:
Python
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import ByStep 2. Connect to Nstbrowser
To get an exact demonstration, we will utilize Nstbrowser, a totally free anti-detect browser as a tool for finishing our task:
Python
def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'xxxxxxx' # your api-key
config = {
'once': True,
'headless': False, # headless
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # required
'name': 'custom browser',
'platform': 'windows', # support: windows, mac, linux
'kernel': 'chromium', # only support: chromium
'kernelMilestone': '120',
'hardwareConcurrency': 4, # support: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # support: 2, 4, 8
'proxy': '', # input format: schema://user:password@host:port eg: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # required
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
print('devtool url: ' + url)
port = get_debugger_port(url)
debugger_address = f'{host}:{port}'
print("debugger_address: " + debugger_address)After connecting to Nstbrowser, we connect to Selenium via the debugger address returned to us by Nstbrowser:
Python
def exec_selenium(debugger_address: str):
options = webdriver.ChromeOptions()
options.add_experimental_option("debuggerAddress", debugger_address)
# Replace with the corresponding version of WebDriver path.
chrome_driver_path = r'./chromedriver' # your chrome driver path
service = ChromeService(executable_path=chrome_driver_path)
driver = webdriver.Chrome(service=service, options=options)Step 3. Scrape the web
From now on, we have successfully started Nstbrowser via Selenium. Begin crawling now!
- Visit our target website, for example: https://www.imdb.com/chart/top
Python
driver.get("https://www.imdb.com/chart/top")- Running the code we just wrote:
Python
python scraping.pyAs you can see, we successfully cranked up Nstbrowser and visited our target site.
- Open Devtool to see the specific information we want to crawl. Yes, obviously they are elements with the same dom structure.
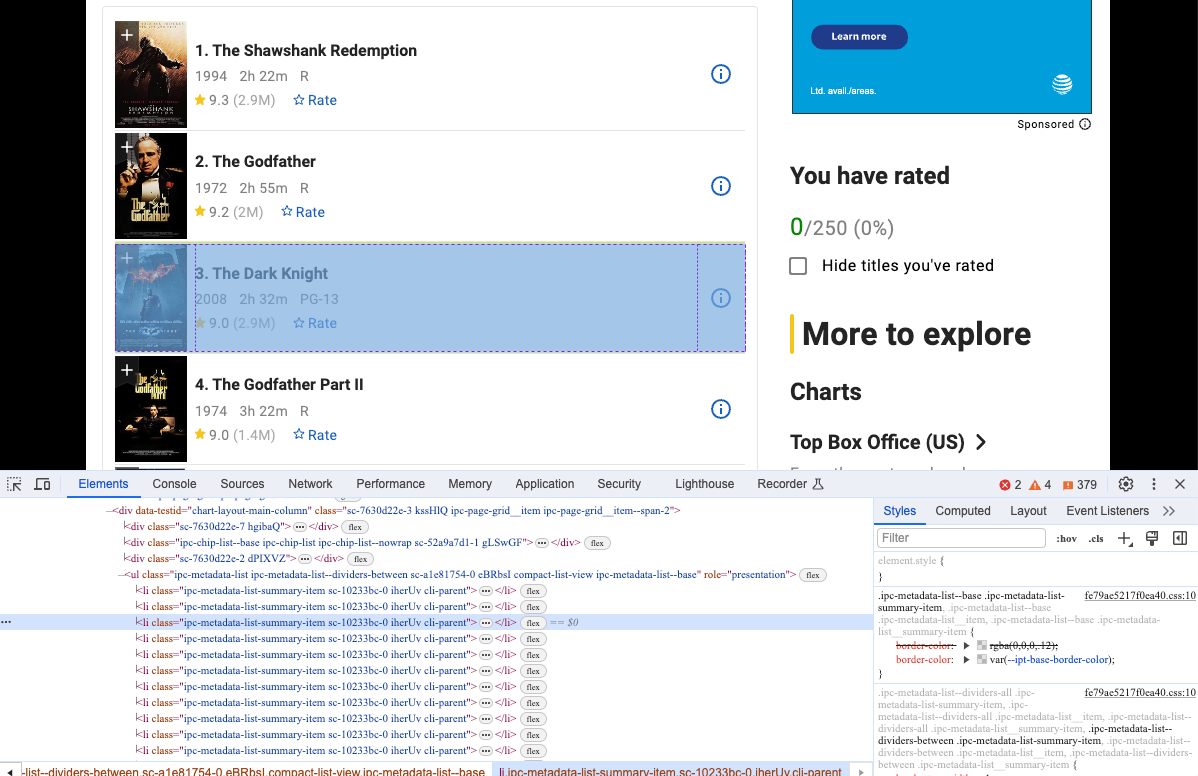
We can use Selenium to get this kind of dom structure and analyze their content:
Python
movies = driver.find_elements(By.CSS_SELECTOR, "li.cli-parent")
for row in movies:
title = row.find_element(By.CLASS_NAME, 'ipc-title-link-wrapper') # get title
year = row.find_element(By.CSS_SELECTOR, 'span.cli-title-metadata-item') # get created year
rate = row.find_element(By.CLASS_NAME, 'ipc-rating-star') # get rate
move_item = {
"title": title.text,
"year": year.text,
"rate": rate.text
}
print(move_item)- Running our code again, you can see that the terminal has already output the information we want to obtain.
Of course, outputting this information in the terminal is not our goal. Next, we need to save the data we crawled.
We use the JSON library to save the retrieved data to a JSON file:
Python
movies = driver.find_elements(By.CSS_SELECTOR, "li.cli-parent")
movies_info = []
for row in movies:
title = row.find_element(By.CLASS_NAME, 'ipc-title-link-wrapper')
year = row.find_element(By.CSS_SELECTOR, 'span.cli-title-metadata-item')
rate = row.find_element(By.CLASS_NAME, 'ipc-rating-star')
move_item = {
"title": title.text,
"year": year.text,
"rate": rate.text
}
movies_info.append(move_item)
# create the json file
json_file = open("movies.json", "w")
# convert movies_info to JSON
json.dump(movies_info, json_file)
# release the file resources
json_file.close()- Run the code and open the file. You can see that there is an extra movies.json next to scraping.py, which means that we have successfully used Selenium to connect to Nstbrowser and crawl the data for our target website!
The Bottom Lines
How to do web scraping with Python and Selenium? This detailed tutorial covered everything you are searching for. To make a comprehensive understanding, we talked about the concept and the advantages of Python for web scraping. Then, it comes to the specific steps by taking a free anti-detect browser - Nstbrowser as an example. I'm sure you have learned a lot about Python web scraping now! Time to operate your project and collect data.
More





