
Web Scraping
Web Crawler in Java: Step-by-Step Tutorial 2024
Java web crawler helps web scraping and automation tasks easily. How to do web scraping using Java web crawler? Here is everything you will like!
Aug 15, 2024Robin Brown
What is the efficient way to get useful information from the website? It's obviously a Java web crawler!
In this blog, you will learn:
- What is the difference between a web crawler and a web scraper?
- How to use Jsoup to parse and extract data from web pages?
- How to avoid detection and improve crawling efficiency and stability?
Can You Do Web Scraping with Java?
Yes! As a mature and widely used programming language, Java provides powerful support that makes web scraping efficient and reliable, and Java can rely on a variety of libraries. This means that you can choose from multiple Java web scraping libraries.
Here are some of the main advantages of Java web scraping:
- Rich libraries and frameworks. Java provides powerful libraries and frameworks such as Jsoup, Selenium, and Apache HttpClient. They can help developers easily scrape and parse web data.
- Excellent performance. The efficient memory management and multi-threading support of Java make it perform well when processing large amounts of data.
- Cross-platform capabilities. Java is available of a platform-independent nature. So it can run on different operating systems, whether on Windows, Linux, or macOS, ensuring the consistency and compatibility of scraping tools.
- Powerful data processing capabilities. Java's data processing capabilities are very powerful and can easily cope with complex data structures and large data sets. Whether it is simple text parsing or complex data conversion, Java can provide efficient solutions.
- Security. The security features of Java, such as the sandbox model and security manager, provide additional protection for crawlers in a network environment, so your system security is not threatened.
With these advantages, Java is an ideal choice for building robust and efficient web crawling tools. Whether it is crawling static web data or processing dynamic content, Java can provide developers with a reliable solution.
What Is a Java Web Crawler?
In Java, a web crawler is an automated program used to collect data from the Internet. It extracts information on web pages by simulating the process of users visiting web pages, and stores or processes it for subsequent use.
The main functions of Java crawler are:
- Send HTTP requests. Through Java's HTTP client library (such as HttpURLConnection or Apache HttpClient), the crawler can send requests to the target website to obtain web page content.
- Parse web page content. Use HTML parsing libraries (such as Jsoup) to parse web page content into an operable DOM structure to extract the required information from it.
- Process data. The extracted information can be further processed, stored, or analyzed. For example, saving data to a database, generating reports, or performing statistical analysis.
- Follow links. A crawler can follow links on a web page and recursively crawl multiple web pages to obtain more comprehensive data.
Main Difference Between Web scraper and Web crawler
Web scraping aims to extract web page data, while web crawling aims to index and find web pages.
Web scraping means writing a program that can secretly collect data from multiple websites. In contrast, web crawling involves permanently following links based on hyperlinks.
Do you have any wonderful ideas and doubts about web scraping and Browserless?
Let's see what other developers are sharing on Discord and Telegram!
How to do web scraping with Jsoup and Nstbrowser API?
Let's take the example of grabbing the basic information and prices of cryptocurrencies on the homepage of CoinmarketCap to demonstrate how to use Jsoup and Selenium in Java web crawler through the Nstbrowser API, specifically using the LaunchExistBrowser API.
Before starting data crawling, we need to:
- Download and install Nstbrowser in advance and generate your API key.
- Create a profile, and click to start the profile to automatically download the corresponding version of the kernel.
- The only step left is to download the chromedriver of the corresponding kernel version before using selenium, which can be referred to: How to use in Selenium in Nstbrowser.
