
Web Scraping
The Best Antidetect Browser for Web Scraping 2024
Anti-detect browser helps you hide your browser fingerprint when scraping the webpage. It really simplifies your tasks. Read this blog and find more!
Jul 19, 2024Robin Brown
Browser fingerprints are one of the most significant ways of identifying your online life. They track your profile across different sessions and websites. So when you want to do web scraping, you are bound to get detected.
In order to crawl data easily and efficiently, anti-detection browsers (or anti-fingerprinting browsers) were created.
This blog helps you understand:
- The advantages of an anti-detect browser
- How it helps with web scraping
- Steps to efficient data scraping with Nstbrowser
What Is Anti-Detect Browser?
Anti-detect browser is capable of creating and running multiple digital identities that are not recognized by social platforms. This requires a lot of custom developer work, so such tools are generally not available for free.
They are created to fight against tracking and analytics so that you can carry out your activities in private. In other words, an anti-fingerprint browser enhances privacy, keeps your data and web activities anonymous, and helps your web crawling tools avoid being blocked.
Try Free anti-detect browser - Nstbrowser!
Unblock 99.9% of websites with numerous effective solutions
Simplify web scraping and automation
Do you have any wonderful ideas and doubts about web scraping and Browserless?
Let's see what other developers are sharing on Discord and Telegram!
How Does Anti-Detect Browsers Help Data Collection?
An anti-detect browser helps reduce the impact of web interception. It minimizes or even prevents websites from identifying users and tracking their online activities.
Since websites have anti-crawler systems, when you use a crawler bot to do direct data crawling you will be detected and thus blocked by the website. Human users are prioritized over bots and some websites do not encourage other businesses to collect their data.
As a result, several organizations combine web scraping technologies and anti-detect browsers with privacy measures like proxies to assist in hiding bots.
What Is Nstbrowser?
Nstbrowser is a totally free anti-fingerprint browser, integrated with an anti-detection bot, Web Unblocker, and Intelligent Proxies. It supports Cloud Container Clusters, Browserless, and an enterprise-grade cloud browser solution compatible with Windows/Mac/Linux.
How to Achieve Web Scraping with An Anti-detect Browser?
Next, let's take an example of scraping with Nstbrowser. Just 5 effortless steps:
Step1. Prerequisites
Before scraping, you must first make the following preparations:
Shell
pip install pyppeteer requests jsonAfter installing pyppeteer, we need to create a new file: scraping.py, and introduce the libraries we just installed as well as some system libraries into the file:
Python
import asyncio
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from pyppeteer import launcherCan we use pyppeteer now?
Please calm down!
We have spent some minutes connecting to Nstbrowser, which provides an API to return the webSocketDebuggerUrl for pyppeteer.
Python
# get_debugger_url: Get the debugger url
def get_debugger_url(url: str):
try:
resp = requests.get(url).json()
if resp['data'] is None:
raise Exception(resp['msg'])
webSocketDebuggerUrl = resp['data']['webSocketDebuggerUrl']
return webSocketDebuggerUrl
except HTTPError:
raise Exception(HTTPError.response)
async def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'your api key'
config = {
'once': True,
'headless': False,
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # required
'name': 'custom browser',
'platform': 'windows', # support: windows, mac, linux
'kernel': 'chromium', # only support: chromium
'kernelMilestone': '120', # support: 113, 115, 118, 120
'hardwareConcurrency': 4, # support: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # support: 2, 4, 8
'proxy': '', # input format: schema://user:password@host:port eg: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # required
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
browser_ws_endpoint = get_debugger_url(url)
print("browser_ws_endpoint: " + browser_ws_endpoint) # pyppeteer connect Nstbrowser with browser_ws_endpoint
(
asyncio
.get_event_loop()
.run_until_complete(create_and_connect_to_browser())
)Great! We successfully obtain the Nstbrowser's webSocketDebuggerUrl!
It's time to connect pyppeteer to the Nstbrowser:
Python
async def exec_pyppeteer(wsEndpoint: str):
browser = await launcher.connect(browserWSEndpoint = wsEndpoint)
page = await browser.newPage()Running the code we just wrote in the terminal: python scraping.py, we successfully opened an Nstbrowser and created a new tab in it.
