
Web Scraping
Python Web Crawler - Step by Step Tutorial 2024
Python offers very powerful web crawler development capabilities. Read this article to learn how to use Python for web crawling.
Jun 13, 2024Robin Brown
Web crawler is a powerful technique that allows us to collect all kinds of data and information by visiting web pages and discovering URLs on websites. Python has various libraries and frameworks that support web crawlers. In this article we will learn about:
- What is Python crawler
- How to use Python crawler and Nstbrowser API crawl webpage
- How to deal with banning while crawling with python
- Examples of python crawling
What Is Python Web Crawler?
Python offers very powerful web crawler development capabilities and is one of the most popular crawling languages available today. A Python web crawler is an automated program for browsing a website or the Internet in order to scrape webpages. It is a Python script that explores pages, discovers links, and follows them to increase the amount of data that can be extracted from relevant websites.
Search engines rely on crawling robots to build and maintain their page indexes, while web crawling tools use them to access and find all pages to apply data extraction logic.
Web crawlers in Python are primarily implemented through the use of a number of third-party libraries. Common Python web crawler libraries include:
-
urllib/urllib2/requests: These libraries provide basic web crawling functionality, allowing you to send HTTP requests and retrieve responses.
-
BeautifulSoup: This is a library for parsing HTML and XML documents, you can help the crawler to extract useful information on the web page.
-
Scrapy: This is a powerful web crawler framework that provides data extraction, pipeline processing, distributed crawling, and other advanced features.
-
Selenium: It is a web browser automation tool, which can simulate the manual operation of the browser. This crawler is always used to crawl the JavaScript-generated dynamic page content.
Always be blocked when scarping?
Web unlocker and anti-detection solutions of Nstbrowser
Try it for FREE!
Do you have any wonderful ideas and doubts about web scraping and Browserless?
Let's see what other developers are sharing on Discord and Telegram!
4 Popular Web Crawler Use Cases:
-
Search engines (e.g. Googlebot, Bingbot, Yandex Bot...) collect all the HTML of the important parts of the web, the data is indexed to make it searchable.
-
SEO analysis tools collect metadata in addition to HTML, such as response time, and response status to detect broken pages and links between different domains to collect backlinks.
-
Price monitoring tools crawl e-commerce sites to find product pages and extract metadata, especially prices. The product pages are then revisited periodically.
-
Common Crawl maintains an open repository of web crawling data. For example, the May 2022 archive contains 3.45 billion web pages.
So how to use Python automation tool Pyppeteer for web crawling?
Keep scrolling!
How to Scrape the Web with Pyppeteer and Nstbrowser API?
Step1. Prerequisites
There are some preparations that need to be done before you can start crawling:
Shell
pip install pyppeteer requests jsonAfter installing the libraries needed above, create a new file scraping.py and introduce the libraries we just installed as well as some system libraries into the file:
python
import asyncio
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from pyppeteer import launcherBefore using pyppeteer, we first need to connect to Nstbrowser, which provides an API to return the webSocketDebuggerUrl for pyppeteer.
Python
# get_debugger_url: Get the debugger url
def get_debugger_url(url: str):
try:
resp = requests.get(url).json()
if resp['data'] is None:
raise Exception(resp['msg'])
webSocketDebuggerUrl = resp['data']['webSocketDebuggerUrl']
return webSocketDebuggerUrl
except HTTPError:
raise Exception(HTTPError.response)
async def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'your api key'
config = {
'once': True,
'headless': False,
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # required
'name': 'custom browser',
'platform': 'windows', # support: windows, mac, linux
'kernel': 'chromium', # only support: chromium
'kernelMilestone': '120', # support: 113, 115, 118, 120
'hardwareConcurrency': 4, # support: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # support: 2, 4, 8
'proxy': '', # input format: schema://user:password@host:port eg: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # required
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
browser_ws_endpoint = get_debugger_url(url)
print("browser_ws_endpoint: " + browser_ws_endpoint) # pyppeteer connects to Nstbrowser via browser_ws_endpoint
(
asyncio
.get_event_loop()
.run_until_complete(create_and_connect_to_browser())
)After successfully obtaining the Nstbrowser's webSocketDebuggerUrl, connect pyppeteer to the Nstbrowser:
Python
async def exec_pyppeteer(wsEndpoint: str):
browser = await launcher.connect(browserWSEndpoint = wsEndpoint)
page = await browser.newPage()Running the code we just wrote in the terminal: python scraping.py, you can see that we successfully opened an Nstbrowser and created a new tab in the Nstbrowser.
