
Web Scraping
Urllib vs Urllib3 vs Requests: Which One Is the Best for You When Web Scraping?
Urllib, urllib3, and requests are 3 wonderful and common Python libraries. What are the differences of these 3? Read this article and find the best one suitable for you!
Jul 17, 2024Robin Brown
Are you always using Python for web scraping? Then, you must also confused about which is the best HTTP client between Urllib, Urllib3, and Requests like me.
Yes, in Python programming, handling HTTP requests is a common requirement.
Python provides multiple libraries to achieve this function, and Urllib, Urllib3, and Requests are the 3 most common libraries.
What is special about them? Which one is suitable for you?
They all have their unique features and pros and cons. Begin reading this article and figure it out!
Overall Comparisons
| Library | Urllib | Urllib3 | Requests |
|---|---|---|---|
| Installation Required | No | Yes | Yes |
| Speed | Moderate | Fast | Moderate |
| Response handling | The response usually requires decoding steps | Extra decoding steps are not required | Extra decoding steps are not required |
| Connection pooling | Not supported | Supported | Supported |
| Ease of use | More syntaxes complicate the learning curve | Easy to use | Easy to use and more beginner-friendly |
1. Urllib
Urllib is part of Python's standard library for handling URLs, and you don't need to install any additional libraries to use it.
When you use Urllib to send a request, it returns a byte array of the response object. However, I have to say that its returned byte array requires an additional decoding step, which can be challenging for beginners.
What are the specialties of Urllib?
The urllib allows finer control with a low-level interface, but it also means more code needs to be written. So, users usually need to manually handle URL encoding, request header settings, and response decoding.
But don't be nervous! Urllib provides basic HTTP request functions such as GET and POST requests and it also supports URL parsing, encoding, and decoding.
Pros & Cons
Pros:
- No additional installation is required. Because it is part of the Python standard library, you don't need to install any additional libraries when using it.
- Comprehensive functions. Supports processing URL requests, responses, and parsing.
Cons:
- High complexity. The steps of sending requests and handling responses are cumbersome.
- Byte arrays need to be processed manually. The returned response needs to be decoded manually, adding an extra step.
What can Urllib be used for?
Urllib is suitable for simple tasks like HTTP requests, especially when you don't want to install third-party libraries.
It can also learn and understand the underlying principles. So, users can use it to learn and understand the underlying implementation of HTTP requests.
However, because urllib lacks advanced features such as connection pool management, default compression, and JSON processing, it is relatively cumbersome to use, especially for complex HTTP requests.
2. Urllib3
Urllib3 provides high-level abstractions, including request API, connection pool, default compression, JSON encoding and decoding, and more.
Applying these features is very simple! You can customize HTTP requests with just a few lines of code. Urllib3 uses C extensions to modify performance. Therefore, it is the fastest among the three.
What are the specialties of Urllib3?
The urllib3 provides a more advanced interface. It also supports advanced features such as a connection pool, automatic retry, SSL configuration, and file upload:
- Connection pool: Manage connection pools to reduce repeated TCP connection overhead.
- Retry mechanism: Automatically retry requests to improve stability.
- Default compression: Supports compression and decompression of request and response data.
- JSON support: Although not a built-in feature, it can be used in conjunction with the JSON module to process JSON data.
- SSL verification: Provides better SSL support and configuration options.
Pros & Cons
Pros:
- More advanced features. provides more advanced features than
urllib, such as connection pool, file chunk upload, retry request, etc. - Easier to use. The syntax is simpler than
urllib, which reduces the complexity of coding.
Cons:
- Installation required. You need to use pip to install
urllib3(pip install urllib3).
What can Urllib3 be used for?
Users can apply urllib3 for some complex HTTP requests, such as handling concurrent requests, connection pool management, etc.
Urllib3 is also suitable for some requirements that need higher performance and stability.
3. Requests
The requests is a popular library for sending HTTP requests. It is known for its simple API design and powerful functions, making it very easy to interact with the network.
HTTP requests sent through requests will become very simple and intuitive. In addition, it has built-in functions such as handling cookies, sessions, proxy settings, and JSON data, which ensure a user-friendly experience.
It also has some powerful features:
- Simple API: Provides the simplest and easiest-to-use interface. That's why the HTTP requests are very intuitive.
- Connection pool: Built-in connection pool management.
- Default compression: Automatically handles compression of requests and responses.