Page Analysis
Start analyzing the site and see what the page we want to crawl looks like:
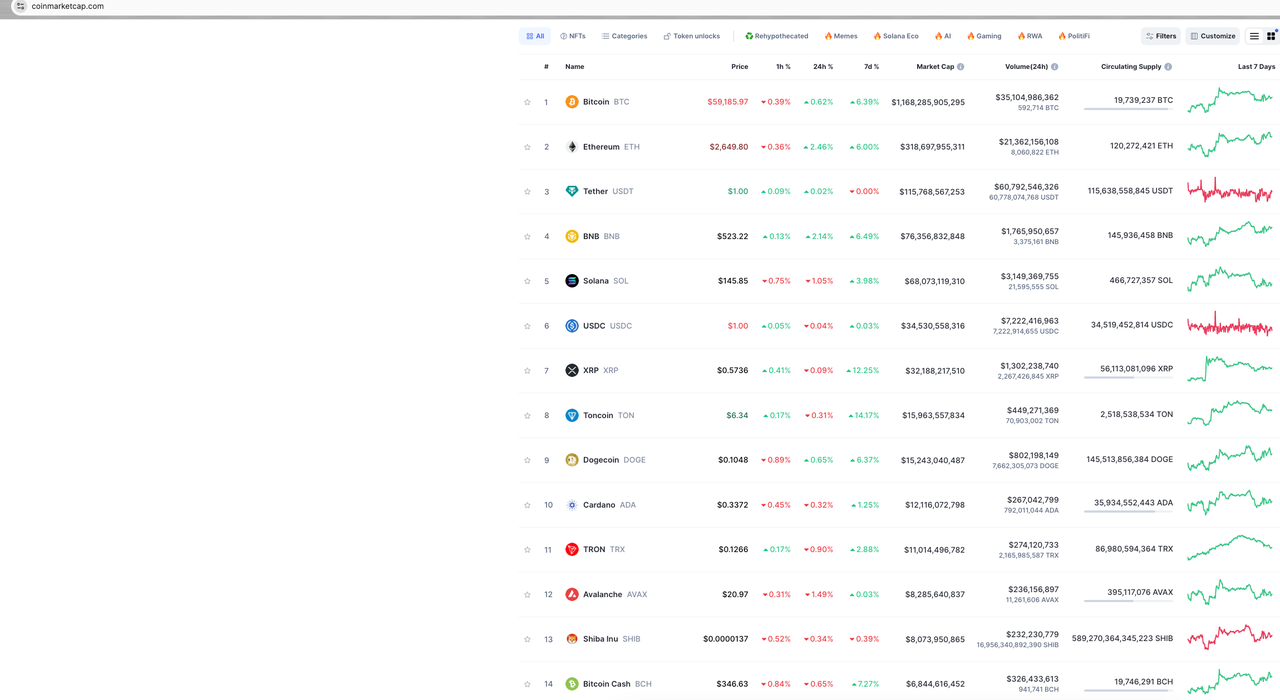
Our target data is the data on the homepage of CoinmarketCap. We only capture some of the data here for demonstration, such as cryptocurrency rankings, cryptocurrency logos, cryptocurrency currencies, and currency prices.
Next, we will analyze each piece of data we need step by step.
Step 1. Open the browser console and start viewing the page elements:
