
Web Scraping
¿Cómo utilizar Go para el web scraping?
Go, también conocido como Golang, proporciona una velocidad de compilación y un rendimiento en tiempo de ejecución eficientes. A través de este tutorial paso a paso, usted aprenderá cómo hacer web scraping con Go.
May 20, 2024
Go, también conocido como Golang, se refiere a un lenguaje de programación de código abierto desarrollado por Google para mejorar la eficiencia y la velocidad de la programación, especialmente al manejar tareas concurrentes. Go combina los beneficios de los lenguajes tipados estáticamente y dinámicamente para proporcionar una velocidad de compilación eficiente y un rendimiento en tiempo de ejecución.
¿Cómo construir un Web Scraper usando la biblioteca Colly en el lenguaje de programación Go? Nstbrowser explicará el código para entender cada parte.
¡No perdamos más tiempo! Descubre los pasos detallados ahora.
¿Por qué usar Go para el Web Scraping?
- Claro y conciso. La sintaxis de Go está diseñada para ser simple y fácil de aprender y usar, reduciendo la complejidad del código.
- Soporte de concurrencia incorporado. Go proporciona potentes capacidades de programación concurrente a través de goroutines y canales, lo que facilita el desarrollo de aplicaciones concurrentes de alto rendimiento.
- Recolección de basura. Go tiene un mecanismo automático de recolección de basura para ayudar a gestionar la memoria y mejorar la eficiencia del desarrollo.
Preparación
Instalando Go
Antes de hacer scraping, configuremos nuestro proyecto en Go. Voy a tomar unos segundos para discutir cómo instalarlo. Así que, si ya has instalado Go, revisa nuevamente.
Dependiendo de tu sistema operativo, puedes encontrar instrucciones de instalación en la página de documentación de Go. Si eres usuario de macOS y usas Brew, puedes ejecutarlo en la Terminal:
bash
brew install goEnsamblando el proyecto
Crea un nuevo directorio para tu proyecto, muévete a este directorio y ejecuta el siguiente comando donde puedes reemplazar la palabra webscraper con cualquier módulo que desees nombrar.
bash
go mod init webscraper- Nota: El comando
go mod initcrea un nuevo módulo Go en el directorio donde se ejecuta. Crea un nuevo archivogo.modque define las dependencias y gestiona las versiones de los paquetes de terceros utilizados en el proyecto (similar a package.json si usas node).
Ahora puedes configurar tus scripts de web scraping en Go. Crea un archivo scraper.go y inicialízalo de la siguiente manera:
Go
package main
import (
"fmt"
)
func main() {
// scraping logic...
fmt.Println("Hello, World!")
}La primera línea contiene el nombre del paquete global. Luego hay algunas importaciones, seguidas de la función main(). Esta representa el punto de entrada para cualquier programa Go y contendrá la lógica de web scraping en Golang. Luego, puedes iniciar el programa:
bash
go run scraper.goEsto imprimirá:
PlainText
Hello, World!Ahora que has construido un proyecto básico en Go, profundicemos en la construcción de un web scraper usando Golang!
Construyendo un Web Scraper con Go
A continuación, tomemos ScrapeMe como un ejemplo de cómo hacer scraping de páginas con Go.
Paso 1. Instalar Colly
Para construir un web scraper más fácilmente, deberías usar uno de los paquetes introducidos anteriormente. Sin embargo, necesitas determinar qué biblioteca de web scraping en Golang se adapta mejor a tus objetivos desde el principio.
Para hacer esto necesitas:
- Visita tu sitio web objetivo.
- Haz clic derecho en el fondo.
- Selecciona la opción Inspeccionar. Esto abrirá DevTools en tu navegador.
- En la pestaña Red, mira la sección Fetch/XHR.
