
Web Scraping
2024 年使用 Java 进行网络抓取 - 最详细的指南
本指南重点介绍 2024 年使用 Java 进行网络抓取。它提供了详细的分步教程。现在就开始探索吧!
May 09, 2024Carlos Rivera
网页抓取基础教程
本指南主要介绍 2024 年使用 Java 进行网络抓取的方法。以 ScrapeMe 网站为例,逐步介绍了如何从网站中提取数据。通过使用 Java 和 jsoup 库,您将学会如何抓取静态网页资源和检索特定信息,如产品名称、图像、价格和详细信息等。
本指南帮助您掌握从类似网站中抓取数据的必要技能,并为学习更高级的网络抓取技术打下基础。
现在就开始利用 Java 的强大功能抓取网站吧!
环境要求:
需要注意的是,由于本文中的演示项目将使用 Java,因此在继续之前,请确保您已具备以下先决条件:
推荐环境:
- Java: 任何 8+ LTS 版本
- 构建工具: 与本地 Java 版本兼容的任何版本的 Gradle 或 Maven
- 集成开发环境: 任意首选,如 Eclipse、IntelliJ IDEA、VS Code
注:环境安装过程省略。
案例环境:
JDK 21
javascript
# java -version
java version "21.0.2" 2024-01-16 LTS
Java(TM) SE Runtime Environment (build 21.0.2+13-LTS-58)
