
Web Scraping
Java 中的 Web 爬虫:分步教程 2024
Java Web 爬虫可轻松帮助完成 Web 抓取和自动化任务。如何使用 Java Web 爬虫进行 Web 抓取?这里有您想要的一切!
Aug 16, 2024Robin Brown
如何有效地从网站获取有用信息?显然,使用Java网络爬虫是一个很好的选择!
在这篇博客中,您将学习到:
- 网络爬虫和网页抓取之间的区别是什么?
- 如何使用Jsoup解析和提取网页数据?
- 如何避免被检测并提高抓取效率和稳定性?
Java可以进行网页抓取吗?
可以!作为一种成熟且广泛使用的编程语言,Java提供了强大的支持,使网页抓取变得高效可靠,且Java可以依赖多种库。这意味着您可以从多种Java网页抓取库中进行选择。
以下是Java网页抓取的一些主要优势:
- 丰富的库和框架。 Java提供了强大的库和框架,如Jsoup、Selenium和Apache HttpClient。它们可以帮助开发人员轻松抓取和解析网页数据。
- 出色的性能。 Java高效的内存管理和多线程支持使其在处理大量数据时表现良好。
- 跨平台能力。 Java具有平台无关性。它可以在不同操作系统上运行,无论是Windows、Linux还是macOS,确保抓取工具的一致性和兼容性。
- 强大的数据处理能力。 Java的数据处理能力非常强大,能够轻松应对复杂的数据结构和大型数据集。无论是简单的文本解析还是复杂的数据转换,Java都能提供高效的解决方案。
- 安全性。 Java的安全特性,如沙盒模型和安全管理器,为爬虫在网络环境中提供了额外的保护,确保您的系统安全不受威胁。
凭借这些优势,Java是构建强大高效的网络爬虫工具的理想选择。无论是抓取静态网页数据还是处理动态内容,Java都能为开发人员提供可靠的解决方案。
什么是Java网络爬虫?
在Java中,网络爬虫是一个用于从互联网收集数据的自动化程序。它通过模拟用户访问网页的过程来提取网页上的信息,并存储或处理这些信息以供后续使用。
Java爬虫的主要功能有:
- 发送HTTP请求。 通过Java的HTTP客户端库(如HttpURLConnection或Apache HttpClient),爬虫可以向目标网站发送请求以获取网页内容。
- 解析网页内容。 使用HTML解析库(如Jsoup)将网页内容解析为可操作的DOM结构,从中提取所需信息。
- 处理数据。 提取的信息可以进一步处理、存储或分析。例如,将数据保存到数据库、生成报告或进行统计分析。
- 跟踪链接。 爬虫可以跟踪网页上的链接,递归地抓取多个网页,以获取更全面的数据。
网络抓取与网络爬虫的主要区别
网页抓取旨在提取网页数据,而网络爬虫则旨在索引和查找网页。
网页抓取是指编写一个程序,从多个网站秘密收集数据。相反,网络爬虫则是基于超链接永久跟踪链接。
您对网页抓取和Browserless有任何奇妙的想法和疑问吗?
让我们看看其他开发者在Discord和Telegram上分享了什么!
如何使用Jsoup和Nstbrowser API进行网页抓取?
