
Web ScrapingRPA
How to Scrape Google Maps Search Results through Nstbrowser RPA?
How to perform web scraping most efficiently? Yes, RPA tools can greatly increase efficiency and reduce costs. In this blog, you will learn how to crawl Google map search results using Nstbrowser RPA tool.
May 14, 2024
Using RPA tools for web data scraping is a common means of data collection, and RPA can also greatly improve the efficiency of data scraping and reduce the cost of collection. Obviously, Nstbrowser RPA provides you with the best RPA experience and the best work efficiency.
After reading this tutorial, you will:
- Understand how to use RPA for data collection
- Learn how to save the data collected by RPA
Step 1: Preparation
You need to:
- have a Nstbrowser account and log into the Nstbrowser client.
- go to the workflow page of the RPA module and click "Create Workflow".
Now, we can start to configure the workflow for RPA crawling based on Google map search results.
Step 2: Visit the Target Website
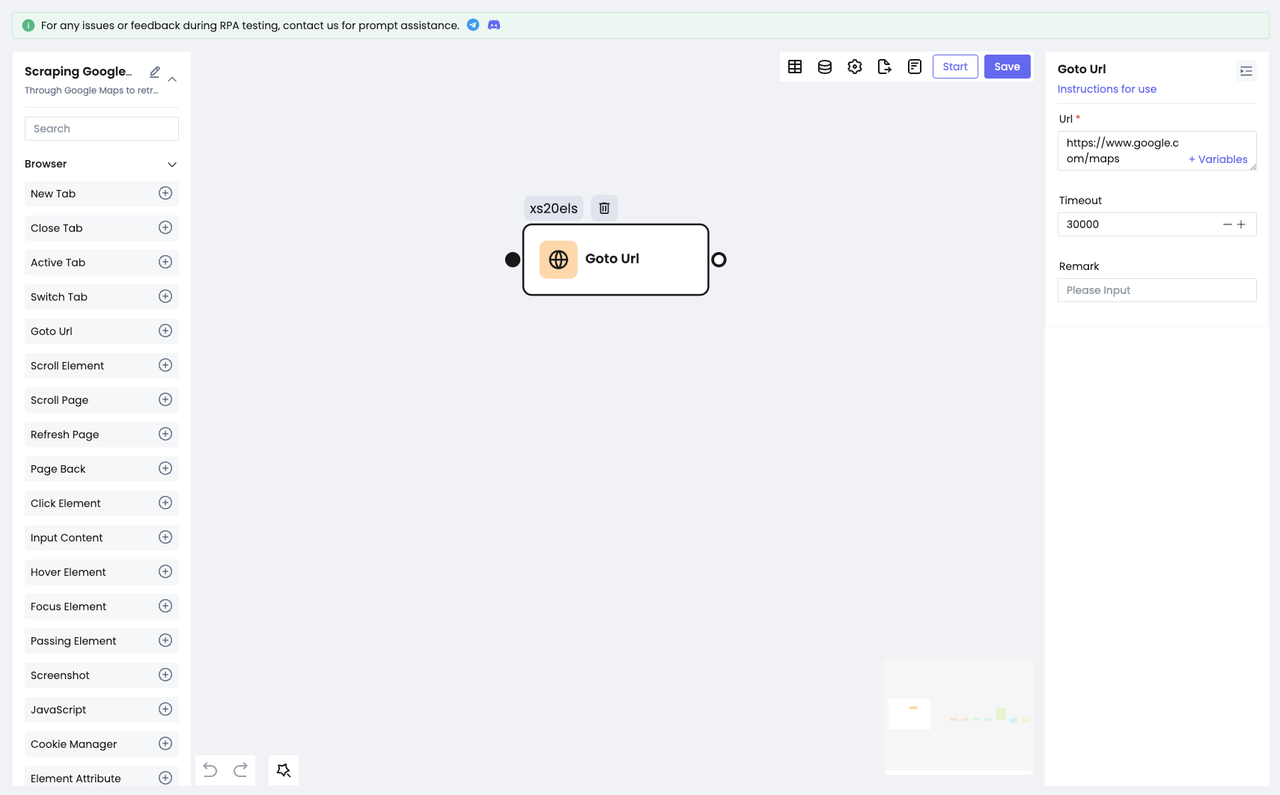
Before searching the target content, we need to visit our target website: https://www.google.com/maps.
- Choose the
Goto Urlnode. - Configure the website URL.
And you can visit the target website now.
Step 3: Search for the Target Content
After reaching the website, we need to search for the target address. Here you need to use the Chrome Devtool to locate the HTML elements.
Open the DevTools and use your mouse to select the search box. Then we can see:
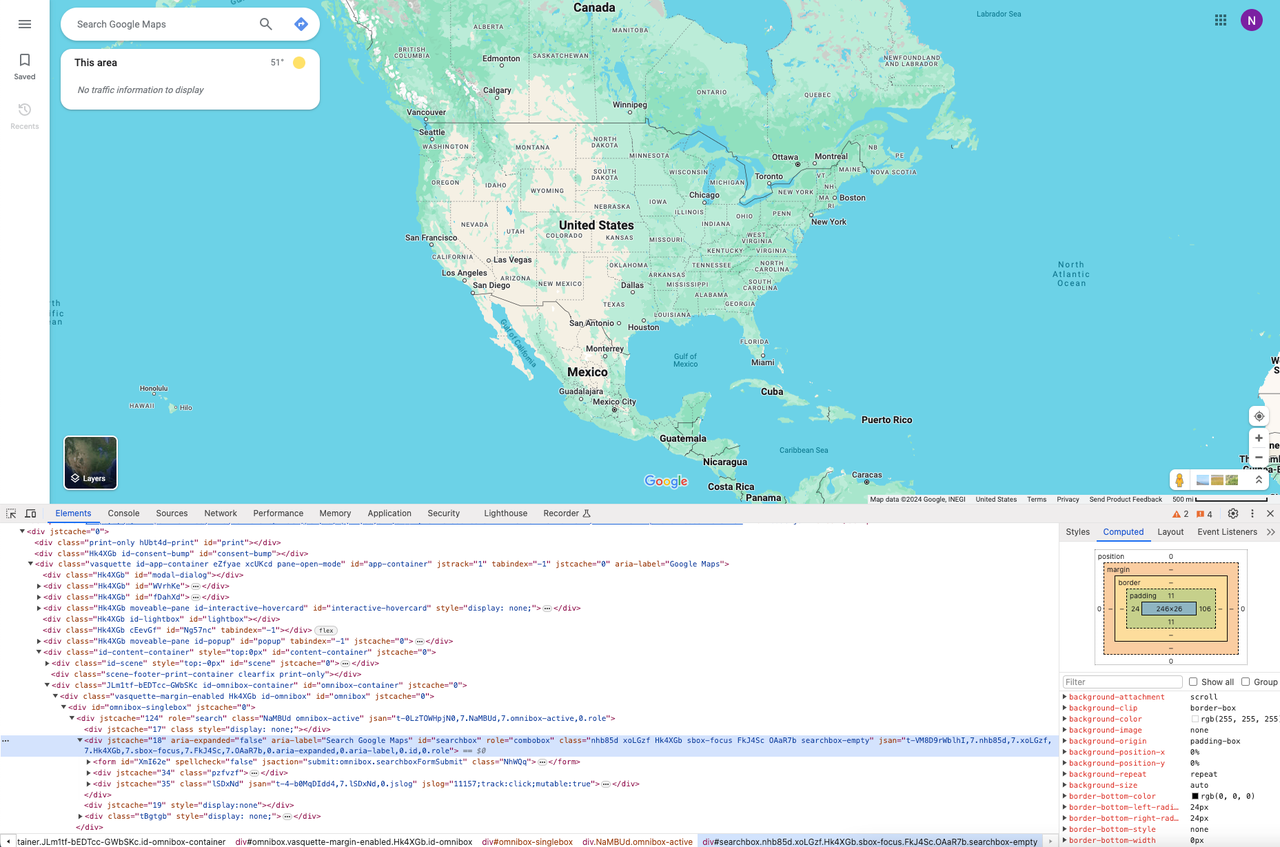
- Our target input box element has an "
id" attribute, which can be used as a CSS selector to locate the input box.
