
Web Scraping
Làm cách nào để sử dụng Node.js để quét web?
Trong bài viết này, chúng tôi sẽ giới thiệu cách sử dụng Node.js để quét web, bao gồm các khái niệm cơ bản, cách sử dụng công cụ và phương pháp chống phát hiện để giúp thu thập và xử lý dữ liệu trang web một cách hiệu quả.
May 15, 2024Triệu Lệ Chi
Sử dụng Node.js để quét web là một nhu cầu phổ biến, cho dù bạn muốn thu thập dữ liệu từ một trang web để phân tích hoặc hiển thị nó trên trang web của riêng bạn. Node.js là một công cụ tuyệt vời cho nhiệm vụ này.
Bằng cách đọc bài viết này, bạn sẽ:
- Hiểu các khái niệm cơ bản về quét web
- Học cơ bản về
Node.js - Học cách sử dụng Node.js để quét web
Quét Web là Gì và Lợi Ích của Nó?
Quét web là quá trình trích xuất dữ liệu từ các trang web. Nó liên quan đến việc sử dụng các công cụ hoặc chương trình để mô phỏng hành vi của trình duyệt và trích xuất dữ liệu cần thiết từ các trang web. Quá trình này cũng được biết đến với các thuật ngữ như thu hoạch web hoặc trích xuất dữ liệu web.
Quét web có nhiều lợi ích, như:
- Giúp bạn thu thập dữ liệu từ các trang web để phân tích.
- Cho phép bạn thu thập dữ liệu về đối thủ trong quá trình phát triển sản phẩm để phân tích điểm mạnh và điểm yếu của họ.
- Tự động hóa các nhiệm vụ lặp đi lặp lại, như tải xuống tất cả hình ảnh từ một trang web hoặc trích xuất tất cả các liên kết.
Node.js là Gì?
"Node.js" là một môi trường thực thi mã JavaScript mã nguồn mở, đa nền tảng mà thực thi mã JavaScript ở phía máy chủ. Được tạo ra bởi Ryan Dahl vào năm 2009, nó được xây dựng trên công cụ V8 JavaScript của Chrome. Node.js được thiết kế để xây dựng các ứng dụng mạng có hiệu suất cao, có khả năng mở rộng, đặc biệt là những ứng dụng xử lý một lượng lớn kết nối đồng thời, như các máy chủ web và ứng dụng thời gian thực.
Đặc điểm của Node.js:
- Mô hình lập trình dựa trên sự kiện và không đồng bộ. Node.js sử dụng một kiến trúc dựa trên sự kiện và các hoạt động I/O không chặn, khiến cho nó rất hiệu quả trong việc xử lý các yêu cầu đồng thời. Điều này có nghĩa là máy chủ sẽ không bị chặn trong khi đợi các hoạt động I/O hoàn thành.
- Kiến trúc đơn luồng. Node.js chạy trên một luồng duy nhất sử dụng một vòng lặp sự kiện, xử lý các yêu cầu đồng thời một cách hiệu quả mà không cần đến chi phí của việc chuyển ngữ cảnh luồng.
- npm (Quản lý Gói Node). Node.js đi kèm với npm, một công cụ quản lý gói giúp cho các nhà phát triển dễ dàng cài đặt và quản lý thư viện và công cụ cần thiết cho dự án của họ. Với một kho lưu trữ lớn các mô-đun mã nguồn mở, npm tăng tốc độ phát triển mạnh mẽ.
- Đa nền tảng. Node.js có thể chạy trên nhiều hệ điều hành khác nhau, bao gồm Windows, Linux và macOS, khiến cho nó trở thành một nền tảng phát triển linh hoạt.
Tại Sao Bạn Nên Sử Dụng Node.js cho Quét Web?
Node.js là một môi trường thực thi mã JavaScript phổ biến cho phép bạn sử dụng JavaScript cho việc phát triển phía máy chủ. Sử dụng Node.js để quét web mang lại nhiều lợi ích:
- Thư viện phong phú: Node.js có nhiều thư viện cho quét web, như Request, Cheerio, và Puppeteer.
- Tính chất không chặn không đồng bộ: I/O không chặn của Node.js làm cho quét web đồng thời dễ dàng và hiệu quả hơn.