Java HotSpot(TM) 64-Bit Server VM (build 21.0.2+13-LTS-58, mixed mode, sharing)构建工具:Gradle
javascript
# gradle -version
Gradle 8.7
Build time: 2024-03-22 15:52:46 UTC
Revision: 650af14d7653aa949fce5e886e685efc9cf97c10
Kotlin: 1.9.22
Groovy: 3.0.17
Ant: Apache Ant(TM) version 1.10.13 compiled on January 4 2023
JVM: 21.0.2 (Oracle Corporation 21.0.2+13-LTS-58)
OS: Mac OS X 14.4.1 aarch64IDE:IntelliJ IDEA
项目创建
项目信息:
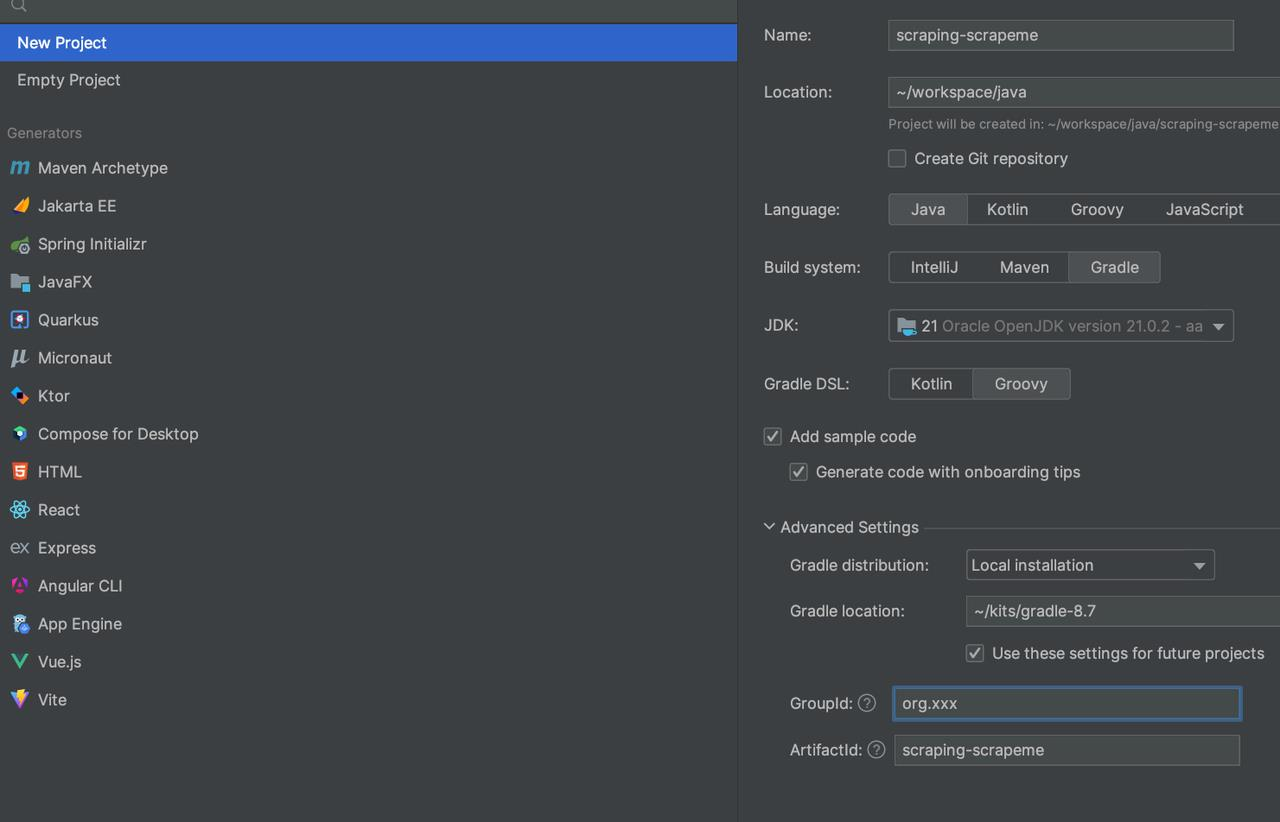
创建后,您的项目可能如下所示:
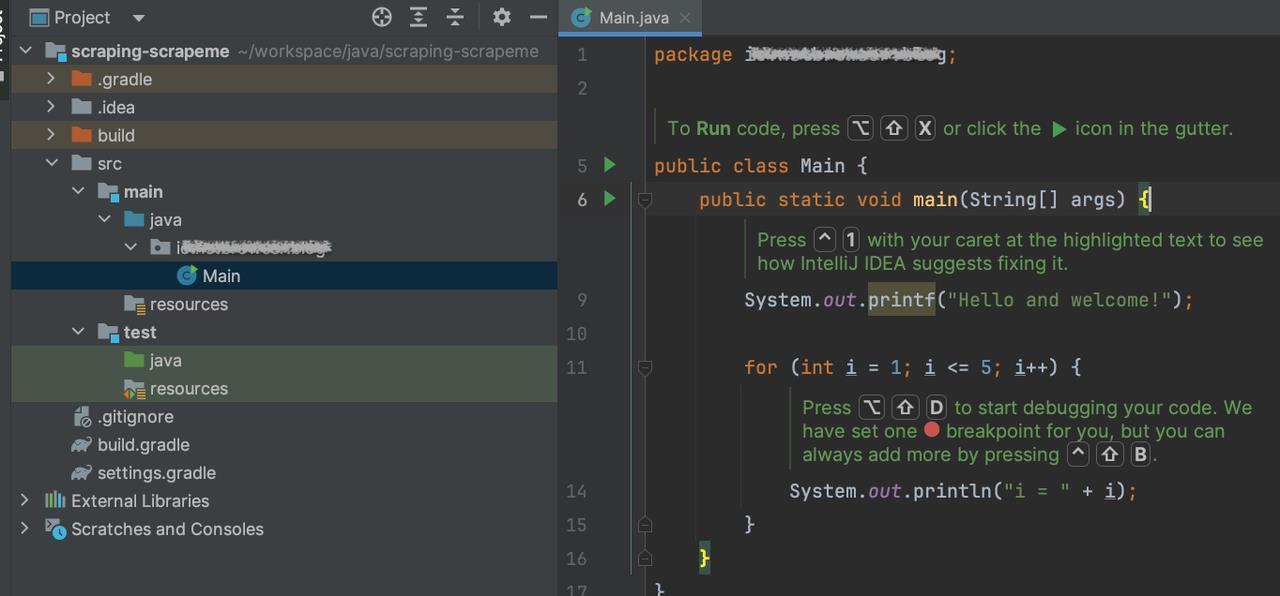
添加依赖项,暂时jsoup就足够了(jsoup:Java HTML Parser):
javascript
// gradle => build.gradle => dependencies
implementation 'org.jsoup:jsoup:1.17.2'让我们正式爬取 ScrapeMe!
