
Gói Proxy giảm tới75% GIẢM+15% Thưởngvới

Bạn có phải là người thường xuyên quét web không? Bạn có rất cẩn thận về quyền riêng tư của mình không? Sau đó, bạn phải nghe về "Tác nhân người dùng" nhiều lần. Bạn có biết tác nhân người dùng là gì không? Nó ảnh hưởng đến cuộc sống trực tuyến của chúng ta như thế nào?
Bắt đầu đọc và bạn sẽ quan tâm đến mọi thứ trong blog này!
User Agent (UA) là một chuỗi mà trình duyệt hoặc các phần mềm client khác gửi đến máy chủ web. Nó có thể cung cấp thông tin về thiết bị và môi trường phần mềm của người dùng.
Bằng cách sử dụng các chuỗi tác nhân người dùng thay đổi ngẫu nhiên hoặc thích hợp, người dọn dẹp có thể bỏ qua các hạn chế truy cập, tìm nạp phiên bản nội dung web chính xác và giảm nguy cơ bị chặn.
Trình quét web của bạn bị chặn nhiều lần?
Nstbrowser xử lý các giải pháp bỏ chặn web toàn diện
Hãy thử MIỄN PHÍ ngay bây giờ!
Bạn có suy nghĩ hoặc câu hỏi nào về việc thu thập dữ liệu web và Browseless không?
Hãy đến xem những gì các nhà phát triển khác đang chia sẻ trên Discord và Telegram!
Nếu UA có thể bắt chước các trình duyệt phổ biến và được sử dụng phổ biến, chúng sẽ được coi là tác nhân người dùng tốt nhất để quét web. Dưới đây là một số trong số họ:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.59Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Mobile Safari/537.36Mozilla/5.0 (iPhone; CPU iPhone OS 14_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Mobile/15E148 Safari/604.1Mozilla/5.0 (Android 11; Mobile; rv:89.0) Gecko/89.0 Firefox/89.0Có nhiều cách để tùy chỉnh User Agent của trình duyệt, dưới đây là danh sách mã mẫu User Agent tùy chỉnh phổ biến trong các ngôn ngữ phát triển phổ biến:
Javascript
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36');
await page.goto('https://example.com');
const content = await page.content();
console.log(content);
await browser.close();
})();const axios = require('axios');
const fetchData = async () => {
try {
const response = await axios.get('https://example.com', {
headers: {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36'
}
});
console.log(response.data);
} catch (error) {
console.error(error);
}
};Python
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36'
}
response = requests.get('https://example.com', headers=headers)
print(response.content)from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36')
driver = webdriver.Chrome(options=options)
driver.get('https://example.com')Java
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
public class WebScraping {
public static void main(String[] args) throws Exception {
String url = "https://example.com";
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet request = new HttpGet(url);
request.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36");
CloseableHttpResponse response = httpClient.execute(request);
Document doc = Jsoup.parse(response.getEntity().getContent(), "UTF-8", url);
System.out.println(doc.html());
response.close();
httpClient.close();
}
}import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class WebScrapingWithChrome {
public static void main(String[] args) {
System.setProperty("webdriver.chrome.driver", "path/to/chromedriver");
ChromeOptions options = new ChromeOptions();
options.addArguments("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36");
WebDriver driver = new ChromeDriver(options);
driver.get("https://example.com");
String pageSource = driver.getPageSource();
System.out.println(pageSource);
driver.quit();
}
}Go
package main
import (
"fmt"
"io/ioutil"
"net/http"
)
func main() {
client := &http.Client{}
req, _ := http.NewRequest("GET", "https://example.com", nil)
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36")
resp, _ := client.Do(req)
defer resp.Body.Close()
body, _ := ioutil.ReadAll(resp.Body)
fmt.Println(string(body))
}Bất kể ngôn ngữ lập trình hoặc công cụ nào được sử dụng trong ví dụ trên, trường UserAgent trong tiêu đề yêu cầu HTTP đều được đặt hoặc sửa đổi bằng các phương thức hoặc cấu hình trong thư viện tương ứng.
Một số trình duyệt chống phát hiện cũng hỗ trợ tùy chỉnh User-Agent và sau đây là ví dụ cho thấy cách tùy chỉnh User-Agent thông qua trình duyệt vân tay Nstbrowser được sử dụng làm ví dụ cho thấy cách tùy chỉnh UserAgent bằng trình duyệt vân tay:
Tùy chỉnh Tác nhân người dùng bằng cách nhấp vào “Tạo” trực tiếp từ bảng “Hồ sơ” trong giao diện người dùng.