- Xử lý các nhiệm vụ tập trung vào I/O: Node.js xuất sắc trong việc xử lý các nhiệm vụ tập trung vào I/O, khiến cho quét web trở nên dễ dàng.
- Dễ học: Nếu bạn biết JavaScript, bạn có thể nhanh chóng học Node.js và bắt đầu quét web.
Cách Sử Dụng Node.js cho Quét Web?
Không chần chừ, hãy bắt đầu với việc quét dữ liệu bằng Node.js!
Bước 1: Khởi tạo môi trường
Trước hết, tải xuống và cài đặt Node.js từ trang web chính thức của nó. Theo các hướng dẫn cài đặt chi tiết cho hệ điều hành của bạn.
Bước 2: Cài đặt Puppeteer
Node.js cung cấp nhiều thư viện cho việc quét web, chẳng hạn như Request, Cheerio và Puppeteer. Ở đây, chúng ta sẽ sử dụng Puppeteer làm ví dụ. Cài đặt Puppeteer bằng npm với các lệnh sau:
bash
mkdir web-scraping && cd web-scraping
npm init -y
npm install puppeteer-coreBước 3: Tạo Một Đoạn Mã
Tạo một tệp, chẳng hạn như index.js, trong thư mục dự án của bạn và thêm mã sau:
- Phương thức
goTođược sử dụng để mở một trang web. Nó có hai tham số: URL của trang web để mở và một đối tượng cấu hình. Chúng ta có thể thiết lập các tham số khác nhau trong đối tượng này, chẳng hạn như waitUntil, chỉ định để trả về sau khi trang đã tải xong. - Phương thức
waitForSelectorđược sử dụng để đợi một bộ chọn xuất hiện. Nó lấy một bộ chọn làm tham số và trả về một đối tượng Promise khi bộ chọn xuất hiện trên trang. Chúng ta có thể sử dụng đối tượng Promise này để xác định xem bộ chọn đã xuất hiện chưa. - Phương thức
contentđược sử dụng để lấy nội dung của trang. Nó trả về một đối tượng Promise, mà chúng ta có thể sử dụng để truy xuất nội dung của trang. - Phương thức
page.$evalđược sử dụng để lấy nội dung văn bản của một bộ chọn. Nó lấy hai tham số: tham số đầu tiên là bộ chọn và tham số thứ hai là một hàm sẽ được thực thi trong trình duyệt. Hàm này cho phép chúng ta lấy nội dung văn bản của bộ chọn.
