
Web Scraping
2024 年最适合网页抓取的反检测浏览器
反检测浏览器可帮助你在搜索网页时隐藏浏览器指纹。它能真正简化你的工作。阅读本博客,了解更多信息!
Jul 19, 2024Robin Brown
浏览器指纹是识别您在线生活的最重要方式之一。它们会在不同的会话和网站中跟踪您的个人资料。所以当您想进行网络爬虫时,您注定会被检测到。
为了轻松高效地抓取数据,反检测浏览器(或反指纹浏览器)应运而生。
这篇博客将帮助您了解:
- 反检测浏览器的优势
- 它如何帮助进行网络爬虫
- 使用Nstbrowser进行高效数据抓取的步骤
什么是反检测浏览器?
反检测浏览器能够创建和运行多个不被社交平台识别的数字身份。这需要大量的自定义开发工作,因此这些工具通常不免费提供。
它们的创建目的是对抗跟踪和分析,使您能够在隐私的保护下进行活动。 换句话说,反指纹浏览器增强了隐私,保持您的数据和网络活动匿名,并帮助您的网络爬虫工具避免被封锁。
试用免费的反检测浏览器 - Nstbrowser!
解锁99.9%的网站,提供众多有效的解决方案
简化网络爬虫和自动化
您对网页抓取和 Browseless 有什么好的想法或疑惑吗?
快来看看其他开发人员在 Discord 和 Telegram 上分享了什么!
反检测浏览器如何帮助数据收集?
反检测浏览器有助于减少网络拦截的影响。它最小化甚至防止网站识别用户和跟踪他们的在线活动。
由于网站拥有反爬虫系统,当您使用爬虫机器人直接抓取数据时,您会被检测到并因此被网站封锁。人类用户优先于机器人,有些网站不鼓励其他业务收集其数据。
因此,一些组织结合网络爬虫技术和反检测浏览器与隐私措施(如代理)来帮助隐藏机器人。
什么是Nstbrowser?
Nstbrowser 是一个完全免费的反指纹浏览器,集成了反检测机器人、Web Unblocker和智能代理。它支持云容器集群、无头浏览器以及兼容Windows/Mac/Linux的企业级云浏览器解决方案。
如何使用反检测浏览器进行网络爬虫?
接下来,我们以Nstbrowser为例进行抓取。只需5个简单步骤:
第一步:准备工作
在抓取之前,您必须先进行以下准备工作:
Shell
pip install pyppeteer requests json安装pyppeteer后,我们需要创建一个新文件:scraping.py,并将我们刚安装的库以及一些系统库引入文件中:
Python
import asyncio
import json
from urllib.parse import quote
from urllib.parse import urlencode
import requests
from requests.exceptions import HTTPError
from pyppeteer import launcher我们现在可以使用pyppeteer了吗?
请冷静!
我们已经花了一些时间连接到 Nstbrowser,它提供一个API来返回pyppeteer的webSocketDebuggerUrl。
Python
# get_debugger_url: 获取调试器URL
def get_debugger_url(url: str):
try:
resp = requests.get(url).json()
if resp['data'] is None:
raise Exception(resp['msg'])
webSocketDebuggerUrl = resp['data']['webSocketDebuggerUrl']
return webSocketDebuggerUrl
except HTTPError:
raise Exception(HTTPError.response)
async def create_and_connect_to_browser():
host = '127.0.0.1'
api_key = 'your api key'
config = {
'once': True,
'headless': False,
'autoClose': True,
'remoteDebuggingPort': 9226,
'userAgent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'fingerprint': { # 必需
'name': 'custom browser',
'platform': 'windows', # 支持: windows, mac, linux
'kernel': 'chromium', # 仅支持: chromium
'kernelMilestone': '120', # 支持: 113, 115, 118, 120
'hardwareConcurrency': 4, # 支持: 2, 4, 8, 10, 12, 14, 16
'deviceMemory': 4, # 支持: 2, 4, 8
'proxy': '', # 输入格式: schema://user:password@host:port 例如: http://user:password@localhost:8080
}
}
query = urlencode({
'x-api-key': api_key, # 必需
'config': quote(json.dumps(config))
})
url = f'http://{host}:8848/devtool/launch?{query}'
browser_ws_endpoint = get_debugger_url(url)
print("browser_ws_endpoint: " + browser_ws_endpoint) # pyppeteer连接Nstbrowser与browser_ws_endpoint
(
asyncio
.get_event_loop()
.run_until_complete(create_and_connect_to_browser())
)太好了!我们成功获得了Nstbrowser的webSocketDebuggerUrl!
