
Web Scraping
使用 Colly 在 Golang 中进行网页抓取的步骤
Golang 是最强大的网络爬虫工具之一。而 Colly 在使用 Go 时提供了很大帮助。阅读这篇博文,了解有关 Colly 的最详细的信息,并学习如何使用 Colly 抓取网站。
Sep 30, 2024Carlos Rivera
什么是 Colly?
Go 是一种用途广泛的语言,它拥有可以完成几乎所有工作的包和框架。
今天,我们将使用一个名为 Colly 的框架,它是一个用 Go 语言编写的、高效且强大的网页抓取框架,用于从网络上抓取数据。它提供了一个简单易用的 API,允许开发者快速构建爬虫,访问网页并提取所需信息。
什么是 Colly?
Colly 提供了一组方便而强大的工具,用于从网站提取数据、自动化网络交互以及构建网页抓取工具。
在本文中,您将获得使用 Colly 的一些实践经验,并学习如何使用 Golang:Colly 从网络上抓取数据。
Colly 如何工作?
Colly 的核心部分是 Collector。它负责执行 HTTP 请求,并允许您定义如何处理请求和响应。通过调用 c := colly.NewCollector(),您可以创建一个新的 Collector 实例,然后可以使用它来启动网络请求并处理数据。
核心功能:
1. Visit 和 Request 方法:
Visit:这是最常用的请求方法,它直接访问目标网页。Request:允许您在发送请求时附加一些额外的信息(例如自定义标头或参数),用于更复杂的请求场景。
2. 回调机制: Colly 依赖于回调函数在请求生命周期的不同阶段执行。Collector 提供了各种回调注册方法,主要包括以下六种:
OnRequest:在发送 HTTP 请求之前触发,您可以添加自定义标头、打印请求信息等。OnError:在请求过程中发生错误时触发,用于捕获和处理请求失败。OnResponse:在收到服务器响应后触发,可用于处理响应数据。OnHTML:在收到 HTML 内容并与指定的 CSS 选择器匹配时触发,用于从 HTML 页面提取数据。OnXML:当响应内容为 XML 或 HTML 时触发,可用于处理 XML 格式的内容。OnScraped:在所有请求数据处理完毕后触发,是爬虫任务结束时的回调。
3. OnHTML 回调:
- 最常用的回调函数,使用 CSS 选择器注册,当 Colly 在 HTML DOM 中找到匹配的元素时,就会调用注册的回调函数。
- Colly 使用
goquery库来解析 HTML 并匹配 CSS 选择器,而goquery的 API 与 jQuery 类似,因此可以使用 jQuery 风格的选择器从页面中提取数据。
您是否对网页抓取和 Browserless 有任何精彩的想法和疑问?
让我们看看其他开发者在 Discord 和 Telegram 上分享了什么!
如何使用 Golang 抓取网络数据?
第 1 步. 环境准备
Golang 安装
访问 Golang 官方网站,选择合适的版本进行下载安装。我们建议使用 go1.20+。本教程使用 go1.23.1。
安装完成后,可以使用终端验证安装是否成功:
Shell
go version成功输出 go 版本信息表示安装成功。
选择合适的 IDE
根据您的喜好选择合适的 IDE。推荐使用 Visual Studio。
第 2 步. 项目构建
接下来,开始创建一个项目。
- 创建一个项目目录:
Shell
mkdir gocolly-browserless && cd gocolly-browserless- 初始化 Go 项目:
Shell
go mod init colly-scraper上面的命令执行 go mod init 初始化一个名为 colly-scraper 的 go 项目,并在项目目录中生成一个 go.mod 文件,内容如下:
Go
module colly-scraper
go 1.23.1- 然后创建
main.go并创建主方法:
Go
package main
import "fmt"
func main() {
fmt.Println("Hello Nstbrowser!")
}- 运行主方法:
Shell
go run main.go如果您成功看到了打印的信息,则表示操作成功。项目已成功构建。
第 3 步. 使用 Colly
做得好!所有准备工作都已完成。接下来,我们将正式开始使用 Colly 完成一些简单的 数据抓取。
安装 Colly
在项目根路径下输入以下命令完成 Colly 安装:
Shell
go get github.com/gocolly/colly如果安装过程中报错当前 go 版本不支持,您可以选择安装更低版本的 Colly 或将 Golang 升级到对应版本。安装 Colly 后,go.mod 如下:
Go
module colly-scraper
go 1.23.1
require (
github.com/gocolly/colly v1.2.0 // indirect
...
