
Paquete de Proxies hasta75% DTO+15% Bonocon

CAPTCHA, conocido como "Prueba de Turing pública y completamente automatizada para diferenciar entre computadoras y humanos", es una prueba para identificar si un visitante de un sitio web es una persona real.
Es una distracción que debe resolverse antes de cargar una página solicitada y viene en diferentes formas. Los sitios web los utilizan para determinar si eres un usuario real o un robot probando la precisión del usuario.
¡No te preocupes! No utilizan biometría sofisticada ni reconocimiento facial para la autenticación.
La verificación CAPTCHA ocurrirá comúnmente en las siguientes situaciones:
CAPTCHA funciona generando desafíos que son fáciles de reconocer para los humanos pero difíciles de interpretar para las computadoras. Estos desafíos generalmente implican reconocer texto distorsionado, seleccionar imágenes que contienen objetos específicos o resolver problemas de lógica simples.
Los siguientes son los pasos y mecanismos principales por los cuales CAPTCHA funciona:
1. Generar el desafío:
2. Mostrar los desafíos:
El sistema CAPTCHA genera y muestra un desafío cuando el usuario visita una página web que requiere autenticación. Se requiere que el usuario ingrese una respuesta o seleccione una imagen en un campo designado.
3. Validación de la respuesta del usuario:
Después de que el usuario envía una respuesta, el sistema compara la entrada o selección del usuario con la respuesta esperada. La validación exitosa permite al usuario proceder, mientras que la validación fallida solicita al usuario intentar nuevamente.
4. Generar nuevo desafío:
Si el usuario falla en la validación varias veces, el sistema puede generar un nuevo desafío para asegurar que es un usuario humano intentando pasar la validación.
Nstbrowser evita fácilmente la autenticación CAPTCHA para desbloquear sitios web.
¡Pruébalo gratis ahora!
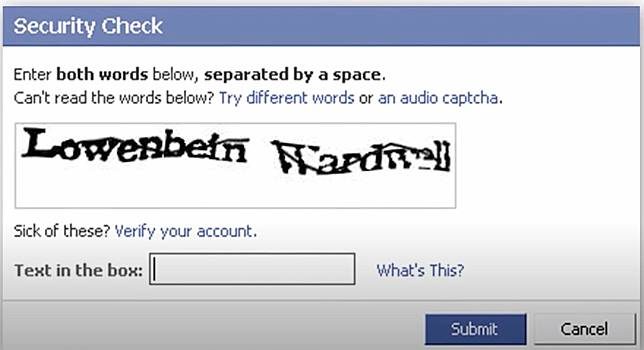
Generar una cadena de caracteres al azar y aplicar distorsiones, rotaciones, cambios de color y otros procesamientos hace que sea difícil para los algoritmos de OCR (Reconocimiento Óptico de Caracteres) interpretarlos.
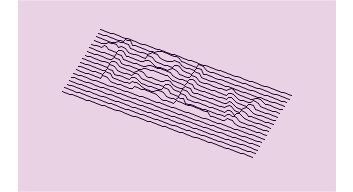
Esta nueva tecnología es una evolución del desafío de texto, utilizando caracteres en 3D, que son más difíciles de reconocer para las computadoras.
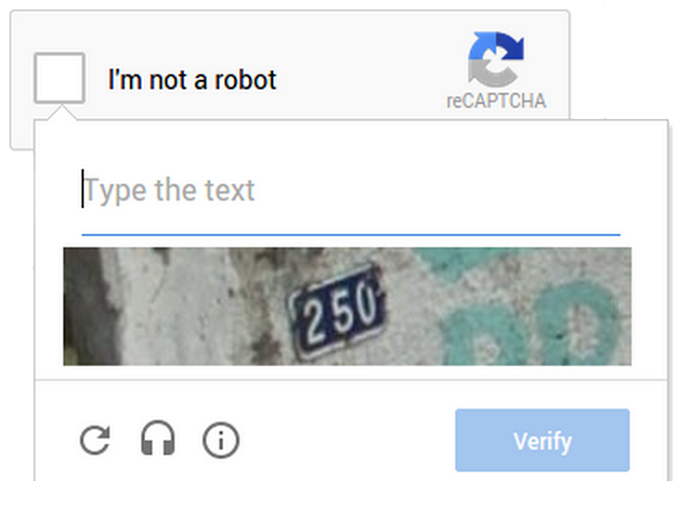
Google ofrece un sistema CAPTCHA avanzado con componentes tanto de selección de imágenes como de reconocimiento de texto.
Utiliza la verificación del usuario mientras ayuda a mejorar las técnicas de reconocimiento de imágenes y digitalización de texto.
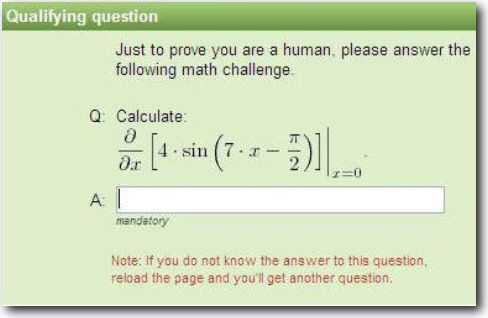
Los usuarios deben resolver ecuaciones matemáticas o preguntas de cálculo para lograr la validación.