So, we need to do:
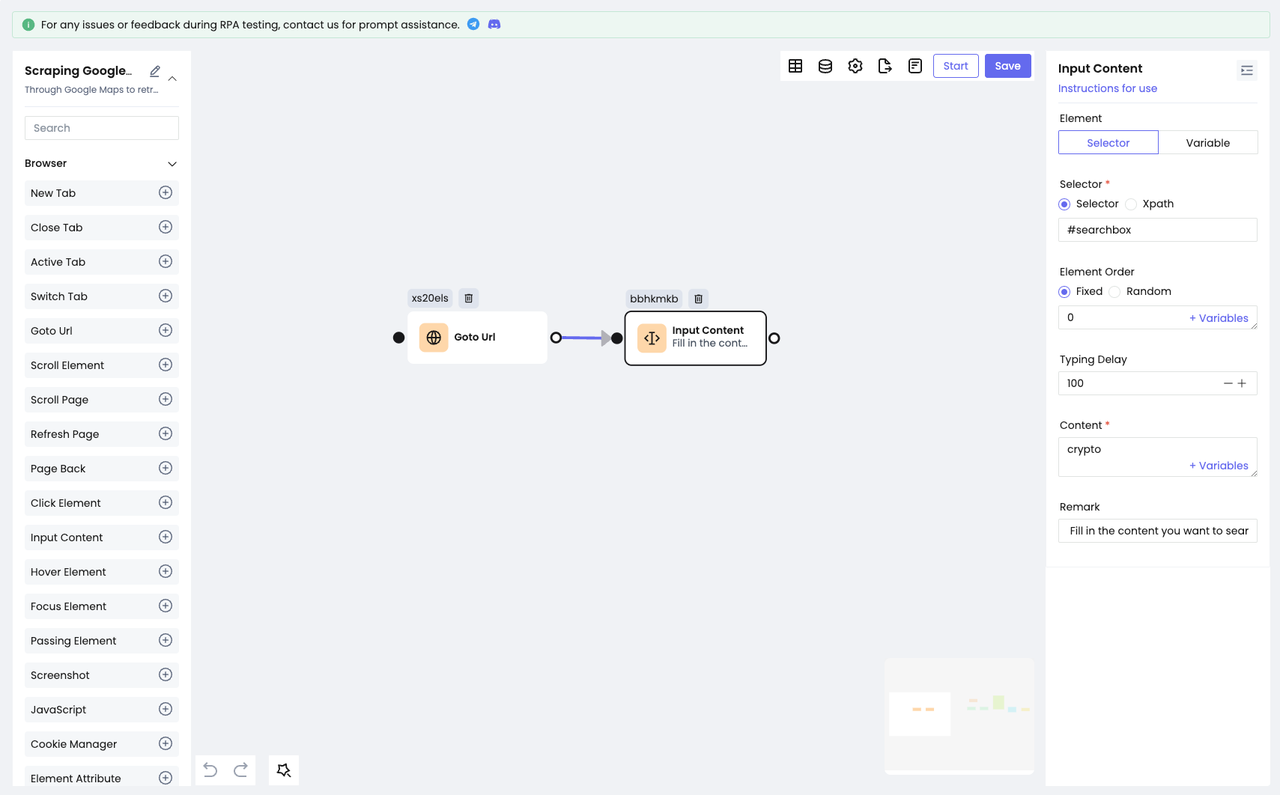
- Add the
Input Contentnode. Select "Selector" for the Element option and Selector for the Selector option. - Fill in the value of the
idwe have positioned in the input box and enter the content we want to search for in the Content option.
We have completed the action of typing in the input box:
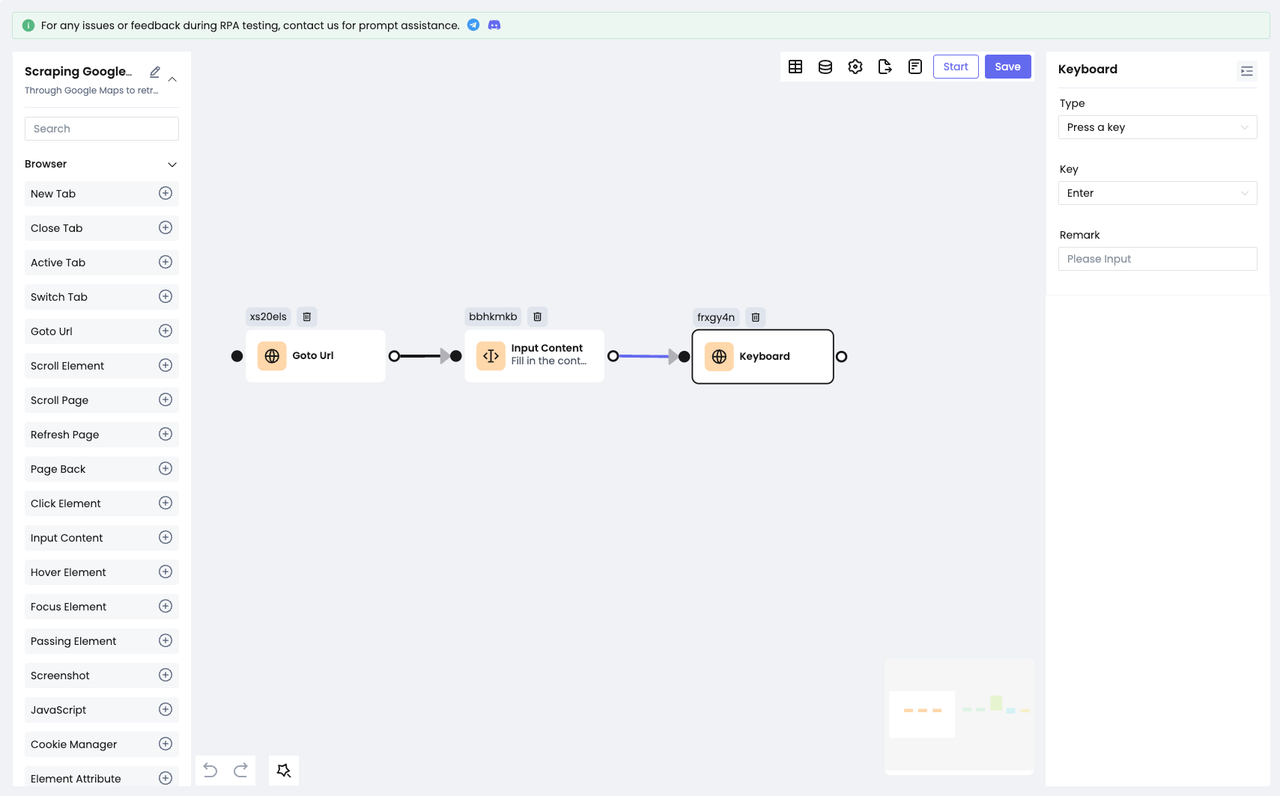
After typing, we need to make Google Maps search for the content we've filled in:
- This can be done quickly by using the
Keyboardnode to simulate a keyboard's "Enter".
Step 4: Data Scraping
Okay, carry on now, we have successfully gotten the content we want, and the next step is to scrape these contents!
Through observation, we can find that the search results of Google Maps are displayed in a list form (a very classic way). Only some important information will be displayed here, and if you click on one particular item, all the detailed corresponding information will appear next to it.