现在是爬取网站的最佳时机!这里我爬取的是ScrapeMe,仅供参考。您可以完成阅读完我的所有进度,然后尝试您的项目。
目标站点分析:
首先,让我们看一下我想要从ScrapeMe站点抓取的数据。在浏览器中打开站点并查看源代码以分析目标元素。然后,通过代码检索所需的元素。
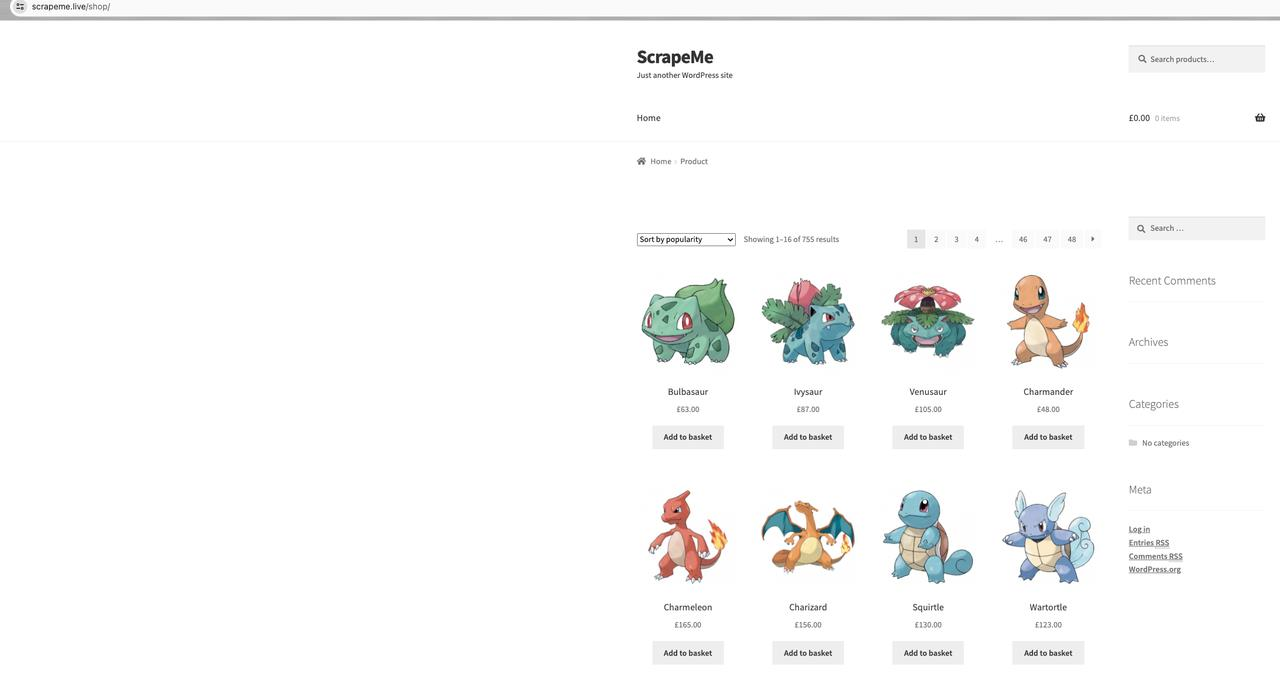
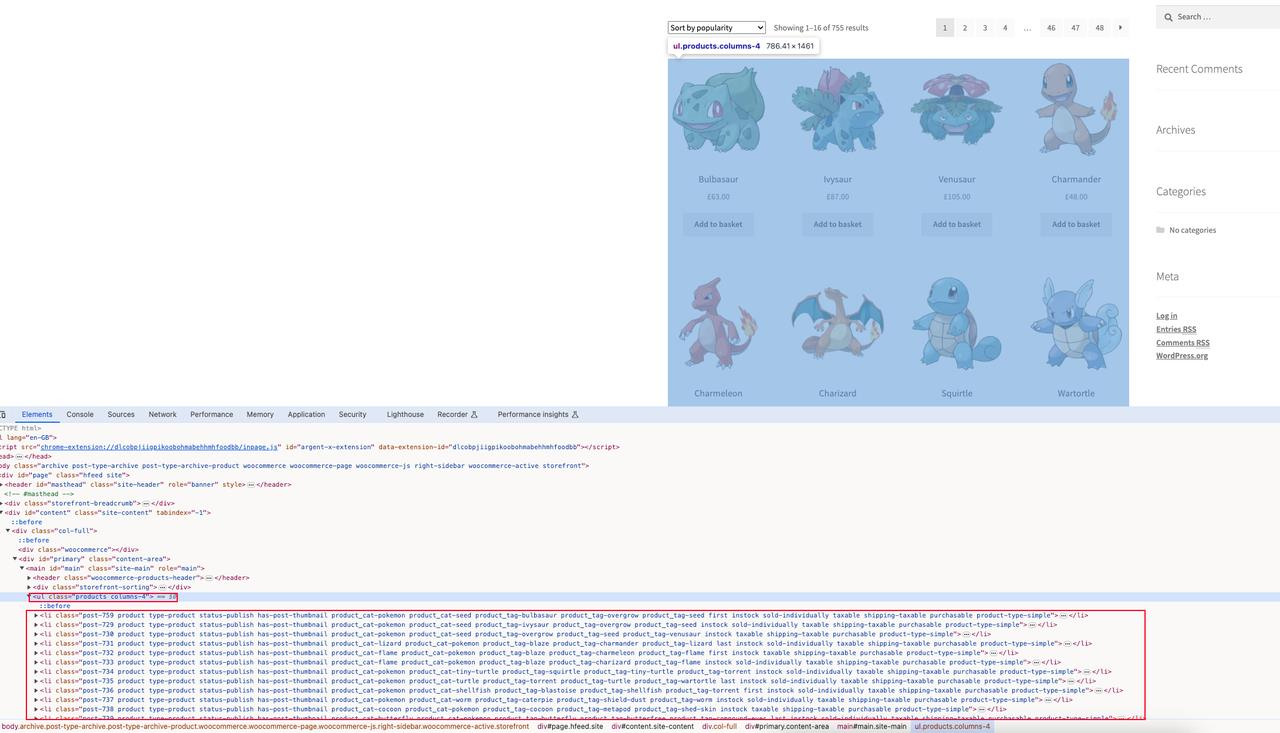
ScrapeMe主页产品列表:
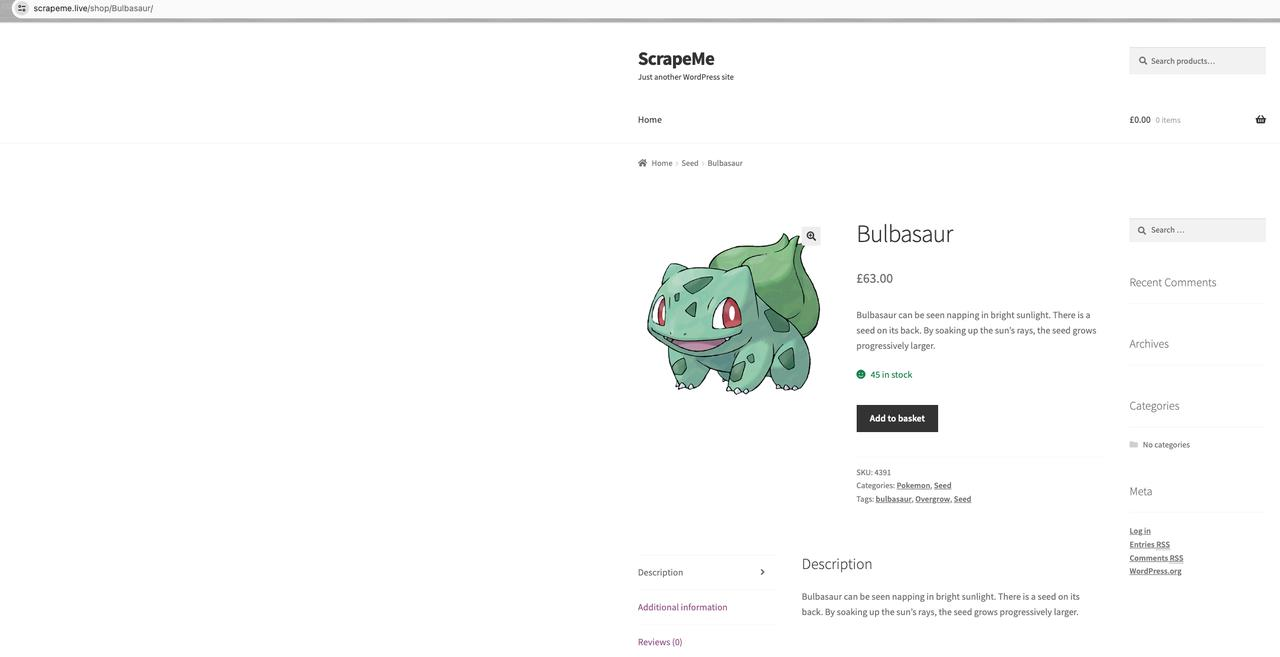
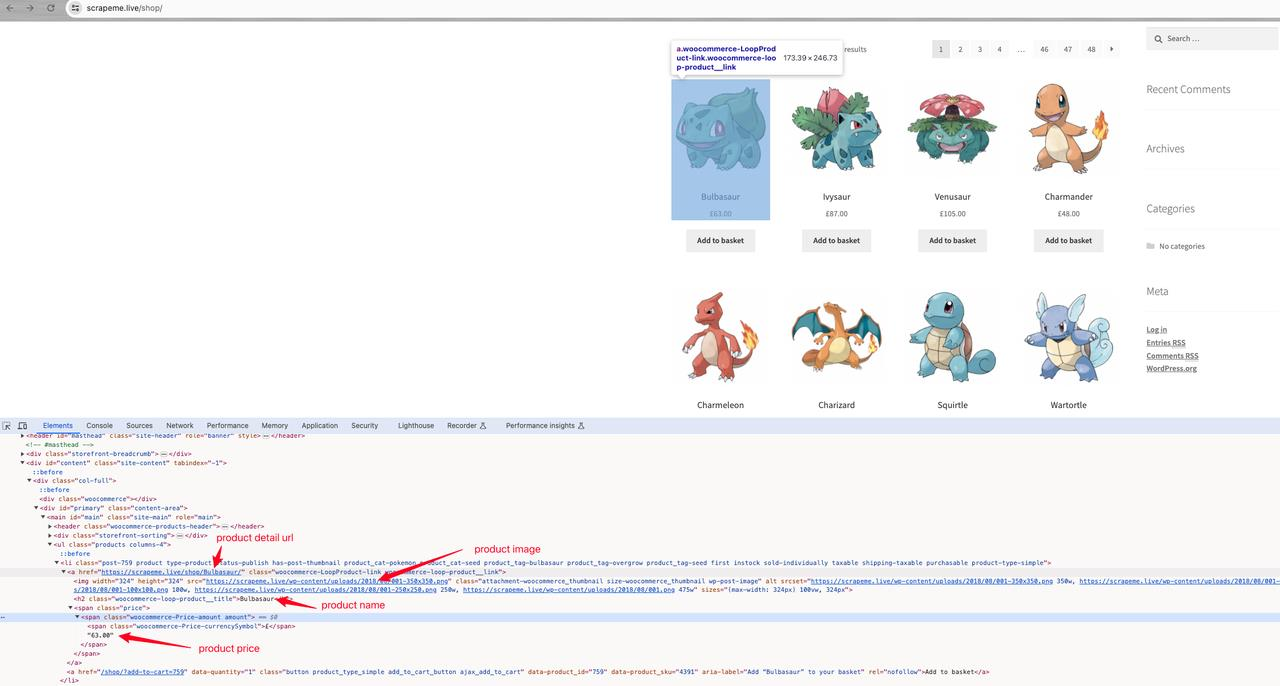
ScrapeMe 产品详细信息:
我们的目标是抓取这些产品信息的首页,包括产品名称、产品图片、产品价格和产品详细地址。
页面源码分析
页面元素
通过查看页面元素分析,我们知道当前页面有所有商品页面元素:ul.products,以及每个商品详情元素:li.product。
产品详情
进一步分析发现产品名称:a h2,产品图片:a img.src,产品价格:a span,产品详细地址:a.href。
代码演示
ScrapeMeProduct.java
java
public class ScrapeMeProduct {
/**
* product detail url
*/
private String url;
/**
* product image
*/
private String image;