以抓取 CoinmarketCap 主页上加密货币的基本信息和价格为例,展示如何通过 Nstbrowser API 中的 LaunchExistBrowser API 在Java网络爬虫中使用Jsoup和Selenium。
在开始数据抓取之前,我们需要:
- 预先下载并安装 Nstbrowser,并生成您的 API 密钥。
- 创建一个配置文件,并点击启动配置文件以自动下载相应版本的内核。
- 最后一步是下载与内核版本对应的chromedriver,然后在使用selenium时可以参考:How to use in Selenium in Nstbrowser。
页面分析
开始分析网站,看看我们想要抓取的页面是什么样子:
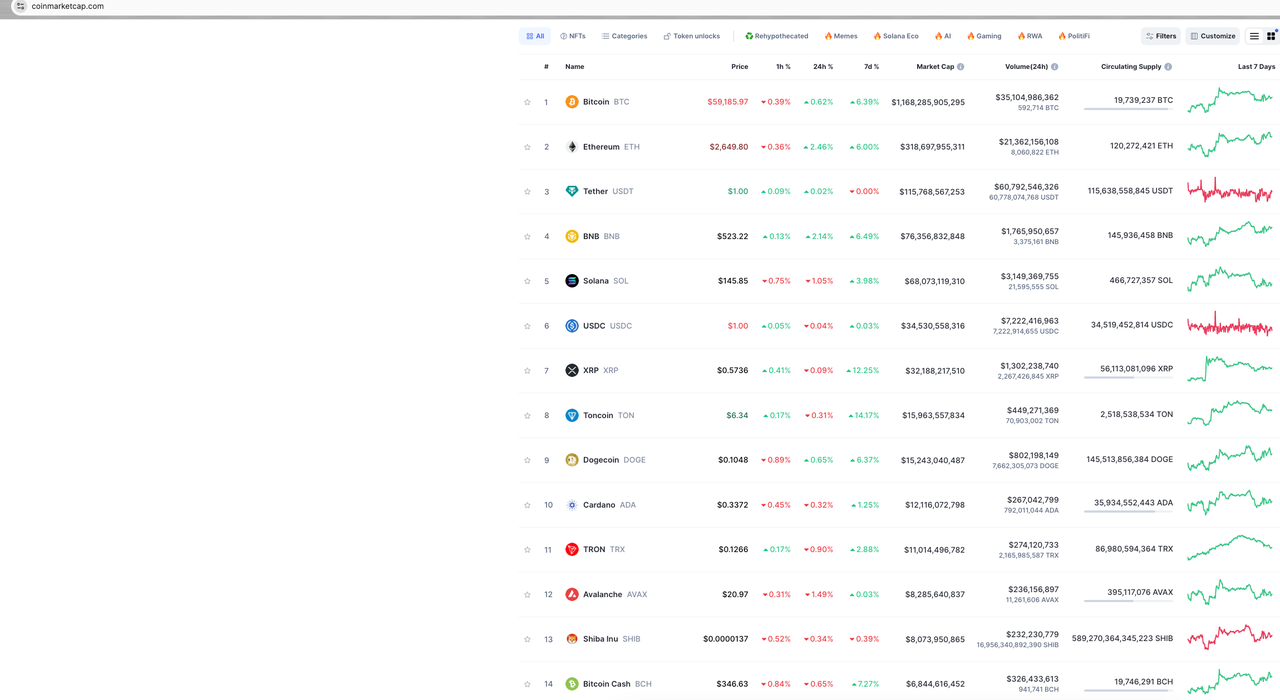
我们的目标数据是 CoinmarketCap 主页上的数据。这里只为演示抓取部分数据,如加密货币排名、加密货币标志、加密货币名称和货币价格。
接下来,我们将逐步分析我们需要的每个数据。
步骤1. 打开浏览器控制台并开始查看页面元素:
整体分析
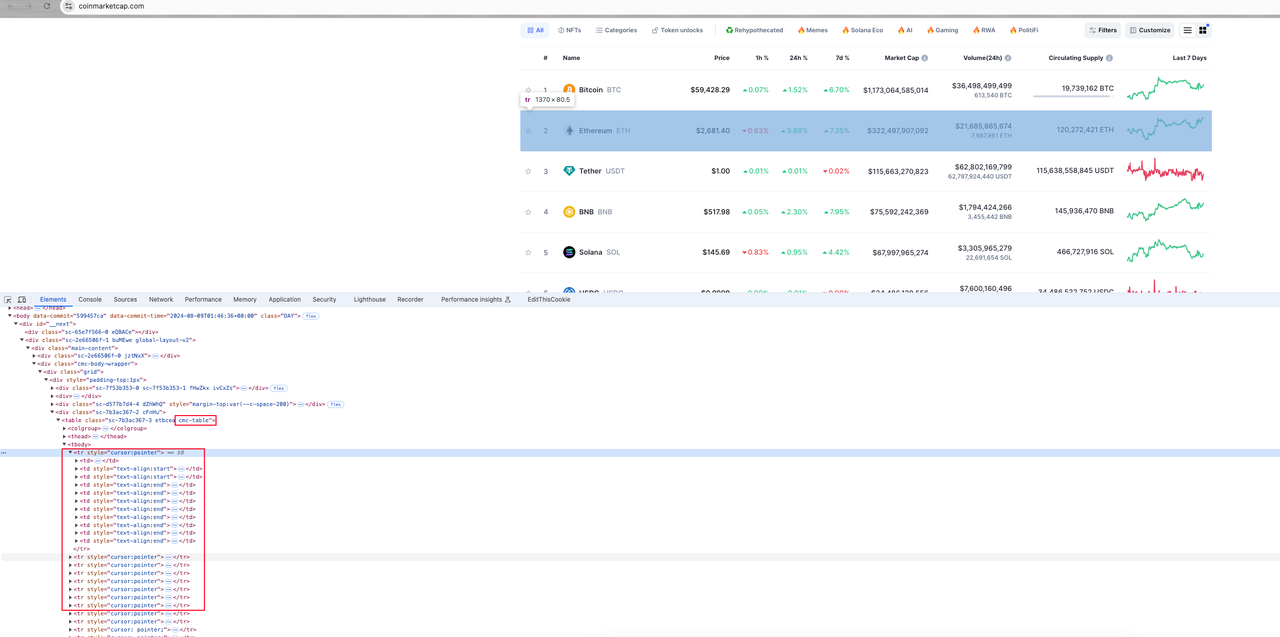
页面上所有的货币信息都包含在一个类名为cmc-rable的table元素中。每个货币信息对应的页面元素是table元素下的tr表行。每个表行包含多个表列元素td。我们的目标是从这些td元素中解析目标数据。
步骤2. 我们将搜索并分析每个目标数据:
货币排名
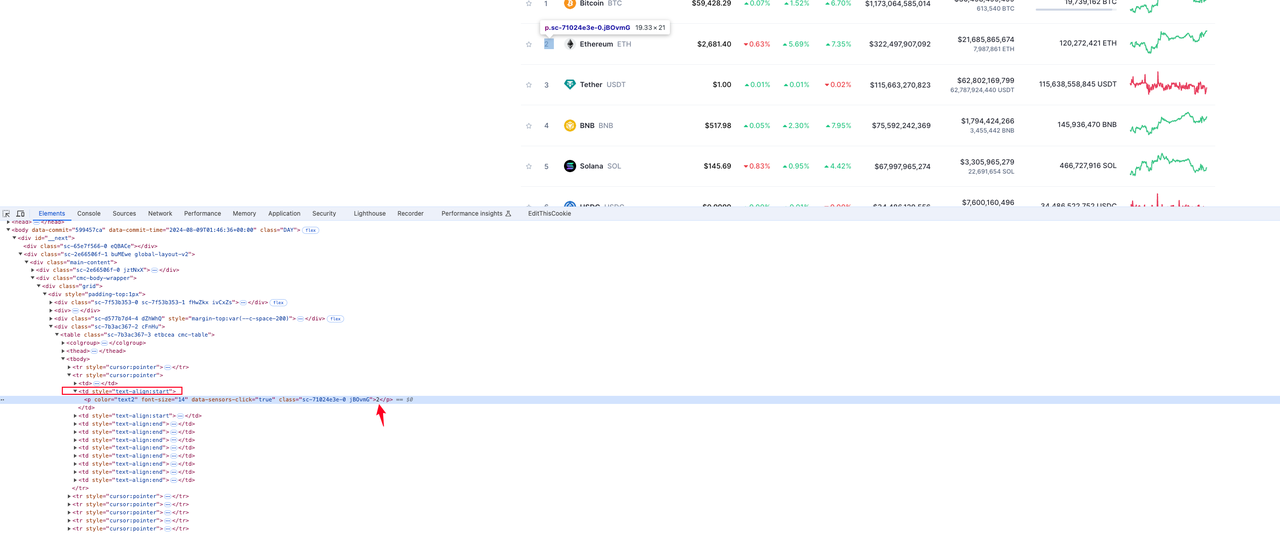
从下面的图片中可以看到,货币排名所在的元素位于tr中第二个td下的p标签值中:
货币标志