Overall analysis
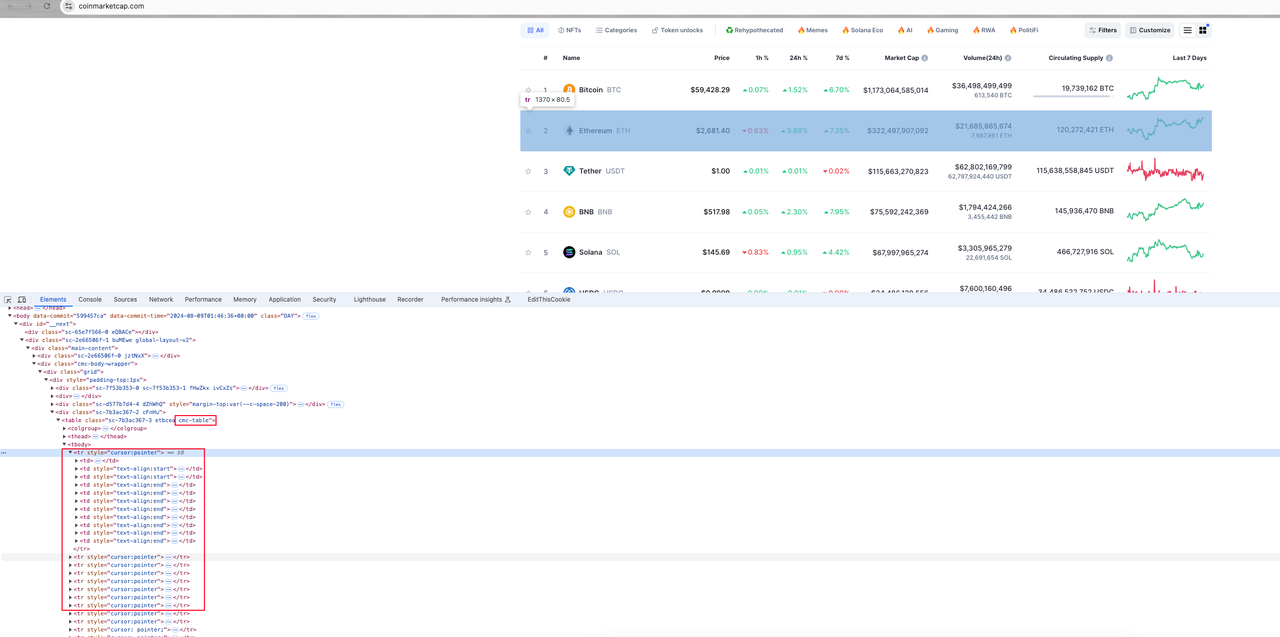
All currency information on the page is contained in a table element with a class name of cmc-rable. The page element corresponding to each currency information is the tr table row under the table element. Each table row contains several table column elements td. Our goal is to parse the target data from these td elements.
Step 2. We will search and analyze each target data:
Coin rank
From the picture below, we can see that the element where the currency ranking is located in the p tag value under the second td in tr:
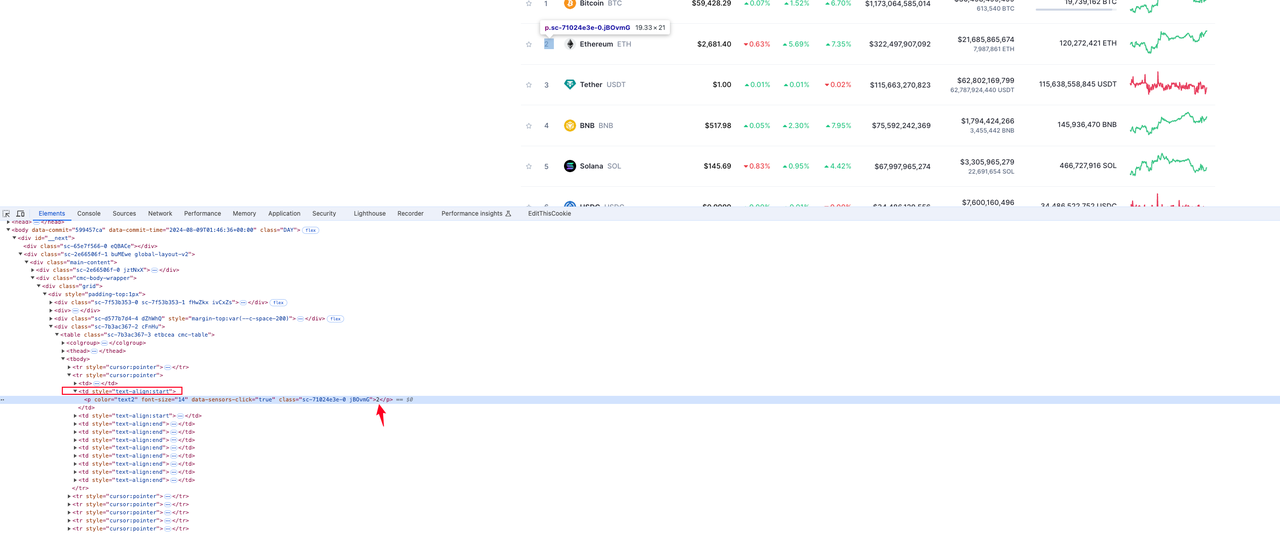
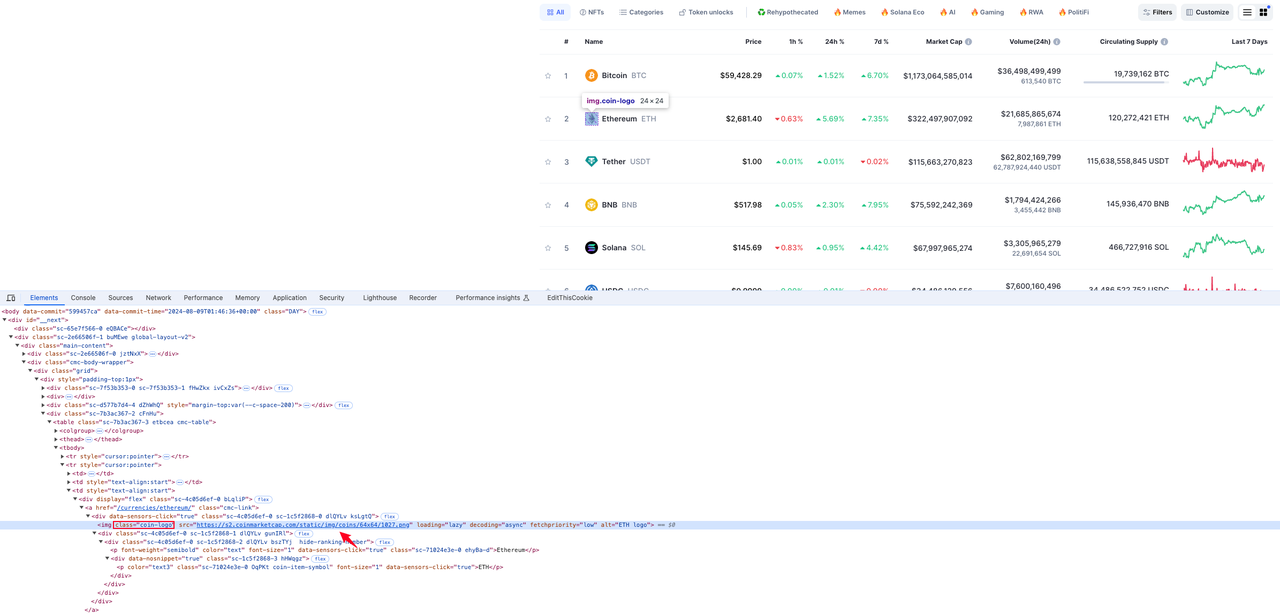
Coin logo
The element where the currency logo icon is located in the src attribute value of the img tag with the class name coin-logo in the tr row element:
Coin symbol