/**
* product name
*/
private String name;
/**
* product price
*/
private String price;
// Getters and Setters
@Override
public String toString() {
return "{ \"url\":\"" + url + "\", "
+ " \"image\": \"" + image + "\", "
+ "\"name\":\"" + name + "\", "
+ "\"price\": \"" + price + "\" }";
}
}Scraper.java
java
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.*;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class Scraper {
// scrapeme site url
private static final String SCRAPEME_SITE_URL = "https://scrapeme.live/shop";
public static List<ScrapeMeProduct> scrape() {
// html doc for scrapeme page
Document doc;
// products data
List<ScrapeMeProduct> pokemonProducts = new ArrayList<>();
try {
doc = Jsoup.connect(SCRAPEME_SITE_URL)
.userAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36") // mock userAgent header
.header("Accept-Language", "*") // mock Accept-Language header
.get();
// select product nodes
Elements products = doc.select("li.product");
for (Element product : products) {
ScrapeMeProduct pokemonProduct = new ScrapeMeProduct();
pokemonProduct.setUrl(product.selectFirst("a").attr("href")); // parse and set product url
pokemonProduct.setImage(product.selectFirst("img").attr("src")); // parse and set product image
pokemonProduct.setName(product.selectFirst("h2").text()); // parse and set product name
