
Web Scraping
The Best User Agent for Web Scraping 2024 | Avoid Getting UA banned When Scraping
You must hear about the "User Agent" many times. Do you know what a user agent is? How does it affect our online lives? Get the answer in this blog.
Jun 07, 2024Carlos Rivera
Are you a frequent web scraper? Are you very careful about your privacy? Then you must hear about the "User Agent" many times. Do you know what a user agent is? How does it affect our online lives?
Start reading and you'll be interested in everything in this blog!
What's My User Agent?
A User Agent (UA) is a string that a browser or other client software sends to a web server. It can provide information about the user's device and software environment.
This string is included in the HTTP header of the web request and helps the server to provide appropriate content based on the user's specific configuration.
In other words, the user agent string helps to recognize the user's browser, device type, and operating system being used.
Why Is the User Agent Important for Web Scraping?
User agents are critical to web scraping because they help simulate human browsing behavior. And they can make your crawling tools look like legitimate browsers and thus avoiding detection and blocking by websites.
By using appropriate or randomly varying user agent strings, scrapers can bypass access restrictions, fetch the correct version of web content, and reduce the risk of being blocked.
- Note: Using the wrong user agent can cause the data extraction script to be blocked.
Your web scraper is blocked once and again?
Nstbrowser handles comprehensive web unblocker solutions
Try for FREE Now!
Do you have any wonderful ideas and doubts about web scraping and Browserless?
Let's see what other developers are sharing on Discord and Telegram!
What Are the Best User Agents for Scraping?
If the UA can mimic popular and commonly used browsers, they would be regarded as best user agents for web scraping. Here are some of them:
Desktop User Agents
- Google Chrome on Windows
SCSS
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36- Mozilla Firefox on Windows
Plain
Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0- Microsoft Edge on Windows
SCSS
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.59- Safari on macOS
SCSS
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15Mobile User Agents
- Google Chrome on Android
SCSS
Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Mobile Safari/537.36- Safari on iPhone
SCSS
Mozilla/5.0 (iPhone; CPU iPhone OS 14_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Mobile/15E148 Safari/604.1- Mozilla Firefox on Android
Plain
Mozilla/5.0 (Android 11; Mobile; rv:89.0) Gecko/89.0 Firefox/89.0How to Set a User Agent for Web Scraping?
1. User Agent sample code
There are many ways to customize the browser User Agent, the following is a list of common custom User Agent sample codes in the mainstream development languages:
Javascript
- Puppeteer
JavaScript
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36');
await page.goto('https://example.com');
const content = await page.content();
console.log(content);
await browser.close();
})();- Axios
JavaScript
const axios = require('axios');
const fetchData = async () => {
try {
const response = await axios.get('https://example.com', {
headers: {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36'
}
});
console.log(response.data);
} catch (error) {
console.error(error);
}
};Python
- Puppeteer
Python
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36'
}
response = requests.get('https://example.com', headers=headers)
print(response.content)- Selenium library
Python
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36')
driver = webdriver.Chrome(options=options)
driver.get('https://example.com')Java
- HttpClient
Java
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
public class WebScraping {
public static void main(String[] args) throws Exception {
String url = "https://example.com";
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet request = new HttpGet(url);
request.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36");
CloseableHttpResponse response = httpClient.execute(request);
Document doc = Jsoup.parse(response.getEntity().getContent(), "UTF-8", url);
System.out.println(doc.html());
response.close();
httpClient.close();
}
}- Selenium
Java
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class WebScrapingWithChrome {
public static void main(String[] args) {
System.setProperty("webdriver.chrome.driver", "path/to/chromedriver");
ChromeOptions options = new ChromeOptions();
options.addArguments("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36");
WebDriver driver = new ChromeDriver(options);
driver.get("https://example.com");
String pageSource = driver.getPageSource();
System.out.println(pageSource);
driver.quit();
}
}Go
- net/http group
Go
package main
import (
"fmt"
"io/ioutil"
"net/http"
)
func main() {
client := &http.Client{}
req, _ := http.NewRequest("GET", "https://example.com", nil)
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36")
resp, _ := client.Do(req)
defer resp.Body.Close()
body, _ := ioutil.ReadAll(resp.Body)
fmt.Println(string(body))
}2. Set with Nstbrowser
No matter which programming language or tool is used in the above example, the UserAgent field in the HTTP request header is set or modified by methods or configurations in the corresponding libraries.