- JSON support: It is very convenient to handle JSON data with
requestsbecause of its built-in JSON encoding and decoding functions. - Rich functions: Including file upload, streaming download, session persistence, etc.
Pros & Cons
Pros:
- The most concise and friendly syntax.
Requestsprovides the simplest and most easy-to-understand API. So sending HTTP requests will be very easy. - Built-in
urllib3. Usesurllib3at the bottom, combining high-performance and advanced functions while hiding complexity. - Popularity and community support. Due to its widespread use, there is a lot of documentation, tutorials, and community support.
Cons:
- Installation required.
Requestsneeds to be installed usingpip(pip install requests). - Despite its rich features, its performance is relatively slow due to its high-level abstraction.
What can requests be used for?
Requests is suitable for almost all HTTP request scenarios, especially for web crawlers and API requests. Because of its concise syntax and rich documentation, it is also particularly suitable for beginners.
Performance comparison
According to the benchmark results, the performance of these three libraries in 100 iterations is as follows:
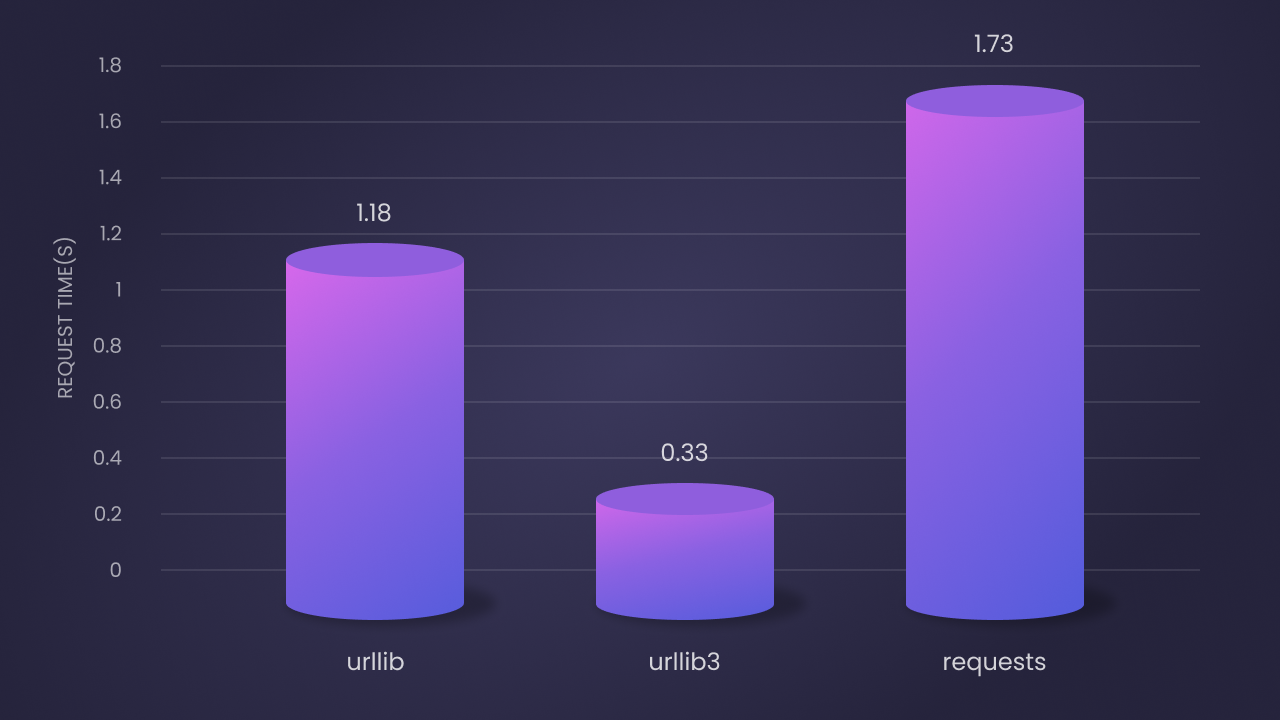
Urllibis the second fastest: the average request time is 1.18 seconds. Although it is a pure Python implementation, it has better performance due to its underlying implementation.Urllib3is the fastest: the average request time is 0.33 seconds. This is due to its C extension and efficient connection pool management.Requestsis the slowest: the average request time is 1.73 seconds. But its ease of use and rich features make up for the lack of.
