
Web Scraping
Hướng dẫn quét web bằng Python và Selenium
Làm cách nào để cạo trang web bằng Python và Selenium? Chỉ cần 3 bước để hoàn thành nhiệm vụ quét web của bạn.
Jun 05, 2024Tạ Quí Lĩnh
Nếu công việc của bạn hôm nay là thu thập thông tin trang giá từ các trang web của đối thủ. Làm thế nào để bạn thực hiện điều đó? Sao chép và dán? Nhập dữ liệu bằng tay? Thực ra không! Những cách này hoàn toàn tốn nhiều thời gian nhất của bạn và có thể gây ra một số lỗi.
Cần phải nhấn mạnh rằng Python đã trở thành một trong những ngôn ngữ lập trình phổ biến nhất cho việc lấy dữ liệu. Điều gì làm cho nó quyến rũ?
Hãy bắt đầu tận hưởng thế giới của việc lấy dữ liệu trên web với Python!
Web Scraping là gì?
Web scraping là quá trình trích xuất dữ liệu từ các trang web. Điều này có thể được thực hiện bằng cách thủ công, nhưng tốt hơn hết là sử dụng một số công cụ hoặc kịch bản tự động hóa để thu thập lượng lớn dữ liệu một cách hiệu quả và chính xác. Sao chép và dán từ các trang cũng thực ra là việc lấy dữ liệu trên web.
Tại sao Python cho Web Scraping?
Python được coi là một trong những lựa chọn tốt nhất cho việc lấy dữ liệu trên web vì một số lý do:
- Dễ sử dụng: Do sự rõ ràng và trực quan, Python có thể tiếp cận ngay cả với người mới bắt đầu.
- Thư viện mạnh mẽ: Python có một hệ thống thư viện phong phú như Beautiful Soup, Scrapy và Selenium giúp đơn giản hóa các nhiệm vụ lấy dữ liệu trên web.
- Hỗ trợ cộng đồng: Python có một cộng đồng lớn và tích cực. Nó cung cấp nguồn tài nguyên phong phú và hỗ trợ cho việc xử lý sự cố và học tập.
Java cũng là một ngôn ngữ quan trọng cho việc lấy dữ liệu trên web. Bạn có thể tìm hiểu 3 phương pháp tuyệt vời trong hướng dẫn Lấy dữ liệu trên web bằng Java.
Lộ trình cho Web Scraping bằng Python
Bạn đã sẵn sàng bắt đầu cuộc hành trình của mình vào việc lấy dữ liệu trên web bằng Python chưa? Trước khi xác định các bước cần thiết, đảm bảo bạn biết điều gì đang chờ đợi và làm thế nào để tiếp tục.
Các Bước Cần Thiết để Thành Thạo Web Scraping
Web scraping liên quan đến một quy trình có hệ thống bao gồm bốn nhiệm vụ chính:
1. Kiểm tra các trang mục tiêu
Trước khi trích xuất dữ liệu, bạn cần hiểu cấu trúc trang web và dữ liệu của nó:
- Khám phá trang web
- Phân tích các phần tử HTML
- Xác định Dữ liệu chính
2. Lấy nội dung HTML
Để lấy dữ liệu từ một trang web, bạn cần truy cập nội dung HTML của nó trước:
- Sử dụng Thư viện Khách hàng HTTP
- Thực hiện yêu cầu HTTP GET
- Xác nhận việc Lấy lại HTML
3. Trích xuất Dữ liệu từ HTML
Sau khi có HTML, bước tiếp theo là trích xuất thông tin mong muốn:
- Phân tích nội dung HTML
- Chọn Dữ liệu liên quan
- Viết Logic Trích xuất
- Xử lý Nhiều trang
4. Lưu trữ Dữ liệu đã Trích xuất
Sau khi trích xuất dữ liệu, việc lưu trữ nó dưới dạng có thể truy cập là rất quan trọng:
- Chuyển đổi Định dạng Dữ liệu
- Xuất Dữ liệu
Mẹo: Các trang web là động, vì vậy hãy định kỳ xem xét và cập nhật quy trình scraping của bạn để giữ cho dữ liệu luôn mới.
