
Web Scraping
How to use Golang for Web Scraping?
Go, also known as Golang, provides efficient compilation speed and runtime performance. Through this step-by-step tutorials, you will learn how to do web scraping with Go.
May 20, 2024
Go, also known as Golang, refers to an open-source programming language developed by Google to improve the efficiency and speed of programming, especially when dealing with concurrent tasks. Go combines the benefits of statically typed and dynamically typed languages to provide efficient compilation speed and runtime performance.
How to build a Web Scraper using the Colly library in the Go programming language? Nstbrowser will walk through the code to understand each part.
Let's not waste more time! Figure out the detailed steps now.
Why Use Go for Web Scraping?
- Plain and concise. Go's syntax is designed to be simple and easy to learn and use, reducing code complexity.
- Built-in concurrency support. Go provides powerful concurrent programming capabilities through goroutines and channels, making it easy to develop high-performance concurrent applications.
- Garbage collection. Go has an automatic garbage collection mechanism to help manage memory and improve development efficiency.
Preparation
Installing Go
Before scraping, let's set up our Go project. I'm going to take a few seconds to discuss how to install it. So, if you've already installed Go, check it again.
Depending on your operating system, you can find installation instructions on the Go documentation page. If you're a macOS user and using Brew, you can run it in Terminal:
bash
brew install goAssembling the project
Create a new directory for your project, move to this directory, and run the following command where you can replace the word webscraper with any module you want to name.
bash
go mod init webscraper- Note: The
go mod initcommand creates a new Go module in the directory where it is executed. It creates a newgo.modfile that defines dependencies and manages the versions of third-party packages used in the project (similar to package.json if using node).
Now you can set up your web crawling Go scripts. Create a scraper.go file and initialize it as follows:
Go
package main
import (
"fmt"
)
func main() {
// scraping logic...
fmt.Println("Hello, World!")
}The first line contains the name of the global package. Then there are some imports, followed by the main() function. This represents the entry point for any Go program and will contain the Golang web crawling logic. Then, you can start the program:
bash
go run scraper.goThis will print:
PlaintText
Hello, World!Now that you've built a basic Go project. Let's dive deeper into building a web scraper using Golang!
Building a Web Scraper with Go
Next, let's take ScrapeMe as an example of how to do page scraping with Go.
Step 1. Install Colly
In order to build a web scraper more easily, you should use one of the packages introduced earlier. However, you need to figure out which Golang web scraping library is best suited for your goals at the very beginning.
To do this you need to:
- Visit your target website.
- Right-click on the background.
- Select the Inspect option. This will open DevTools in your browser.
- In the Network tab, look at the Fetch/XHR section.
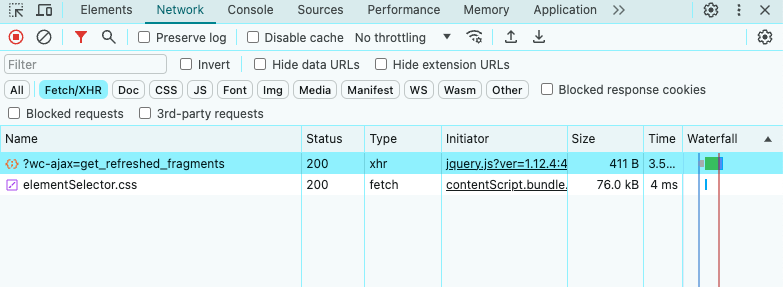
As you can see above, the target page only performs a few AJAX requests. If you study each XHR request, you'll notice that they don't return any meaningful data. In other words, the server returns an HTML document that already contains all the data. This is what usually happens with static content sites.
This means that the target site does not rely on JavaScript to dynamically retrieve data or render it. Therefore, you don't need a library with headless browser capabilities to retrieve data from the target page. You can still use Selenium, but this only introduces performance overhead. For this reason, you should prefer a simple HTML parser such as Colly.
Now let's install colly and its dependencies:
bash
go get github.com/gocolly/collyThis command will also update the go.mod file with all necessary dependencies and create the go.sum file.
Colly is a Go package that allows you to write Web Scraper and crawler, built on top of Go's net/HTTP package for network communication, and helps you to
goquery, which provides a “jQuery-like” syntax for positioning HTML elements.