Everything is ready, and now, we can officially start the crawl!
Step 2. Visit the target website
Python
options = {'timeout': 60000}
await page.goto('https://www.yahoo.com/', options)Step 3. Execute the code
Execute the code one more time and then we will access our target website via Nstbrowser.
Now we need to open Devtool to see the specific information we want to crawl and we can see all of them are elements with the same dom structure.
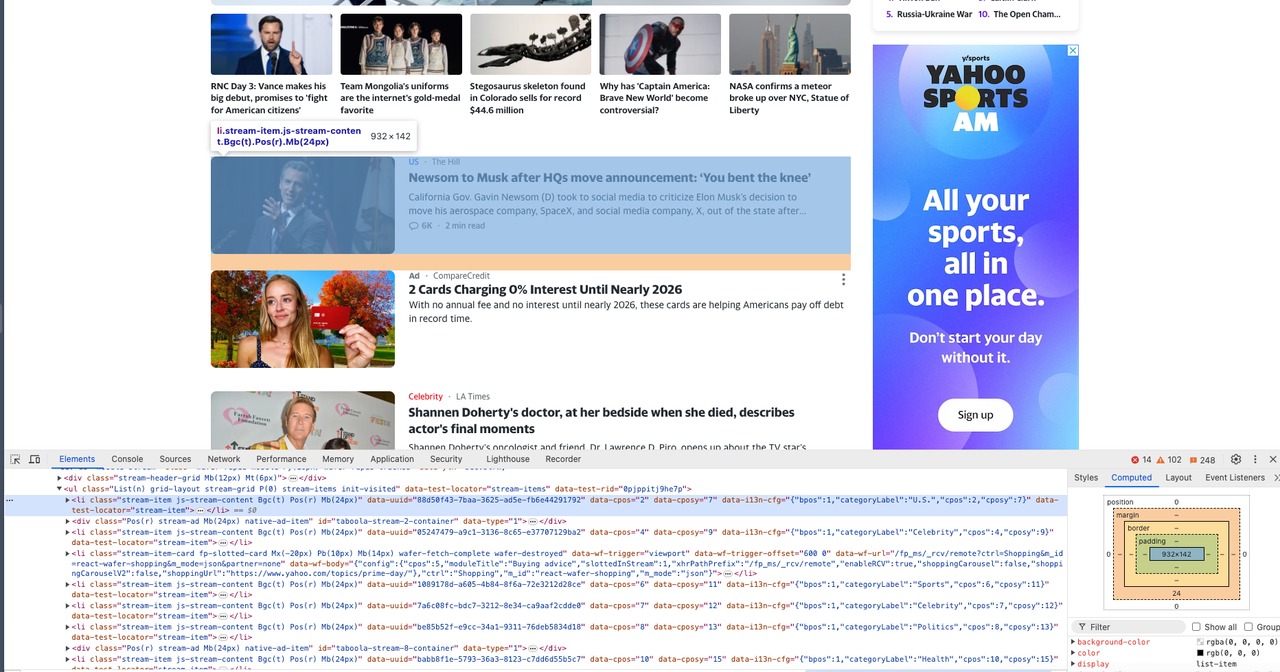
Step 4. Crawl the web page
Now, it's our nice time to use Pyppeteer to crawl these dom structures and analyze their content:
Python
news = await page.JJ('li.stream-item')
for row in news:
title = await row.J('a:not([data-test-locator])')
content = await row.J('p')
comment = await row.J('span[data-test-locator="stream-comment"]')
title_text = await page.evaluate('item => item.textContent', title)
content_text = await page.evaluate('item => item.textContent', content)
comment_text = await page.evaluate('item => item.textContent', comment)
pringt('titile: ', title_text)
pringt('content: ', content_text)
pringt('comment: ', comment_text)Of course, just outputting the data at the terminal is obviously not our final goal, what we also need to do is to save the data.