javascript
const puppeteer = require('puppeteer');
async function run() {
const browser = await puppeteer.launch({
headless: false,
ignoreHTTPSErrors: true,
});
const page = await browser.newPage();
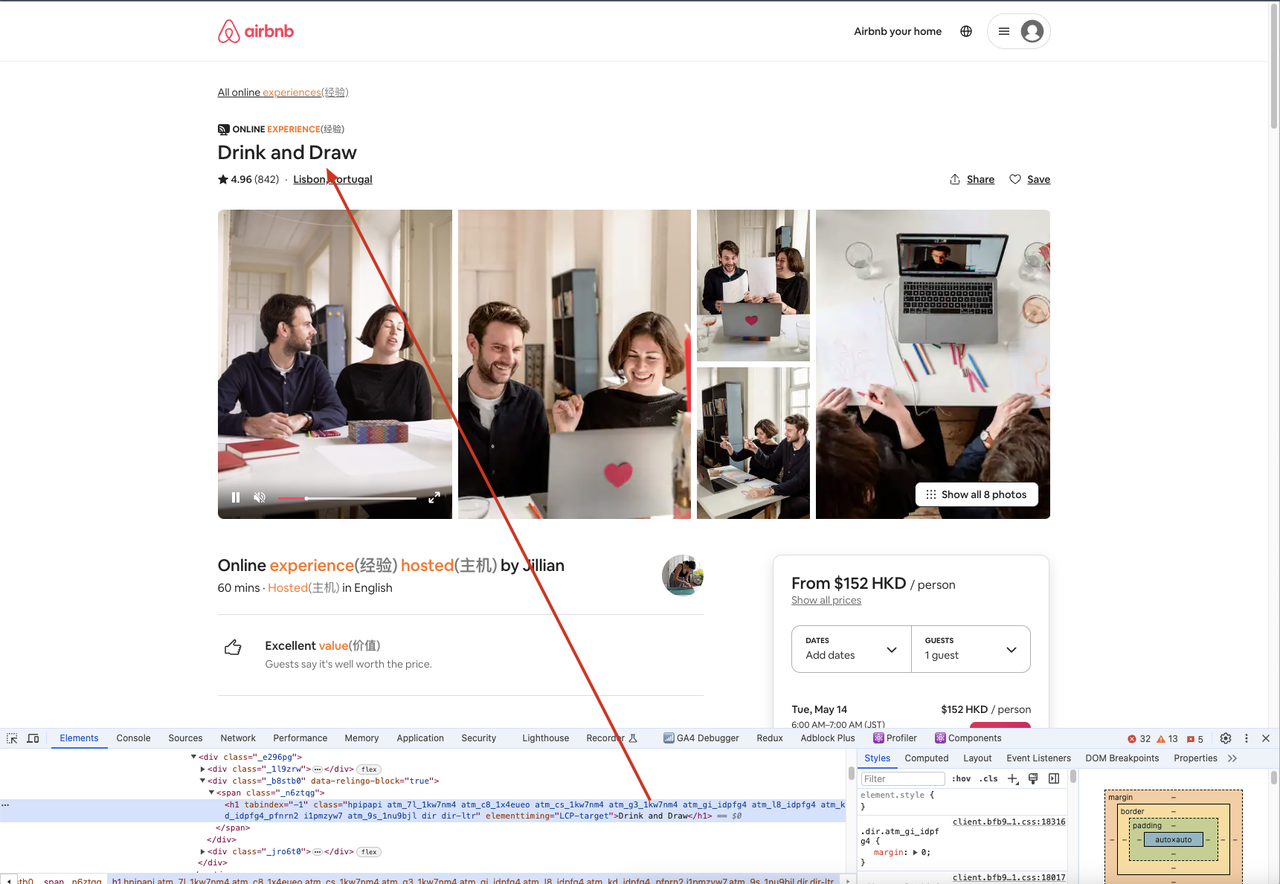
await page.goto('https://airbnb.com/experiences/1653933', {
waitUntil: 'domcontentloaded',
});
await page.waitForSelector('h1');
await page.content();
const title = await page.$eval('h1', (el) => el.textContent);
console.log(title);
await browser.close();
}
run();Bước 4: Chạy Đoạn Mã
Chạy index.js với lệnh sau:
bash
node index.jsSau khi chạy đoạn mã, bạn sẽ thấy kết quả đầu ra trên cửa sổ terminal:

Trong ví dụ này, chúng tôi sử dụng puppeteer.launch() để tạo một phiên trình duyệt, browser.newPage() để tạo một trang mới, page.goto() để mở một trang web, page.waitForSelector() để đợi một bộ chọn xuất hiện và page.$eval() để lấy nội dung văn bản của một bộ chọn.
Ngoài ra, chúng ta có thể truy cập trang web đã được quét thông qua một trình duyệt, mở công cụ phát triển và sau đó sử dụng bộ chọn để tìm phần tử chúng ta cần, so sánh nội dung phần tử với những gì chúng ta nhận được trong mã để đảm bảo tính nhất quán.
Kỹ Thuật Chống Phát Hiện
Khi sử dụng Puppeteer để quét web, một số trang web có thể phát hiện ra hoạt động quét của bạn và trả về lỗi như 403 Forbidden. Để tránh bị phát hiện, bạn có thể sử dụng các kỹ thuật khác nhau như:
- Sử dụng proxy IPs
- Sửa đổi User-Agent
- Chạy trong chế độ headless
- Tùy chỉnh fonts và canvas fingerprints
Các phương pháp này giúp tránh được phát hiện, cho phép nhiệm vụ quét web của bạn tiếp tục một cách trơn tru. Đối với các kỹ thuật chống phát hiện tiên tiến, hãy xem xét việc sử dụng các công cụ như Nstbrowser - Trình duyệt Chống Phát Hiện Tiên Tiến.
Hơn