Các Ứng Dụng của Web Scraping
Lấy dữ liệu trên web bằng Python có thể được áp dụng trong các tình huống khác nhau, bao gồm:
- Phân tích Đối thủ: Giám sát sản phẩm, dịch vụ và chiến lược tiếp thị của đối thủ bằng cách thu thập dữ liệu từ trang web của họ.
- So sánh Giá cả: Thu thập và so sánh giá từ các nền tảng thương mại điện tử khác nhau để tìm kiếm các ưu đãi tốt nhất.
- Phân tích Mạng xã hội: Lấy dữ liệu từ các nền tảng mạng xã hội để phân tích sự phổ biến và tương tác của hashtag, từ khóa hoặc người ảnh hưởng cụ thể.
- Tạo Danh sách Tiếp thị: Trích xuất thông tin liên hệ từ các trang web để tạo danh sách tiếp thị có mục tiêu, luôn lưu ý các quy định pháp lý.
- Phân tích Tính cảm: Thu thập tin tức và bài đăng trên mạng xã hội để theo dõi ý kiến công chúng về một chủ đề hoặc thương hiệu.
Vượt qua Những Thách thức của Web Scraping
Web scraping đi kèm với một loạt các thách thức riêng:
- Cấu trúc Web đa dạng: Mỗi trang web có một cấu trúc riêng, đòi hỏi các kịch bản scraping tùy chỉnh.
- Thay đổi Trang Web: Các trang web có thể thay đổi cấu trúc của mình mà không cần thông báo trước, đòi hỏi điều chỉnh logic scraping của bạn.
- Vấn đề về Khả năng Mở rộng: Khi lượng dữ liệu tăng lên, đảm bảo rằng scraper của bạn vẫn hiệu quả bằng cách sử dụng hệ thống phân phối, scraping song song hoặc tối ưu hóa mã.
Ngoài ra, các trang web sử dụng biện pháp chống bot như chặn IP, thách thức JavaScript và CAPTCHA. Những vấn đề này có thể được vượt qua bằng các kỹ thuật như proxies xoay vòng và trình duyệt không đầu.
Gặp khó khăn trong việc rảnh rỗi web?
Vượt qua phát hiện chống bot để đơn giản hóa web scraping và tự động hóa
Thử Nstbrowser miễn phí!
Bạn có suy nghĩ hoặc câu hỏi nào về việc thu thập dữ liệu web và Browseless không?
Hãy đến xem những gì các nhà phát triển khác đang chia sẻ trên Discord và Telegram!
Các Phương Thức Thay Thế cho Web Scraping
Mặc dù web scraping là linh hoạt, nhưng vẫn có các phương thức thay thế:
- APIs: Một số trang web cung cấp APIs để yêu cầu và nhận dữ liệu. APIs ổn định và thường không được bảo vệ khỏi scraping, nhưng chúng cung cấp dữ liệu giới hạn, và không phải tất cả các trang web đều cung cấp chúng.
- Bộ Dữ liệu Sẵn sàng sử dụng: Mua các bộ dữ liệu trực tuyến là một lựa chọn khác, mặc dù chúng có thể không luôn đáp ứng được nhu cầu cụ thể của bạn.
Mặc dù có những phương thức thay thế này, nhưng web scraping vẫn là một lựa chọn phổ biến nhờ tính linh hoạt và khả năng truy cập dữ liệu toàn diện của nó.
Hãy bắt đầu hành trình web scraping của bạn với Python, và mở khóa tiềm năng lớn của dữ liệu trực tuyến!
Làm thế nào để Làm Web Scraping với Python và Selenium?
