
Web Scraping
How to Do Web Scraping in Golang Using Colly?
Golang is one of the most powerful tools for web scraping. And Colly helps a lot when using Go. Read this blog and find the most detailed information about Colly and learn how to scrape website with Colly.
Sep 30, 2024Carlos Rivera
What Is Colly?
Go is a versatile language with packages and frameworks that can do almost everything.
Today, we will use a framework called Colly, which is an efficient and powerful web scraping framework written in Go for scraping data on the web. It provides a simple and easy-to-use API that allows developers to quickly build crawlers to visit web pages and extract the required information.
What is Colly?
Colly provides a set of convenient and powerful tools for extracting data from websites, automating network interactions, and building web scraping tools.
In this article, you will get some practical experience using Colly and learn how to scrap data from the web with Golang: Colly.
How Does Colly Work?
The core part of Colly is Collector. It is responsible for executing HTTP requests and allows you to define how to handle requests and responses. By calling c := colly.NewCollector(), you can create a new Collector instance, which can then be used to initiate network requests and process data.
Core functions:
1. Visit and Request methods:
Visit: This is the most commonly used request method, which directly accesses the target web page.Request: Allows you to attach some additional information (such as custom headers or parameters) when sending a request, which is used for more complex request scenarios.
2. Callback mechanism: Colly relies on callback functions to execute at different stages of the request life cycle. Collector provides a variety of callback registration methods, mainly including the following six:
OnRequest: Triggered before sending an HTTP request, you can add custom headers, print request information, etc.OnError: Triggered when an error occurs during the request process, used to capture and handle request failures.OnResponse: Triggered after receiving the server's response, which can be used to process response data.OnHTML: Triggered when HTML content is received and matches the specified CSS selector, used to extract data from HTML pages.OnXML: Triggered when the response content is XML or HTML and can be used to process XML-formatted content.OnScraped: Triggered after all requested data is processed, and is the callback at the end of the crawling task.
3. OnHTML callback:
- The most commonly used callback function, registered using CSS Selector, when Colly finds a matching element in the HTML DOM, the registered callback function is called.
- Colly uses the
goquerylibrary to parse HTML and match CSS selectors, and thegoqueryAPI is similar to jQuery, so jQuery-style selectors can be used to extract data from the page.
Do you have any wonderful ideas and doubts about web scraping and Browserless?
Let's see what other developers are sharing on Discord and Telegram!
How to Scrap Data from Web with Golang?
Step 1. Environment preparation
Golang installation
Go to the Golang official website, and select the appropriate version to download and install. We recommend go1.20+. This tutorial uses go1.23.1.
After the installation is complete, you can verify whether the installation is successful by using the terminal:
Shell
go versionThe successful output of the go version information indicates that the installation is successful.
Choose a suitable IDE
Choose a suitable IDE according to your preference. Visual Studio is recommended.
Step 2. Project construction
Next, start creating a project.
- Create a project directory:
Shell
mkdir gocolly-browserless && cd gocolly-browserless- Initialize the Go project:
Shell
go mod init colly-scraperThe above command executes go mod init to initialize a go project named colly-scraper, and generates a go.mod file in the project directory with the following content:
Go
module colly-scraper
go 1.23.1- Then create
main.goand create the main method:
Go
package main
import "fmt"
func main() {
fmt.Println("Hello Nstbrowser!")
}- Run the main method:
Shell
go run main.goIf you see the printed information successfully, it means the operation is successful. The project has been successfully built.
Step 3. Use Colly
Well done! All the preparations have been completed. Next, we will officially start using Colly to complete some simple data crawling.
Install Colly
Enter the following command under the project root path to complete the Colly installation:
Shell
go get github.com/gocolly/collyIf the installation process reports an error that the current go version is not supported, you can choose to install a lower version of Colly or upgrade Golang to the corresponding version. After installing Colly, the go.mod is as follows:
Go
module colly-scraper
go 1.23.1
require (
github.com/gocolly/colly v1.2.0 // indirect
...
)Core Principle
The core working principle of Colly is to obtain web page content through HTTP requests, and then parse the DOM structure in the web page to extract the specific data we need. Its workflow can be divided into the following steps:
- Create Collector: This is the core object used by Colly to initiate HTTP requests and process responses.
- Define callback functions: Colly processes specific elements or events (such as clicking links, parsing forms, etc.) when parsing HTML by registering callback functions.
- Visit the target website: By calling the Visit() method, the Collector will initiate a request to the specified URL.
- Process the response data: Process the HTML data in the callback function to extract the required information.