Some anti-detect browsers also support customizing the User-Agent, and the following is an example to show how to customize the User-Agent through fingerprint browsers Nstbrowser is used as an example to show how to customize UserAgent by fingerprint browser:
Customize the User Agent by clicking “Create” directly from the “Profile” panel in the UI.
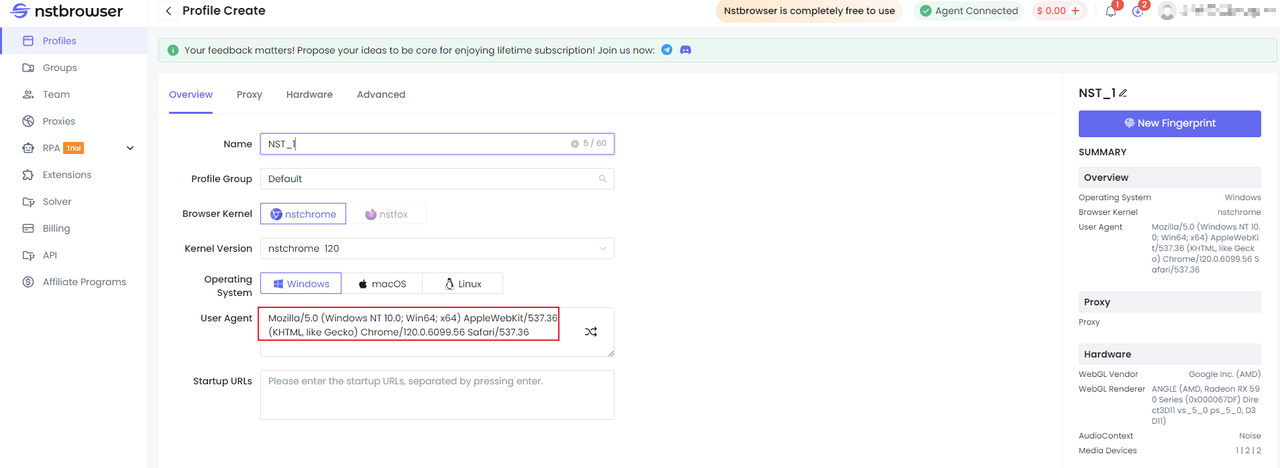
Nstbrowser API
You can also customize UserAgent through API methods such as LaunchBrowser, CreateProfile, Nstbrowser Puppeteer, etc., where the code for using the Puppeteer method is as follows:
JavaScript
import puppeteer from 'puppeteer-core';
// LaunchExistBrowser: Connect to or start an existing browser
// You need to create the corresponding profile in advance
// Support custom config
async function launchAndConnectToBrowser(profileId) {
const host = 'localhost:8848';
const apiKey = 'your api key';
const config = {
headless: true,
autoClose: true,
fingerprint: {
name: 'browser113',
platform: 'windows',
kernel: 'chromium',
kernelMilestone: '120',
hardwareConcurrency: 4,
deviceMemory: 8,
proxy: '',
userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.6099.56 Safari/537.36',
}
};
const query = new URLSearchParams({
'x-api-key': apiKey, // required
config: encodeURIComponent(JSON.stringify((config))),
});
const browserWSEndpoint = `ws://${host}/devtool/launch/${profileId}?${query.toString()}`;
console.log('browserWSEndpoint: ', browserWSEndpoint);
await execPuppeteer(browserWSEndpoint);
}
launchAndConnectToBrowser('your profileId').then();How to Avoid Getting Your UA Banned?
If too many requests are sent by the same user agent, it will trigger the anti-bot system and eventually lead to blocking as well. The best way to avoid this is to rotate the list of user agents to search and keep it updated.