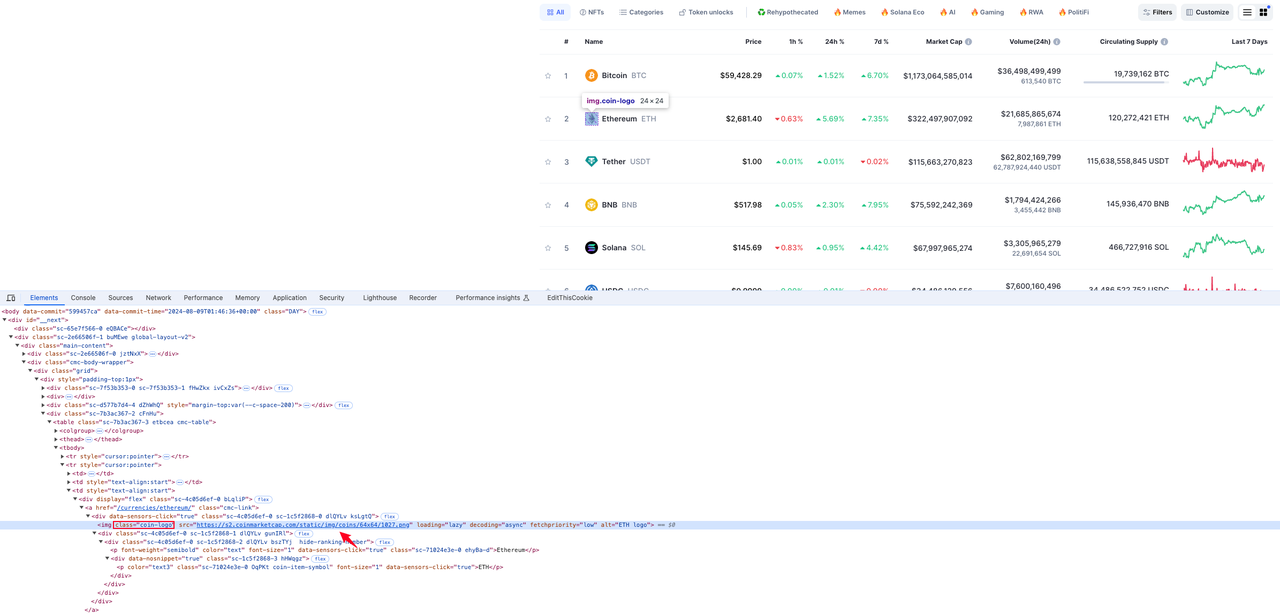
货币标志图标所在的元素位于类名为coin-logo的img标签的src属性值中:
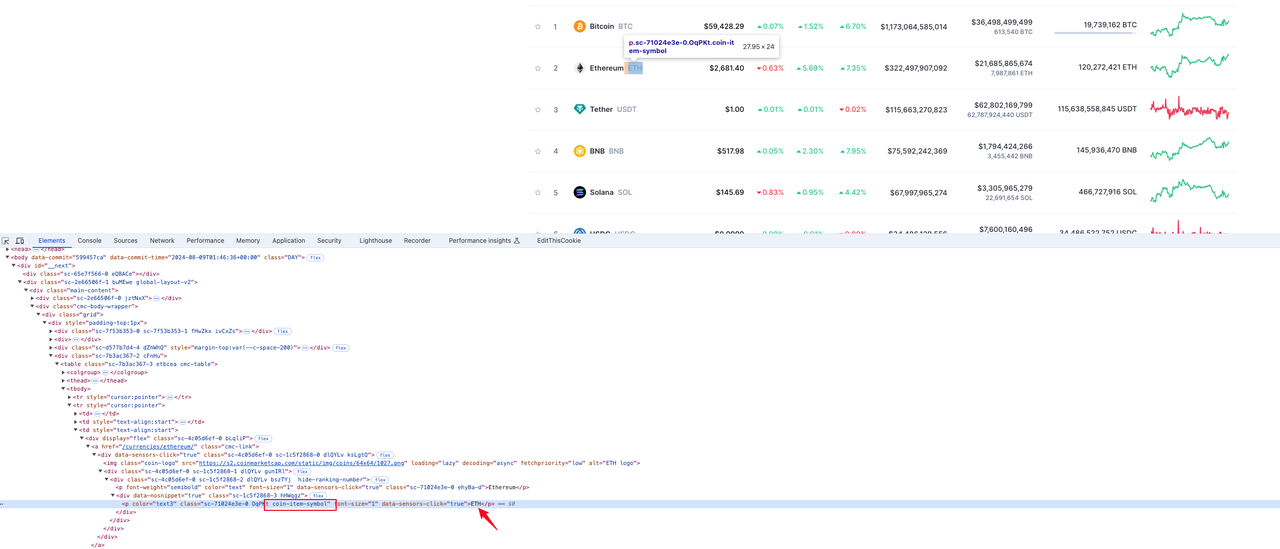
货币符号
货币信息所在的元素位于tr行元素中类名为coin-item-symbol的p标签值中:
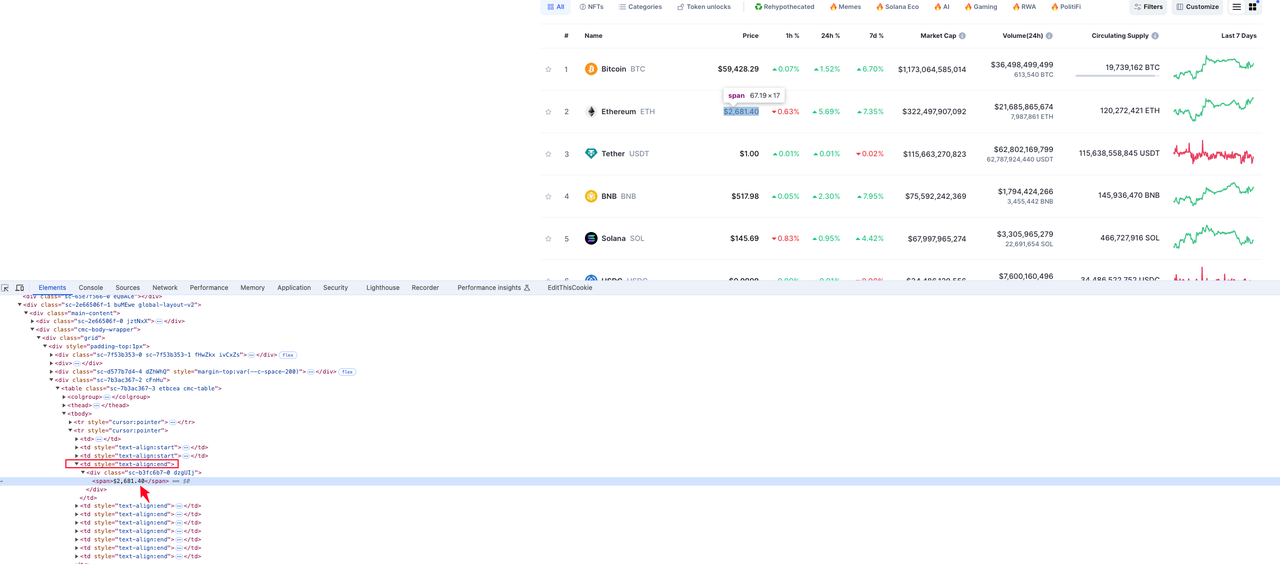
货币价格
货币信息所在的元素位于tr行元素中第四个td元素下的div span元素值中:
经过分析,我们已经获得了目标数据所在的元素。您可以自己研究更多的数据元素分析。
编码
事不宜迟,让我们直接进入代码:
dependencies(build.gradle)
Java
dependencies {
implementation 'com.squareup.okhttp3:okhttp:4.12.0'
implementation 'com.google.code.gson:gson:2.10.1'
implementation 'org.jsoup:jsoup:1.17.2'
implementation "org.seleniumhq.selenium:selenium-java:4.14.1"
}CmcRank.java
Java
public class CMCRank {
// 货币排名
private Integer rank;
// 货币符号
private String coinSymbol;
// 货币标志
private String coinLogo;
// 货币价格
private String price;