Getting Started Example
The following is a simple example of visiting the Nstbrowser official website
Go
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
// Create a new collector
c := colly.NewCollector()
// Callback function, invoked when the crawler finds a <title> element
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Page Title:", e.Text)
})
// Handle errors
c.OnError(func(_ *colly.Response, err error) {
fmt.Println("Error:", err)
})
// Visit the target page
c.Visit("https://nstbrowser.io")
}After executing the above code, the crawler will output the content of the title element of the page. This is Colly's basic workflow, which allows it to easily parse HTML and extract the information you need. Running go run main.go will print information similar to the following:
Plain Text
Page Title: Nstbrowser - Advanced Anti-Detect Browser for Web Scraping and Multiple Accounts ManagingCommon settings
Colly is a powerful and flexible Golang crawler framework that can control the behavior of the crawler through configuration. The following will introduce the commonly used configuration options in Colly in detail, and explain its usage scenarios and implementation methods.
- Collector configuration
The colly.NewCollector is used to create a new Collector instance, which is the core part of the crawler. By passing different configuration options, you can customize the behavior of the crawler, such as limiting the crawled domain names, the maximum crawling depth, asynchronous crawling, etc.
Example
Go
c := colly.NewCollector(
colly.AllowedDomains("example.com"), // Restrict to certain domains
colly.MaxDepth(3), // Limit the depth of the crawl
colly.Async(true), // Enable asynchronous scraping
colly.IgnoreRobotsTxt(), // Ignore robots.txt rules
colly.DisallowedURLFilters(regexp.MustCompile(".*.jpg")), // Skip certain URLs
...
)- Request Configuration
Colly provides multiple methods to configure HTTP request behavior, such as setting custom request headers, proxies, cookies, etc. Through these settings, the crawler can simulate the behavior of real users and bypass some anti-crawler mechanisms.
Custom UA header
You can set custom HTTP header information for each request through the Headers.Set method. For example, set User-Agent to simulate the browser's access behavior to avoid being intercepted by anti-crawler mechanisms.
Go
c.OnRequest(func(r *colly.Request) {
r.Headers.Set("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
...
})Cookie Management
Colly automatically handles cookies by default, but you can also manually set specific cookies. For example, when crawling certain pages that require a login, you can pre-set cookies after login.
Go
c.SetCookies("http://example.com", []*http.Cookie{
&http.Cookie{
Name: "session_id",
Value: "1234567890",
Domain: "example.com",
},
})Set up a proxy
Using a proxy server can hide your real IP address and bypass the IP-blocking policies of some websites. Colly supports single proxy and dynamic proxy switching.
Go
c.SetProxy("your proxy url")Set request timeout
When the website responds slowly, setting a request timeout can prevent the program from hanging for a long time. By default, Colly's timeout is 10 seconds, and you can adjust the timeout as needed.
Go
c.SetRequestTimeout(30 * time.Second)Callbacks
Colly supports callback processing for various events, such as page loading success, element found, request error, etc. Through these callbacks, you can flexibly handle the crawled content or deal with errors in the crawling process.
Common callback examples:
- OnRequest
This callback will be called before each request is sent. You can dynamically set the request header or other parameters here.
Go
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting:", r.URL.String())
})- OnResponse
This callback is called when a response is received to process the original HTTP response data.
Go
c.OnResponse(func(r *colly.Response) {
fmt.Println("Received:", string(r.Body))
})- OnHTML
Used to process specific elements in HTML pages. When a matching HTML element appears on the page, this callback will be called to extract the required information.
Go
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Page Title:", e.Text)
})- OnError
This callback is called when an error occurs in the request. You can handle the exception here.
Go
c.OnError(func(_ *colly.Response, err error) {
fmt.Println("Error:", err)
})- Request Limitation
Colly also provides some options to optimize the performance of the crawler, such as limiting the number of concurrent requests, increasing the crawling speed, and setting a delay between requests.
Go
c.Limit(&colly.LimitRule{
DomainGlob: "*", // DomainRegexp is a glob pattern to match against domains
Delay: 3 * time.Second, // Delay is the duration to wait before creating a new request to the matching domains
Parallelism: 2, // Parallelism is the number of the maximum allowed concurrent requests of the matching domains
})For more settings, please refer to the official documentation of Colly.