Bước 1. Yêu cầu Tiên quyết
Ở đầu tiên, chúng ta cần cài đặt shell của mình:
Shell
pip install selenium requests jsonSau khi cài đặt hoàn tất, hãy tạo một tệp scraping.py mới và nhập thư viện chúng ta vừa cài đặt vào tệp:
Python
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import ByBước 2. Kết nối đến Nstbrowser
Để có một bản mô phỏng chính xác, chúng ta sẽ sử dụng Nstbrowser, một trình duyệt hoàn toàn miễn phí với tính năng chống phát hiện như một công cụ để hoàn thành nhiệm vụ của chúng ta:
Python
def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'xxxxxxx' # khóa API của bạn
config = {
'once': True,
'headless': False, # không có đầu
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # yêu cầu
'name': 'custom browser',
'platform': 'windows', # hỗ trợ: windows, mac, linux
'kernel': 'chromium', # chỉ hỗ trợ: chromium
'kernelMilestone': '120',
'hardwareConcurrency': 4, # hỗ trợ: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # hỗ trợ: 2, 4, 8
'proxy': '', # định dạng đầu vào: schema://user:password@host:port ví dụ: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # yêu cầu
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
print('devtool url: ' + url)
port = get_debugger_port(url)
debugger_address = f'{host}:{port}'
print("debugger_address: " + debugger_address)Sau khi kết nối với Nstbrowser, chúng ta kết nối với Selenium thông qua địa chỉ của trình gỡ lỗi được trả về cho chúng ta bởi Nstbrowser:
Python
def exec_selenium(debugger_address: str):
options = webdriver.ChromeOptions()
options.add_experimental_option("debuggerAddress", debugger_address)
# Thay thế bằng đường dẫn tương ứng của Chrome WebDriver.
chrome_driver_path = r'./chromedriver' # đường dẫn trình điều khiển Chrome của bạn
service = ChromeService(executable_path=chrome_driver_path)
driver = webdriver.Chrome(service=service, options=options)Bước 3. Lấy dữ liệu trên web
Từ bây giờ, chúng ta đã khởi động Nstbrowser thành công thông qua Selenium. Bắt đầu thu thập dữ liệu ngay bây giờ!
- Truy cập trang web mục tiêu của chúng tôi, ví dụ: https://www.imdb.com/chart/top
Python
driver.get("https://www.imdb.com/chart/top")- Chạy mã chúng ta vừa viết:
Python
python scraping.pyNhư bạn có thể thấy, chúng ta đã khởi động thành công Nstbrowser và đã truy cập vào trang web mục tiêu của chúng tôi.