Before you start using it, you need to dive into some key concepts of Colly:
The main entity in Colly is the Collector, an object that allows you to make HTTP requests and perform web scraping with the following callbacks:
OnRequest(): called before any HTTP request using Visit().OnError(): Called if an error occurs in the HTTP request.OnResponse(): Called after getting a response from the server.OnHTML(): Called after OnResponse() if the server returns a valid HTML document.OnScraped(): called at the end of all OnHTML() calls.
Each of these functions takes a callback as a parameter. Colly executes the input callback when the event associated with the function is raised. Therefore, to build a data scraper in Colly, you need to follow the callback-based function approach.
You can use the NewCollector() function to initialize the Collector object:
Go
c := colly.NewCollector()Import Colly and create the Collector by updating scraper.go as follows:
Go
// scraper.go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
// scraping logic...
}Step 2. Connect to the Target Website
Use Colly to connect to the target page with:
Go
c.Visit("https://scrapeme.live/shop/")In the back office, the Visit() function performs an HTTP GET request and retrieves the target HTML document from the server. Specifically, it fires the onRequest event and starts the Colly function lifecycle. Keep in mind that Visit() must be called after registering the other Colly callbacks.
Note that the HTTP request made by Visit() may fail. When this happens, Colly raises the OnError event. The reason for this failure may be a temporarily unavailable server or an invalid URL, while web scrapers often fail when the target site takes anti-robot measures. For example, these techniques generally filter out requests that do not have a valid User-Agent HTTP header.
What causes that?
Typically, Colly sets a placeholder User-Agent that does not match the proxy used by popular browsers. This makes Colly's requests easily identifiable by anti-scraping technologies. To avoid being blocked, specify a valid User-Agent header in Colly, as shown below:
Go
c.UserAgent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"Looking for a more efficient solution?
Nstbrowser has a complete web crawler API to handle all the anti-bot obstacles for you.
Try It for Totally Free!
Do you have any wonderful ideas and doubts about web scraping and Browserless?
Let's see what other developers are sharing on Discord and Telegram!
Any Visit() call will now perform a request with that HTTP header.
Your scraper.go file should now look like as follows:
Go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
// creating a new Colly instance
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
// visiting the target page
c.Visit("https://scrapeme.live/shop/")
// scraping logic...
}Step 3. Examine the HTML page and capture