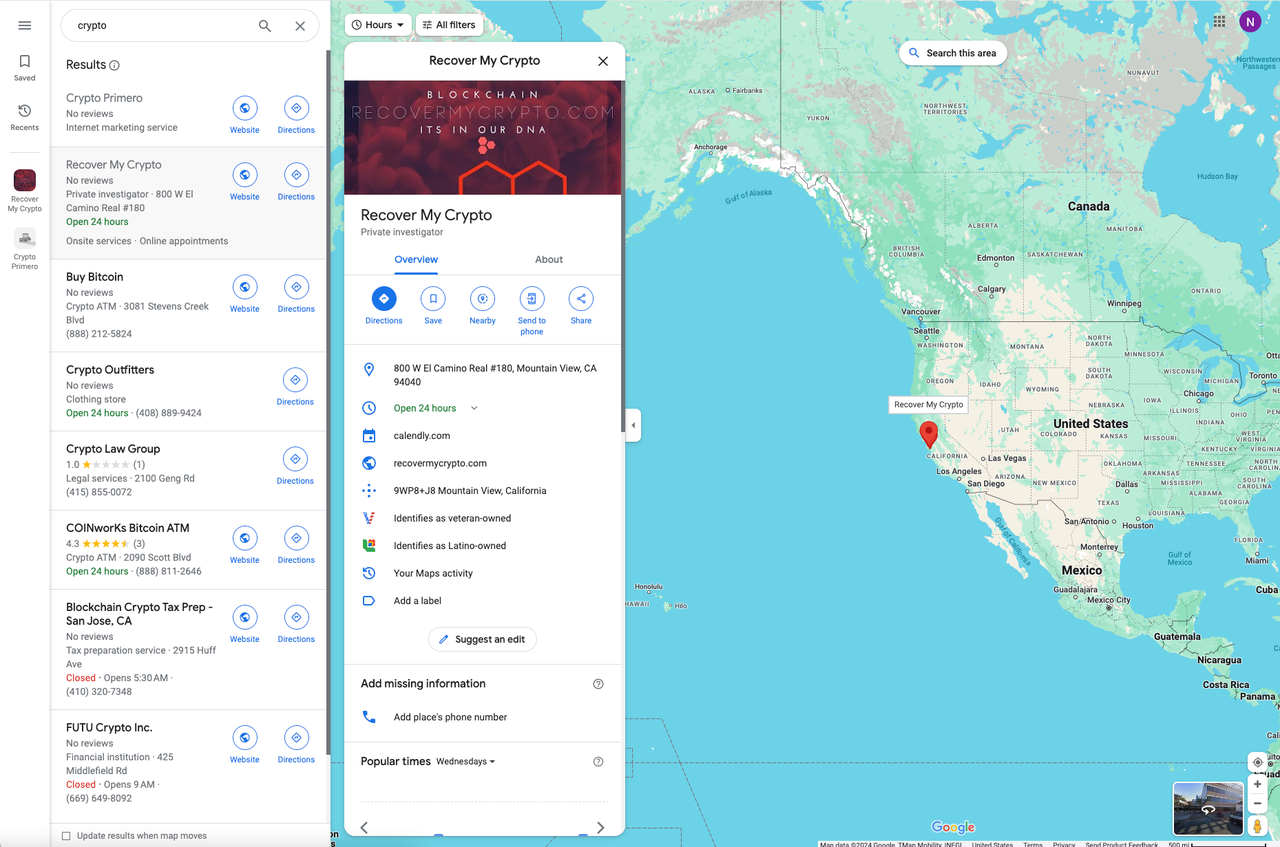
Again, open the DevTools to locate each result in the list:
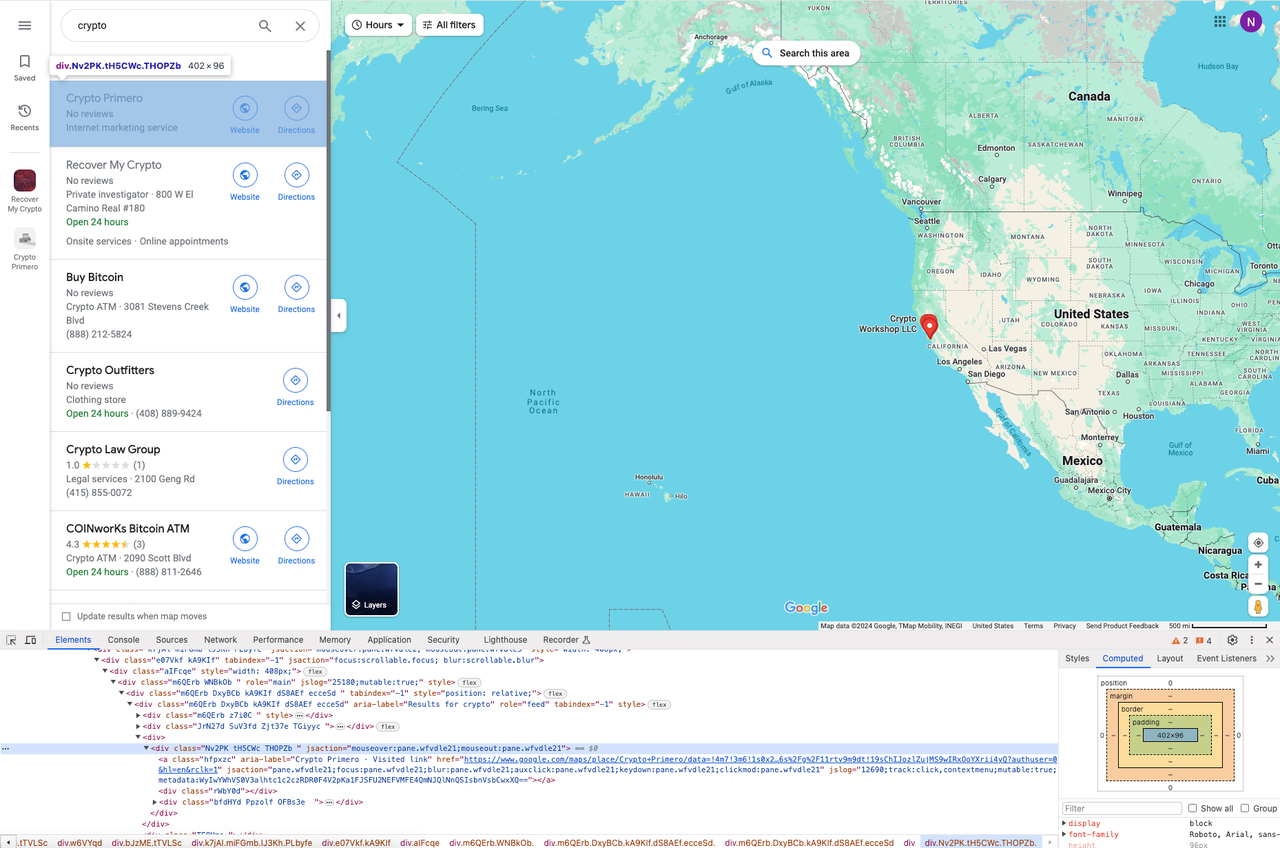
Iterating through all the results
Since each item in the list uses an HTML layout, we need to use the Loop Element node to iterate through all the results of the query:
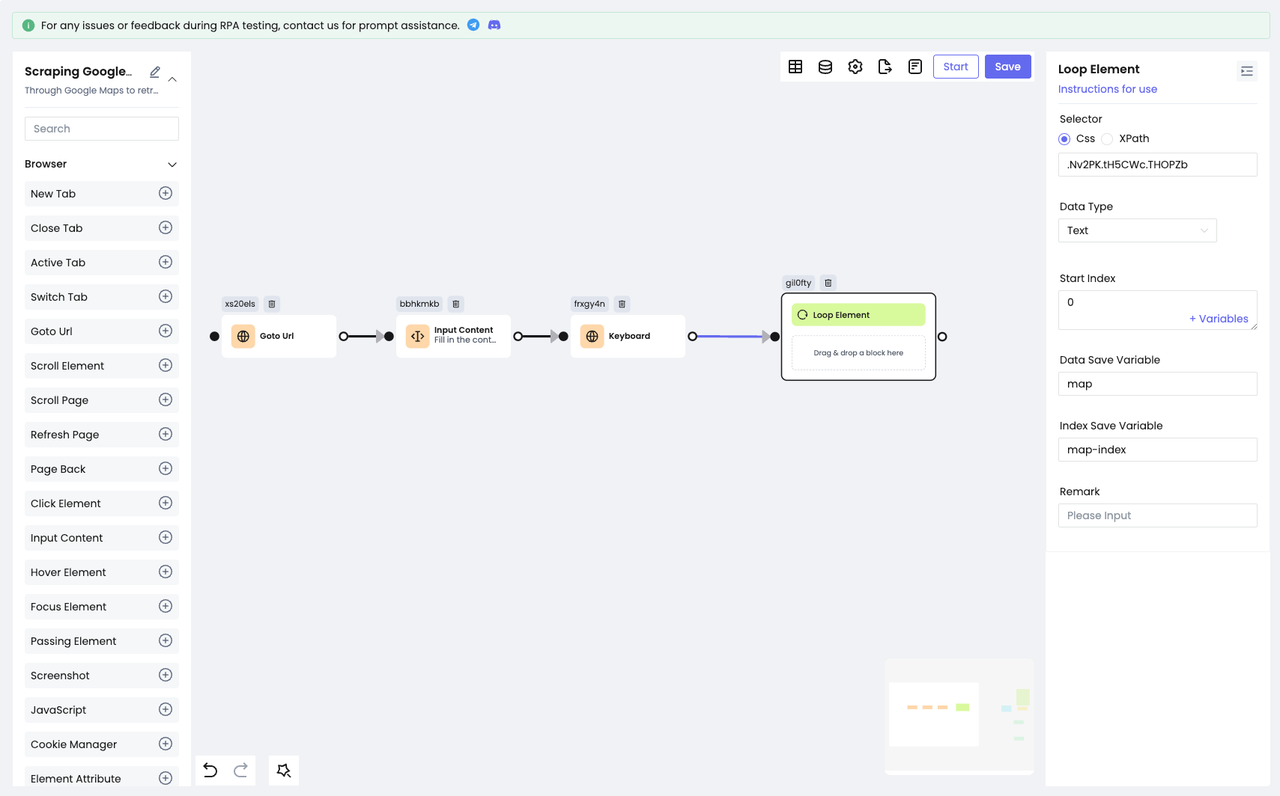
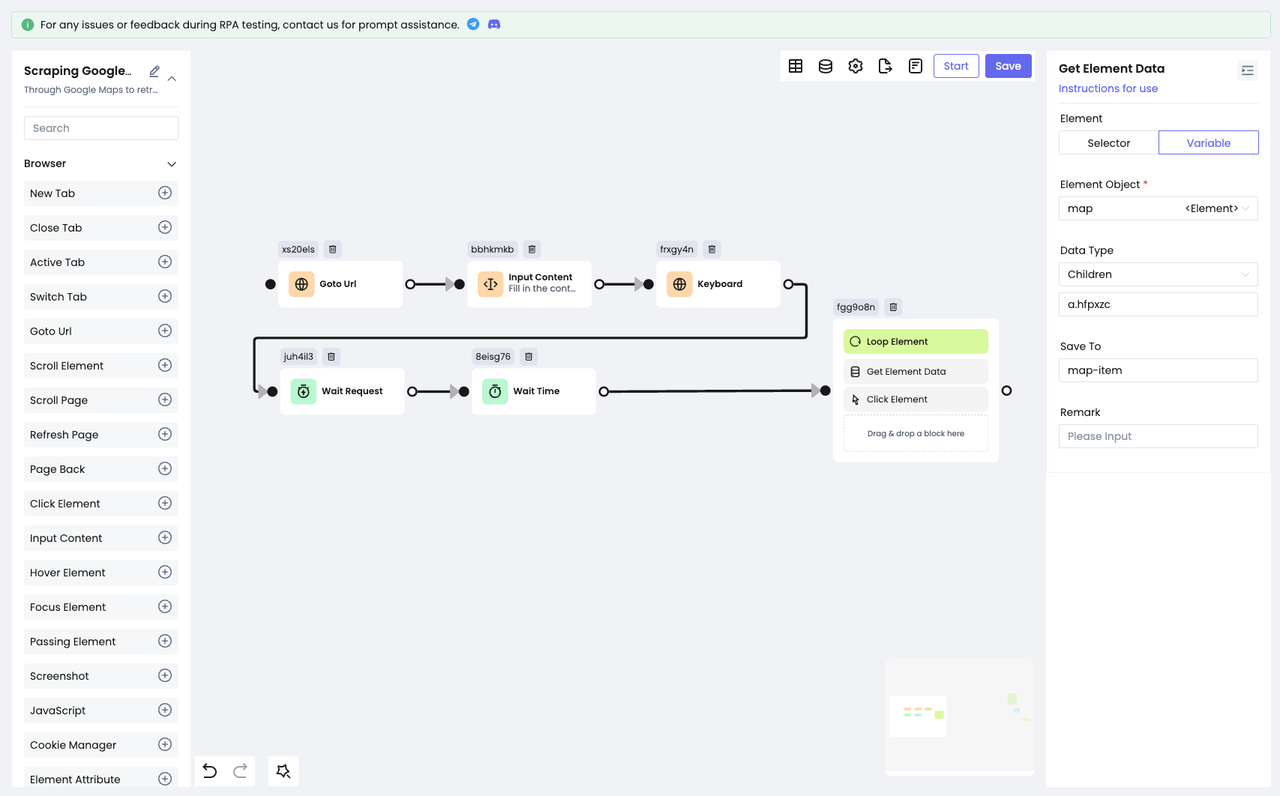
We should save each of the traversed elements to the map variable and the index of each element to the map-index traversal for subsequent use.
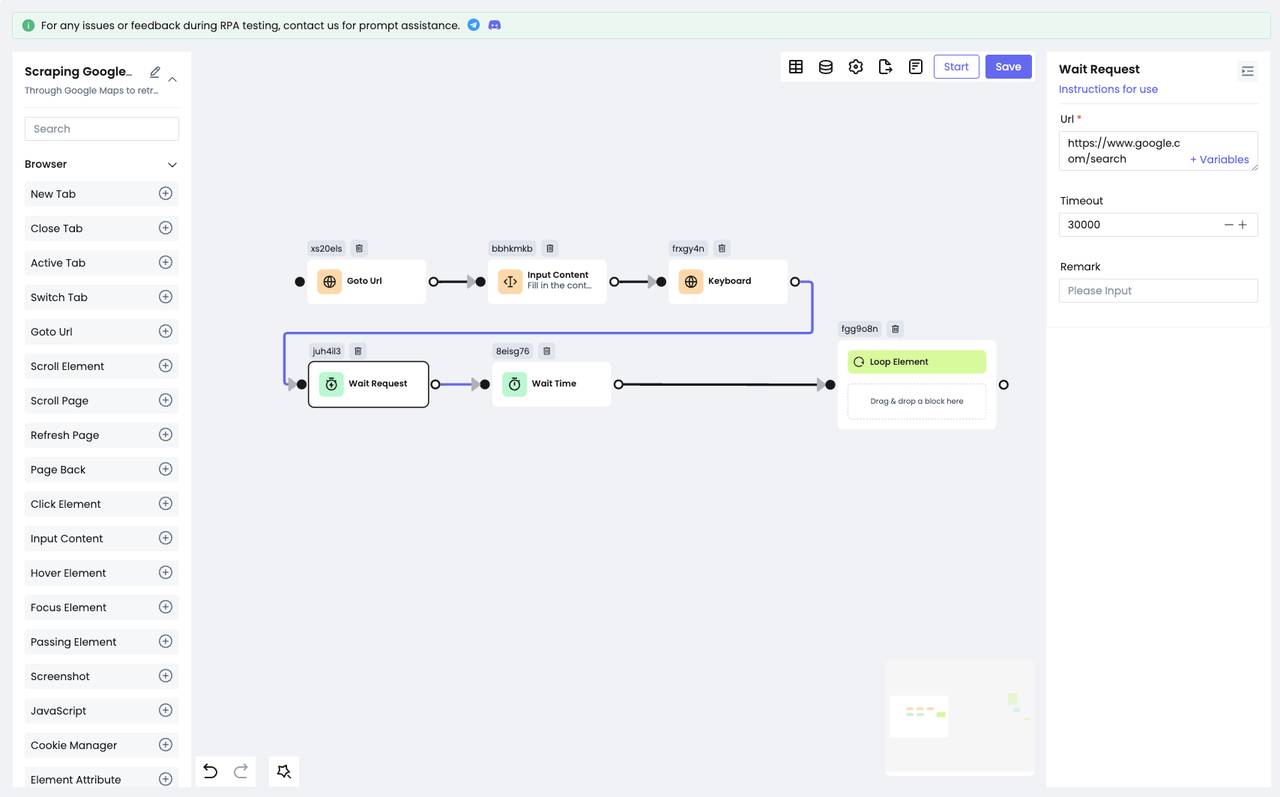
All the search results are obtained through a web request, so we have to add a "wait" action before traversing to make sure we will get the latest and correct element. Nstbrowser RPA provides two wait actions: Wait Time and Wait Request.
Wait Time: used to wait for a certain period of time. You can choose a fixed time or a random time according to your specific situation.Wait Request: used to wait for the end of the network request. It is applicable to the case of obtaining data through a network request.
Clicking on a list item
After traversing the results for each item, we need to collect the data.