- Mở Devtool để xem thông tin cụ thể mà chúng ta muốn thu thập. Đúng, rõ ràng chúng là các phần tử có cấu trúc DOM giống nhau.
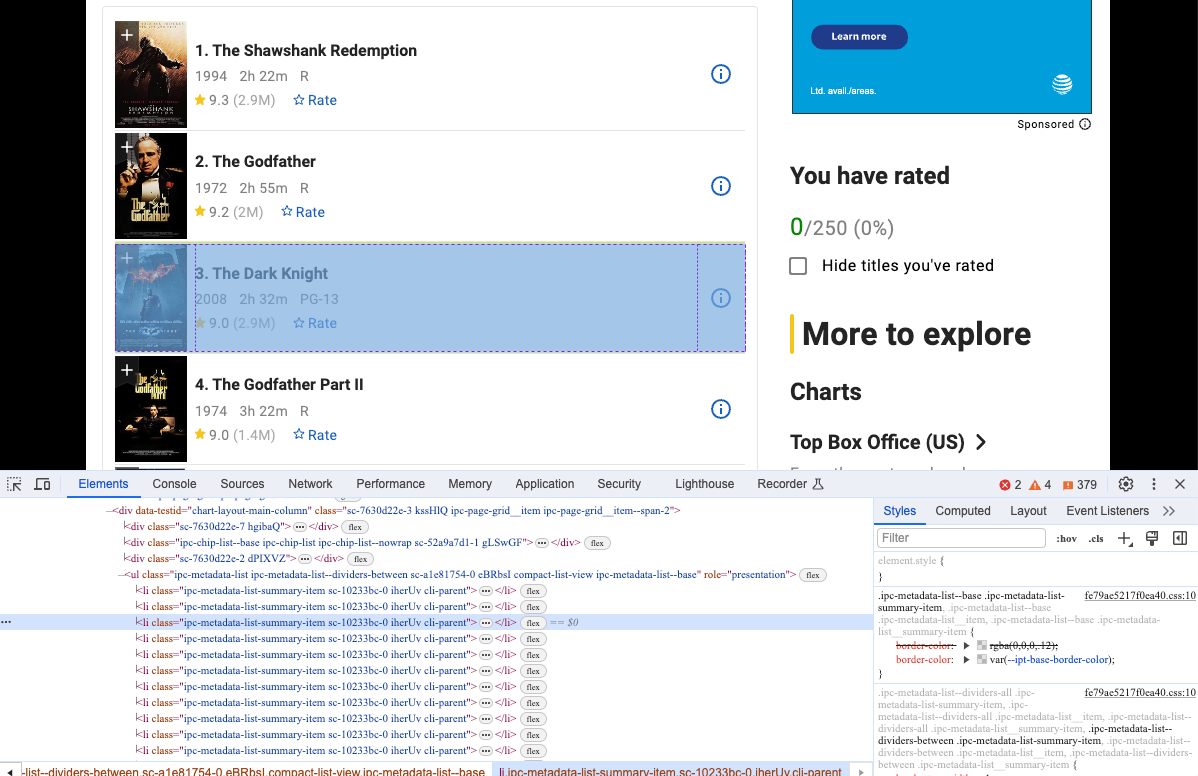
Chúng ta có thể sử dụng Selenium để lấy loại cấu trúc DOM này và phân tích nội dung của chúng:
Python
movies = driver.find_elements(By.CSS_SELECTOR, "li.cli-parent")
for row in movies:
title = row.find_element(By.CLASS_NAME, 'ipc-title-link-wrapper') # lấy tiêu đề
year = row.find_element(By.CSS_SELECTOR, 'span.cli-title-metadata-item') # lấy năm tạo ra
rate = row.find_element(By.CLASS_NAME, 'ipc-rating-star') # lấy tỷ lệ
move_item = {
"title": title.text,
"year": year.text,
"rate": rate.text
}
print(move_item)- Chạy mã của chúng ta một lần nữa, và bạn sẽ thấy rằng terminal đã hiển thị thông tin chúng ta muốn thu thập.
Tất nhiên, việc đưa thông tin này ra terminal không phải là mục tiêu của chúng ta. Tiếp theo, chúng ta cần lưu trữ dữ liệu mà chúng ta đã thu thập.
Chúng ta sử dụng thư viện JSON để lưu trữ dữ liệu đã thu thập vào một tệp JSON:
Python
movies = driver.find_elements(By.CSS_SELECTOR, "li.cli-parent")
movies_info = []
for row in movies:
title = row.find_element(By.CLASS_NAME, 'ipc-title-link-wrapper')
year = row.find_element(By.CSS_SELECTOR, 'span.cli-title-metadata-item')
rate = row.find_element(By.CLASS_NAME, 'ipc-rating-star')
move_item = {
"title": title.text,
"year": year.text,
"rate": rate.text
}
movies_info.append(move_item)
# tạo tệp JSON
json_file = open("movies.json", "w")
# chuyển đổi movies_info sang JSON
json.dump(movies_info, json_file)
# giải phóng tài nguyên của tệp
json_file.close()- Chạy mã và mở tệp. Bạn sẽ thấy có một tệp JSON phụ bên cạnh scraping.py, điều này có nghĩa là chúng ta đã thành công sử dụng Selenium để kết nối với Nstbrowser và thu thập dữ liệu cho trang web mục tiêu của chúng tôi!
Kết Luận
Làm thế nào để thực hiện web scraping với Python và Selenium? Hướng dẫn chi tiết này đã bao gồm tất cả những gì bạn đang tìm kiếm. Để hiểu biết toàn diện hơn, chúng ta đã nói về khái niệm và ưu điểm của Python cho việc web scraping. Tiếp theo, đến các bước cụ thể bằng cách lấy một trình duyệt chống phát hiện miễn phí - Nstbrowser làm ví dụ. Tôi chắc chắn rằng bạn đã học rất nhiều về web scraping với Python! Đến lúc vận hành dự án của bạn và thu thập dữ liệu.
Hơn