Now we need to browse and analyze the DOM of the target web page to locate the data we need to crawl. As a result, we can adopt an effective data retrieval strategy.
- Right-click on one of the HTML cards and select “Inspect”:
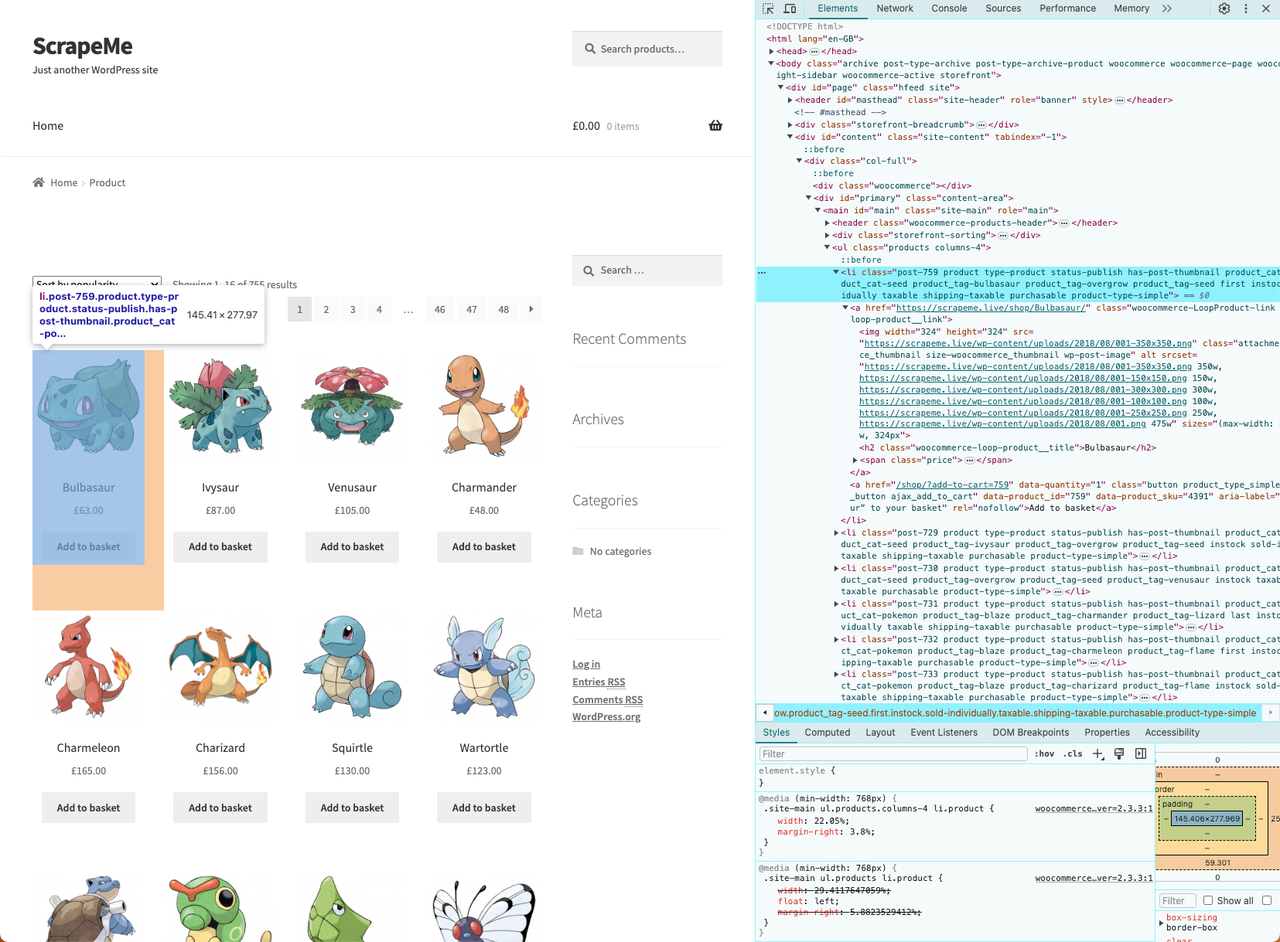
We have figured out its HTML structure, before crawling, you need a data structure to store the crawled data.
- Define the
PokemonProduct Structas follows:
Go
// defining a data structure to store the scraped data
type PokemonProduct struct {
url, image, name, price string
}- Then, initialize a slice of
PokemonProductthat will contain the scraped data:
Go
// initializing the slice of structs that will contain the scraped data
var pokemonProducts []PokemonProductIn Go, slices provide an efficient way to work with sequences of typed data. You can think of them as sort of lists.
- Now, implement the crawling logic:
Go
// iterating over the list of HTML product elements
c.OnHTML("li.product", func(e *colly.HTMLElement) {
// initializing a new PokemonProduct instance
pokemonProduct := PokemonProduct{}
// scraping the data of interest
pokemonProduct.url = e.ChildAttr("a", "href")
pokemonProduct.image = e.ChildAttr("img", "src")
pokemonProduct.name = e.ChildText("h2")
pokemonProduct.price = e.ChildText(".price")
// adding the product instance with scraped data to the list of products
pokemonProducts = append(pokemonProducts, pokemonProduct)
})The HTMLElement interface exposes the ChildAttr() and ChildText() methods. They allow you to extract the text of the corresponding attribute value from the child object identified by the CSS selector, respectively. By setting up two simple functions, you have implemented the entire data extraction logic.
- Finally, you can use
append()to attach a new element to the slice of the grabbed element.
Step 4. Converting Captured Data to CSV
The logic for exporting the crawled data to a CSV file using Go is as follows:
Go
// opening the CSV file
file, err := os.Create("products.csv")
if err != nil {
log.Fatalln("Failed to create output CSV file", err)
}
defer file.Close()
// initializing a file writer
writer := csv.NewWriter(file)
// defining the CSV headers
headers := []string{
"url",
"image",
"name",
"price",
}
// writing the column headers
writer.Write(headers)
// adding each Pokemon product to the CSV output file
for _, pokemonProduct := range pokemonProducts {
// converting a PokemonProduct to an array of strings
record := []string{
pokemonProduct.url,
pokemonProduct.image,
pokemonProduct.name,
pokemonProduct.price,
}
// writing a new CSV record
writer.Write(record)
}
defer writer.Flush()- Note: This code snippet creates a
products.csvfile and renames it using the title column. It then iterates over the slices of the grabbedPokemonProduct, converts each of them to a new CSV record, and appends it to the CSV file.