Choice suggestion
- If you want to rely on as few external libraries as possible and the project requirements are simple, you can choose
urllib. It is part of the standard library and does not need to be installed separately. - If you need high-performance and advanced functions and don't mind doing some technical operations,
urllib3is a good choice. - If you pursue minimal code and a highly easy-to-use interface, especially when dealing with complex HTTP requests,
requestsis ideal. It is the most user-friendly library and is widely used for web crawlers and API requests.
2 Effective Methods to Avoid Getting Blocked While Scraping
Many websites have integrated anti-bot systems to detect and block automated scripts such as web scrapers. So, it is essential to bypass these blocks to access the data!
One way to avoid detection is to use Nstbrowser to avoid IP blocking. Urllib and urllib3 also have built-in capabilities to add proxies to HTTP requests.
Nstbrowser is designed with IP rotation and web unblocker.
Try free Nstbrowser to avoid IP blocking!
Do you have any wonderful ideas and doubts about web scraping and Browserless?
Let's see what other developers are sharing on Discord and Telegram!
Method 1: Use Nstbrowser to bypass the anti-bot system
Before starting, you need to meet some conditions:
- Become a user of Nstbrowser.
- Obtain the API Key of the Nstbrowser.
- Run the Nstbrowserless service locally.
The following are the specific steps. We will take the example of scraping the content title of a page on the Amazon website.
If we need to scrape the h3 title content of the following web page:
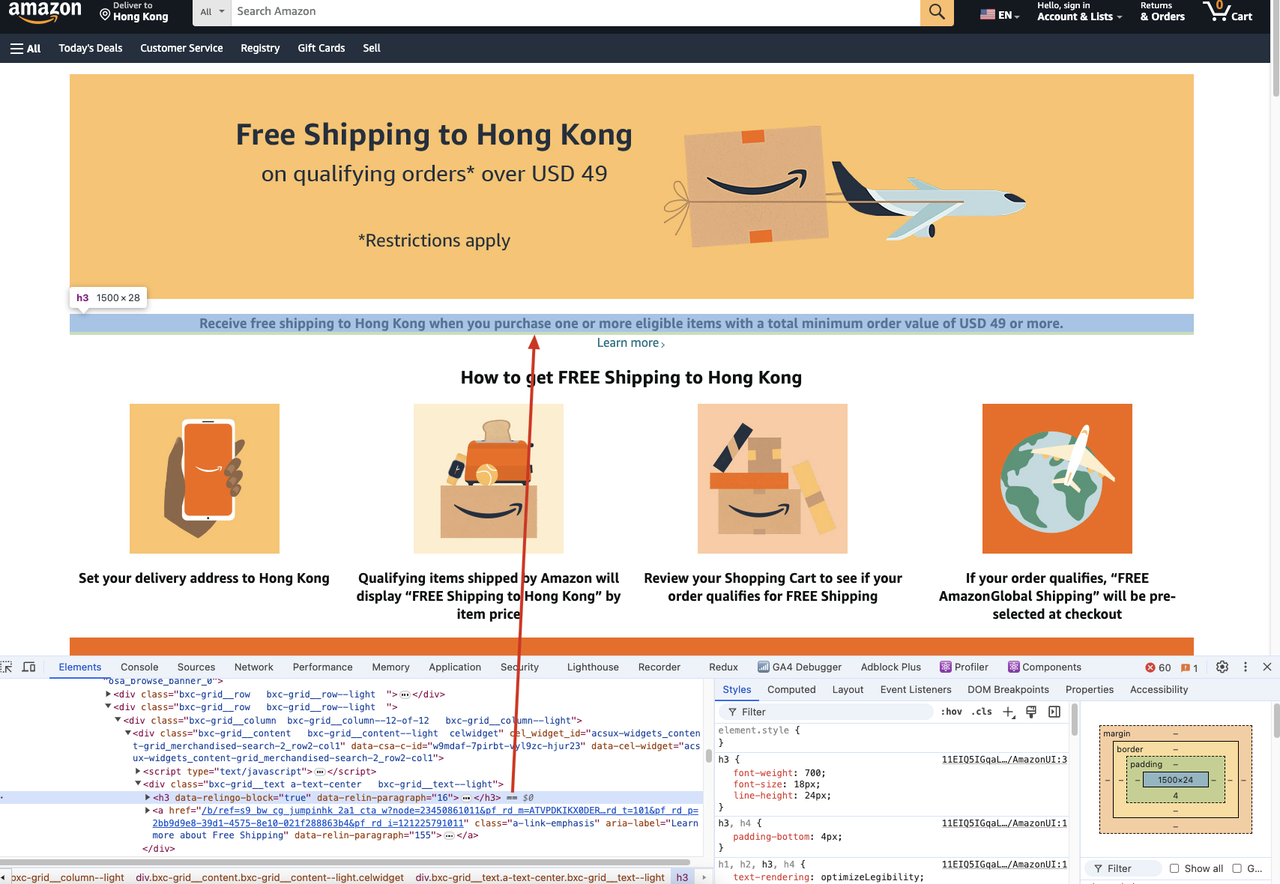
We should run the following code:
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # set headless mode
"autoClose": True,
"args": {"--disable-gpu": "", "--no-sandbox": ""}, # browser args should be a dictionary
"fingerprint": {
"name": 'amazon_scraper',
"platform": 'mac', # support: windows, mac, linux
"kernel": 'chromium', # only support: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8,
"deviceMemory": 8,
},
}
query = {'config': json.dumps(config)}
profileUrl = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
print("Profile URL: ", profileUrl)