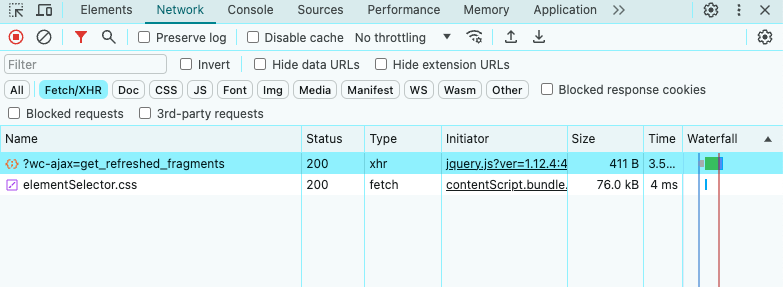
Como puedes ver arriba, la página objetivo solo realiza algunas solicitudes AJAX. Si estudias cada solicitud XHR, notarás que no devuelven datos significativos. En otras palabras, el servidor devuelve un documento HTML que ya contiene todos los datos. Esto es lo que suele ocurrir con los sitios de contenido estático.
Esto significa que el sitio objetivo no depende de JavaScript para recuperar datos dinámicamente o renderizarlos. Por lo tanto, no necesitas una biblioteca con capacidades de navegador sin cabeza para recuperar datos de la página objetivo. Aún puedes usar Selenium, pero esto solo introduce una sobrecarga de rendimiento. Por esta razón, deberías preferir un simple analizador HTML como Colly.
Ahora instalemos Colly y sus dependencias:
bash
go get -u github.com/gocolly/collyEste comando también actualizará el archivo go.mod con todas las dependencias necesarias y creará el archivo go.sum.
Colly es un paquete Go que te permite escribir Web Scrapers y crawlers, construido sobre el paquete net/HTTP de Go para la comunicación de red, y te ayuda a usar
goquery, que proporciona una sintaxis similar a “jQuery” para posicionar elementos HTML.
Antes de comenzar a usarlo, necesitas profundizar en algunos conceptos clave de Colly:
La entidad principal en Colly es el Collector, un objeto que te permite hacer solicitudes HTTP y realizar web scraping con las siguientes callbacks:
OnRequest(): llamado antes de cualquier solicitud HTTP usando Visit().OnError(): llamado si ocurre un error en la solicitud HTTP.OnResponse(): llamado después de obtener una respuesta del servidor.OnHTML(): llamado después de OnResponse() si el servidor devuelve un documento HTML válido.OnScraped(): llamado al final de todas las llamadas OnHTML().
Cada una de estas funciones toma una callback como parámetro. Colly ejecuta la callback de entrada cuando se produce el evento asociado con la función. Por lo tanto, para construir un scraper de datos en Colly, necesitas seguir el enfoque basado en funciones callback.
Puedes usar la función NewCollector() para inicializar el objeto Collector:
Go
c := colly.NewCollector()Importa Colly y crea el Collector actualizando scraper.go de la siguiente manera:
Go
// scraper.go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
// scraping logic...
}Paso 2. Conectar al Sitio Web Objetivo
Usa Colly para conectarte a la página objetivo con:
go
c.Visit("https://scrapeme.live/shop/")En el back office, la función Visit() realiza una solicitud HTTP GET y recupera el documento HTML objetivo del servidor. Específicamente, activa el evento onRequest y comienza el ciclo de vida de la función Colly. Ten en cuenta que Visit() debe ser llamado después de registrar las otras callbacks de Colly.
Nota que la solicitud HTTP realizada por Visit() puede fallar. Cuando esto sucede, Colly activa el evento OnError. La razón de este fallo puede ser un servidor temporalmente no disponible o una URL inválida, mientras que los web scrapers a menudo fallan cuando el sitio objetivo toma medidas anti-robot. Por ejemplo, estas técnicas generalmente filtran solicitudes que no tienen un encabezado HTTP User-Agent válido.
¿Qué causa eso?
Típicamente, Colly establece un User-Agent de marcador de posición que no coincide con el proxy utilizado por los navegadores populares. Esto hace que las solicitudes de Colly sean fácilmente identificables por las tecnologías anti-scraping. Para evitar ser bloqueado, especifica un encabezado User-Agent válido en Colly, como se muestra a continuación:
go
c.UserAgent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"¿Buscas una solución más eficiente?