The element where the currency information is located in the p tag value with the class name coin-item-symbol in the tr row element:
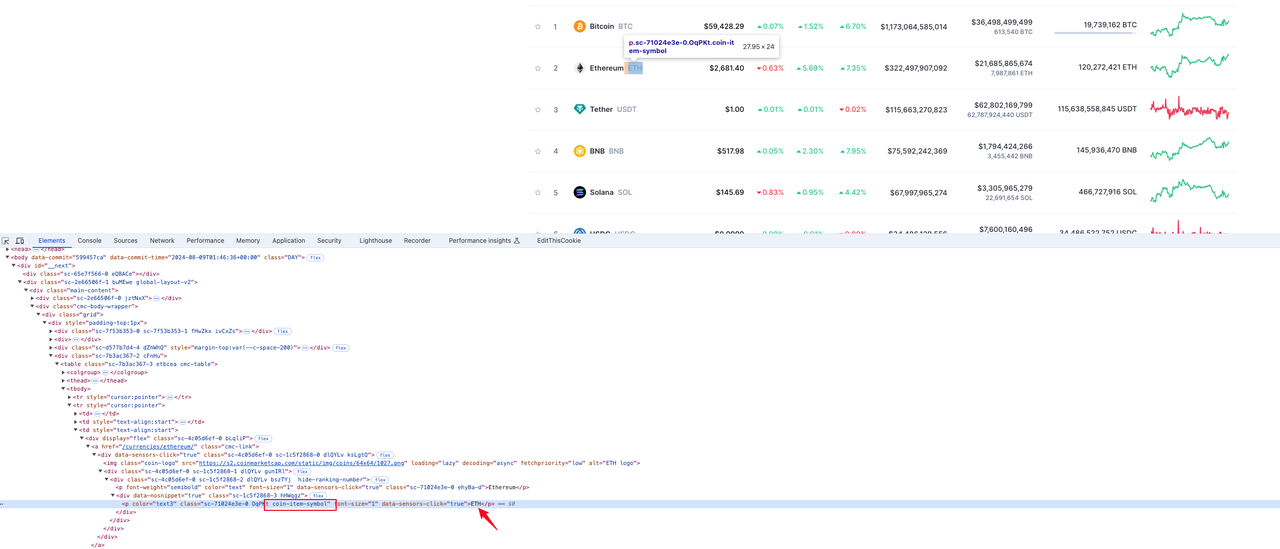
Coin price
The element where the currency information is located is the div span element value under the fourth td element in the tr row element:
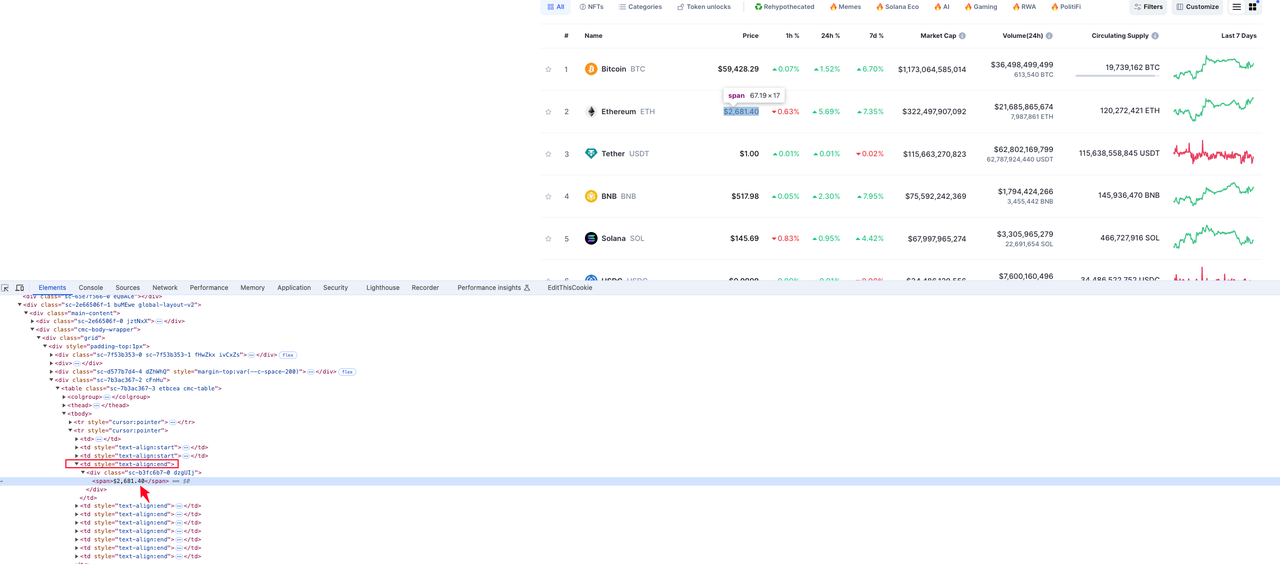
After analysis, we have obtained the elements where the target data we want is located. You can study more data element analysis by yourself.