// 省略的getter和setter方法
}CmcScraper.java
Java
import com.google.gson.Gson;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
import org.openqa.selenium.*;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class CmcScraper {
// http客户端
private static final OkHttpClient client = new OkHttpClient();
// gson
private static final Gson gson = new Gson();
// 您的apiKey
private static final String API_KEY = "your apikey";
// 您的profileId
private static final String PROFILE_ID = "your profileId";
// cmc网站URL
private static final String BASE_URL = "https://coinmarketcap.com";
// nstbrowser API基础URL
private final String baseUrl;
// webdriver文件路径
private final String webdriverPath;
public CmcScraper(String baseUrl, String webdriverPath) {
this.baseUrl = baseUrl;
this.webdriverPath = webdriverPath;
}
public void scrape() {
String url = String.format("%s/devtool/launch/%
s?webgl=false", baseUrl, PROFILE_ID);
try (Response response = client.newCall(new Request.Builder()
.url(url)
.addHeader("X-API-KEY", API_KEY)
.get()
.build())
.execute()) {
Map<String, Object> data = gson.fromJson(response.body().string(), Map.class);
String wsURL = data.get("wsURL").toString();
// 设置webdriver
System.setProperty("webdriver.chrome.driver", webdriverPath);
ChromeOptions options = new ChromeOptions();
options.setExperimentalOption("debuggerAddress", wsURL);
WebDriver driver = new ChromeDriver(options);
try {
driver.get(BASE_URL);
// 等待加载
Thread.sleep(5000);
// 查找table元素