Nstbrowser tiene una API completa de web crawler para manejar todos los obstáculos anti-bot por ti.
¡Pruébalo totalmente gratis!
Cualquier llamada a Visit() ahora realizará una solicitud con ese encabezado HTTP.
Tu archivo scraper.go ahora debería verse así:
go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
// creating a new Colly instance
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
// visiting the target page
c.Visit("https://scrapeme.live/shop/")
// scraping logic...
}Paso 3. Examinar la Página HTML y Capturar Datos
Ahora necesitamos navegar y analizar el DOM de la página web objetivo para localizar los datos que necesitamos extraer. Como resultado, podemos adoptar una estrategia efectiva de recuperación de datos.
- Haz clic derecho en una de las tarjetas HTML y selecciona “Inspeccionar”:
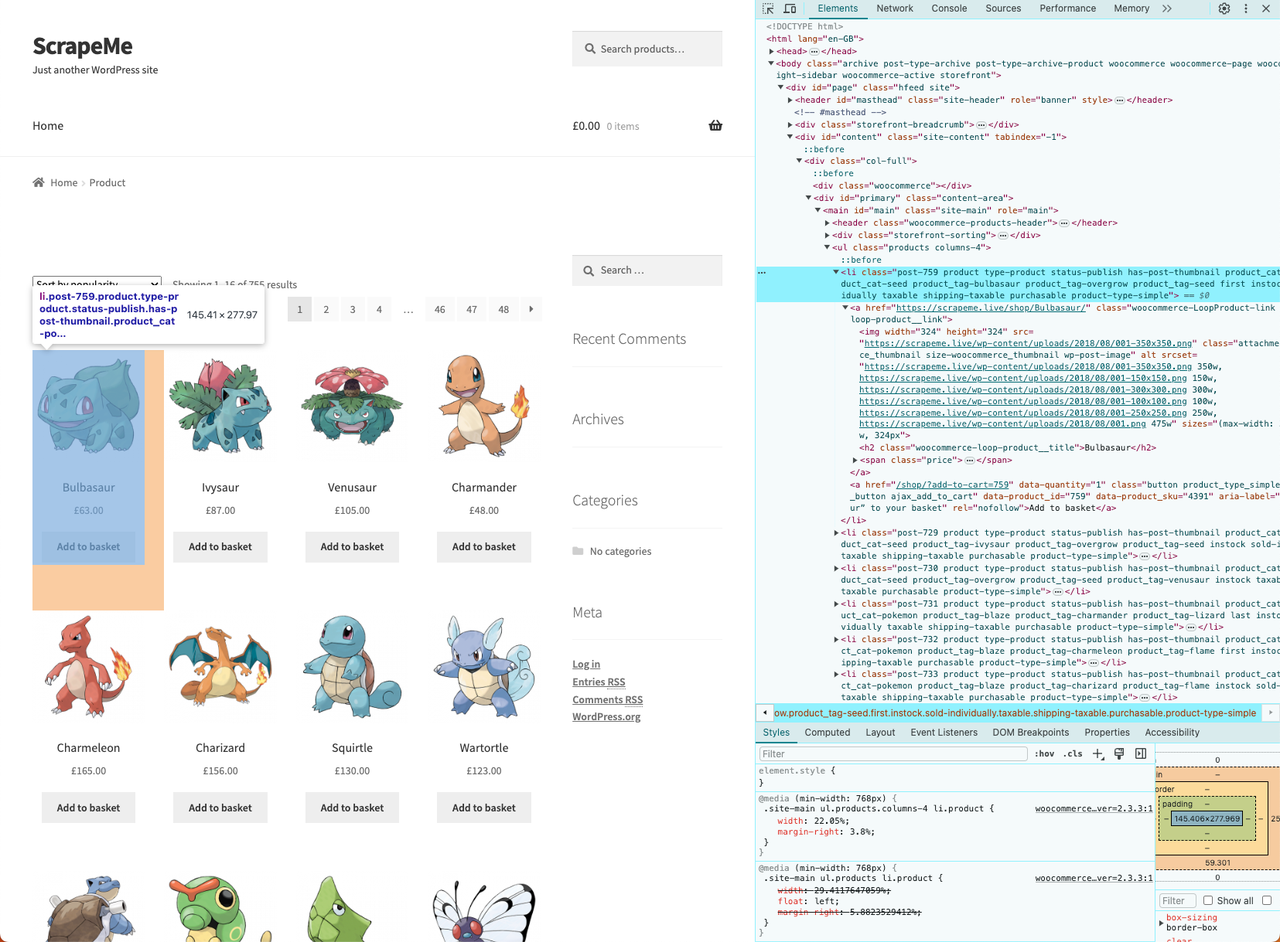
Hemos descubierto su estructura HTML, antes de hacer scraping, necesitas una estructura de datos para almacenar los datos extraídos.