Before getting the full information, click on the "list" item. Here we need to use the Get Element Data node to locate the target element to click on based on the elements saved in the map variable:
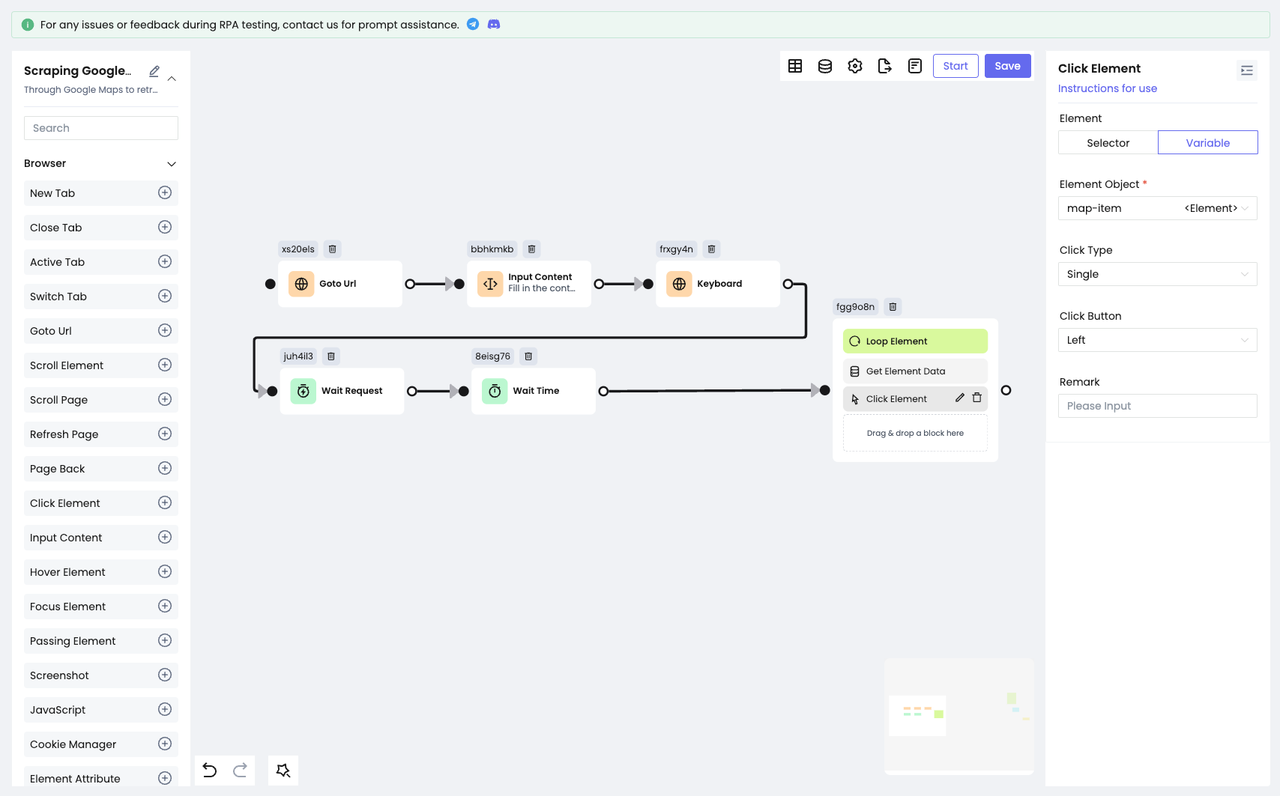
Then, use the Click Element node to simulate "click":
- Drag and drop the above nodes inside the
Loop Elementso that these nodes will be executed inside the loop.
Get element data
After performing the above actions, we can already see the specific information of each search result! Now, it's time to use the Get Element Data node to get the data we want:
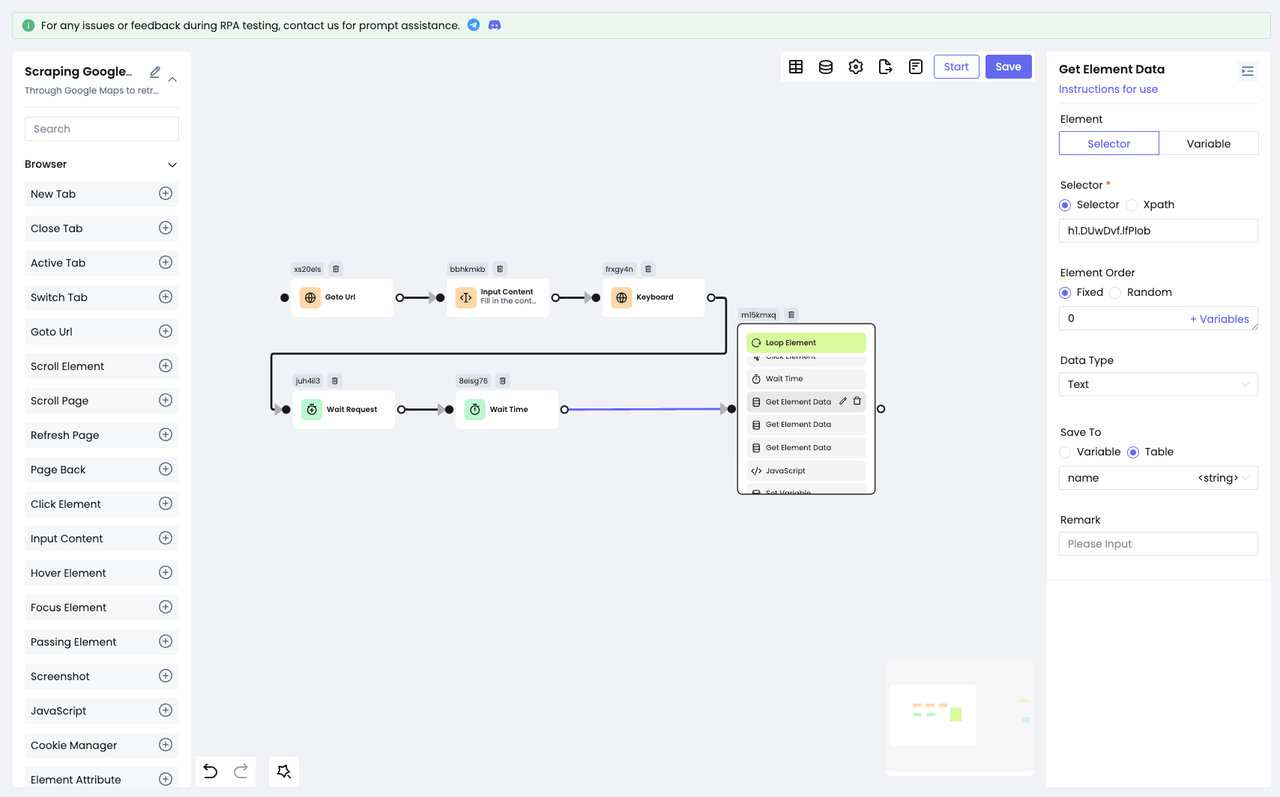
- Use DevTools to position our target element once again.
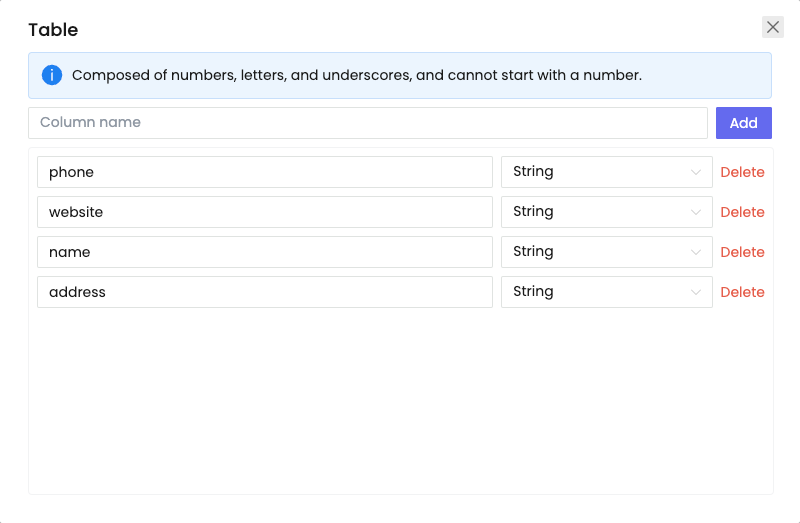
- Apply the node to retrieve the element's content and save the information to our pre-designed table:
Congratulation!
At this point, we're done crawling information from a single search result!
