
Web Scraping
403 Forbidden Error: What Is It? How to Fix It?
403 error is super annoying! What is 403 forbidden error? How to solve it? There is everything in this blog.
Jul 12, 2024Robin Brown
You must be familiar with Error 403! There will be a loss of traffic and even some business opportunities!
What? Did you encounter a 403 forbidden error on your website? Fix it immediately! However, what causes it? How to solve it? Both of these two questions are important but confusing.
That's what our blog can do!
From this blog, you will learn:
- Why does 403 forbidden error occur?
- How to fix the 403 error?
Begin scrolling now!
What Is Error 403?
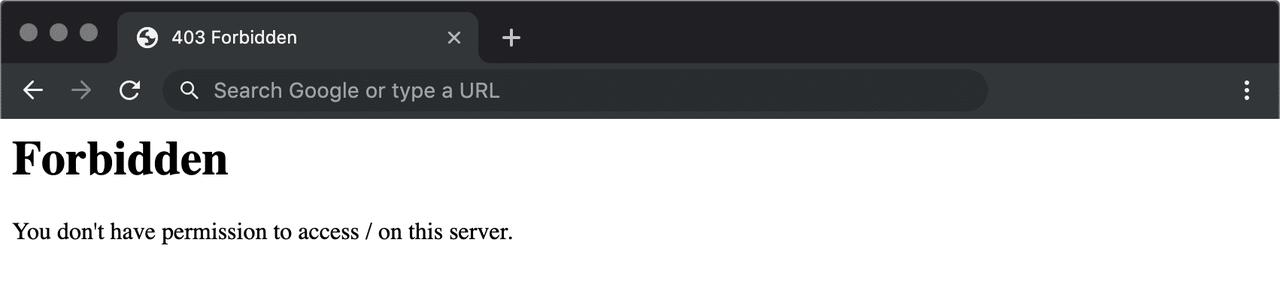
A 403 error means that the server can clearly understand your request, but you are still unable to gain access to the target website. This usually occurs because of insufficient permissions or authentication credentials on the server side.
In other words, your server knows exactly what you're trying to do, but it doesn't work.
Why?
Because you don't get the most fundamental permission for some reason.
It's kind of like when you want to attend a private event, but your name is accidentally removed from the guest list for some reason.
What Causes 403 Errors?
5 Common causes of HTTP 403 forbidden errors include:
- File or folder permissions error
.htaccessfile error- IP address problems
- Plugin conflicts
- No index page
1. File or folder permissions error
When you try to access a file, folder, or even a whole directory, you may be rejected by the website if the server cannot recognize the permissions displayed by the client.
To avoid this error, check and change the file or folder permissions.
Bash
# for directories, set permissions to 755
chmod 755 /path/to/directory
# for files, set permissions to 644
chmod 644 /path/to/file2. .htaccess file error:
If the .htaccess file is incorrectly set or corrupted (infected by malware), then it may cause various problems.
How to solve it? Please check and repair the .htaccess file, or create a new configuration file.
Apache
# sample .htaccess content
<Directory "/path/to/directory">
AllowOverride All
Require all granted
</Directory>3. Wrong IP address:
Wait! A wrong or outdated IP address domain name pointed out will also cause a 403 forbidden error? Yes! It's right.
So, please check the DNS settings of the domain name to ensure that it is pointing to the correct IP address.
4. WordPress plugin issue:
These errors usually pop up when a user tries to access a website that is configured incorrectly by a WordPress plugin. This is usually due to the WordPress plugin being incompatible with other plugins or set up incorrectly.
Oh! It may be also because the host itself cannot access the wp-content folder in the WordPress home directory.
It's time to disable all plugins and then enable them one by one to check which plugin is causing the problem.
PHP
// add the following code to wp-config.php to disable all plugins
define('WP_ALLOW_REPAIR', true);5. No index page:
For the last reason, I found when my home page of the site is not named "index.php" or "index.html", I will also encounter the 403 error.
So, you have to make sure the homepage file of the website is named correctly.
How to easily bypass web blocking for seamless access?
Start using Nstbrowser for free now!
Do you have any wonderful ideas and doubts about web scraping and Browserless?
Let's see what other developers are sharing on Discord and Telegram!
10 Variations of 403 Forbidden Error
- Error 403 – Forbidden: General access forbidden error.
- 403 – Forbidden: Access is denied: Access is denied by the server, possibly due to a permissions issue or configuration error.