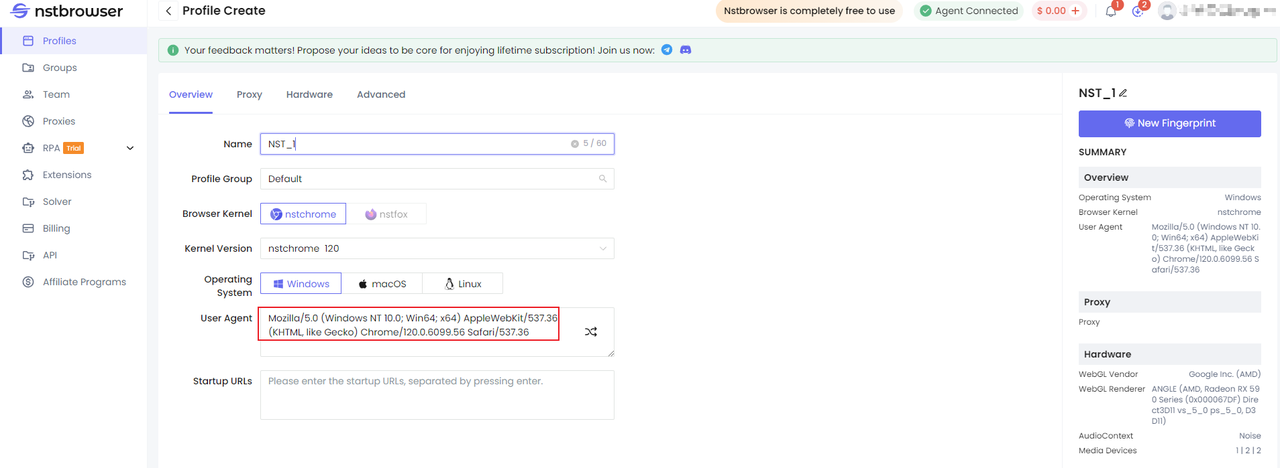
API trình duyệt Nstbrowser
Bạn cũng có thể tùy chỉnh UserAgent thông qua các phương thức API như LaunchBrowser, CreateProfile, Nstbrowser Puppeteer, v.v., trong đó mã sử dụng phương thức Puppeteer như sau:
import puppeteer from 'puppeteer-core';
// LaunchExistBrowser: Connect to or start an existing browser
// You need to create the corresponding profile in advance
// Support custom config
async function launchAndConnectToBrowser(profileId) {
const host = 'localhost:8848';
const apiKey = 'your api key';
const config = {
headless: true,
autoClose: true,
fingerprint: {
name: 'browser113',
platform: 'windows',
kernel: 'chromium',
kernelMilestone: '120',
hardwareConcurrency: 4,
deviceMemory: 8,
proxy: '',
userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.6099.56 Safari/537.36',
}
};
const query = new URLSearchParams({
'x-api-key': apiKey, // required
config: encodeURIComponent(JSON.stringify((config))),
});
const browserWSEndpoint = `ws://${host}/devtool/launch/${profileId}?${query.toString()}`;
console.log('browserWSEndpoint: ', browserWSEndpoint);
await execPuppeteer(browserWSEndpoint);
}
launchAndConnectToBrowser('your profileId').then();Nếu có quá nhiều yêu cầu được gửi bởi cùng một tác nhân người dùng, nó sẽ kích hoạt hệ thống chống bot và cuối cùng dẫn đến việc chặn. Cách tốt nhất để tránh điều này là xoay danh sách tác nhân người dùng để tìm kiếm và cập nhật nó.
Xoay tác nhân người dùng cóp nhặt có nghĩa là thay thế tác nhân đó khi thực hiện yêu cầu web. Điều này cho phép bạn truy cập nhiều dữ liệu hơn và tăng hiệu quả của máy cạp. Phương pháp này còn giúp bảo vệ địa chỉ IP của bạn không bị chặn và đưa vào danh sách đen.
Làm cách nào để luân chuyển tác nhân người dùng?