现在是时候将pyppeteer连接到Nstbrowser了:
Python
async def exec_pyppeteer(wsEndpoint: str):
browser = await launcher.connect(browserWSEndpoint = wsEndpoint)
page = await browser.newPage()在终端运行我们刚刚编写的代码:python scraping.py,我们成功打开了一个Nstbrowser并在其中创建了一个新标签页。
一切准备就绪,现在我们可以正式开始爬取了!
第二步:访问目标网站
Python
options = {'timeout': 60000}
await page.goto('https://www.yahoo.com/', options)第三步:执行代码
再次执行代码,然后我们将通过Nstbrowser访问目标网站。
现在我们需要打开开发工具以查看我们想要抓取的具体信息,可以看到它们都是具有相同DOM结构的元素。
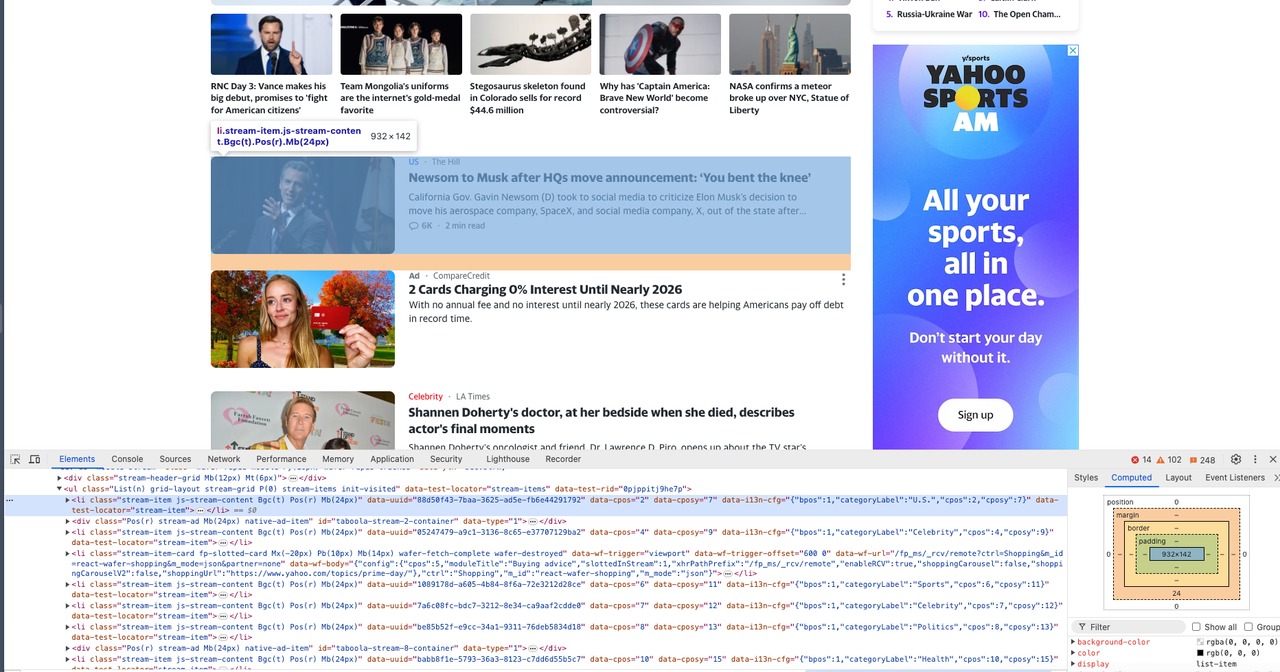
第四步:抓取网页
现在,是时候使用Pyppeteer抓取这些DOM结构并分析其内容了:
Python
news = await page.JJ('li.stream-item')
for row in news:
title = await row.J('a:not([data-test-locator])')
content = await row.J('p')
comment = await row.J('span[data-test-locator="stream-comment"]')
title_text = await page.evaluate('item => item.textContent', title)
content_text = await page.evaluate('item => item.textContent', content)
comment_text = await page.evaluate('item => item.textContent', comment)
pringt('titile: ', title_text)
pringt('content: ', content_text)
pringt('comment: ', comment_text)当然,仅在终端输出数据显然不是我们的最终目标,我们还需要做的是保存数据。
第五步:保存数据
我们使用json库将数据保存到本地json文件中:
Python
news = await page.JJ('li.stream-item')
news_info = []
for row in news:
title = await row.J('a:not([data-test-locator])')
content = await row.J('p')
comment = await row.J('span[data-test-locator="stream-comment"]')
title_text = await page.evaluate('item => item.textContent', title)
content_text = await page.evaluate('item => item.textContent', content)
comment_text = await page.evaluate('item => item.textContent', comment)
news_item = {
"title": title_text,
"content": content_text,
"comment": comment_text
}
news_info.append(news_item)
# 创建json文件
json_file = open("news.json", "w")
# 将movies_info转换为JSON
json.dump(news_info, json_file)
# 释放文件资源
json_file.close()运行我们的代码,然后打开代码所在的文件夹。您会看到一个新的news.json文件出现。打开它检查内容!
