
Web Scraping
Python Web Crawler - Tutorial Paso a Paso 2024
Python proporciona capacidades de desarrollo de rastreadores web muy potentes y es uno de los lenguajes de rastreo más populares. Lee este artículo para aprender a utilizar Python para el rastreo web.
Jun 13, 2024Robin Brown
El rastreador web es una técnica poderosa que nos permite recopilar todo tipo de datos e información visitando páginas web y descubriendo URL en sitios web. Python cuenta con diversas bibliotecas y frameworks que admiten rastreadores web. En este artículo aprenderemos sobre:
- Qué es un rastreador web en Python.
- Cómo utilizar un rastreador web en Python y la API de Nstbrowser para rastrear páginas web.
- Cómo lidiar con el bloqueo mientras se realiza el rastreo con Python.
- Ejemplos de rastreo en Python.
¿Qué es un Rastreador Web en Python?
Python ofrece capacidades de desarrollo de rastreadores web muy potentes y es uno de los lenguajes de rastreo más populares disponibles en la actualidad. Un rastreador web en Python es un programa automatizado para navegar por un sitio web o Internet con el fin de raspar páginas web. Es un script en Python que explora páginas, descubre enlaces y los sigue para aumentar la cantidad de datos que se pueden extraer de sitios web relevantes.
Los motores de búsqueda dependen de robots rastreadores para construir y mantener sus índices de páginas, mientras que las herramientas de rastreo web los utilizan para acceder y encontrar todas las páginas para aplicar lógica de extracción de datos.
Los rastreadores web en Python se implementan principalmente mediante el uso de varias bibliotecas de terceros. Las bibliotecas comunes de rastreadores web en Python incluyen:
-
urllib/urllib2/requests: Estas bibliotecas proporcionan funcionalidad básica de rastreo web, lo que le permite enviar solicitudes HTTP y recuperar respuestas.
-
BeautifulSoup: Esta es una biblioteca para analizar documentos HTML y XML, que puede ayudar al rastreador a extraer información útil en la página web.
-
Scrapy: Este es un poderoso framework de rastreo web que proporciona extracción de datos, procesamiento de canalizaciones, rastreo distribuido y otras características avanzadas.
-
Selenium: Es una herramienta de automatización de navegadores web, que puede simular la operación manual del navegador. Este rastreador se utiliza siempre para rastrear el contenido de páginas dinámicas generado por JavaScript.
¿Siempre te bloquean al hacer raspaduras?
Desbloqueador web y soluciones contra la detección de Nstbrowser
¡Pruébalo GRATIS!
¿Tienes ideas y dudas interesantes sobre el web scraping y el Browserless?
¡Veamos qué comparten otros desarrolladores en Discord y Telegram!
4 Casos de Uso Populares de Rastreadores Web:
-
Los motores de búsqueda (por ejemplo, Googlebot, Bingbot, Yandex Bot...) recopilan todo el HTML de las partes importantes de la web, los datos se indexan para que sean buscables.
-
Las herramientas de análisis de SEO recopilan metadatos además de HTML, como el tiempo de respuesta y el estado de respuesta para detectar páginas rotas y enlaces entre diferentes dominios para recopilar enlaces de retroceso.
-
Las herramientas de monitoreo de precios recorren sitios de comercio electrónico para encontrar páginas de productos y extraer metadatos, especialmente precios. Las páginas de productos son revisadas periódicamente.
-
Common Crawl mantiene un repositorio abierto de datos de rastreo web. Por ejemplo, el archivo de mayo de 2022 contiene 3.45 mil millones de páginas web.
Entonces, ¿cómo utilizar la herramienta de automatización de Python Pyppeteer para el rastreo web?
¡Sigue desplazándote!
¿Cómo Raspar la Web con Pyppeteer y la API de Nstbrowser?
