
Web Scraping
¿Cómo utilizar Node.js para Web Scraping?
En este artículo, presentaremos cómo usar Node.js para el web scraping, incluyendo conceptos básicos, uso de herramientas y métodos antidetección para ayudar a adquirir y procesar eficientemente datos de sitios web.
May 15, 2024Robin Brown
El uso de Node.js para web scraping es una necesidad común, ya sea que desee recopilar datos de un sitio web para análisis o mostrarlos en su propio sitio. Node.js es una excelente herramienta para esta tarea.
Al leer este artículo, aprenderá:
- Comprender los conceptos básicos del web scraping
- Aprender los conceptos básicos de
Node.js - Aprender cómo usar Node.js para web scraping
¿Qué es el Web Scraping y cuáles son sus beneficios?
El web scraping es el proceso de extracción de datos de sitios web. Involucra el uso de herramientas o programas para simular el comportamiento del navegador y recuperar los datos necesarios de las páginas web. Este proceso también se conoce como cosecha web o extracción de datos web.
El web scraping tiene muchos beneficios, como:
- Ayudarlo a recopilar datos de sitios web para análisis.
- Permitirle recopilar datos de competidores durante el desarrollo de productos para analizar sus fortalezas y debilidades.
- Automatizar tareas repetitivas, como descargar todas las imágenes de un sitio o extraer todos los enlaces.
¿Qué es Node.js?
"Node.js" es un entorno de ejecución de JavaScript de código abierto y multiplataforma que ejecuta código JavaScript en el lado del servidor. Creado por Ryan Dahl en 2009, está construido sobre el motor JavaScript V8 de Chrome. Node.js está diseñado para construir aplicaciones de red escalables y de alto rendimiento, especialmente aquellas que manejan un gran número de conexiones simultáneas, como servidores web y aplicaciones en tiempo real.
Características de Node.js:
- Modelo de programación basado en eventos y asíncrono. Node.js utiliza una arquitectura basada en eventos y operaciones de E/S no bloqueantes, lo que lo hace altamente eficiente en el manejo de solicitudes concurrentes. Esto significa que el servidor no se bloqueará mientras espera que las operaciones de E/S se completen.
- Arquitectura de un solo hilo. Node.js se ejecuta en un solo hilo utilizando un bucle de eventos, que maneja las solicitudes concurrentes de manera eficiente sin el sobrecosto del cambio de contexto de hilo.
- npm (Node Package Manager). Node.js viene con npm, una herramienta de gestión de paquetes que facilita a los desarrolladores instalar y gestionar bibliotecas y herramientas necesarias para sus proyectos. Con un vasto repositorio de módulos de código abierto, npm acelera considerablemente el desarrollo.
- Multiplataforma. Node.js puede ejecutarse en varios sistemas operativos, incluidos Windows, Linux y macOS, lo que lo convierte en una plataforma de desarrollo versátil.
¿Por qué debería usar Node.js para Web Scraping?
Node.js es un entorno de ejecución de JavaScript popular que le permite usar JavaScript para el desarrollo del lado del servidor. El uso de Node.js para web scraping ofrece varias ventajas:
- Bibliotecas extensas: Node.js tiene muchas bibliotecas para web scraping, como Request, Cheerio y Puppeteer.
- Naturaleza asíncrona no bloqueante: la E/S no bloqueante de Node.js hace que el web scraping concurrente sea más fácil y eficiente.
- Manejo de tareas intensivas de E/S: Node.js se destaca en el manejo de tareas intensivas de E/S, lo que hace que el web scraping sea sencillo.
- Facilidad de aprendizaje: si conoce JavaScript, puede aprender rápidamente Node.js y comenzar a hacer web scraping.
¿Cómo usar Node.js para Web Scraping?
¡Sin más preámbulos, comencemos con el scraping de datos con Node.js!
Paso 1: Inicializar el entorno
Primero, descargue e instale Node.js desde su sitio web oficial. Siga las guías de instalación detalladas para su sistema operativo.
Paso 2: Instalar Puppeteer
Node.js ofrece muchas bibliotecas para web scraping, como Request, Cheerio y Puppeteer. Aquí, usaremos Puppeteer como ejemplo. Instale Puppeteer usando npm con los siguientes comandos:
bash
mkdir web-scraping && cd web-scraping
npm init -y
npm install puppeteer-corePaso 3: Crear un Script
Cree un archivo, como index.js, en el directorio de su proyecto y agregue el siguiente código:
- El método
goTose utiliza para abrir una página web. Toma dos parámetros: la URL de la página web para abrir y un objeto de configuración. Podemos establecer varios parámetros en este objeto, como waitUntil, que especifica regresar después de que la página haya terminado de cargar. - El método
waitForSelectorse utiliza para esperar a que aparezca un selector. Toma un selector como parámetro y devuelve un objeto Promise cuando el selector aparece en la página. Podemos usar este objeto Promise para determinar si el selector ha aparecido. - El método
contentse utiliza para obtener el contenido de la página. Devuelve un objeto Promise, que podemos usar para obtener el contenido de la página. - El método
page.$evalse utiliza para obtener el contenido de texto de un selector. Toma dos parámetros: el primero es el selector y el segundo es una función que se ejecutará en el navegador. Esta función nos permite recuperar el contenido de texto del selector.