)核心原理
Colly 的核心工作原理是通过 HTTP 请求获取网页内容,然后解析网页中的 DOM 结构,提取我们需要的特定数据。它的工作流程可以分为以下步骤:
- 创建 Collector: 这是 Colly 用于启动 HTTP 请求和处理响应的核心对象。
- 定义回调函数: Colly 通过注册回调函数来处理解析 HTML 时出现的特定元素或事件(如点击链接、解析表单等)。
- 访问目标网站: 通过调用 Visit() 方法,Collector 将会启动对指定 URL 的请求。
- 处理响应数据: 在回调函数中处理 HTML 数据,提取所需信息。
入门示例
以下是从 Nstbrowser 官方网站 访问的简单示例
Go
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
// 创建一个新的 Collector
c := colly.NewCollector()
// 回调函数,当爬虫找到一个 <title> 元素时调用
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Page Title:", e.Text)
})
// 处理错误
c.OnError(func(_ *colly.Response, err error) {
fmt.Println("Error:", err)
})
// 访问目标页面
c.Visit("https://nstbrowser.io")
}执行完以上代码后,爬虫会输出页面中 title 元素的内容。这就是 Colly 的基本工作流程,它可以轻松地解析 HTML 并提取您需要的信息。运行 go run main.go 会打印类似以下的信息:
Plain Text
Page Title: Nstbrowser - Advanced Anti-Detect Browser for Web Scraping and Multiple Accounts Managing常用设置
Colly 是一个功能强大且灵活的 Golang 爬虫框架,可以通过配置控制爬虫的行为。以下将详细介绍 Colly 中常用的配置选项,并说明其使用场景和实现方法。
- Collector 配置
colly.NewCollector 用于创建一个新的 Collector 实例,它是爬虫的核心部分。通过传递不同的配置选项,您可以自定义爬虫的行为,例如限制爬取的域名、爬取的最大深度、异步爬取等。
示例
Go
c := colly.NewCollector(
colly.AllowedDomains("example.com"), // 限制到特定域名
colly.MaxDepth(3), // 限制爬取深度
colly.Async(true), // 启用异步抓取
colly.IgnoreRobotsTxt(), // 忽略 robots.txt 规则
colly.DisallowedURLFilters(regexp.MustCompile(".*.jpg")), // 跳过某些 URL
...
)- 请求配置
Colly 提供了多种方法来配置 HTTP 请求行为,例如设置自定义请求头、代理、cookie 等。通过这些设置,爬虫可以模拟真实用户的行为,绕过一些反爬机制。
自定义 UA 头
您可以通过 Headers.Set 方法为每个请求设置自定义 HTTP 头信息。例如,设置 User-Agent 来模拟浏览器的访问行为,避免被反爬机制拦截。
Go
c.OnRequest(func(r *colly.Request) {
r.Headers.Set("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
...
})Cookie 管理
Colly 默认会自动处理 cookie,但您也可以手动设置特定的 cookie。例如,在抓取某些需要登录的页面时,可以在登录后预先设置 cookie。
Go
c.SetCookies("http://example.com", []*http.Cookie{
&http.Cookie{
Name: "session_id",
Value: "1234567890",
Domain: "example.com",
},
})设置代理
使用代理服务器可以隐藏您的真实 IP 地址,绕过一些网站的 IP 封锁策略。Colly 支持单一代理和动态代理切换。
Go
c.SetProxy("your proxy url")设置请求超时
当网站响应速度较慢时,设置请求超时可以防止程序长时间挂起。默认情况下,Colly 的超时时间为 10 秒,您可以根据需要调整超时时间。
Go
c.SetRequestTimeout(30 * time.Second)回调
Colly 支持对各种事件进行回调处理,例如页面加载成功、元素找到、请求错误等。通过这些回调,您可以灵活地处理抓取到的内容或处理抓取过程中的错误。
常见的回调示例:
- OnRequest
此回调将在发送每个请求之前被调用。您可以在此处动态设置请求头或其他参数。
Go
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting:", r.URL.String())
})- OnResponse
此回调在收到响应时被调用,用于处理原始的 HTTP 响应数据。
Go