Paso 1. Requisitos previos
Hay algunas preparaciones que deben hacerse antes de poder comenzar a rastrear:
Shell
pip install pyppeteer requests jsonDespués de instalar las bibliotecas necesarias anteriormente, cree un nuevo archivo scraping.py e introduzca las bibliotecas que acabamos de instalar, así como algunas bibliotecas de sistema en el archivo:
python
import asyncio
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from pyppeteer import launcherAntes de usar pyppeteer, primero necesitamos conectarnos a Nstbrowser, que proporciona una API para devolver la webSocketDebuggerUrl para pyppeteer.
Python
# get_debugger_url: Obtener la URL del depurador
def get_debugger_url(url: str):
try:
resp = requests.get(url).json()
if resp['data'] is None:
raise Exception(resp['msg'])
webSocketDebuggerUrl = resp['data']['webSocketDebuggerUrl']
return webSocketDebuggerUrl
except HTTPError:
raise Exception(HTTPError.response)
async def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'tu clave de API'
config = {
'once': True,
'headless': False,
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # requerido
'name': 'navegador personalizado',
'platform': 'windows', # soporte: windows, mac, linux
'kernel': 'chromium', # solo soporte: chromium
'kernelMilestone': '120', # soporte: 113, 115, 118, 120
'hardwareConcurrency': 4, # soporte: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # soporte: 2, 4, 8
'proxy': '', # formato de entrada: schema://user:password@host:port por ejemplo: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # requerido
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
browser_ws_endpoint = get_debugger_url(url)
print("browser_ws_endpoint: " + browser_ws_endpoint) # pyppeteer se conecta a Nstbrowser a través de browser_ws_endpoint
(
asyncio
.get_event_loop()
.run_until_complete(create_and_connect_to_browser())
)Después de obtener con éxito la webSocketDebuggerUrl de Nstbrowser, conecta pyppeteer a Nstbrowser:
Python
async def exec_pyppeteer(wsEndpoint: str):
browser = await launcher.connect(browserWSEndpoint = wsEndpoint)
page = await browser.newPage()Ejecuta el código que acabamos de escribir en la terminal: python scraping.py, y verás que hemos abierto con éxito un Nstbrowser y creado una nueva pestaña en el Nstbrowser.
¡Todo está listo, y ahora, podemos comenzar oficialmente el rastreo!