Advanced Example
Combining the knowledge we have learned before, let's crawl the classified information data on the homepage of Wikipedia and print the results:
- Page element analysis
After entering the homepage, we right click -> inspect or press the F12 shortcut key to enter the page element analysis:
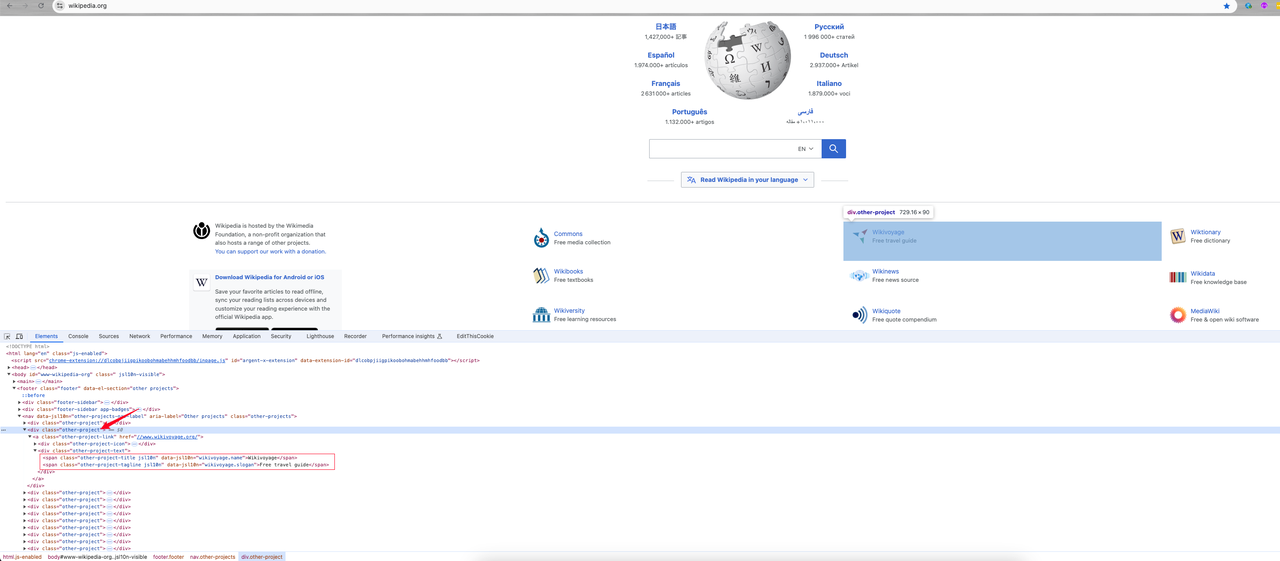
We can find:
- The category information I need is the
divelement with the class nameother-project, where the category link is thehrefattribute value in the a tag. Its class name isother-project-link. - Continue to follow up on this element and it shows that the two
spanclass names (other-project-titleandother-project-tagline) under the class element .other-project-text are its category name and introduction.
Next, start coding to get the data we want.
- Coding
Go
package main
import (
"fmt"
"time"
"github.com/gocolly/colly"
)
func main() {
// Create a new collector
c := colly.NewCollector()
// Handle errors
c.OnError(func(_ *colly.Response, err error) {
fmt.Println("Error:", err)
})
// Custom request header: User-Agent
c.OnRequest(func(r *colly.Request) {
r.Headers.Set("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
})
// Set proxy
c.SetProxy("your proxy")
// Set request timeout
c.SetRequestTimeout(30 * time.Second)
c.Limit(&colly.LimitRule{
DomainGlob: "*", // DomainRegexp is a glob pattern to match against domains
Delay: 1 * time.Second, // Delay is the duration to wait before creating a new request to the matching domains
Parallelism: 2, // Parallelism is the number of the maximum allowed concurrent requests of the matching domains
})
// Wait for elements with the class "other-project-text" to appear
c.OnHTML("div.other-project", func(e *colly.HTMLElement) {
link := e.ChildAttrs(".other-project-link", "href")
title := e.ChildText(".other-project-link .other-project-text .other-project-title")
tagline := e.ChildText(".other-project-link .other-project-text .other-project-tagline") // project tagline
fmt.Println(fmt.Sprintf("%s => %s(%s)", title, tagline, link))
})
// Visit the target page
c.Visit("https://wikipedia.org")
}- Running project
Shell
go run main.go- Result
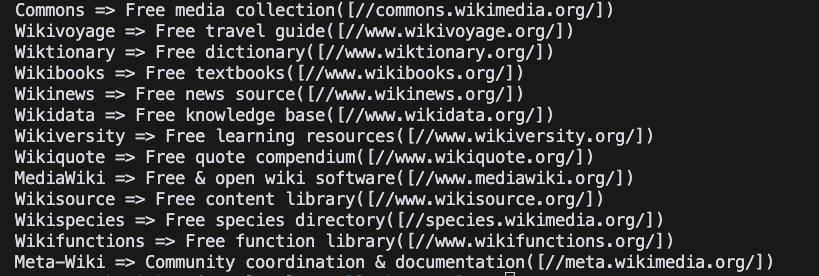
The Bottom Lines
Stop here dears! Nstbrowser always helps you simplify every difficult step of web scraping and automation tasks. In this wonderful blog, we have learned that:
- How to build the basic environment of Colly.
- Common Colly configuration and usage methods.
- Use Colly to complete the visit to the Nstbrowser official website and crawl the Wikipedia homepage Wiki classification data.
Through simple examples, we have experienced the simplicity and powerful data crawling capabilities of Colly. For more advanced usage, please refer to the official Colly.
More