- 403 Forbidden – nginx: General access is denied error.
- Forbidden – You don’t have permission to access / on this server: Server root directory permissions are set incorrectly or there are no indexed files.
- 403 – Forbidden Error – You are not allowed to access this address: Access is denied for a specific address.
- HTTP Error 403 – Forbidden – You do not have permission to access the document or program you requested: Access to the requested document or program is disabled.
- 403 Forbidden – Access to this resource on the server is denied: Resource access is denied by the server.
- 403. That’s an error. Your client does not have permission to get URL / from this server: The client does not have permission to access the specified URL.
- You are not authorized to view this page: You don't have the authority to view the page.
- It appears you don’t have permission to access this page.: You don't have the permission to access the target page.
How to Fix Error Code 403?
How to avoid the 403 error? Here are 5 methods!
Method 1. Use Nstbrowser to bypass 403 forbidden error:
The most effective way to bypass 403 errors in web scraping is to use an anti-detect browser! It is designed with numerous anti-bot measures.
Nstbrowser offers the most comprehensive solution, including JavaScript rendering, intelligent proxy rotation, and efficient anti-bot detection. This allows you to avoid 403 forbidden errors and crawl without being blocked.
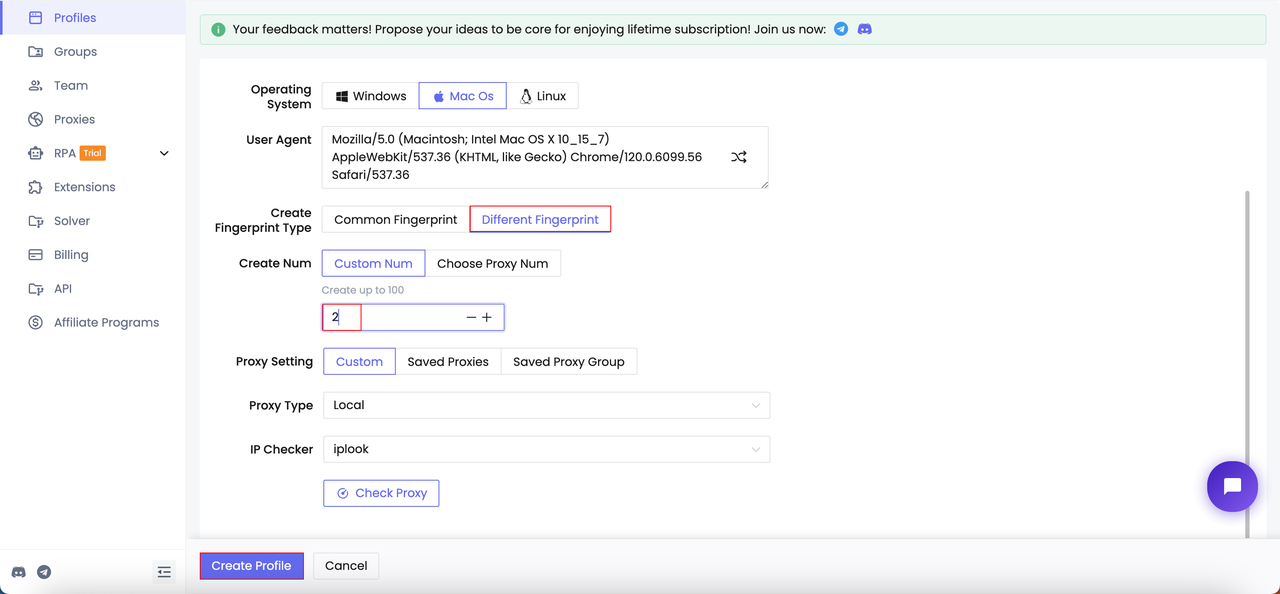
Option 1: Create different browser fingerprints
Nstbrowser provides real browser fingerprints and it will solve the 403 forbidden error in just 3 steps after registration:
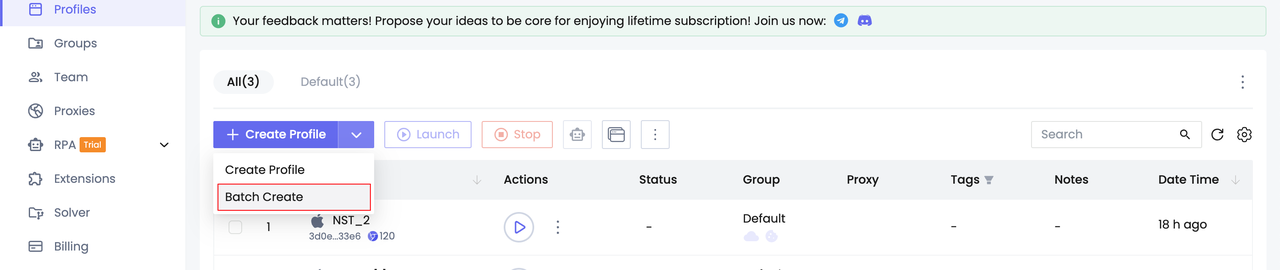
Step 1. Create multiple profiles
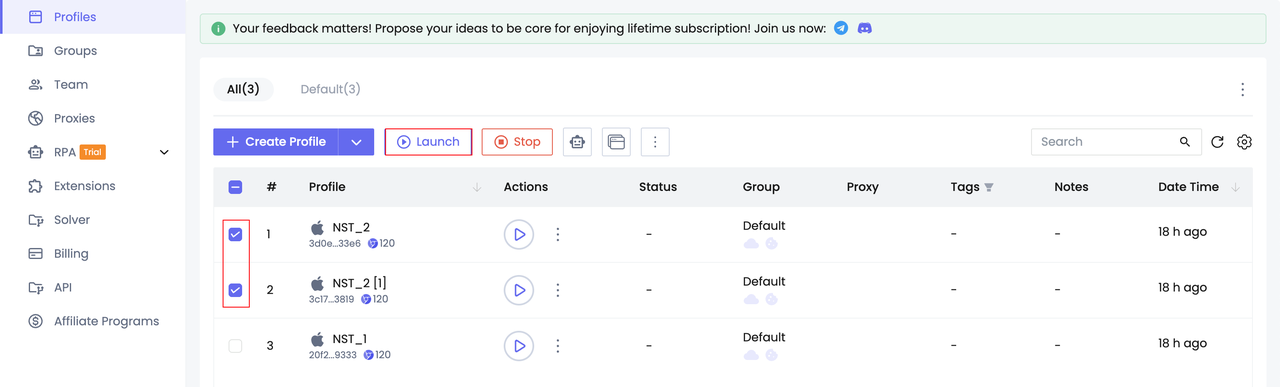
Step 2. Start profiles
Step 3. Accessing the target website
Option 2: Get dynamic proxies
You can also use Nstbrowser to set up a proxy for Profile to implement a group dynamic proxy, so as to keep your browser away from 403 forbidden error warnings. All you need to do is:
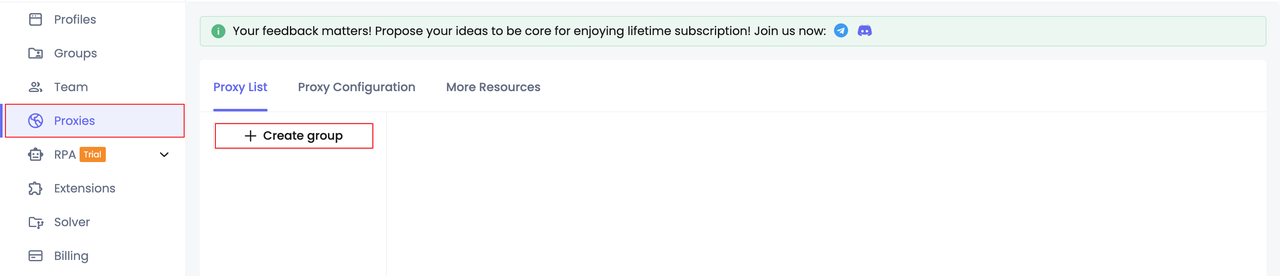
Step 1. Configure the proxy group
- Create group
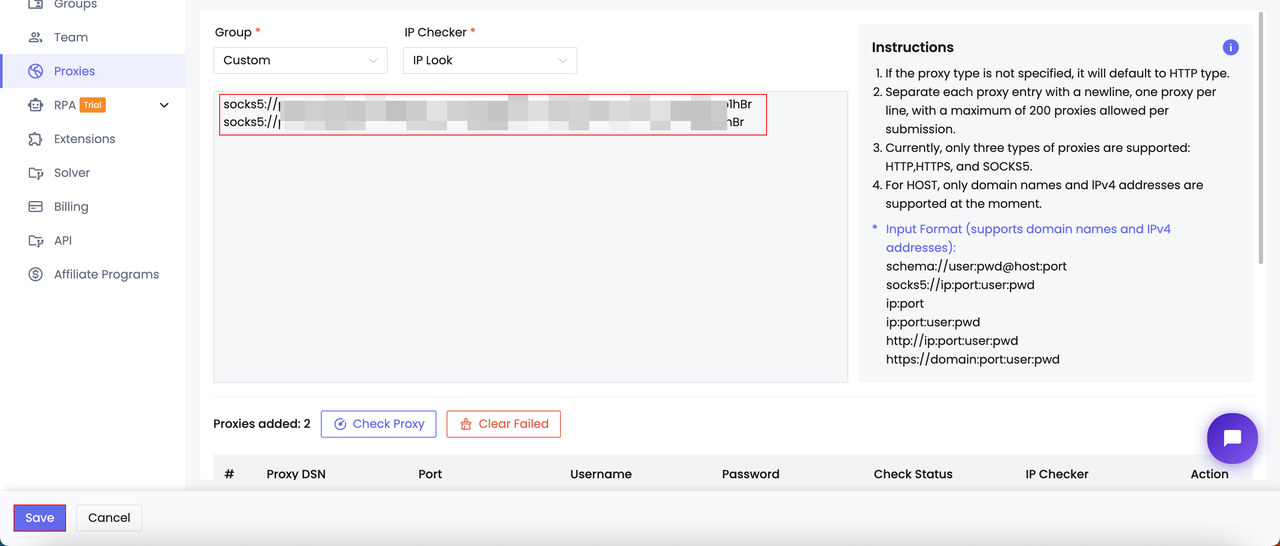
- Add proxy

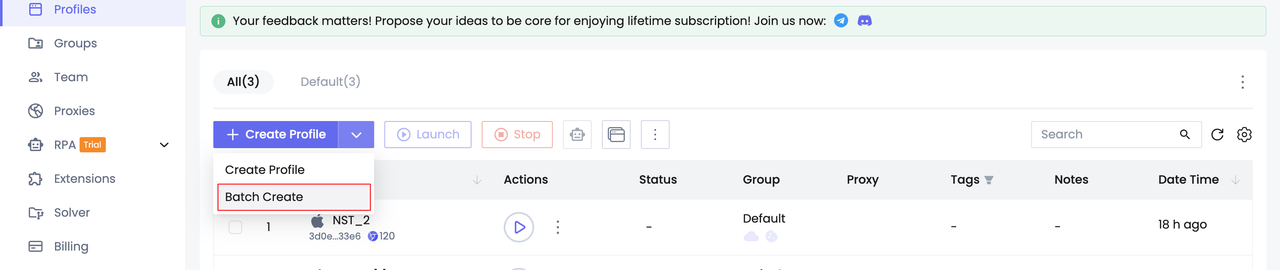
- Create profiles
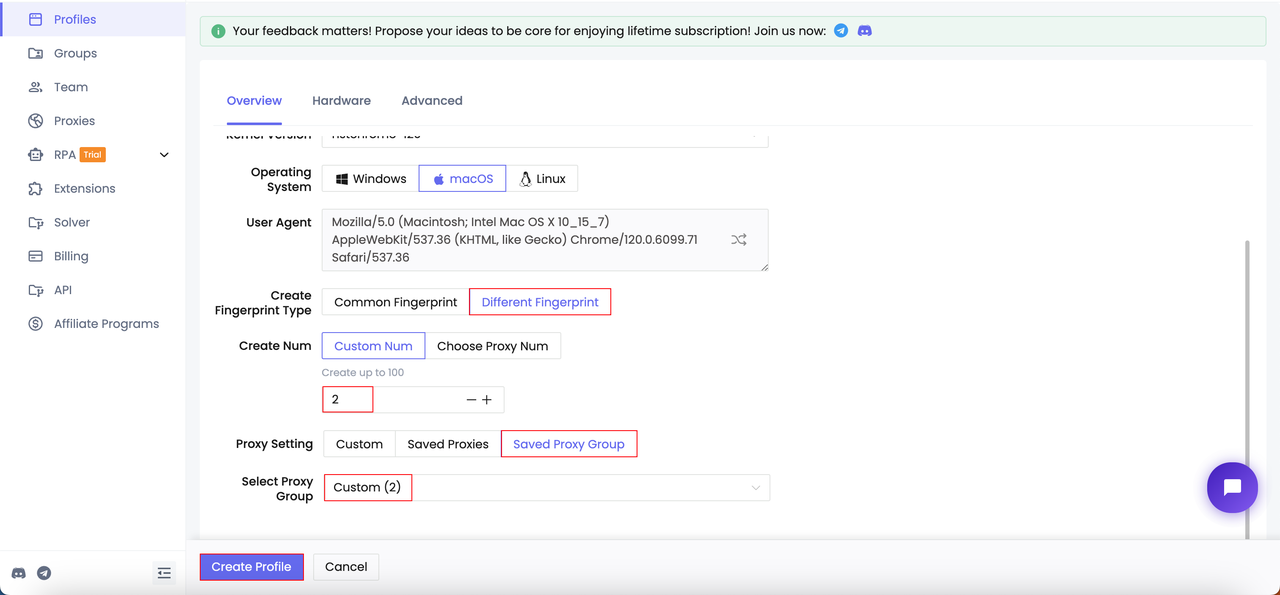
Step 2. Start profiles
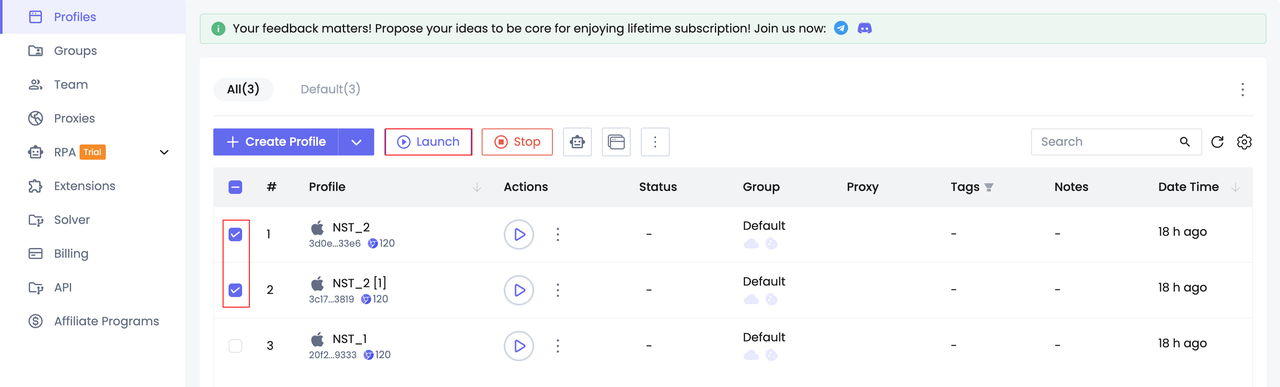
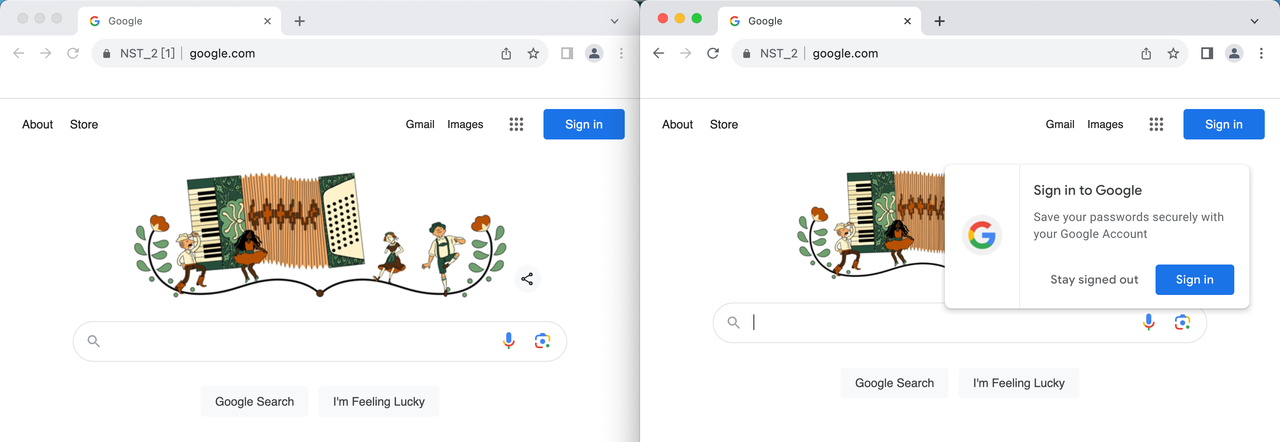
Step 3. Visit the target website
Method 2. Setting up a fake UserAgent
Because the server may decide to allow access based on the user agent, a fake user agent can help bypass the HTTP 403 forbidden error in some cases.