Paso 2. Visitar el sitio web objetivo
https://www.imdb.com/chart/top
Python
await page.goto('https://www.imdb.com/chart/top')Paso 3. Ejecutar el código
Ejecuta nuestro código una vez más y verás que hemos accedido a nuestro sitio web objetivo a través de Nstbrowser. Abre Devtool para ver la información específica que queremos rastrear y verás que son elementos con la misma estructura dom.
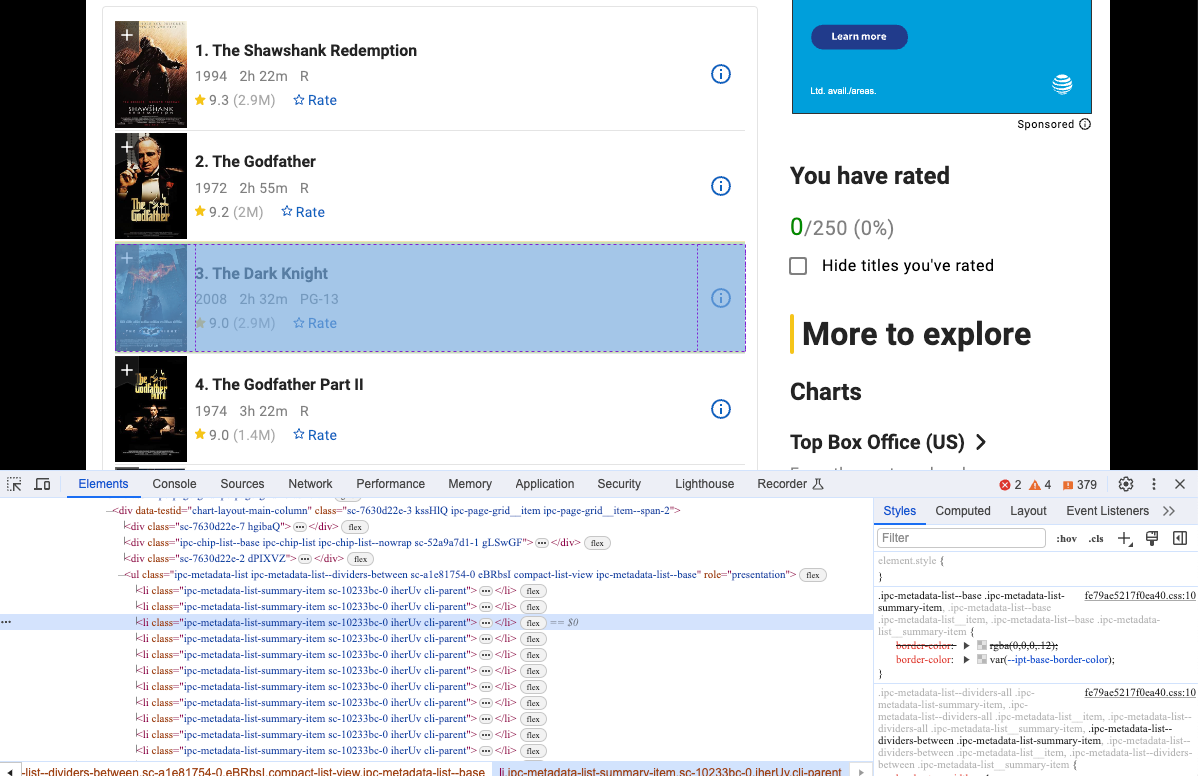
Paso 4. Rastrear la página web
Podemos usar Pyppeteer para rastrear estas estructuras dom y analizar su contenido:
Python
movies = await page.JJ('li.cli-parent')
for row in movies:
title = await row.J('.ipc-title-link-wrapper')
year = await row.J('span.cli-title-metadata-item')
rate = await row.J('.ipc-rating-star')
title_text = await page.evaluate('item => item.textContent', title)
year_text = await page.evaluate('item => item.textContent', year)
rate_text = await page.evaluate('item => item.textContent', rate)
pringt('titile: ', title_text)
pringt('year: ', title_text)
pringt('rate: ', title_text)Por supuesto, simplemente imprimir los datos en la terminal obviamente no es nuestro objetivo final, lo que queremos hacer es guardar los datos.
Paso 5. Guardar los datos
Utilizamos la biblioteca json para guardar los datos en un archivo local json:
Python
movies = await page.JJ('li.cli-parent')
movies_info = []
for row in movies:
title = await row.J('.ipc-title-link-wrapper')
year = await row.J('span.cli-title-metadata-item')
rate = await row.J('.ipc-rating-star')
title_text = await page.evaluate('item => item.textContent', title)
year_text = await page.evaluate('item => item.textContent', year)
rate_text = await page.evaluate('item => item.textContent', rate)
movie_item = {
"title": title_text,
"year": year_text,
"rate": rate_text
}
movies_info.append(movie_item)
# crear el archivo json
json_file = open("movies.json", "w")
# convertir movies_info a JSON
json.dump(movies_info, json_file)
# liberar los recursos del archivo
json_file.close()Ejecuta nuestro código y luego abre la carpeta donde se encuentra el código. Verás que aparece un nuevo archivo movies.json. Ábrelo para verificar el contenido. Si encuentras que se ve así:
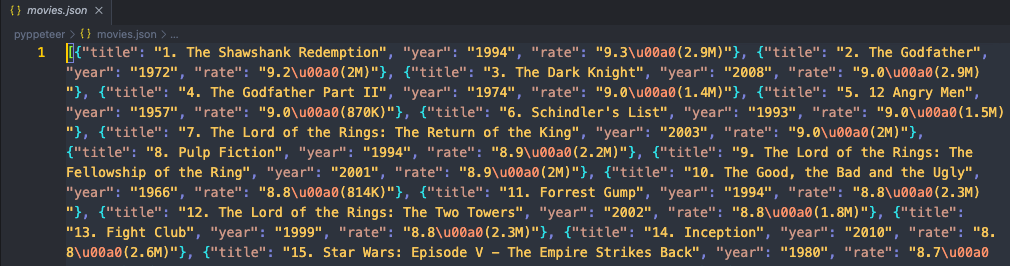
¡Eso significa que hemos rastreado con éxito el sitio web objetivo usando Pyppeteer y Nstbrowser!