pokemonProduct.setPrice(product.selectFirst("span").text()); // parse and set product price
pokemonProducts.add(pokemonProduct);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
return pokemonProducts;
}
}Main.java
java
import io.xxx.basic.ScrapeMeProduct;
import io.xxx.basic.Scraper;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<ScrapeMeProduct> products = Scraper.scrape();
products.forEach(System.out::println);
// continue coding
}
}结果表达
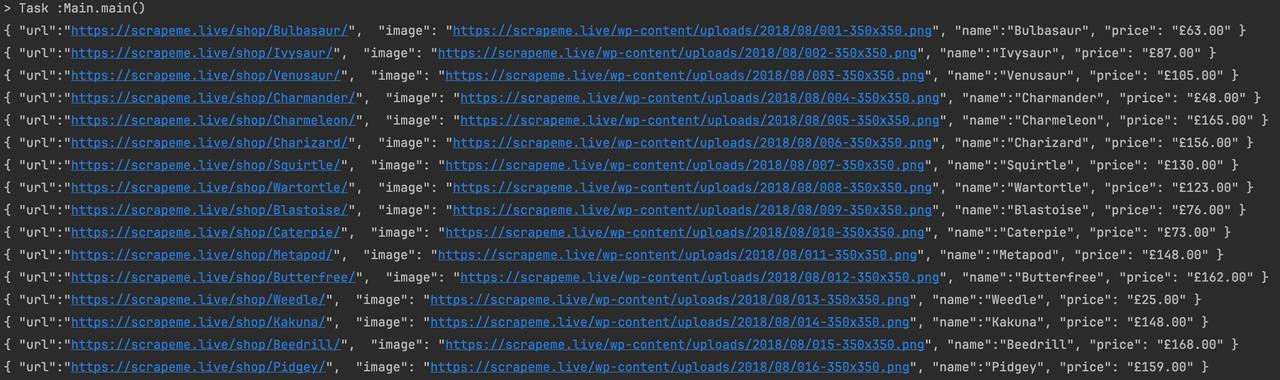
结论
到目前为止我们已经学会了使用Java进行简单的静态页面数据爬取,接下来我们将在此基础上进阶,使用 Java并发程序 爬取ScrapeMe上面的所有产品数据,以及使用Java代码连接到Nstbrowser浏览器进行爬取数据爬取,因为进阶章节会用到Nstbrowser中的无头浏览器等功能。
更多