Coding
Without further ado, let's get straight to the code:
dependencies(build.gradle)
Java
dependencies {
implementation 'com.squareup.okhttp3:okhttp:4.12.0'
implementation 'com.google.code.gson:gson:2.10.1'
implementation 'org.jsoup:jsoup:1.17.2'
implementation "org.seleniumhq.selenium:selenium-java:4.14.1"
}CmcRank.java
Java
public class CMCRank {
// coin rank
private Integer rank;
// coin symbol
private String coinSymbol;
// coin logo
private String coinLogo;
// coin price
private String price;
// getters and setters omitted
}CmcScraper.java
Java
import com.google.gson.Gson;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
import org.openqa.selenium.*;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class CmcScraper {
// http client
private static final OkHttpClient client = new OkHttpClient();
// gson
private static final Gson gson = new Gson();
// your apiKey
private static final String API_KEY = "your apikey";
// your profileId
private static final String PROFILE_ID = "your profileId";
// cmc website url
private static final String BASE_URL = "https://coinmarketcap.com";
// nstbrowser API base url
private final String baseUrl;
// webdriver file path
private final String webdriverPath;
public CmcScraper(String baseUrl, String webdriverPath) {
this.baseUrl = baseUrl;
this.webdriverPath = webdriverPath;
}
public void scrape() {
String url = String.format("%s/devtool/launch/%s", this.baseUrl, PROFILE_ID);
Request request = new Request.Builder()
.url(url)
.get()
.addHeader("Content-Type", "application/json")
.addHeader("x-api-key", API_KEY)
.build();
try (Response response = client.newCall(request).execute()) {
if (!response.isSuccessful()) {
throw new IOException("Unexpected code " + response);
}
Map<String, Object> responseBody = gson.fromJson(response.body().string(), Map.class);
Map<String, Object> data = (Map<String, Object>) responseBody.get("data");
Double port = (Double) data.get("port"); // get browser port
if (port != null) {
this.execSelenium("localhost:" + port.intValue());
} else {
throw new IOException("Port not found in response");
}
} catch (IOException e) {
throw new RuntimeException("Failed to scrape", e);
}
}
public void execSelenium(String debuggerAddress) {
System.setProperty("webdriver.chrome.driver", this.webdriverPath);
ChromeOptions options = new ChromeOptions();
options.setExperimentalOption("debuggerAddress", debuggerAddress);
try {
WebDriver driver = new ChromeDriver(options);
driver.get(BASE_URL);
WebElement cmcTable = driver.findElement(By.cssSelector("table.cmc-table"));