1. User-Agents Rotation
Rotating a scraping user agent means replacing it when making a web request. This allows you to access more data and increase the efficiency of your scraper. This method also helps protect your IP address from being blocked and blacklisted.
How to Rotate User Agents?
Most browsers support rotating the User-Agent header. In JS, for example, a list of available UserAgents is defined in advance, and then a randomized or rotated UserAgent is taken from the list and used.
JavaScript
const axios = require('axios');
// define rotate UserAgent list
const userAgents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0',
// more UerAgent
];
let currentIndex = 0;
async function fetchData() {
try {
const response = await axios.get('https://example.com', {
headers: {
'User-Agent': userAgents[currentIndex]
}
});
console.log(response.data);
currentIndex = (currentIndex + 1) % userAgents.length;
} catch (error) {
console.error(error);
}
}
fetchData();Avoid UA ban with intelligent UA rotation of Nstbrowser
Try for Free Now!
You can also use the UserAgent Rotation feature that comes with an anti-detect browser. By rotating the User-Agent value, Nstbrowser can prevent anti-bot detection and avoid blocking crawling activities.
Nstbrowser Web Scraping is a demonstration of creating or editing a UserAgent fingerprint in the configuration file of a Nstbrowser client. Just click on the Randomize UserAgent button as shown in the following figure:
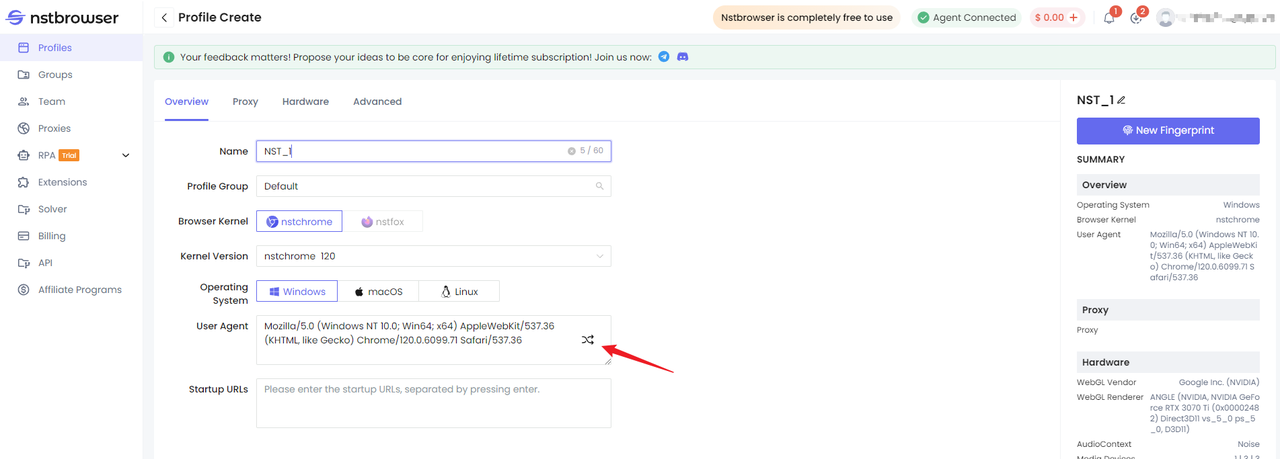
2. Random Intervals Between Requests
Keep random intervals between requests to prevent your scrapers from being detected and blocked.
3. Up-to-date User Agents
An outdated user agent can cause your IP to be blocked! To maintain a smooth, and seamless scraping experience, make sure to update your user agent regularly.
It's a Wrap
Although the user agent string can be modifiable by the client, it is still not reliable enough for web administrators to protect their servers from bot traffic. To avoid uncertainty and hassle, an anti-detect browser is an ideal solution to scrape smoothly.
Nstbrowser helps bypass anti-bot detection and unblock 99.9% of websites with its real browser fingerprint, CAPTCHA solver, web unblocker, and browserless. Oh! Try the free version and enjoy your seamless access to web scraping!
More