WebElement tableElement = driver.findElement(By.className("cmc-table"));
// 查找所有tr表行元素
List<WebElement> rows = tableElement.findElements(By.tagName("tr"));
List<CMCRank> ranks = new ArrayList<>();
for (WebElement row : rows) {
try {
CMCRank rank = new CMCRank();
rank.setRank(Integer.valueOf(row.findElement(By.xpath("//td[2]/p")).getText()));
rank.setCoinSymbol(row.findElement(By.className("coin-item-symbol")).getText());
rank.setCoinLogo(row.findElement(By.className("coin-logo")).getAttribute("src"));
rank.setPrice(row.findElement(By.xpath("//td[4]/div/span")).getText());
ranks.add(rank);
} catch (Exception ignored) {
System.out.println(ignored.getMessage());
}
}
ranks.forEach(System.out::println);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
driver.quit();
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
new CmcScraper("https://sandbox.nstbrowser.io", "your webdriverpath").scrape();
}
}Main.java
Java
public class Main {
public static void main(String[] args) {
String baseUrl = "http://localhost:8848";
String webdriverPath = "your chromedriver file path";
CmcScraper scraper = new CmcScraper(baseUrl, webdriverPath);
scraper.scrape();
}
}运行程序
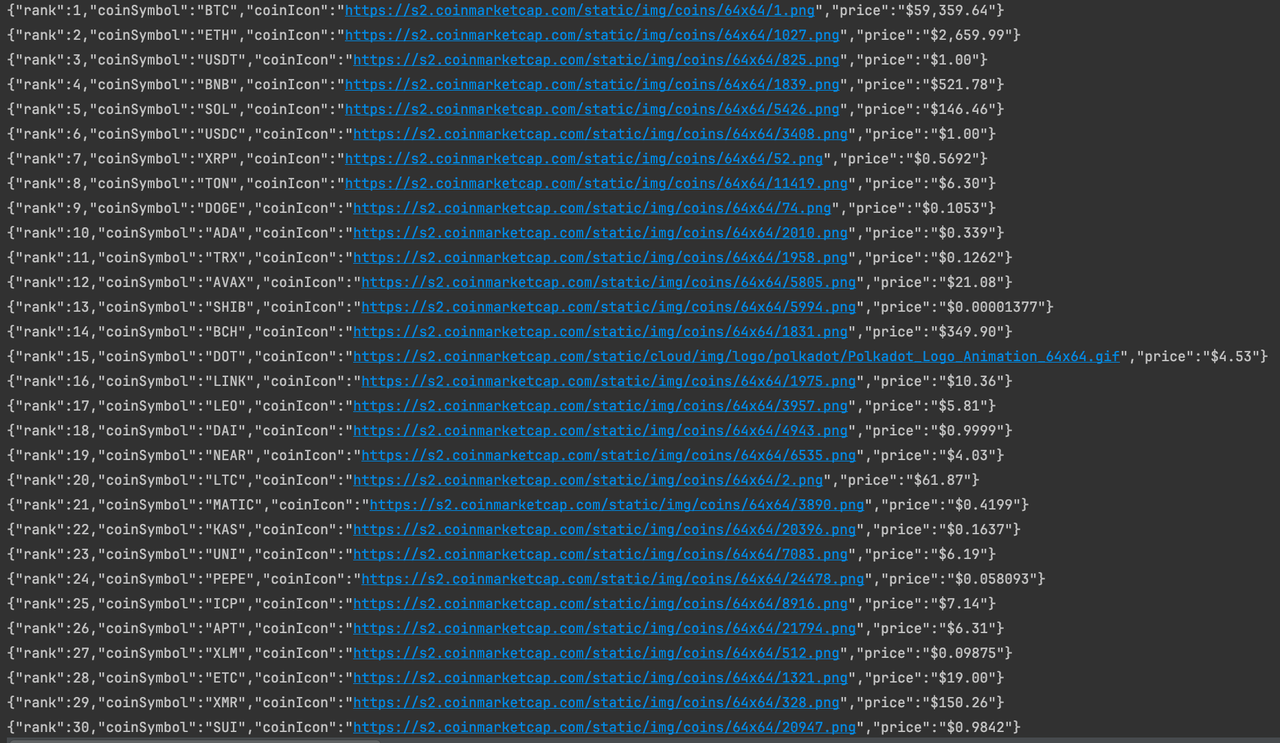
到目前为止,我们已经成功抓取了CoinmarketCap首页上的货币信息数据。如果你有兴趣,可以对页面进行深入分析,以抓取更多数据。
总结
为什么Java是进行网络爬虫的优秀编程语言?如何使用Java抓取整个网站?网络爬虫和网页抓取之间有什么区别?这些都不重要,因为在这篇博客中,你已经学到了使用Java进行专业网络爬虫所需的一切知识。
然而,在进行网络爬虫时,最重要的是:你的网络爬虫必须能够绕过反爬虫系统。这就是为什么你需要一个能够绕过网站封锁的防检测浏览器。
Nstbrowser为网页抓取提供了所有绝佳的解决方案。
更多