- Define la estructura PokemonProduct de la siguiente manera:
go
// defining a data structure to store the scraped data
type PokemonProduct struct {
url, image, name, price string
}- Luego, inicializa una slice de
PokemonProductque contendrá los datos extraídos:
go
// initializing the slice of structs that will contain the scraped data
var pokemonProducts []PokemonProductEn Go, las slices proporcionan una forma eficiente de trabajar con secuencias de datos tipados. Puedes pensar en ellas como una especie de listas.
- Ahora, implementa la lógica de scraping:
go
// iterating over the list of HTML product elements
c.OnHTML("li.product", func(e *colly.HTMLElement) {
// initializing a new PokemonProduct instance
pokemonProduct := PokemonProduct{}
// scraping the data of interest
pokemonProduct.url = e.ChildAttr("a", "href")
pokemonProduct.image = e.ChildAttr("img", "src")
pokemonProduct.name = e.ChildText("h2")
pokemonProduct.price = e.ChildText(".price")
// adding the product instance with scraped data to the list of products
pokemonProducts = append(pokemonProducts, pokemonProduct)
})La interfaz HTMLElement expone los métodos ChildAttr() y ChildText(). Estos permiten extraer el texto del valor del atributo correspondiente desde el objeto hijo identificado por el selector CSS, respectivamente. Configurando dos funciones simples, has implementado toda la lógica de extracción de datos.
- Finalmente, puedes usar append() para adjuntar un nuevo elemento a la slice del elemento capturado.
Paso 4. Convertir los Datos Capturados a CSV
La lógica para exportar los datos extraídos a un archivo CSV usando Go es la siguiente:
go
// opening the CSV file
file, err := os.Create("products.csv")
if err != nil {
log.Fatalln("Failed to create output CSV file", err)
}
defer file.Close()
// initializing a file writer
writer := csv.NewWriter(file)
// defining the CSV headers
headers := []string{
"url",
"image",
"name",
"price",
}
// writing the column headers
writer.Write(headers)
// adding each Pokemon product to the CSV output file
for _, pokemonProduct := range pokemonProducts {
// converting a PokemonProduct to an array of strings
record := []string{
pokemonProduct.url,
pokemonProduct.image,
pokemonProduct.name,
pokemonProduct.price,
}
// writing a new CSV record
writer.Write(record)
}
defer writer.Flush()- Nota: Este fragmento de código crea un archivo products.csv y lo renombra usando la columna de título. Luego, itera sobre las slices de PokemonProduct capturados, convierte cada uno de ellos en un nuevo registro CSV y lo agrega al archivo CSV.
Para que este fragmento de código funcione, asegúrate de tener las siguientes importaciones:
go
import (
"encoding/csv"
"log"
"os"
// ...
