Web Crawling con Java en 2024 - ¡La guía más detallada!
Esta guía se centra en el rastreo web con Java en 2024. Proporciona tutoriales detallados paso a paso. ¡Empieza a explorar ahora!
May 10, 2024Carlos Rivera
Tutorial básico de Web Scraping
Esta guía se centra en el web scraping con Java en 2024. Proporciona un tutorial paso a paso sobre cómo extraer datos de sitios web utilizando el sitio Scrapeme como ejemplo. Utilizando Java y la biblioteca jsoup, aprenderá a raspar recursos estáticos de páginas web y recuperar información específica como nombres de productos, imágenes, precios y detalles.
Esta guía le proporcionará los conocimientos necesarios para extraer datos de sitios web similares y le servirá de base para técnicas de extracción web más avanzadas.
Prepárese para aprovechar la potencia de Java para el web scraping en esta era moderna.
Requisitos del entorno:
Es importante tener en cuenta que ya que vamos a utilizar Java para el proyecto de demostración en este artículo, por favor asegúrese de que tiene los siguientes requisitos previos en su lugar antes de continuar:
Entorno recomendado:
Java: Cualquier versión 8+ LTS
Herramientas de compilación: Cualquier versión de Gradle o Maven compatible con su versión local de Java
IDE: Cualquiera de tus preferencias, como Eclipse, IntelliJ IDEA, VS Code
Nota: Se omite el proceso de instalación del entorno.
Entorno Case:
JDK 21
javascriptCopy
# java -version
java version "21.0.2" 2024-01-16 LTS
Java(TM) SE Runtime Environment (build 21.0.2+13-LTS-58)
Java HotSpot(TM) 64-Bit Server VM (build 21.0.2+13-LTS-58, mixed mode, sharing)
Herramientas de compilación: Gradle
javascriptCopy
# gradle -version
Gradle 8.7
Build time: 2024-03-22 15:52:46 UTC
Revision: 650af14d7653aa949fce5e886e685efc9cf97c10
Kotlin: 1.9.22
Groovy: 3.0.17
Ant: Apache Ant(TM) version 1.10.13 compiled on January 4 2023
JVM: 21.0.2 (Oracle Corporation 21.0.2+13-LTS-58)
OS: Mac OS X 14.4.1 aarch64
IDE: IntelliJ IDEA
Creación de proyectos
Información del proyecto:
Después de la creación, su proyecto puede tener este aspecto:
Se añaden dependencias y, por el momento, bastará con jsoup (jsoup: Java HTML Parser):
Ha llegado el momento de rastrear el sitio web. Aquí voy a rastrear el ScrapeMe, sólo como referencia. Puedes revisar todo el progreso y luego terminar tu proyecto.
Análisis del sitio objetivo:
En primer lugar, vamos a echar un vistazo a los datos que queremos raspar desde el sitio Scrapeme. Abra el sitio en un navegador y ver el código fuente para analizar los elementos de destino. A continuación, recuperar los elementos deseados a través de código.
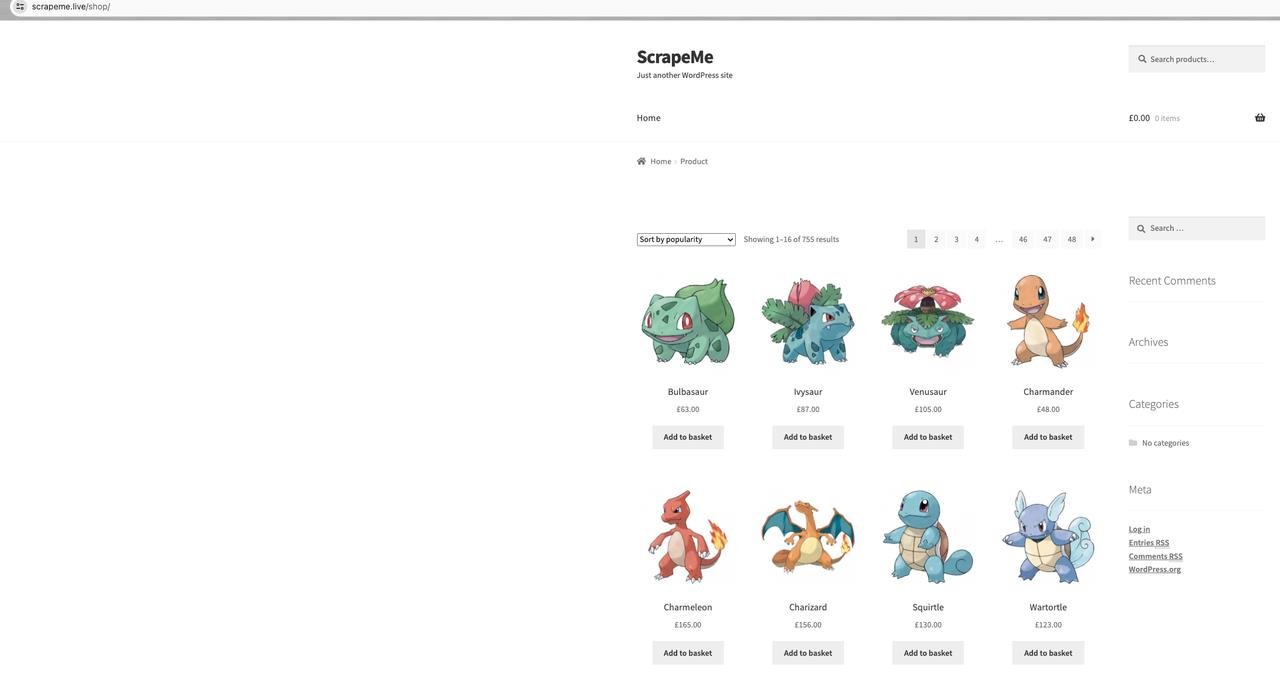
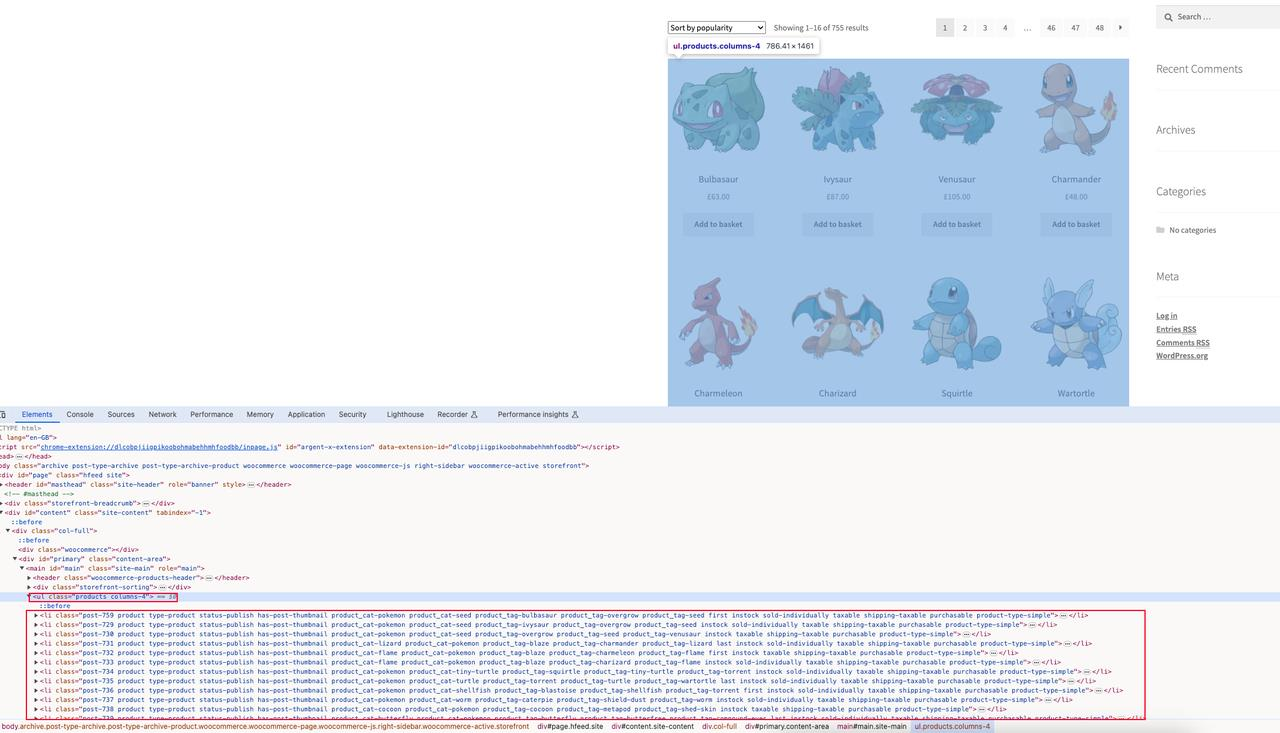
Lista de productos de la página de inicio de ScrapeMe:
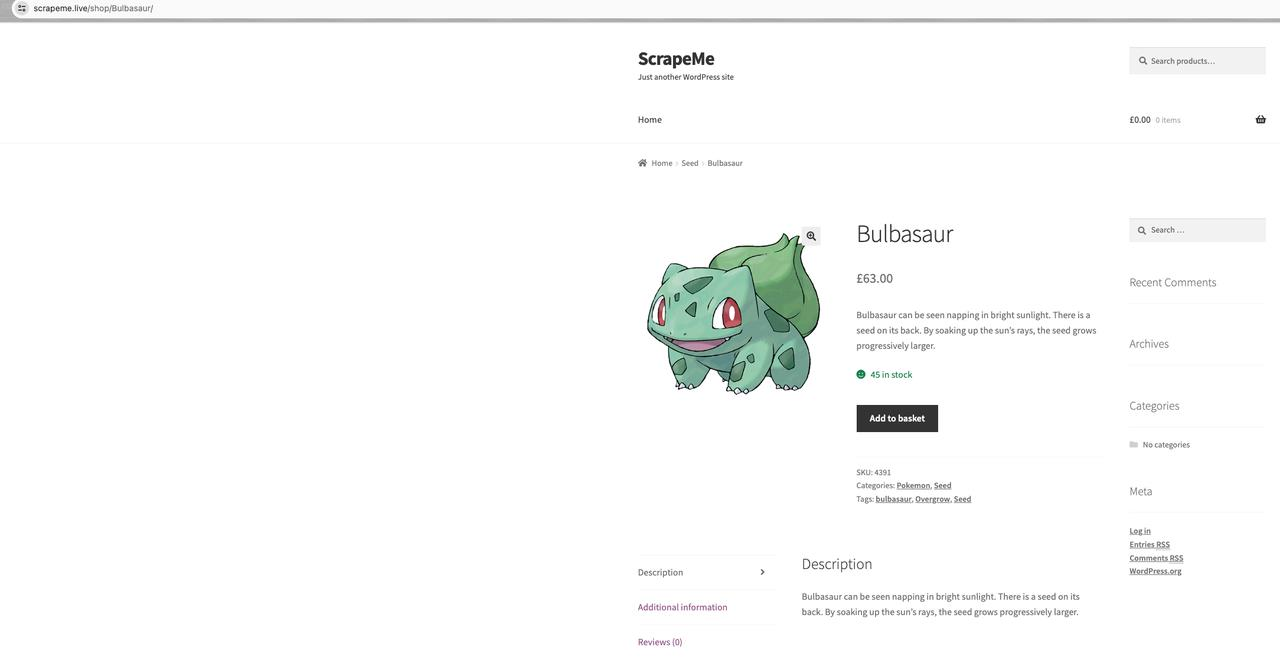
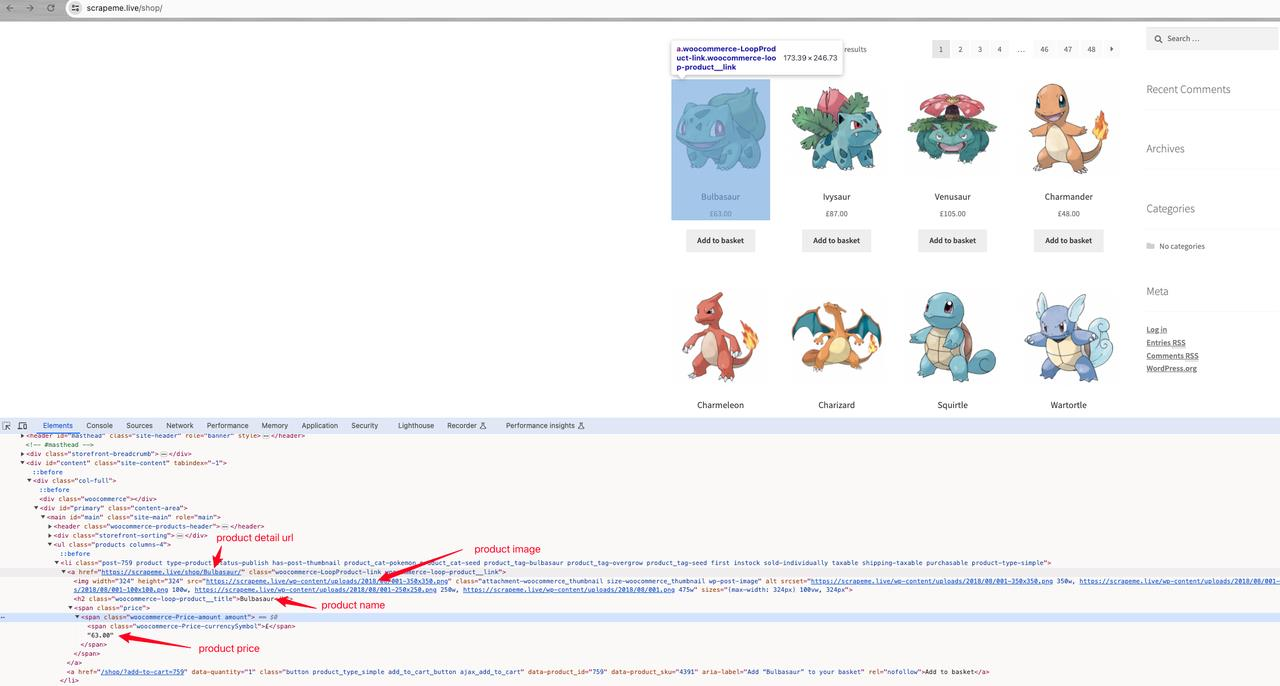
ScrapeMe Detalles del producto:
Nuestro objetivo es rastrear la página de inicio de la información de estos productos, incluido el nombre del producto, las imágenes del producto, el precio del producto y la dirección de los detalles del producto.
