
Web Scraping
How to Bypass CAPTCHA and reCAPTCHA During Web Scraping?
Why there is CAPTCHA? How to bypass CAPTCHA? Everything useful has been prepared in this blog!
Jul 03, 2024Robin Brown
What is CAPTCHA?
CAPTCHA, known as the “Completely Automated Public Turing test to tell Computers and Humans Apart”, is a test to identify whether a website visitor is a real person.
It is a distraction that must be resolved before loading a requested page and comes in different forms. Websites use them to determine whether you are an actual user or a robot by testing the accuracy of the user.
Not to worry! They don't use sophisticated biometrics and facial recognition for authentication.
CAPTCHA verification will commonly occur in the following situations:
- Unusual spikes in traffic for the same user over a short period of time.
- Suspicious interactions. For example, visiting many pages without scrolling.
- Random checks. This is because some high-security firewalls do check just in case.
How does CAPTCHA Work?
CAPTCHA works by generating challenges that are easy for humans to recognize but difficult for computers to parse. These challenges typically involve recognizing distorted text, selecting images that contain specific objects, or solving simple logic problems.
The following are the main steps and mechanisms by which CAPTCHA works:
1. Generate the challenge:
- Text CAPTCHA. Generate images that contain distorted or blurred text, usually including randomly arranged letters and numbers.
- Image Selection. Provide a set of images and ask the user to select the image that contains a specific object (e.g., traffic lights, cars, pedestrians, etc.).
- Logic Problems. Ask simple math or logic questions and require the user to answer them.
- Audio CAPTCHA. Plays audio containing random letters or numbers that the user is required to listen to and enter.
2. Display Challenges:
The CAPTCHA system generates and displays a challenge when the user visits a web page that requires authentication. The user is required to enter an answer or select an image in a designated field.
3. User Response Validation:
After the user submits an answer, the system compares the user's input or selection with the expected answer. Successful validation allows the user to proceed, while failed validation prompts the user to try again.
4. Generate new challenge:
If the user fails the validation multiple times, the system may generate a new challenge to ensure that it is a human user trying to pass the validation.
Nstbrowser easily bypasses CAPTCHA authentication to Unblock Websites
Try It for Free Now!
6 Main Types of CAPTCHA
Text CAPTCHA
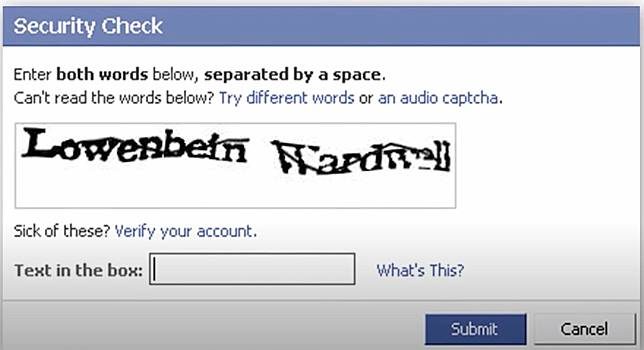
Randomly generating a string of characters and applying distortions, rotations, color changes, and other processing makes it difficult for OCR (Optical Character Recognition) algorithms to parse them.
3D CAPTCHA
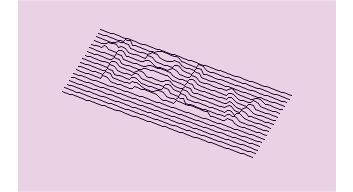
This new technology is an evolution of the text challenge, using 3D characters, which are more difficult for computers to recognize.
reCAPTCHA
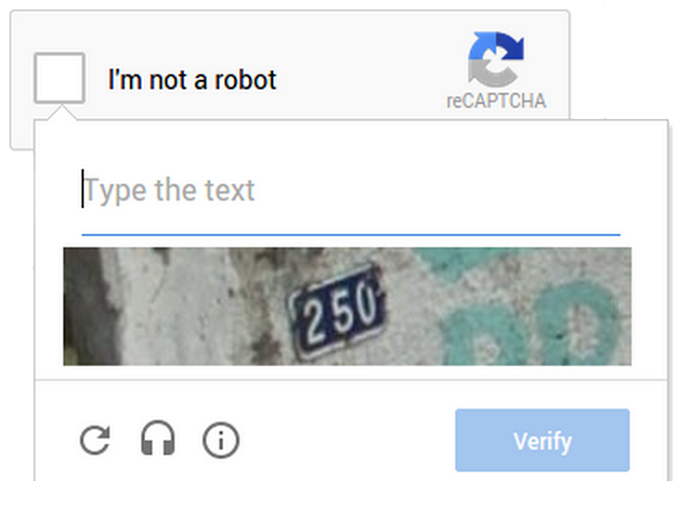
Google offers an advanced CAPTCHA system with both image selection and text recognition components.
Utilizes user verification while helping to improve image recognition and text digitization techniques.