Step 5. Save the data
We use the json library to save the data to a local json file:
Python
news = await page.JJ('li.stream-item')
news_info = []
for row in news:
title = await row.J('a:not([data-test-locator])')
content = await row.J('p')
comment = await row.J('span[data-test-locator="stream-comment"]')
title_text = await page.evaluate('item => item.textContent', title)
content_text = await page.evaluate('item => item.textContent', content)
comment_text = await page.evaluate('item => item.textContent', comment)
news_item = {
"title": title_text,
"content": content_text,
"comment": comment_text
}
news_info.append(news_item)
# create the json file
json_file = open("news.json", "w")
# convert movies_info to JSON
json.dump(news_info, json_file)
# release the file resources
json_file.close()Run our code and then open the folder where the code is located. You will see a new news.json file appear. Open it to check the content!
If you find it looks like this:
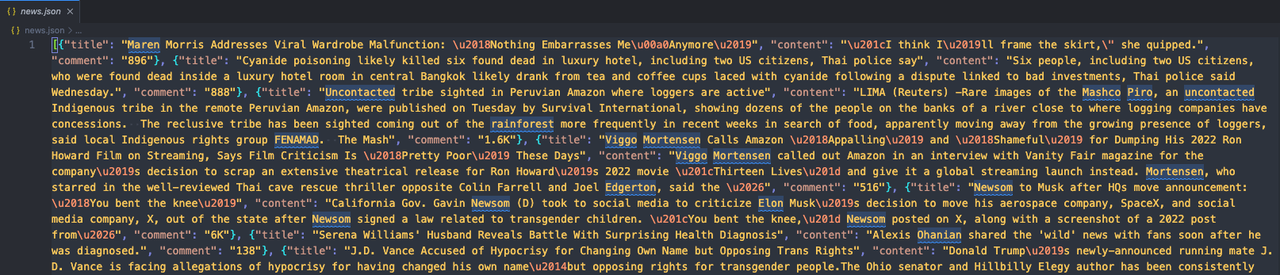
That means we have successfully crawled the target website using Pyppeteer and Nstbrowser!
Why Anti-Detect Browser Best for Web Scraping?
An anti-detect browser is highly effective for web scraping due to the ability to simulate human browsing behavior and evade detection by websites. Let me show you the 6 main features:
1. Avoiding IP Blocking
Websites often track and limit the number of requests from a single IP address. Anti-detect browsers can integrate with proxy services, allowing scrapers to automatically rotate IP addresses and avoid triggering rate limits or bans.
2. Bypassing Browser Fingerprinting
Websites use browser fingerprinting to detect and block automated traffic. Anti-detect browser can modify browser characteristics, such as user-agent, screen resolution, and installed plugins, creating unique fingerprints that make automated requests look like come from different human users.
3. Human-like Interaction
Anti-detect browsers can simulate human interactions such as mouse movements, clicks, and keyboard inputs. This behavior can help in evading detection mechanisms that monitor for non-human patterns, making the scraping process appear more natural and less likely to be banned.
4. Rotating User Agents
Any anti-fingerprint browser allows for the rotation of user-agent strings, which helps in disguising the scraping activity. So requests will be recognised from different browsers and devices. This diversity in user agents makes it harder for websites to identify and block scraping bots.
5. JavaScript Execution
Many modern websites rely heavily on JavaScript to render content dynamically. Anti-detect browsers can execute JavaScript, ensuring that the scraper can access and interact with content that isn't available in the initial HTML source code.
6. Captcha Solving
Anti-detect browsers often support integration with captcha-solving services. This feature is crucial for bypassing captcha challenges that websites implement to prevent automated scraping.
Final Thoughts
With any individual waiting for the opportunity to steal your data and any company preparing to collect your information to further their own business, privacy is vital.
Anti-detect browsers are a great way to protect your data without being detected by detection bots. They can also help you enhance your web scraping tasks.
It's time to use Nstbrowser to help you protect your privacy and perform web crawling quickly and efficiently!
You may also like:
Manage multiple accounts with an anti detect browser
More