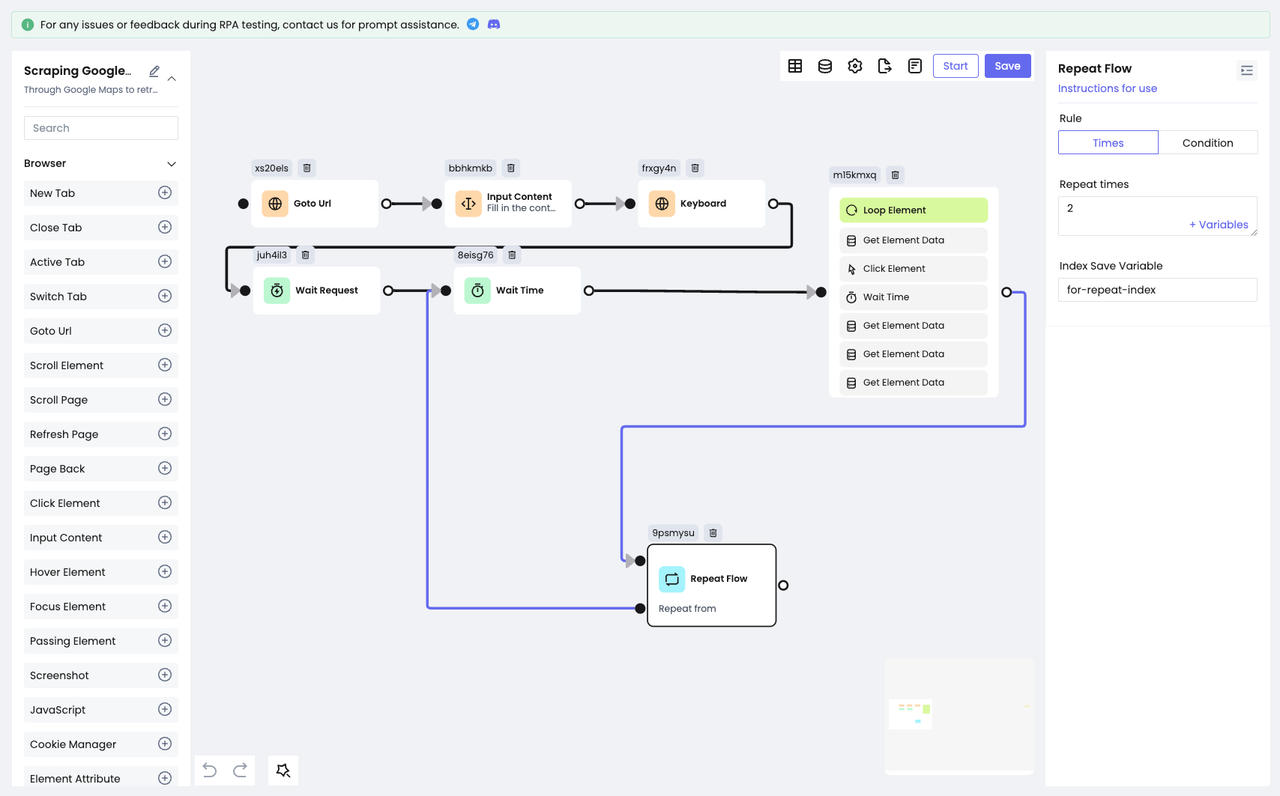
Step 5: Repeat Scraping
Of course, collecting data from a single search is not enough, and Nstbrowser's RPA functionality facilitates this repetitive work with only one node!
- The
Repeat Flownode is used to repeat the execution of an already existing node. All you need to do is just configure the number of repetitions or the end condition. As a result, Nstbrowser can repeat the action automatically according to your needs.
Suppose we need to scrape data for 2 more requests, then just configure the repeat count to 2:
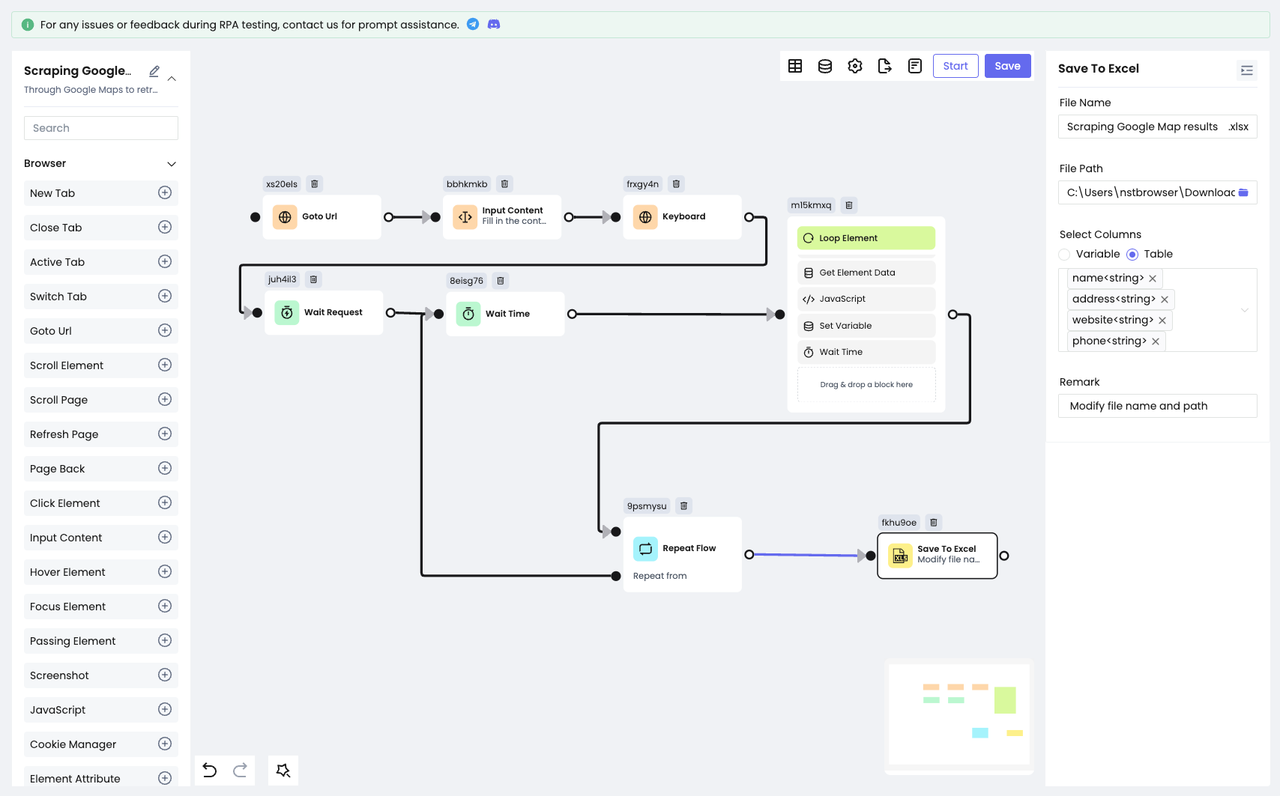
Step 6: Save the Results
By now, we have acquired all the data we want to collect and it's time to save them.
Nstbrowser RPA provides two ways to save data: Save To File and Save To Excel.
Save To Fileprovides three file types for you to choose from: .txt, . csv, .json.Save To Excel, on the other hand, can only save data to an Excel file.
For easy viewing, we choose to save the collected data to Excel:
- Add
Save To Excelnode. - Configure the file path and file name needed to be saved.
- Select the content of the table to be saved.
Step 7: Execute RPA
How to execute it automatically? We need to:
- Save our configured workflow.
- Create a new schedule.
- Click the run button.
Then, we can start collecting data from Google Maps!