)Presentación del código completo
Aquí está el código completo para scraper.go:
go
package main
import (
"encoding/csv"
"log"
"os"
"github.com/gocolly/colly"
)
// initializing a data structure to keep the scraped data
type PokemonProduct struct {
url, image, name, price string
}
func main() {
// initializing the slice of structs to store the data to scrape
var pokemonProducts []PokemonProduct
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
// creating a new Colly instance
c := colly.NewCollector()
// visiting the target page
c.Visit("https://scrapeme.live/shop/")
// scraping logic
c.OnHTML("li.product", func(e *colly.HTMLElement) {
pokemonProduct := PokemonProduct{}
pokemonProduct.url = e.ChildAttr("a", "href")
pokemonProduct.image = e.ChildAttr("img", "src")
pokemonProduct.name = e.ChildText("h2")
pokemonProduct.price = e.ChildText(".price")
pokemonProducts = append(pokemonProducts, pokemonProduct)
})
// opening the CSV file
file, err := os.Create("products.csv")
if err != nil {
log.Fatalln("Failed to create output CSV file", err)
}
defer file.Close()
// initializing a file writer
writer := csv.NewWriter(file)
// writing the CSV headers
headers := []string{
"url",
"image",
"name",
"price",
}
writer.Write(headers)
// writing each Pokemon product as a CSV row
for _, pokemonProduct := range pokemonProducts {
// converting a PokemonProduct to an array of strings
record := []string{
pokemonProduct.url,
pokemonProduct.image,
pokemonProduct.name,
pokemonProduct.price,
}
// adding a CSV record to the output file
writer.Write(record)
}
defer writer.Flush()
}Ejecuta tu scraper de datos en Go con:
bash
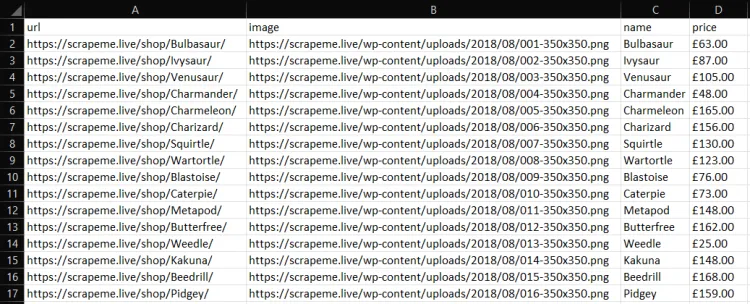
go run scraper.goLuego, encontrarás un archivo products.csv en el directorio raíz de tu proyecto. Ábrelo, y debería contener:
Otras Bibliotecas Efectivas para Web Scraping
- Nstbrowser: Equipado con una API integral de web scraping, maneja todos los obstáculos anti-bot por ti. También fue diseñado con un navegador sin cabeza, bypass de captcha y muchas más características.
- Chromedp: Una forma más rápida y sencilla de controlar navegadores que soportan el Chrome DevTools Protocol.
- GoQuery: Una biblioteca de Go que ofrece una sintaxis y un conjunto de características similares a jQuery. Puedes usarla para realizar web scraping tal como lo harías en jQuery.
- Seleniumum: Probablemente el navegador sin cabeza más conocido, ideal para scraping de contenido dinámico. No ofrece soporte oficial, pero hay un port para usarlo en Go.
- Ferret: Un sistema de web scraping portátil, extensible y rápido que busca simplificar la extracción de datos de la web. Ferret permite a los usuarios centrarse en los datos y se basa en un lenguaje declarativo único.
Conclusión
En este tutorial,
- has aprendido no solo qué es un web scraper,
- sino también cómo construir tu propia aplicación de web scraping usando Colly y las bibliotecas estándar de Go.
Como puedes ver en este tutorial, el web scraping con Go se puede lograr con unas pocas líneas de código limpio y eficiente.
Sin embargo, también es importante darse cuenta de que extraer datos de Internet no siempre es fácil. Hay una variedad de desafíos que puedes encontrar en el proceso. Muchos sitios web han adoptado soluciones anti-scraping y anti-bot que pueden detectar y bloquear tus scripts de crawling en Go.
La mejor práctica es usar una API de web crawling, como Nstbrowser, una solución totalmente gratuita que te permite evitar todos los sistemas anti-bot con una sola llamada a la API, como una solución para evitar el problema de ser bloqueado mientras realizas tus tareas de crawling.
Más