c.OnResponse(func(r *colly.Response) {
fmt.Println("Received:", string(r.Body))
})- OnHTML
用于处理 HTML 页面中的特定元素。当页面上出现匹配的 HTML 元素时,此回调将被调用,用于提取所需信息。
Go
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Page Title:", e.Text)
})- OnError
此回调在请求发生错误时被调用。您可以在此处处理异常。
Go
c.OnError(func(_ *colly.Response, err error) {
fmt.Println("Error:", err)
})- 请求限制
Colly 还提供了一些选项来优化爬虫的性能,例如限制并发请求数量、提高爬取速度、设置请求之间的延迟等。
Go
c.Limit(&colly.LimitRule{
DomainGlob: "*", // DomainRegexp 是一个通配符模式,用于匹配域名
Delay: 3 * time.Second, // Delay 是等待创建新请求到匹配域名的持续时间
Parallelism: 2, // Parallelism 是匹配域名的最大允许并发请求数
})更多设置请参考 Colly 官方文档。
高级示例
结合我们之前学到的知识,让我们来抓取维基百科首页的分类信息数据并打印结果:
- 页面元素分析
进入首页后,我们 右键 -> 检查 或按下 F12 快捷键进入页面元素分析:
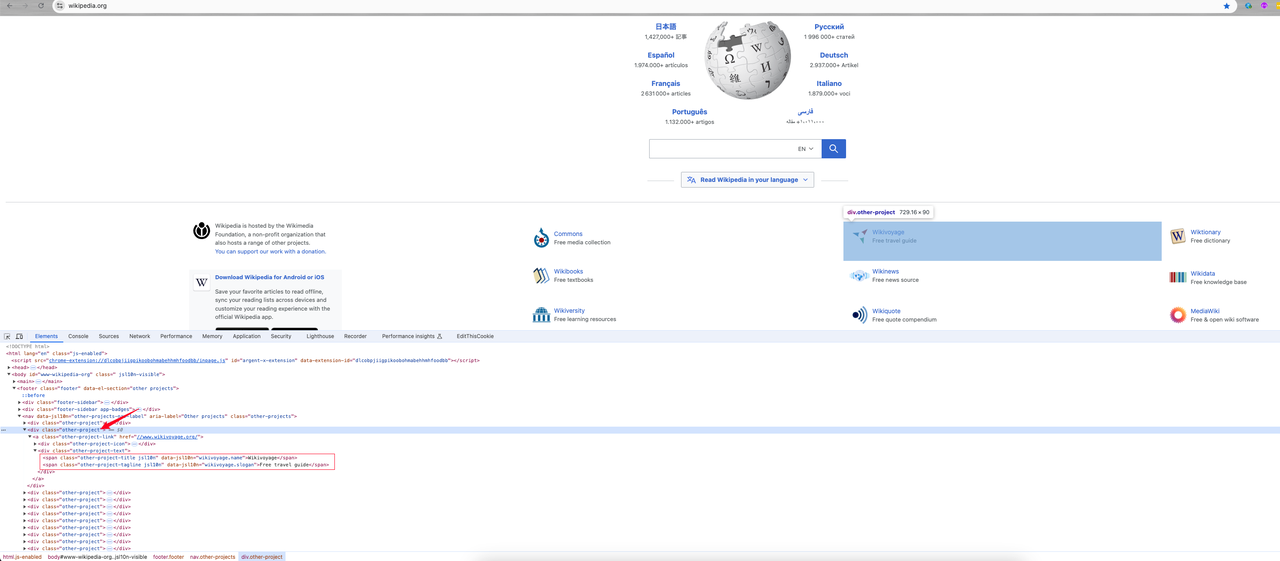
我们可以找到:
- 我需要的分类信息是 class 名为
other-project的div元素,其中分类链接是 a 标签中的href属性值。它的 class 名称为other-project-link。 - 继续跟踪这个元素,它显示了 class 元素 .other-project-text 下的两个
spanclass 名(other-project-title和other-project-tagline)是它的分类名称和介绍。
接下来,开始编码以获取我们想要的数据。
- 编码
Go
package main
import (
"fmt"
"time"
"github.com/gocolly/colly"
)
func main() {
// 创建一个新的 Collector
c := colly.NewCollector()
// 处理错误
c.OnError(func(_ *colly.Response, err error) {
fmt.Println("Error:", err)
})
// 自定义请求头: User-Agent
c.OnRequest(func(r *colly.Request) {
r.Headers.Set("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
})
// 设置代理
c.SetProxy("your proxy")
// 设置请求超时
c.SetRequestTimeout(30 * time.Second)
c.Limit(&colly.LimitRule{
DomainGlob: "*", // DomainRegexp 是一个通配符模式,用于匹配域名
Delay: 1 * time.Second, // Delay 是等待创建新请求到匹配域名的持续时间
Parallelism: 2, // Parallelism 是匹配域名的最大允许并发请求数
})
// 等待 class 为 "other-project-text" 的元素出现
c.OnHTML("div.other-project", func(e *colly.HTMLElement) {
link := e.ChildAttrs(".other-project-link", "href")
title := e.ChildText(".other-project-link .other-project-text .other-project-title")
tagline := e.ChildText(".other-project-link .other-project-text .other-project-tagline") // 项目介绍
fmt.Println(fmt.Sprintf("%s => %s(%s)", title, tagline, link))
})
// 访问目标页面
c.Visit("https://wikipedia.org")
}- 运行项目
Shell
go run main.go- 结果
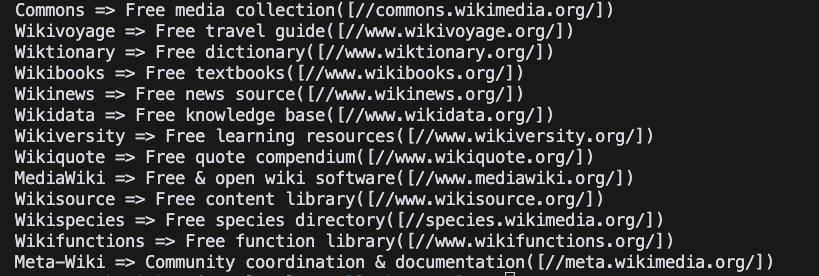
总结
亲爱的朋友们,到此为止!Nstbrowser 一直在帮助您简化网页抓取和自动化任务的每一个困难步骤。在这篇精彩的博文中,我们学习了:
- 如何构建 Colly 的基本环境。
- 常用的 Colly 配置和使用方法。
- 使用 Colly 完成对 Nstbrowser 官方网站 的访问和抓取维基百科首页 Wiki 分类数据。
通过简单的例子,我们体验了 Colly 的简洁性和强大的数据抓取能力。更多高级用法请参考 Colly 官方文档。
更多