To make this snippet work, make sure you have the following imports:
Go
import (
"encoding/csv"
"log"
"os"
// ...
)Overall code presentation
Here is the complete code for the scraper.go:
Go
package main
import (
"encoding/csv"
"log"
"os"
"github.com/gocolly/colly"
)
// initializing a data structure to keep the scraped data
type PokemonProduct struct {
url, image, name, price string
}
func main() {
// initializing the slice of structs to store the data to scrape
var pokemonProducts []PokemonProduct
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
// creating a new Colly instance
c := colly.NewCollector()
// visiting the target page
c.Visit("https://scrapeme.live/shop/")
// scraping logic
c.OnHTML("li.product", func(e *colly.HTMLElement) {
pokemonProduct := PokemonProduct{}
pokemonProduct.url = e.ChildAttr("a", "href")
pokemonProduct.image = e.ChildAttr("img", "src")
pokemonProduct.name = e.ChildText("h2")
pokemonProduct.price = e.ChildText(".price")
pokemonProducts = append(pokemonProducts, pokemonProduct)
})
// opening the CSV file
file, err := os.Create("products.csv")
if err != nil {
log.Fatalln("Failed to create output CSV file", err)
}
defer file.Close()
// initializing a file writer
writer := csv.NewWriter(file)
// writing the CSV headers
headers := []string{
"url",
"image",
"name",
"price",
}
writer.Write(headers)
// writing each Pokemon product as a CSV row
for _, pokemonProduct := range pokemonProducts {
// converting a PokemonProduct to an array of strings
record := []string{
pokemonProduct.url,
pokemonProduct.image,
pokemonProduct.name,
pokemonProduct.price,
}
// adding a CSV record to the output file
writer.Write(record)
}
defer writer.Flush()
}Run your Go data scraper with:
Bash
go run scraper.goThen, you'll find a products.csv file in the root directory of your project. Open it, and it should contain:
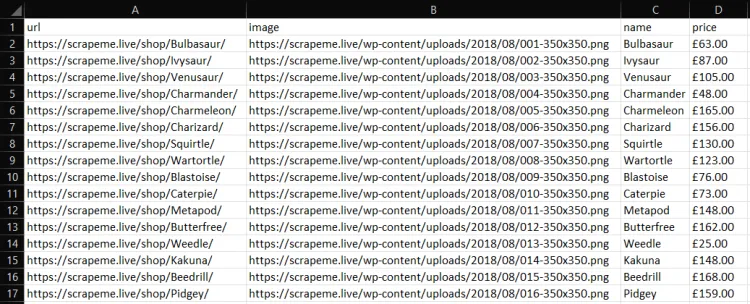
Other Effective Web Scraping Libraries
- Nstbrowser: Equipped with a comprehensive web scraping API, it handles all anti-bot obstacles for you. It was also designed with a headless browser, captcha bypass, and many more features.
- Chromedp: A faster, simpler way to drive browsers supporting the Chrome DevTools Protocol.
- GoQuery: A Go library that offers a syntax and a set of features similar to jQuery. You can use it to perform web scraping just like you would do in JQuery.
- Selenium: Probably the most well-known headless browser, ideal for scraping dynamic content. It doesn't offer official support but there's a port to use it in Go.
- Ferret: A portable, extensible, and fast web scraping system that aims to simplify data extraction from the web. Ferret allows users to focus on the data and is based on a unique declarative language.
The Bottom Lines
In this tutorial, you have
- not only learned what web scraper is
- but also understood how to build your own web scraping application using Colly and Go's standard libraries.
As you can see from this tutorial, web crawling with Go can be accomplished with a few lines of clean and efficient code.
However, it's also important to realize that extracting data from the Internet isn't always easy. There are a variety of challenges you may encounter in the process. Many websites have adopted anti-scraping and anti-bot solutions that can detect and block your Go crawling scripts.
The best practice is to use a web crawling API, such as Nstbrowser, a Totally Free solution that enables you to bypass all anti-bot systems with a single API call, as a solution to the hassle of being blocked while you perform your crawling tasks.
More