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profileUrl)
try:
page = await browser.new_page()
await page.goto("https://www.amazon.com/b/?_encoding=UTF8&node=121225791011&pd_rd_w=Uoi8X&content-id=amzn1.sym.dde8a7c4-f315-46af-87af-ab98d7f18222&pf_rd_p=dde8a7c4-f315-46af-87af-ab98d7f18222&pf_rd_r=CM6698M8C3J02BBVTVM3&pd_rd_wg=olMbe&pd_rd_r=ff5d2eaf-26db-4aa4-a4dd-e74ea389f355&ref_=pd_hp_d_atf_unk&discounts-widget=%2522%257B%255C%2522state%255C%2522%253A%257B%255C%2522refinementFilters%255C%2522%253A%257B%257D%257D%252C%255C%2522version%255C%2522%253A1%257D%2522")
await page.wait_for_selector('h3')
title = await page.inner_text('h3')
print(title)
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())In the above code, we mainly did the following steps:
- Create Nstbrowser service, and set headless mode and some basic startup parameters in the startup configuration.
- Use Playwright to connect to Nstbrowser.
- Jump to the corresponding page that needed to be scraped to get its content.
After executing the above code, you will eventually notice the following output:

Method 2: Use custom request headers to mimic a real browser
Step 1. We should use Playwright and Nstbrowser to visit a website that can get the current request header information.
- Code demonstration:
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # set headless mode
"autoClose": True,
"args": {"--disable-gpu": "", "--no-sandbox": ""}, # browser args should be a dictionary
"fingerprint": {
"name": 'amazon_scraper',
"platform": 'mac', # support: windows, mac, linux
"kernel": 'chromium', # only support: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8,
"deviceMemory": 8,
},
}
query = {'config': json.dumps(config)}
profileUrl = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
print("Profile URL: ", profileUrl)
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profileUrl)
try:
page = await browser.new_page()
await page.goto("https://httpbin.org/headers")
await page.wait_for_selector('pre')
content = await page.inner_text('pre')
print(content)
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())Through the above code, we will see the following output:
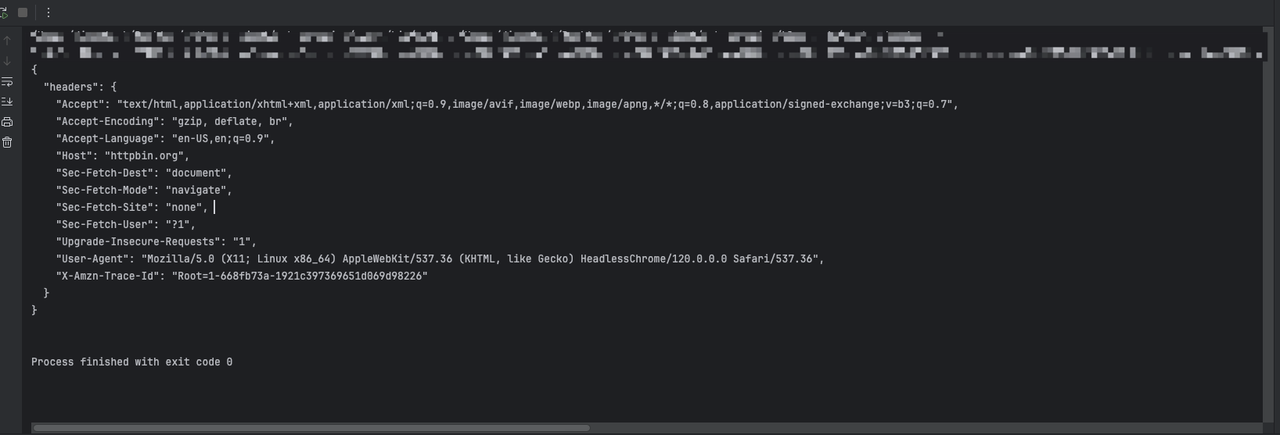
Step 2. We need to use Playwright to add additional request header information by setting up request interception when creating the page:
Python
{
'sec-ch-ua': '\'Not A(Brand\';v=\'99\', \'Google Chrome\';v=\'121\', \'Chromium\';v=\'121\'',
'accept-Language': 'zh-CN,en;q=0.9'
}- Code demonstration:
Python
import json
from urllib.parse import urlencode
from playwright.async_api import async_playwright
extra_headers = {
'sec-ch-ua': '\'Not A(Brand\';v=\'99\', \'Google Chrome\';v=\'121\', \'Chromium\';v=\'121\'',
'accept-Language': 'en-US,en;q=0.9'
}
async def main():
async with async_playwright() as playwright:
config = {
"once": True,
"headless": True, # set headless mode
"autoClose": True,
"args": ["--disable-gpu", "--no-sandbox"], # browser args should be a list
"fingerprint": {
"name": 'amazon_scraper',
"platform": 'mac', # support: windows, mac, linux
"kernel": 'chromium', # only support: chromium
"kernelMilestone": '120',
"hardwareConcurrency": 8,
"deviceMemory": 8,
},
}
query = {'config': json.dumps(config)}
profileUrl = f"ws://127.0.0.1:8848/ws/connect?{urlencode(query)}"
print("Profile URL: ", profileUrl)
browser = await playwright.chromium.connect_over_cdp(endpoint_url=profileUrl)
try:
context = await browser.new_context()
page = await context.new_page()
# Add request interception to set extra headers
await page.route('**/*', lambda route, request: route.continue_(headers={**request.headers, **extra_headers}))
response = await page.goto("https://httpbin.org/headers")
print(await response.text())
finally:
await browser.close()
if __name__ == "__main__":
import asyncio
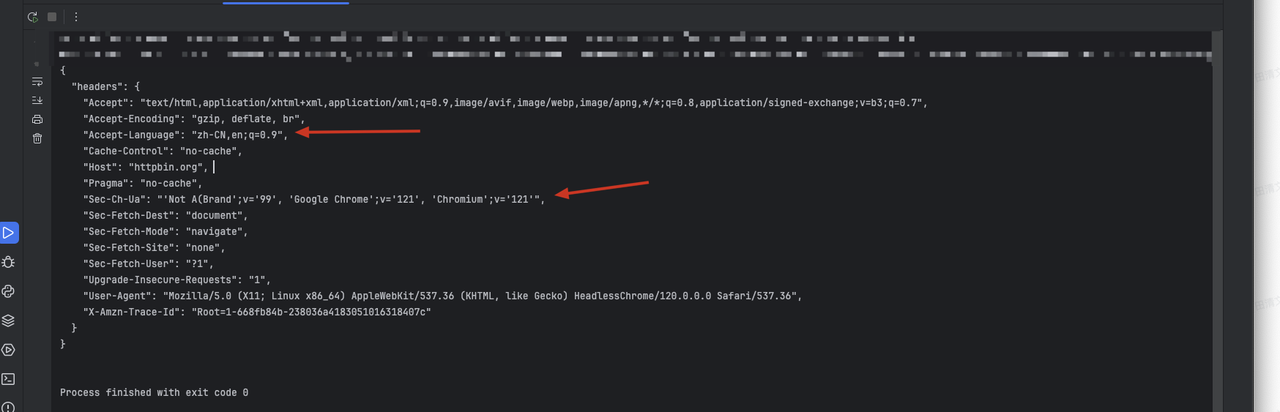
asyncio.run(main())Through the above code, we will see the following returned result information, in which the custom header information we set will be added:
- The header
sec-ch-ua. - Replaced content of the original header accept-Language.
Take Away Notes
In general:
Requestshas become the first choice for most developers due to its ease of use and rich functionality.Urllib3excels when performance and more advanced features are required.- As part of the standard library,
urllibis suitable for projects with high dependency requirements.
Depending on your specific needs and scenarios, choosing the most suitable tool will help you handle HTTP requests more efficiently.
More