Hầu hết các trình duyệt đều hỗ trợ xoay tiêu đề Tác nhân người dùng. Ví dụ: trong JS, một danh sách các Tác nhân người dùng có sẵn được xác định trước, sau đó một Tác nhân người dùng ngẫu nhiên hoặc xoay vòng sẽ được lấy từ danh sách và sử dụng.
const axios = require('axios');
// define rotate UserAgent list
const userAgents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0',
// more UerAgent
];
let currentIndex = 0;
async function fetchData() {
try {
const response = await axios.get('https://example.com', {
headers: {
'User-Agent': userAgents[currentIndex]
}
});
console.log(response.data);
currentIndex = (currentIndex + 1) % userAgents.length;
} catch (error) {
console.error(error);
}
}
fetchData();Tránh lệnh cấm UA với tính năng xoay UA thông minh của Nstbrowser
Hãy thử miễn phí ngay bây giờ!
Bạn cũng có thể sử dụng tính năng Xoay vòng UserAgent đi kèm với trình duyệt chống phát hiện. Bằng cách xoay giá trị Tác nhân người dùng, Nstbrowser có thể ngăn chặn việc phát hiện chương trình chống bot và tránh chặn các hoạt động thu thập thông tin.
Nstbrowser Web Scraping là minh họa cho việc tạo hoặc chỉnh sửa dấu vân tay UserAgent trong tệp cấu hình của ứng dụng khách Nstbrowser. Chỉ cần nhấp vào nút Randomize UserAgent như trong hình sau:
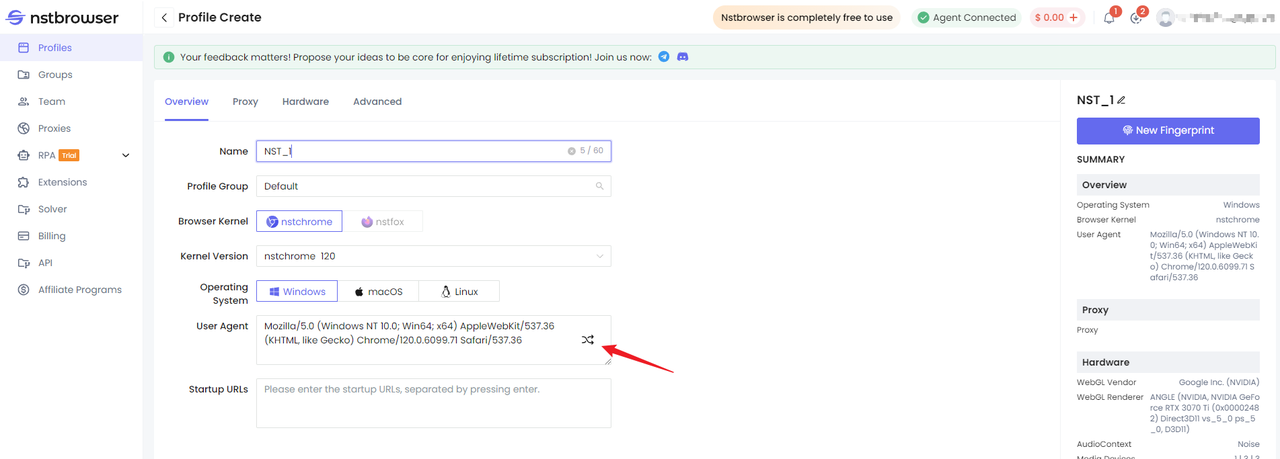
Giữ các khoảng thời gian ngẫu nhiên giữa các yêu cầu để ngăn không cho người dọn dẹp của bạn bị phát hiện và chặn.
Tác nhân người dùng lỗi thời có thể khiến IP của bạn bị chặn! Để duy trì trải nghiệm quét trơn tru và liền mạch, hãy đảm bảo cập nhật tác nhân người dùng của bạn thường xuyên.
Mặc dù máy khách có thể sửa đổi chuỗi tác nhân người dùng nhưng nó vẫn không đủ tin cậy để quản trị viên web bảo vệ máy chủ của họ khỏi lưu lượng truy cập của bot. Để tránh sự không chắc chắn và rắc rối, trình duyệt chống phát hiện là một giải pháp lý tưởng để quét trơn tru.
Nstbrowser giúp vượt qua khả năng phát hiện chống bot và bỏ chặn 99,9% trang web bằng dấu vân tay trình duyệt thực, trình giải CAPTCHA, trình bỏ chặn web và không cần trình duyệt. Ồ! Hãy thử phiên bản miễn phí và tận hưởng khả năng truy cập liền mạch của bạn vào việc tìm kiếm trên web!