if (cmcTable != null) {
List<WebElement> tableRows = cmcTable.findElements(By.cssSelector("tbody tr"));
List<CMCRank> cmcRanks = new ArrayList<>(tableRows.size());
for (WebElement row : tableRows) {
CMCRank cmcRank = extractCMCRank(row);
if (cmcRank != null) {
System.out.println(gson.toJson(cmcRank));
cmcRanks.add(cmcRank);
}
}
// TODO
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
private CMCRank extractCMCRank(WebElement row) {
try {
CMCRank cmcRank = new CMCRank();
List<WebElement> tds = row.findElements(By.tagName("td"));
if (tds.size() > 1) {
WebElement rankElem = tds.get(1).findElement(By.tagName("p"));
// find coin rank
if (rankElem != null && !rankElem.getText().isEmpty()) {
cmcRank.setRank(Integer.valueOf(rankElem.getText()));
}
// find coin logo
WebElement logoElem = row.findElement(By.cssSelector("img.coin-logo"));
if (logoElem != null) {
cmcRank.setCoinLogo(logoElem.getAttribute("src"));
}
// find coin symbol
WebElement symbolElem = row.findElement(By.cssSelector("p.coin-item-symbol"));
if (symbolElem != null && !symbolElem.getText().isEmpty()) {
cmcRank.setCoinSymbol(symbolElem.getText());
}
// find coin price
WebElement priceElem = tds.get(3).findElement(By.cssSelector("div span"));
if (priceElem != null) {
cmcRank.setPrice(priceElem.getText());
}
}
return cmcRank;
} catch (NoSuchElementException e) {
System.err.println("Failed to extract coin info: " + e.getMessage());
return null;
}
}
}Main.java
Java
public class Main {
public static void main(String[] args) {
String baseUrl = "http://localhost:8848";
String webdriverPath = "your chromedriver file path";
CmcScraper scraper = new CmcScraper(baseUrl, webdriverPath);
scraper.scrape();
}
}Run the program
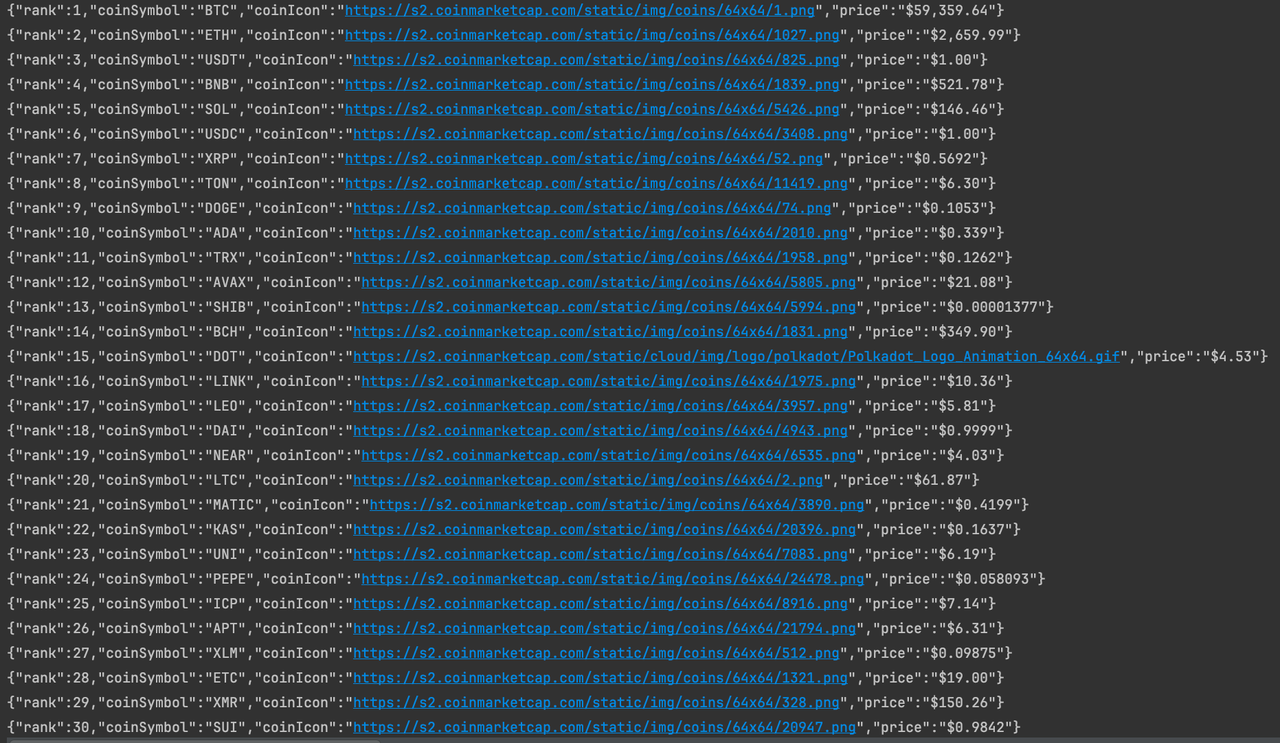
So far, we have successfully crawled the currency information data on the homepage of CoinmarketCap. If you are interested, you can analyze the page in-depth to crawl more data.
It's A Wrap
Why is Java an excellent programming language for web crawling? How to crawl an entire website using Java? What is the difference between web crawler and web scraping? It doesn't matter, you have learned everything you need to know to perform professional web crawling with Java in this blog.
However, the most important thing when doing web crawling is: your web crawler must be able to bypass anti-bot systems. This is why you need an anti-detect browser that can bypass website blocking.
Nstbrowser provides everything wonderful for web scraping.
More