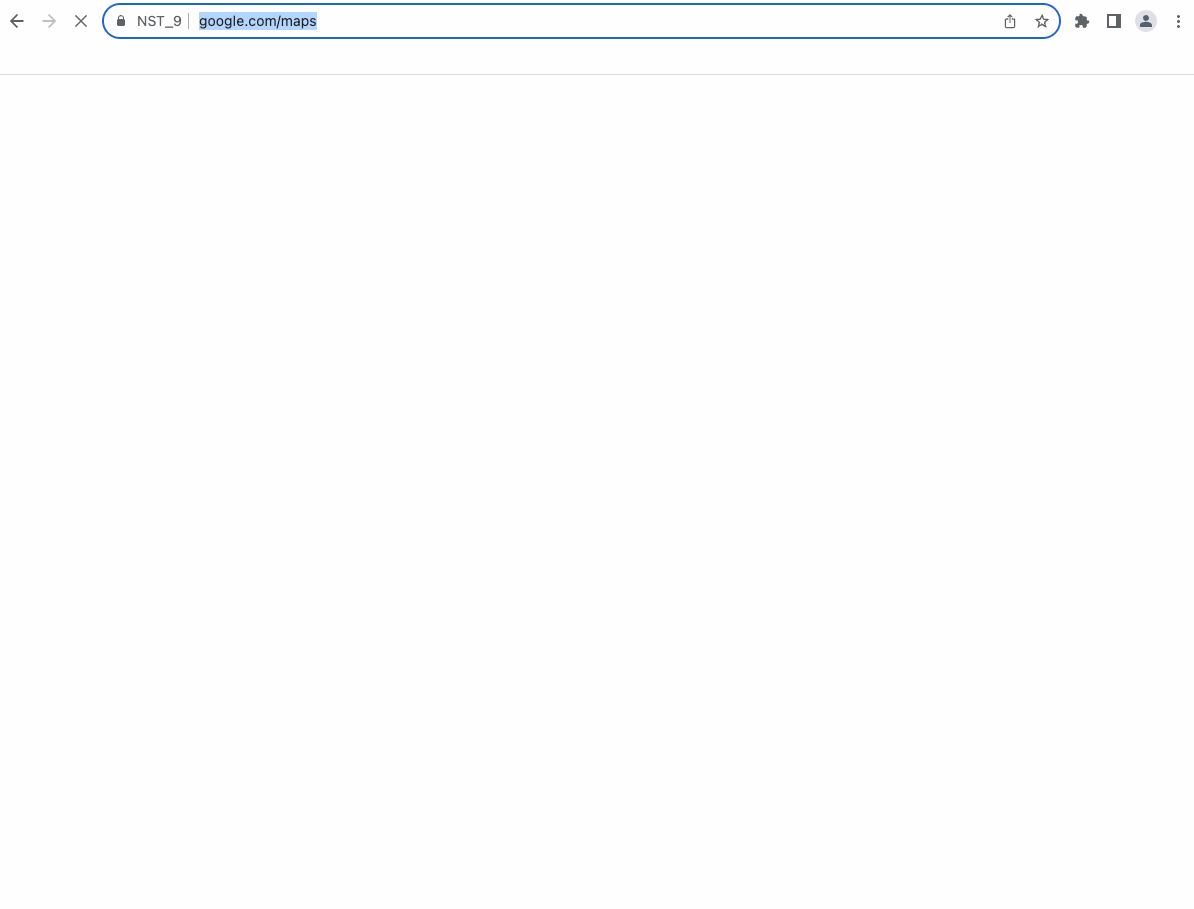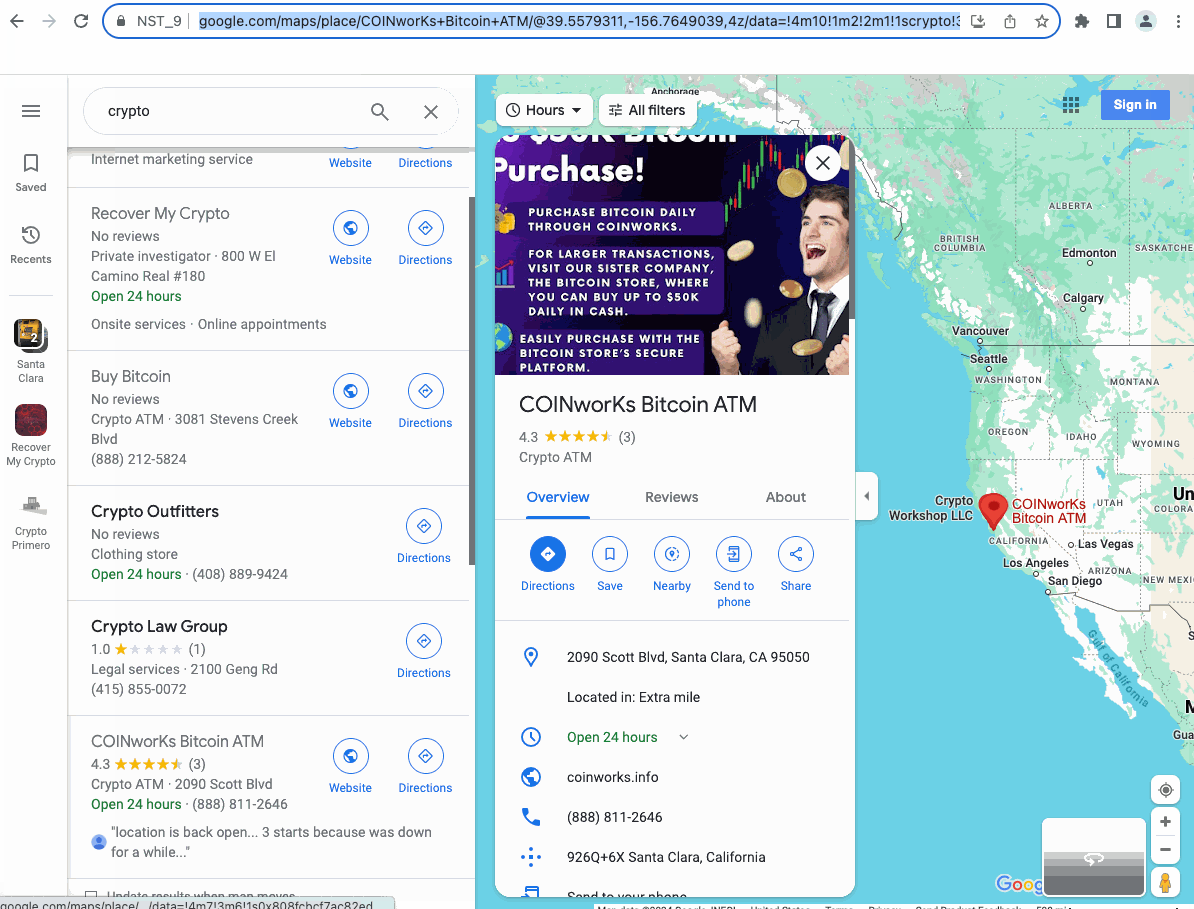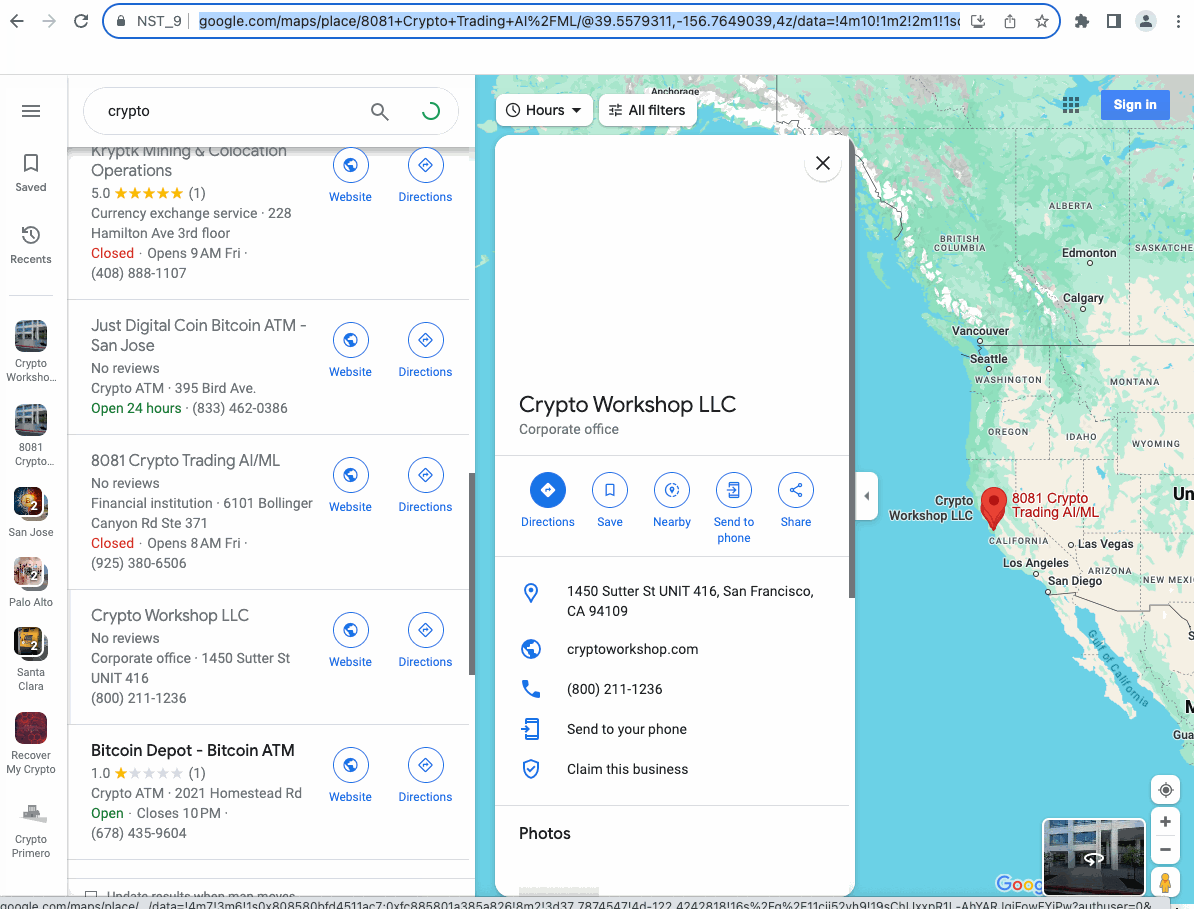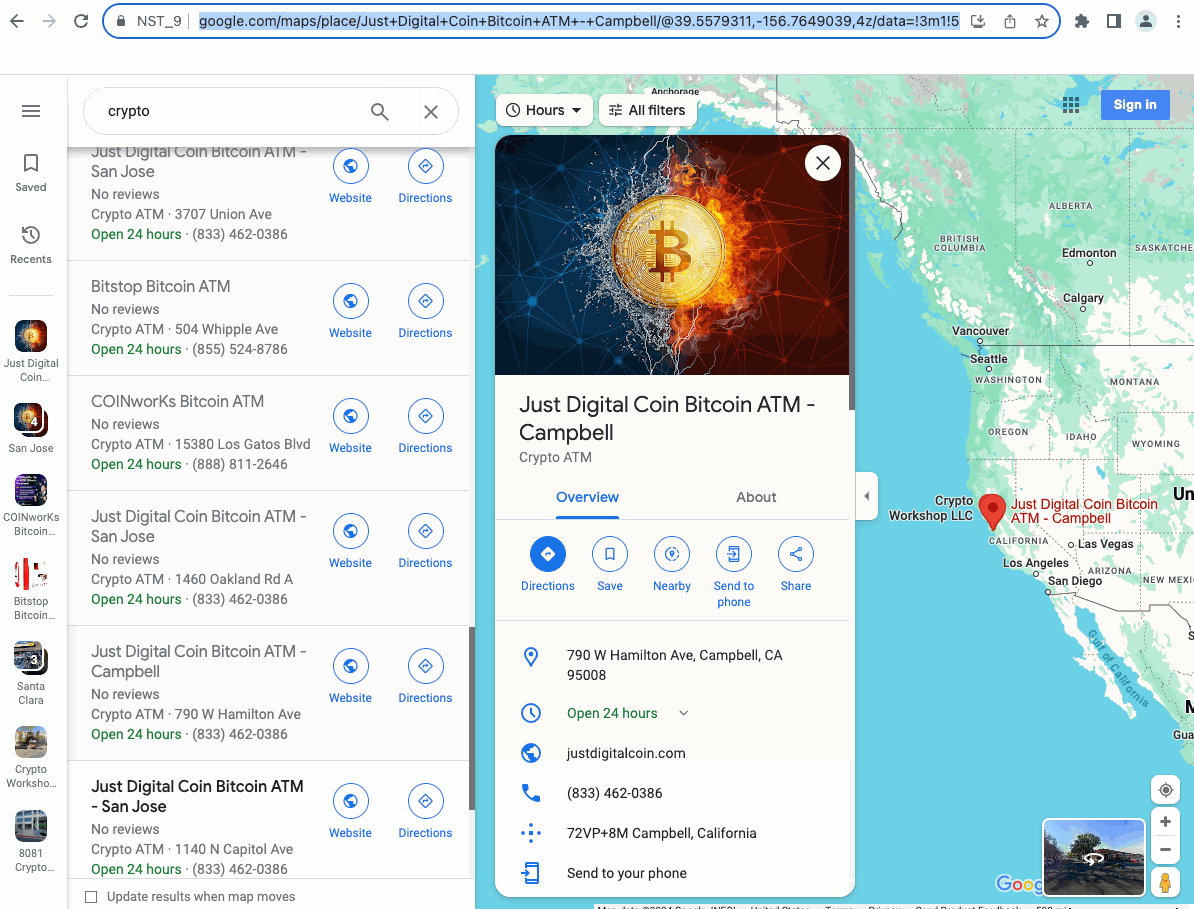
After completing, let's take a look at the results we collected:
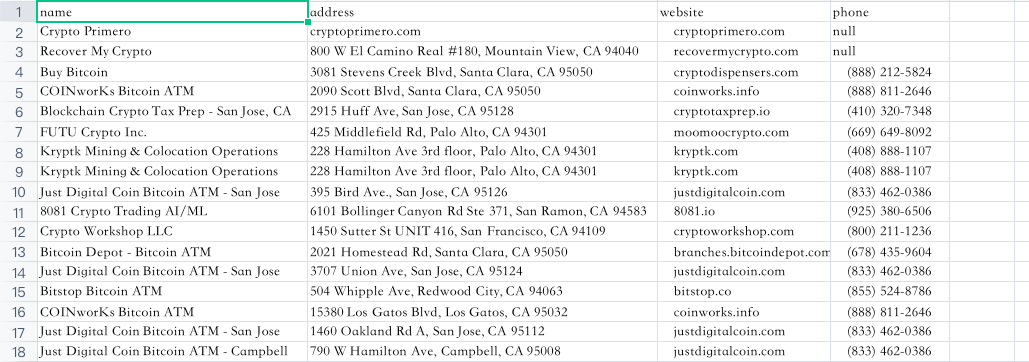
It's very cool, isn't it?
You only need to configure the workflow once, and then you can do data scraping anytime. That's why Nstbrowser RPA is charming!