Math challenges
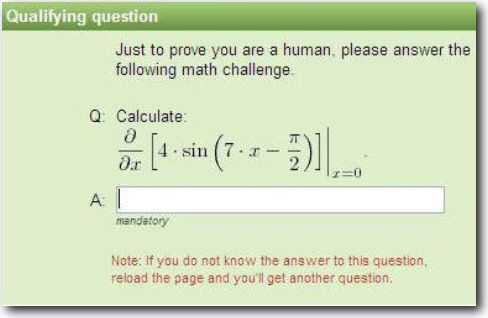
Users need to solve mathematical equations or calculation questions to achieve validation.
Image selection CAPTCHA
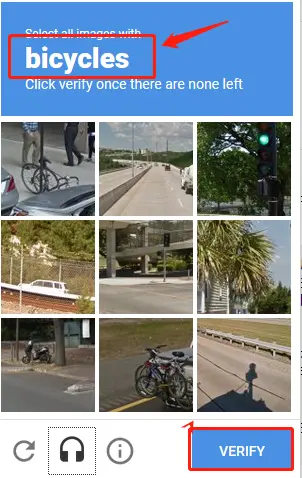
At login, the system displays a set of images and asks the user to select the image that contains a specific object. This approach uses deep learning techniques to analyze how well the user's choice matches the expected answer.
Audio CAPTCHA
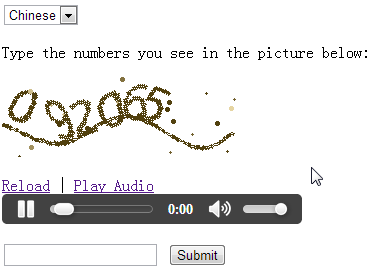
This type of verification is designed for visually impaired users. The verification system plays an audio clip containing letters or numbers that the user needs to listen to and enter.
How to Bypass CHAPTCHA?
Method 1. Avoid Honeypot traps
Honeypot traps are a strategy to prevent bots from crawling content by using hidden links or forms to detect and flag automated tools. Therefore, if you click on them, you will be flagged as a crawler.
- Skip hidden elements
Make sure that crawler scripts ignore elements that have CSS properties such as display: none or visibility: hidden. These elements can be filtered using the following selector:
Python
hidden_elements = driver.find_elements_by_css_selector("[style*='display:none'], [style*='visibility:hidden']")- Detecting hidden forms
The crawler should also skip hidden forms and input boxes:
Python
hidden_forms = driver.find_elements_by_css_selector("input[type='hidden']")- Avoid clicking on suspicious links
Before clicking on links, check if they have hidden attributes:
Python
links = driver.find_elements_by_tag_name("a")
for link in links:
if "display:none" in link.get_attribute("style") or "visibility:hidden" in link.get_attribute("style"):
continue # Skip the hidden link
link.click() # Click the visible link- Using
robots.txt
Follow the rules in your website's robots.txt file to avoid crawling prohibited sections.
- Human-computer interaction simulation
Simulate real user behavior, such as clicking and scrolling at random intervals, to avoid being detected as a crawler.
- Log Analysis
Regularly analyze the crawler's logs to see if it is blocked or redirected, so as to adjust the strategy.
Method 2. Using real header
Properly recognizing request headers is a common way to detect web crawlers, especially when using headless browsers such as Selenium and Puppeteer. To avoid being recognized as a crawler, the User-Agent header can be modified to mimic a real user's browser.
Method 3. IP rotation or header rotation
A large number of requests from the same HTTP header in a short period of time must be suspicious, right?
A large number of requests coming from the same IP address is also suspicious! Because real users are not capable of visiting 1000 web pages in five minutes.
In order to convince the website that you are a real user, rotate your header or IP address so that you are not easily recognized by the website.
Nstbrowser is designed with intelligent IP rotation to avoid web blocking.
Try It for Free Now!
Do you have any wonderful ideas and doubts about web scraping and Browserless?
Let's see what other developers are sharing on Discord and Telegram!
Method 4. Using Nstbrowserless
Nstbrowserless provides an efficient way to run headless browser automation scripts while avoiding detection as a crawler. This cloud-based headless browser service mimics the behavior of real users to help bypass CAPTCHA and other anti-crawler mechanisms.
Nstbrowser easily solves CAPTCHA recognition with the help of Selenium and Puppeteer. Allows you to seamlessly access and crawl the site.
Method 5. Disable automation metrics
Most browser automation tools like Selenium and Puppeteer have some specific flags like navigator.webdriver that expose the fact that they are automation tools.
This is where you need to use a plugin like Puppeteer-stealth to effectively hide these traces.
Method 6. Simulate real user behavior
Finally, websites track user navigation, hover elements, and even click coordinates to analyze user behavior. So mimicking real human browsing behavior is very important to avoid detection.
Some of the behaviors you can try to set up are:
- Randomize actions such as scrolling.
- Clicking.
- Typing.
- Use random time intervals between actions.
Take Away Notes
What is CAPTCHA, why does it occur, and how to bypass it? You have learned the most comprehensive knowledge about CAPTCHA in this article. Rotating your header and IP is the most effective and easiest way to avoid CAPTCHA.
To make web crawling easier for you, use Nstbrowser to easily unlock websites, intelligently rotate IPs, and bypass CAPTCHA validation.
More