如果您发现它看起来像这样:
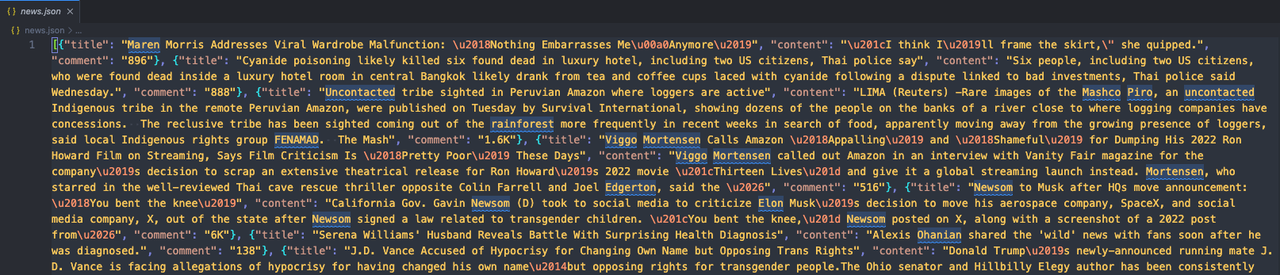
这意味着我们已经成功使用Pyppeteer和Nstbrowser抓取了目标网站!
为什么反检测浏览器最适合网络爬虫?
反检测浏览器因其模拟人类浏览行为和躲避网站检测的能力而非常适合网络爬虫。让我展示反检测浏览器的六个主要特点:
1. 避免IP封锁
网站通常会跟踪并限制来自单个IP地址的请求数量。反检测浏览器可以与代理服务集成,允许爬虫自动轮换IP地址,避免触发速率限制或封禁。
2. 绕过浏览器指纹识别
网站使用浏览器指纹识
别来检测和阻止自动化流量。反检测浏览器可以修改浏览器特性,例如用户代理、屏幕分辨率和已安装插件,创建独特的指纹,使自动请求看起来像来自不同的人类用户。
3. 模拟人类互动
反检测浏览器可以模拟人类互动,例如鼠标移动、点击和键盘输入。这种行为有助于躲避检测机制,这些机制会监控非人类模式,使爬虫过程显得更自然,减少被封禁的可能性。
4. 轮换用户代理
任何反指纹浏览器都允许轮换用户代理字符串,这有助于伪装爬虫活动。这样,网站会识别到不同浏览器和设备的请求。这种用户代理的多样性使网站更难识别和阻止爬虫机器人。
5. 执行JavaScript
许多现代网站严重依赖JavaScript来动态呈现内容。反检测浏览器可以执行JavaScript,确保爬虫能够访问和互动初始HTML源代码中不可用的内容。
6. 解决验证码
反检测浏览器通常支持与验证码解决服务的集成。此功能对于绕过网站为防止自动爬虫而实施的验证码挑战至关重要。
最后的想法
随着任何个人等待机会窃取您的数据以及任何公司准备收集您的信息以推动其业务发展,隐私至关重要。
反检测浏览器是保护您的数据而不被检测到的绝佳方式。它们还可以帮助您提升网络爬虫任务。
是时候使用Nstbrowser来帮助您保护隐私并快速高效地进行网络爬虫了!
您可能还喜欢:
使用反检测浏览器管理多个账户
更多