Enjoy Nstbrowser Now!
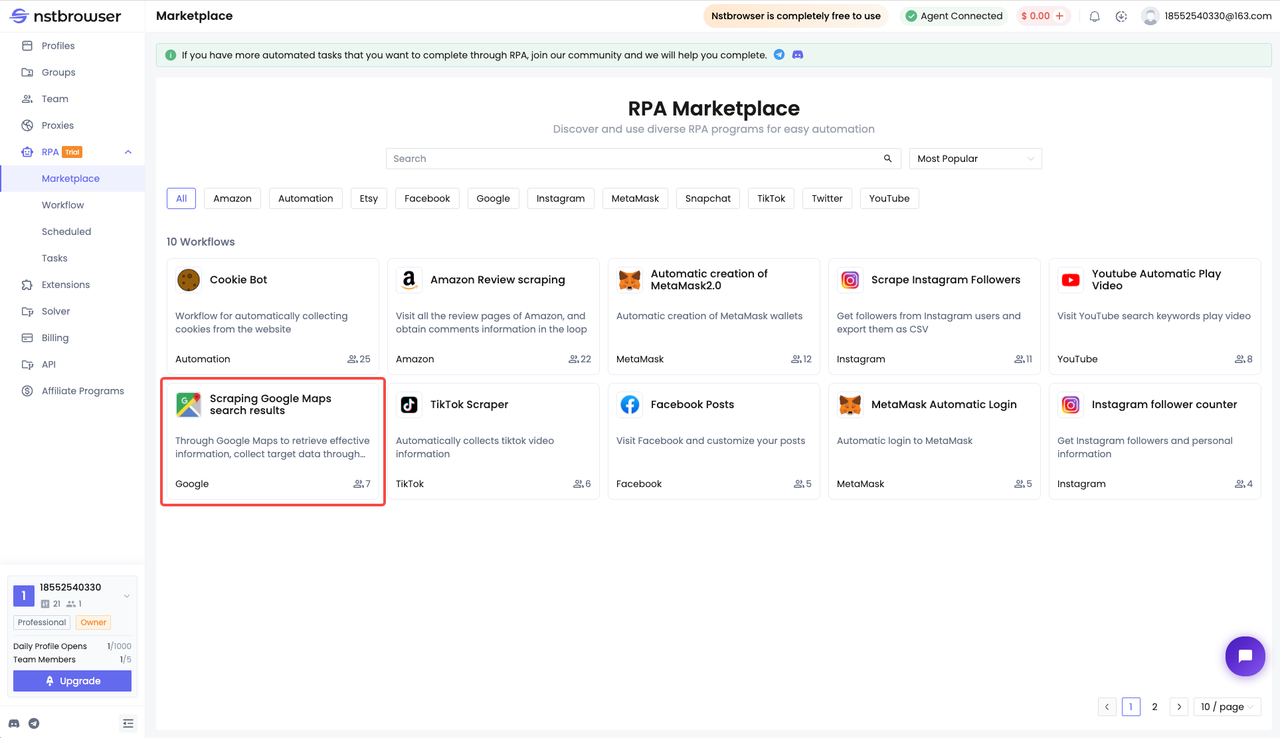
Scraping the Google Maps' search result is now available in the Nstbrowser RPA marketplace, and you can go to the RPA marketplace to get it directly! Just change the content you want to search and the path of the file you want to save after getting it, and you can start your RPA crawling journey.
More