Everything is ready, and now, we can officially start the crawl!
Step 2. Visit the target website
https://www.imdb.com/chart/top
Python
await page.goto('https://www.imdb.com/chart/top')Step 3. Execute the code
Execute our code one more time and you will see that we have accessed our target website via Nstbrowser. Open Devtool to see the specific information we want to crawl and you will see that they are elements with the same dom structure.
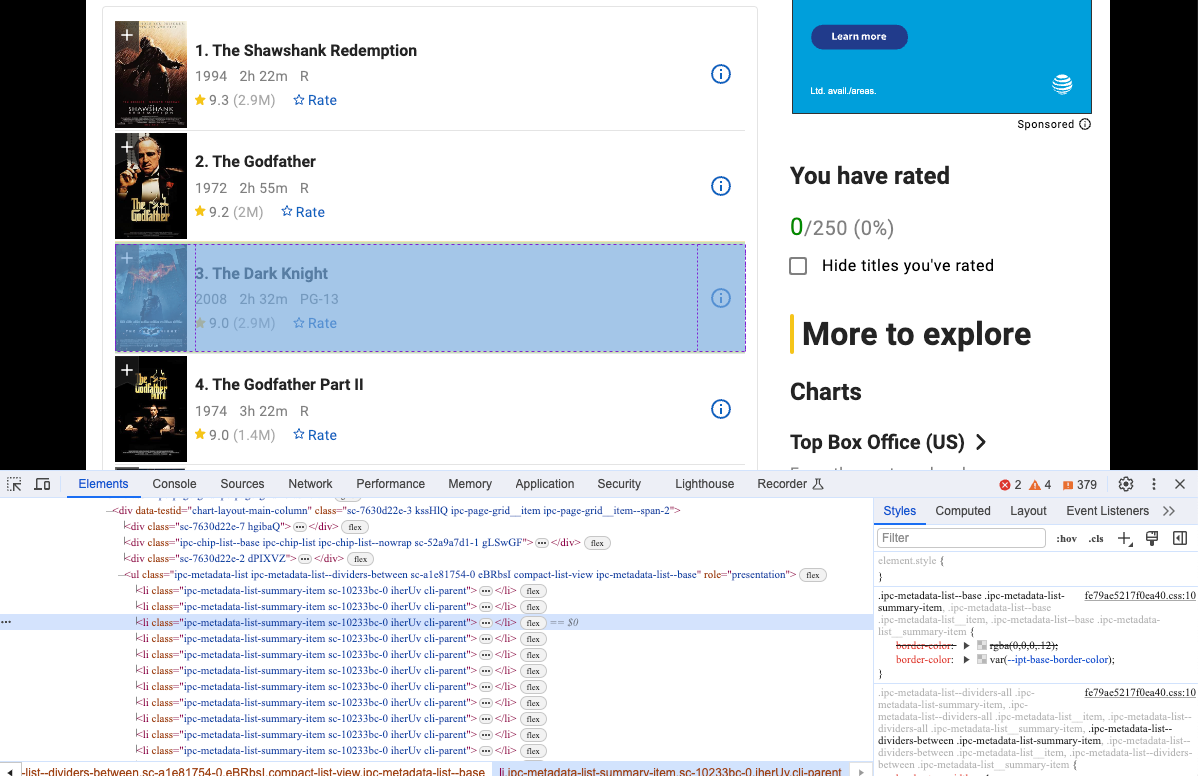
Step 4. Crawl the web page
We can use Pyppeteer to crawl these dom structures and analyze their content:
Python
movies = await page.JJ('li.cli-parent')
for row in movies:
title = await row.J('.ipc-title-link-wrapper')
year = await row.J('span.cli-title-metadata-item')
rate = await row.J('.ipc-rating-star')
title_text = await page.evaluate('item => item.textContent', title)
year_text = await page.evaluate('item => item.textContent', year)
rate_text = await page.evaluate('item => item.textContent', rate)
pringt('titile: ', title_text)
pringt('year: ', title_text)
pringt('rate: ', title_text)Of course, just outputting the data at the terminal is obviously not our final goal, what we want to do is to save the data.