4 Consejos para Resolver un Rastreador Python Bloqueado
El mayor desafío al hacer un rastreador web en Python es ser bloqueado. Muchos sitios web protegen su acceso con medidas anti-bots que reconocen y detienen aplicaciones automatizadas, impidiendo que accedan a la página.
Evita el Bloqueo Web y el Bloqueo de IP con Nstbrowser.
¡Pruébalo gratis!
Aquí hay algunas sugerencias para superar el rastreo anti-bots:
- Rotar
User-Agent: Cambiar constantemente el encabezado User-Agent en las solicitudes puede ayudar a imitar diferentes navegadores web y evitar ser detectado como un bot.
La información UA se puede cambiar modificando la configuración al iniciar Nstbrowser:
Python
config = {
'once': True,
'headless': False,
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # requerido
'name': 'navegador personalizado2',
'platform': 'mac', # soporte: windows, mac, linux
'kernel': 'chromium', # solo soporte: chromium
'kernelMilestone': '120', # soporte: 113, 115, 118, 120
'hardwareConcurrency': 8, # soporte: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 2, # soporte: 2, 4, 8
}
}-
Ejecutar durante horas fuera de pico: Iniciar el rastreador durante horas fuera de pico y agregar retrasos entre las solicitudes ayuda a evitar que el servidor web se sobrecargue y active un mecanismo de bloqueo.
-
Respetar
robots.txt: Seguir la directivarobots.txten un sitio web demuestra un comportamiento ético de rastreo. Además, ayuda a evitar el acceso a áreas restringidas y hace que las solicitudes desde scripts sean sospechosas. -
Evitar trampas de bot: No todos los enlaces son iguales y algunos de ellos esconden trampas de bot. Al seguirlos, serás marcado como un bot.
Sin embargo, estos consejos son muy útiles para escenarios simples, pero no suficientes para los más complejos. ¡Echa un vistazo a nuestro artículo más completo sobre Web scraping.
Superar todas las defensas no es fácil y requiere mucho esfuerzo. Además, una solución que funciona hoy puede no funcionar mañana. ¡Pero espera, hay mejores soluciones!
Nstbrowser ayuda a prevenir que los sitios web reconozcan y bloqueen la actividad de rastreo mediante Emulación de Navegador, Rotación de User-Agent y más. ¡Regístrate para una prueba gratuita hoy!
3 Rastreadores Web Python Populares
Hay varias herramientas útiles de rastreo web que pueden facilitar el proceso de descubrir enlaces y visitar páginas. Aquí tienes una lista de los mejores rastreadores web Python que pueden ayudarte:
-
Nstbrowser: proporciona huellas dactilares de navegador reales. Combina técnicas avanzadas de desbloqueo de sitios web y eludir bots, y puede rotar IPs de manera inteligente para reducir en gran medida la probabilidad de detección.
-
Scrapy: una de las opciones de biblioteca de rastreo Python más potentes para principiantes. Proporciona un marco avanzado para construir rastreadores escalables y eficientes.
-
Selenium: una popular biblioteca de navegador sin cabeza para rastreo web y navegación. A diferencia de BeautifulSoup, puede interactuar con páginas web en el navegador como un usuario humano.
Notas Finales
A partir de este artículo, debes tener una comprensión completa de los conceptos básicos del rastreo web. Es importante tener en cuenta que, no importa qué tan inteligente sea tu rastreador, las medidas anti-bot pueden detectarlo y bloquearlo.
Sin embargo, puedes superar cualquier desafío utilizando Nstbrowser, un navegador anti-detección todo en uno con funciones de automatización, Huella Digital del Navegador, Resolución de Captchas, Rotación de UA y muchas otras características imprescindibles para evitar ser bloqueado.
¡El rastreo nunca ha sido más fácil! ¡Comienza a usar Nstbrowser ahora para convertirte en un maestro del rastreo web!
Más