- Using requests library
Python
import requests
url = 'http://example.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
print(response.status_code)
print(response.text)- Using Selenium
Python
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36')
driver = webdriver.Chrome(options=options)
driver.get('http://example.com')
print(driver.page_source)- Using Puppeteer
JavaScript
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36');
await page.goto('http://example.com');
const content = await page.content();
console.log(content);
await browser.close();
})();Method 3. Complete the Headers
When making requests using Selenium and Python Requests, for example, the default header does not contain all the usual data in a user request.
This can make your request look super suspicious. As a result, you have a high potential to encounter a 403 forbidden error.
So when using an automated tool, the most important step is to refine the request headers to mimic a real user's request.
- User-Agent: Identifies the client application type, operating system, software vendor, or software version.
- Referer: Indicates the URL from which the request originated.
- Accept: Indicates the type of content that the client can process.
- Accept-Language: The client's preferred natural language.
- Accept-Encoding: The encoding of the content that the client can handle.
- Connection: Controls how the connection is managed (e.g., keeping the connection active).
- Cache-Control: Caching mechanism for requests and responses.
- Host: The domain name and port number of the server.
- Upgrade-Insecure-Requests: Indicates that the client wants the server to upgrade to HTTPS.
Method 4. Avoid IP bans
Numerous requests from the same IP address over a period of time are likely to result in an IP ban.
Most websites usually use request rate limiting to control traffic and resource usage. Therefore, exceeding the limit set by the website will result in you being banned.
In this case, you can prevent IP banning by setting intervals or delays between successive requests and by implementing a request limit (limiting the number of requests you can make within a certain time frame).
Automatically rotate IP to effectively avoid IP ban and easily bypass 403 errors.
Use Nstbrowser now for free!
- Java
In Node.js, delays can be implemented using the setTimeout() function:
JavaScript
const axios = require('axios');
const url = 'http://example.com';
const headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
};
// define random delay time range
const minDelay = 1000; // minimum delay in ms
const maxDelay = 5000; // maximum delay in ms
// initiate a request
axios.get(url, { headers })
.then(response => {
console.log(response.data);
})
.catch(error => {
console.error(error);
})
.finally(() => {
// wait a random period of time before initiating the next request
const delay = Math.random() * (maxDelay - minDelay) + minDelay;
setTimeout(() => {
// initiate the next request or other action
}, delay);
});- Python
Use the time.sleep() function in Python to introduce random delays:
Python
import requests
import time
import random
url = 'http://example.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# define random delay time range
min_delay = 1 # minimum delay in seconds
max_delay = 5 # maximum delay in seconds
# initiate a request
response = requests.get(url, headers=headers)
# processing response
print(response.status_code)
print(response.text)
# wait a random period of time before initiating the next request
delay = random.uniform(min_delay, max_delay)
time.sleep(delay)Method 5. Using Nstbrowserless
Nstbrowserless is a headerless browser. It can effortlessly bypass the HTTP 403 forbidden error. The key is to set proper request headers and simulate human behavior to avoid being detected as a bot by the server.
- Setting request headers: Make sure to set appropriate request header fields such as User-Agent, Referer, etc. to simulate a real user's visit.
- Mimic human behavior: Introduce random intervals, mouse movements, clicks, etc. to mimic human operation patterns when performing web scraping or automation tasks.
- Handle JavaScript rendering: Nstbrowserless can handle JavaScript rendering to ensure that the full-page content is fetched.
- Avoiding frequent requests: Set the appropriate request frequency to avoid requesting the same website too often.
The Ending
403 forbidden error means: I know who you are, but you are not allowed to be here.
There are 5 effective ways to get around this hassle, but the most worth trying is Nstbrowser.
Easily bypass detection with powerful IP rotation and website unblocker to ensure you don't encounter a 403 error.
More