Step 5. Save the data
We use the json library to save the data to a local json file:
Python
movies = await page.JJ('li.cli-parent')
movies_info = []
for row in movies:
title = await row.J('.ipc-title-link-wrapper')
year = await row.J('span.cli-title-metadata-item')
rate = await row.J('.ipc-rating-star')
title_text = await page.evaluate('item => item.textContent', title)
year_text = await page.evaluate('item => item.textContent', year)
rate_text = await page.evaluate('item => item.textContent', rate)
move_item = {
"title": title_text,
"year": year_text,
"rate": rate_text
}
movies_info.append(move_item)
# create the json file
json_file = open("movies.json", "w")
# convert movies_info to JSON
json.dump(movies_info, json_file)
# release the file resources
json_file.close()Run our code and then open the folder where the code is located. You will see a new movies.json file appears. Open it to check the content. If you find it looks like this:
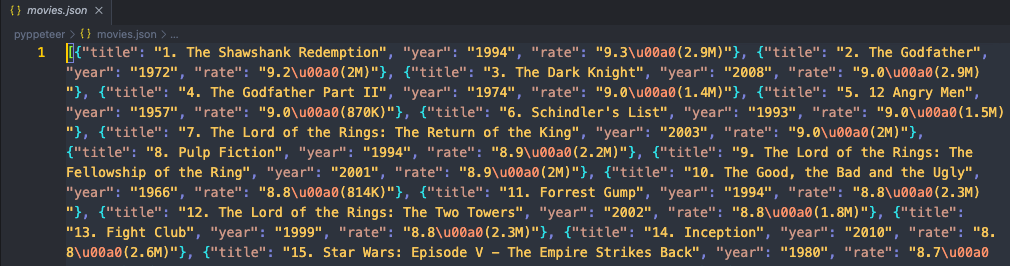
That means we have successfully crawled the target website using Pyppeteer and Nstbrowser!
4 Tips to Fix a Blocked Python Crawler
The biggest challenge when doing Python web crawler is getting blocked. Many websites protect their access with anti-bot measures that recognize and stop automated applications, preventing them from accessing the page.
Avoid Web Blocking and IP Blocking with Nstbrowser.
Try it for free!
Here are some suggestions to overcome anti-crawling:
- Rotate
User-Agent: Constantly changing the User-Agent header in requests can help mimic different web browsers and avoid detection as a bot.
The UA information can be changed by modifying the config when starting Nstbrowser:
Python
config = {
'once': True,
'headless': False,
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # required
'name': 'custom browser2',
'platform': 'mac', # support: windows, mac, linux
'kernel': 'chromium', # only support: chromium
'kernelMilestone': '120', # support: 113, 115, 118, 120
'hardwareConcurrency': 8, # support: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 2, # support: 2, 4, 8
}
}-
Run during off-peak hours: Starting the crawler during off-peak hours and adding delays between requests helps prevent the web server from being overwhelmed and triggering a blocking mechanism.
-
Respect
robots.txt: Following therobots.txtdirective on a website demonstrates ethical crawling behavior. In addition, it helps to avoid accessing restricted areas and makes requests from scripts suspicious. -
Avoid honeypots: Not all links are created equal and some of them hide bot traps. By following them, you will be flagged as a bot.
However, these tips are very useful for simple scenarios, but not enough for more complex ones. Check out our more complete article on Web scraping.
Bypassing all defenses is not easy and requires a lot of effort. Also, a solution that works today may not work tomorrow. But wait, there are better solutions!
Nstbrowser helps prevent websites from recognizing and blocking crawling activity through Browser Emulation, User-Agent Rotation, and more. Sign up for a free trial today!
3 Popular Python Web Crawlers
There are several useful web crawling tools that can make the process of discovering links and visiting pages easier. Here is a list of the best Python web crawlers that can help you:
-
Nstbrowser: provides real browser fingerprints. Combines advanced website unlocking and bot bypassing techniques, and can intelligently rotate IPs to greatly reduce the probability of detection.
-
Scrapy: One of the most powerful Python crawling library options for beginners. It provides an advanced framework for building scalable and efficient crawlers.
-
Selenium: a popular headless browser library for web crawling and crawling. Unlike BeautifulSoup, it can interact with web pages in the browser like a human user.
Take Away Notes
From this article, you must be completely clear about the basics of web crawling. It is important to note that no matter how smart your crawler is, anti-bot measures can detect and block it.
However, you can get rid of any challenges by using Nstbrowser, an all-in-one anti-detect browser with automation features, Browser Fingerprinting, Captcha Solver, UA Rotation, and many other must-have features to avoid being blocked.
Crawling has never been easier! Start using Nstbrowser now to become a web crawler master!
More