javascript
const puppeteer = require('puppeteer');
async function run() {
const browser = await puppeteer.launch({
headless: false,
ignoreHTTPSErrors: true,
});
const page = await browser.newPage();
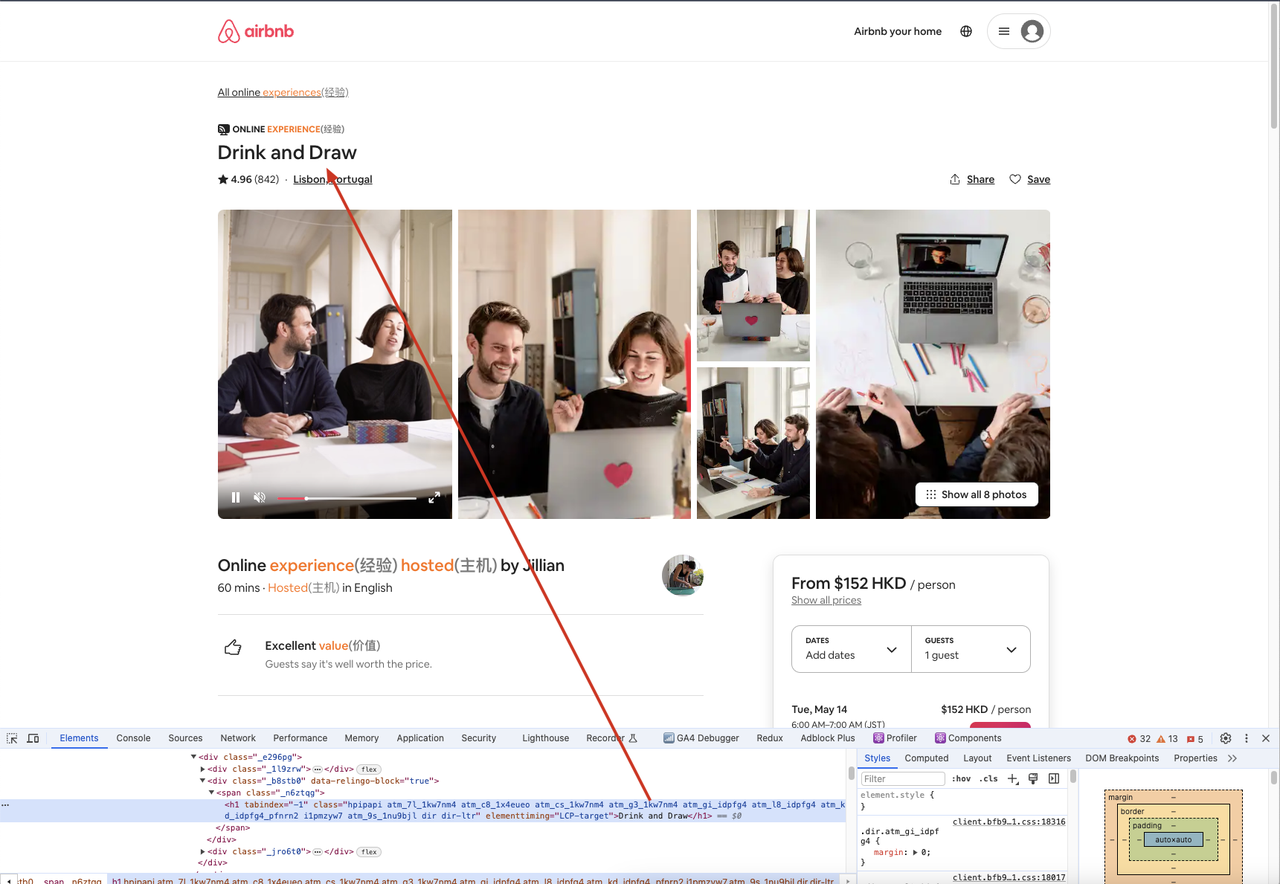
await page.goto('https://airbnb.com/experiences/1653933', {
waitUntil: 'domcontentloaded',
});
await page.waitForSelector('h1');
await page.content();
const title = await page.$eval('h1', (el) => el.textContent);
console.log(title);
await browser.close();
}
run();Paso 4: Ejecutar el Script
Ejecute index.js con el siguiente comando:
bash
node index.jsDespués de ejecutar el script, verá la salida en la terminal:

En este ejemplo, usamos puppeteer.launch() para crear una instancia del navegador, browser.newPage() para crear una nueva página, page.goto() para abrir una página web, page.waitForSelector() para esperar a que aparezca un selector y page.$eval() para obtener el contenido de texto de un selector.
Además, podemos ir al sitio rastreado a través de un navegador, abrir la herramienta de desarrollo y luego usar el selector para encontrar el elemento que necesitamos, comparando el contenido del elemento con lo que obtenemos en el código para garantizar la consistencia.
Técnicas Antidetección
Mientras utiliza Puppeteer para web scraping, algunos sitios web pueden detectar su actividad de scraping y devolver errores como 403 Forbidden. Para evitar la detección, puede utilizar varias técnicas como:
- Usar IPs de proxy
- Modificar el User-Agent
- Ejecutar en modo headless
- Personalizar fuentes y huellas de lienzo
Estos métodos ayudan a evitar la detección, permitiendo que sus tareas de web scraping continúen sin problemas. Para técnicas avanzadas antidetección, considere utilizar herramientas como Nstbrowser - Navegador Avanzado Antidetección.
Más