Análisis del código fuente de la página
Elementos de la página
Observando el análisis de elementos de página, sabemos que la página actual tiene todos los elementos de página de producto: ul.products, y cada elemento de detalle de producto: li.product.
Detalles del producto
Un análisis más detallado encuentra el nombre del producto: a h2, la imagen del producto: a img.src, el precio del producto: a span, la dirección de los detalles del producto: a.href.
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.*;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class Scraper {
// scrapeme site url
private static final String SCRAPEME_SITE_URL = "https://scrapeme.live/shop";
public static List<ScrapeMeProduct> scrape() {
// html doc for scrapeme page
Document doc;
// products data
List<ScrapeMeProduct> pokemonProducts = new ArrayList<>();
try {
doc = Jsoup.connect(SCRAPEME_SITE_URL)
.userAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36") // mock userAgent header
.header("Accept-Language", "*") // mock Accept-Language header
.get();
// select product nodes
Elements products = doc.select("li.product");
for (Element product : products) {
ScrapeMeProduct pokemonProduct = new ScrapeMeProduct();
pokemonProduct.setUrl(product.selectFirst("a").attr("href")); // parse and set product url
pokemonProduct.setImage(product.selectFirst("img").attr("src")); // parse and set product image
pokemonProduct.setName(product.selectFirst("h2").text()); // parse and set product name
pokemonProduct.setPrice(product.selectFirst("span").text()); // parse and set product price
pokemonProducts.add(pokemonProduct);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
return pokemonProducts;
}
}
Main.java
javaCopy
import io.xxx.basic.ScrapeMeProduct;
import io.xxx.basic.Scraper;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<ScrapeMeProduct> products = Scraper.scrape();
products.forEach(System.out::println);
// continue coding
}
}
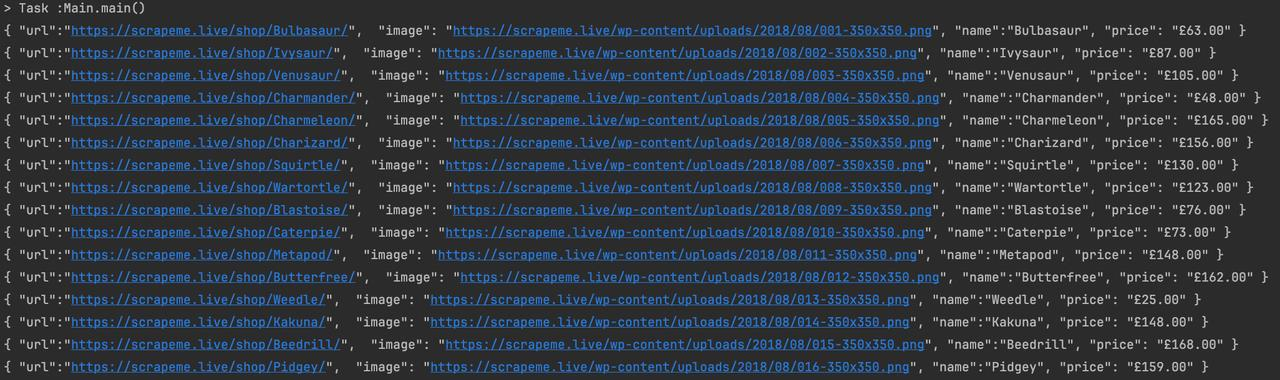
Resultados Expresión
Conclusión
Hasta ahora hemos aprendido a utilizar Java para el rastreo de datos de páginas estáticas simple, el siguiente vamos a ser avanzado sobre esta base, utilizando Java concurrente rastreo ScrapeMe sobre todo los datos del producto , así como el uso de código Java conectado al navegador Nstbrowser para el rastreo de datos , porque el capítulo avanzado se utilizará para Nstbrowser en el navegador sin cabeza y otras características.