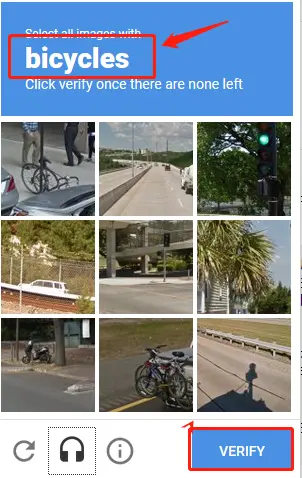
Al iniciar sesión, el sistema muestra un conjunto de imágenes y pide al usuario seleccionar la imagen que contiene un objeto específico. Este enfoque utiliza técnicas de aprendizaje profundo para analizar qué tan bien coincide la elección del usuario con la respuesta esperada.
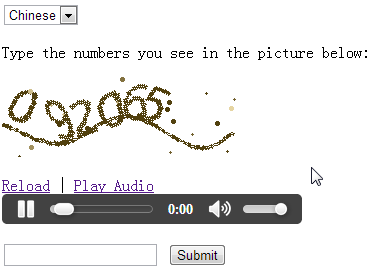
Este tipo de verificación está diseñado para usuarios con discapacidad visual. El sistema de verificación reproduce un clip de audio que contiene letras o números que el usuario debe escuchar e ingresar.
Las trampas Honeypot son una estrategia para prevenir que los bots rastreen contenido mediante el uso de enlaces o formularios ocultos para detectar y marcar herramientas automatizadas. Por lo tanto, si haces clic en ellos, serás marcado como un rastreador.
Asegúrate de que los scripts del rastreador ignoren los elementos que tienen propiedades CSS como display: none o visibility: hidden. Estos elementos se pueden filtrar utilizando el siguiente selector:
hidden_elements = driver.find_elements_by_css_selector("[style*='display:none'], [style*='visibility:hidden']")El rastreador también debe omitir formularios ocultos y cajas de entrada:
hidden_forms = driver.find_elements_by_css_selector("input[type='hidden']")Antes de hacer clic en los enlaces, verifica si tienen atributos ocultos:
links = driver.find_elements_by_tag_name("a")
for link in links:
if "display:none" in link.get_attribute("style") or "visibility:hidden" in link.get_attribute("style"):
continue # Omitir el enlace oculto
link.click() # Hacer clic en el enlace visiblerobots.txtSigue las reglas en el archivo robots.txt de tu sitio web para evitar rastrear secciones prohibidas.
Simula el comportamiento real del usuario, como hacer clic y desplazarse a intervalos aleatorios, para evitar ser detectado como un rastreador.
Analiza regularmente los registros del rastreador para ver si está bloqueado o redirigido, de modo que puedas ajustar la estrategia.
Reconocer correctamente los encabezados de solicitud es una forma común de detectar rastreadores web, especialmente al usar navegadores sin cabeza como Selenium y Puppeteer. Para evitar ser reconocido como un rastreador, se puede modificar el encabezado User-Agent para imitar el navegador de un usuario real.
¡Un gran número de solicitudes desde el mismo encabezado HTTP en un corto período de tiempo debe ser sospechoso, verdad?
¡Un gran número de solicitudes provenientes de la misma dirección IP también es sospechoso! Porque los usuarios reales no son capaces de visitar 1000 páginas web en cinco minutos.
Para convencer al sitio web de que eres un usuario real, rota tu encabezado o dirección IP para no ser fácilmente reconocido por el sitio web.
Nstbrowser está diseñado con rotación inteligente de IP para evitar el bloqueo web.
¡Pruébalo gratis ahora!
¿Tienes ideas y dudas interesantes sobre el web scraping y el Browserless?
¡Veamos qué comparten otros desarrolladores en Discord y Telegram!
Nstbrowserless proporciona una forma eficiente de ejecutar scripts de automatización de navegador sin cabeza mientras evita la detección como un rastreador. Este servicio de navegador sin cabeza basado en la nube imita el comportamiento de los usuarios reales para ayudar a evitar CAPTCHA y otros mecanismos anti-rastreador.
Nstbrowser resuelve fácilmente el reconocimiento CAPTCHA con la ayuda de Selenium y Puppeteer. Te permite acceder y rastrear el sitio sin problemas.
La mayoría de las herramientas de automatización de navegadores como Selenium y Puppeteer tienen algunas banderas específicas como navigator.webdriver que exponen el hecho de que son herramientas de automatización.
Aquí es donde necesitas usar un complemento como Puppeteer-stealth para ocultar efectivamente estos rastros.
Finalmente, los sitios web rastrean la navegación del usuario, los elementos de flotación e incluso las coordenadas de clic para analizar el comportamiento del usuario. Por lo tanto, imitar el comportamiento de navegación humano real es muy importante para evitar la detección
.
Algunos de los comportamientos que puedes intentar configurar son:
¿Qué es CAPTCHA, por qué ocurre y cómo evitarlo? Has aprendido el conocimiento más completo sobre CAPTCHA en este artículo. Rotar tu encabezado y IP es la forma más efectiva y fácil de evitar CAPTCHA.
Para facilitarte el rastreo web, usa Nstbrowser para desbloquear sitios web fácilmente, rotar IPs de manera inteligente y evitar la validación CAPTCHA.





